
This is a Plain English Papers summary of a research paper called UniME: MLLMs Beat CLIP for Universal Multimodal Embeddings. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overcoming CLIP's Limitations: The Case for Universal Multimodal Embeddings
Modern AI applications rely heavily on multimodal embeddings to process diverse data types, enabling critical tasks like image-text retrieval, Retrieval Augmented Generation (RAG), and Visual Question Answering (VQA). While the Contrastive Language-Image Pre-training (CLIP) framework established a strong foundation for multimodal representation learning, it faces significant limitations that constrain its effectiveness in complex applications.
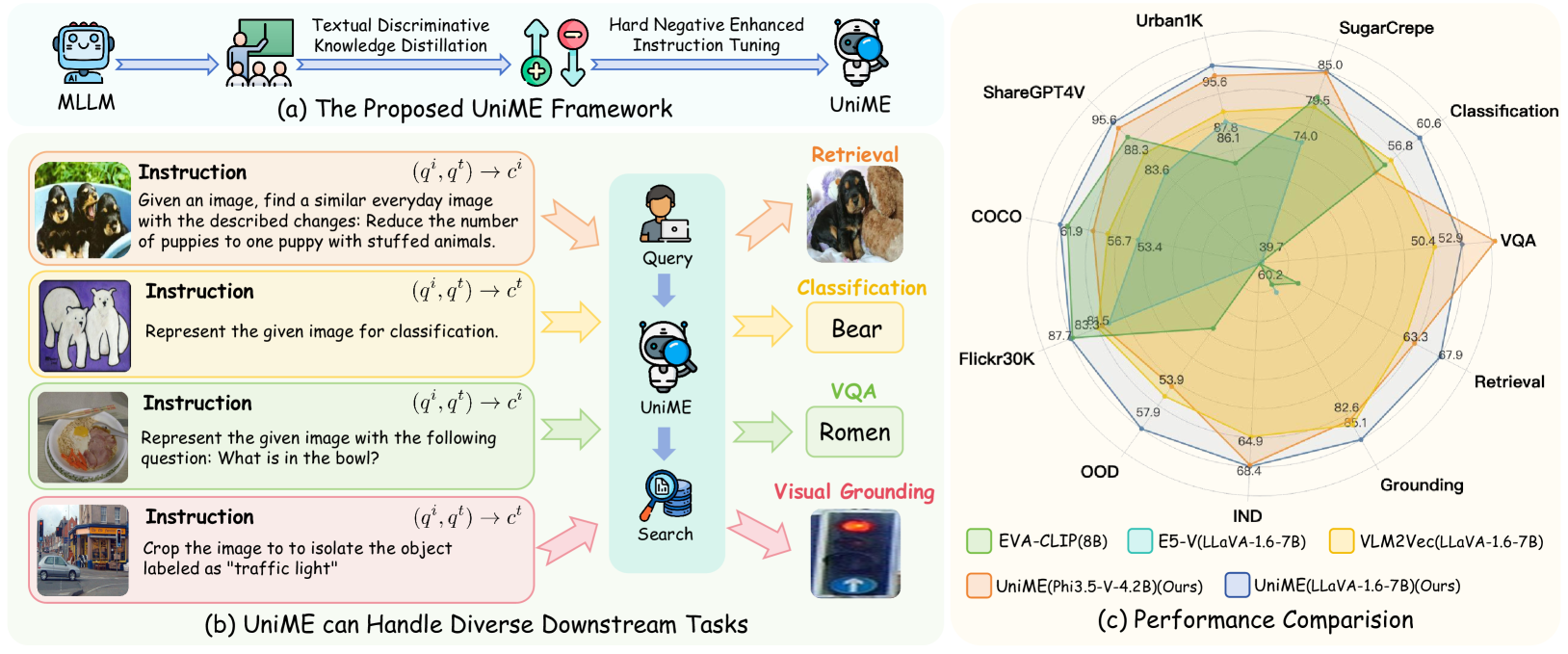
The UniME framework incorporates textual discriminative knowledge distillation and hard negative enhanced instruction tuning stages to learn discriminative representations for diverse downstream tasks. The framework achieves state-of-the-art performance on both the MMEB benchmark and multiple retrieval tasks.
CLIP suffers from three key constraints: text token truncation (limited to 77 tokens), isolated image-text encoding (dual-encoder architecture), and deficient compositionality (bag-of-words behavior). These limitations hinder CLIP's ability to process detailed descriptions, compromise its effectiveness in complex tasks requiring cross-modal understanding, and restrict its advanced language processing capabilities.
While Multimodal Large Language Models (MLLMs) like LLaVA have demonstrated remarkable progress in vision-language understanding, their potential for learning transferable multimodal representations remains underexplored. Their autoregressive next-token prediction objective inherently limits their effectiveness in learning discriminative embeddings compared to contrastive methods.
To address these challenges, researchers introduce UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks:
- Textual discriminative knowledge distillation: Enhances the embedding capability of the MLLM's language component by distilling knowledge from a powerful LLM-based teacher model
- Hard negative enhanced instruction tuning: Advances discriminative representation learning through false negative filtering and hard negative sampling
The Evolution of Multimodal Large Language Models
Multimodal Large Language Models extend LLMs to process and integrate cross-modal information, marking significant progress in AI's ability to understand both visual and textual content. A seminal development in this field was LLaVA, which encodes images into token representations using vision encoders like CLIP and projects them into the LLM's token space.
Following this breakthrough, numerous MLLM variants have demonstrated remarkable performance in multimodal comprehension and reasoning tasks. Models like CogVLM incorporate trainable visual expert modules within the attention and feed-forward network layers of the language model, yielding substantial performance enhancements. LLaVA-1.6 introduces the "AnyRes" technique to process variable high-resolution images, significantly improving fine-grained visual understanding. Phi3.5-Vision exhibits strong reasoning capabilities for both single and multi-image text prompts.
Despite these advancements, the autoregressive next-token prediction objective of MLLMs inherently constrains their capacity to learn efficient multimodal representations. This limitation motivates the search for more effective approaches to multimodal embedding learning.
Transforming LLMs for Representation Learning
As large language models demonstrate increasing proficiency in natural language processing, recent research has focused on harnessing decoder-only architectures for effective representation learning. Previous approaches have adapted prompt-based representation methods for autoregressive models, enabling Large Language Models to perform in-context learning and scale to various model sizes.
LLM2Vec transforms pre-trained decoder-only LLMs into versatile text encoders by incorporating bidirectional attention mechanisms, masked next-token prediction, and unsupervised contrastive alignment. Similarly, NV-Embed introduces a latent attention layer and eliminates the causal attention mask during contrastive training, substantially enhancing the efficiency of embeddings generated from decoder-only LLMs.
While these approaches show promising embedding performance, their exclusive focus on text-only inputs fails to meet the growing demands of multimodal applications. This gap highlights the need for comprehensive frameworks that can handle both textual and visual inputs seamlessly.
Challenges in Multimodal Representation Learning
CLIP demonstrates superior image-text retrieval capabilities through large-scale cross-modal contrastive learning, but suffers from three inherent constraints: 77-token text truncation limits fine-grained semantic alignment; disjoint dual-encoder architecture impedes cross-modal fusion for instruction-sensitive tasks; and primitive language modeling induces bag-of-words representations.
Recent research addresses these limitations through two complementary approaches:
- MagicLens employs lightweight dual encoders to enable relation-aware image retrieval guided by textual instructions
- MLLM-based approaches like E5-V propose a single-modality training approach that significantly outperforms traditional multimodal training on image-text pairs while reducing training costs
VLM2Vec presents a contrastive training framework that can handle any combination of images and text, as well as high-resolution images and long text inputs. Despite these improvements, current methods still face challenges in effectively discriminating hard negative samples during retrieval.
The UniME Framework: A Two-Stage Approach
UniME presents a novel two-stage framework that enables MLLMs to learn universal multimodal embeddings for diverse downstream tasks. This approach addresses the limitations of dual-tower encoder structures by employing MLLMs with robust multimodal understanding.
Preliminary: Task Definition and Feature Extraction
To formalize the problem, both query and candidate data are fed into the MLLM using customized prompts to extract embeddings. The similarity between the query and candidates is calculated, followed by ranking and selecting the most relevant pairs:
$$\boldsymbol{P}=\text{Rank}(\Theta(\phi(\boldsymbol{q}),\phi(\boldsymbol{c}))),$$
where $\phi$ denotes the MLLM employed to extract embeddings. Both the query and candidate may be either unimodal (text or image only) or multimodal (interleaved image-text).
Unlike CLIP's dual-tower structure, MLLM incorporates three essential components: a vision tower, a projection layer, and an LLM backbone. This unified structure supports flexible processing of both unimodal and multimodal inputs.
Textual Discriminative Knowledge Distillation
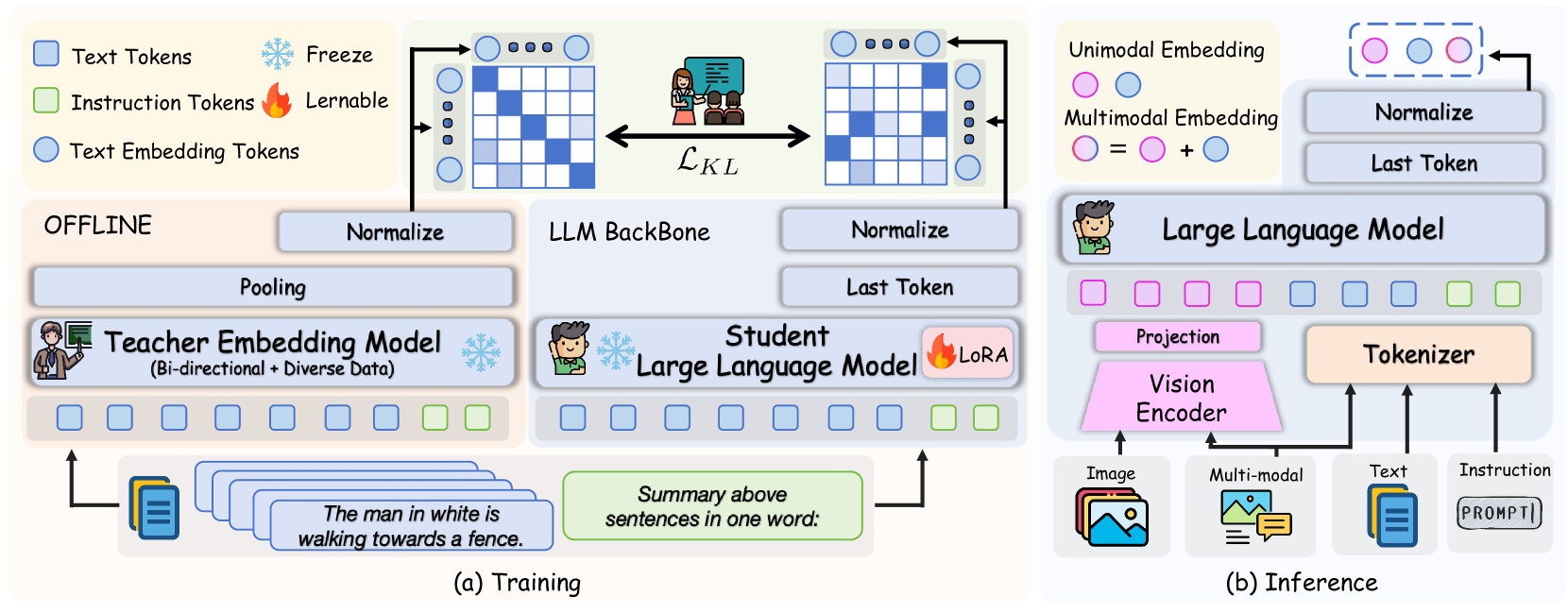
The framework of the Textual Discriminative Knowledge Distillation stage. This approach leverages the state-of-the-art LLM-based embedding model to enhance the discriminative capabilities of the MLLM's language component.
The autoregressive decoder architecture of LLMs, constrained by a causal masking mechanism, inherently restricts their discriminative capacity. To address this limitation, UniME introduces discriminative textual knowledge distillation, transferring knowledge from the state-of-the-art LLM-based embedding model NV-Embed V2.
The process involves:
- Decoupling the LLM component from the MLLM architecture
- Processing text-only inputs using the prompt: "Summarize the above sentences in one word: \\n"
- Obtaining normalized student and teacher text embeddings
- Implementing discriminative distribution alignment by minimizing the Kullback-Leibler (KL) divergence between the embeddings
This method demonstrates enhanced efficiency compared to direct contrastive learning under identical data and training conditions, achieving significant performance improvements in downstream tasks.
Hard Negative Enhanced Instruction Tuning
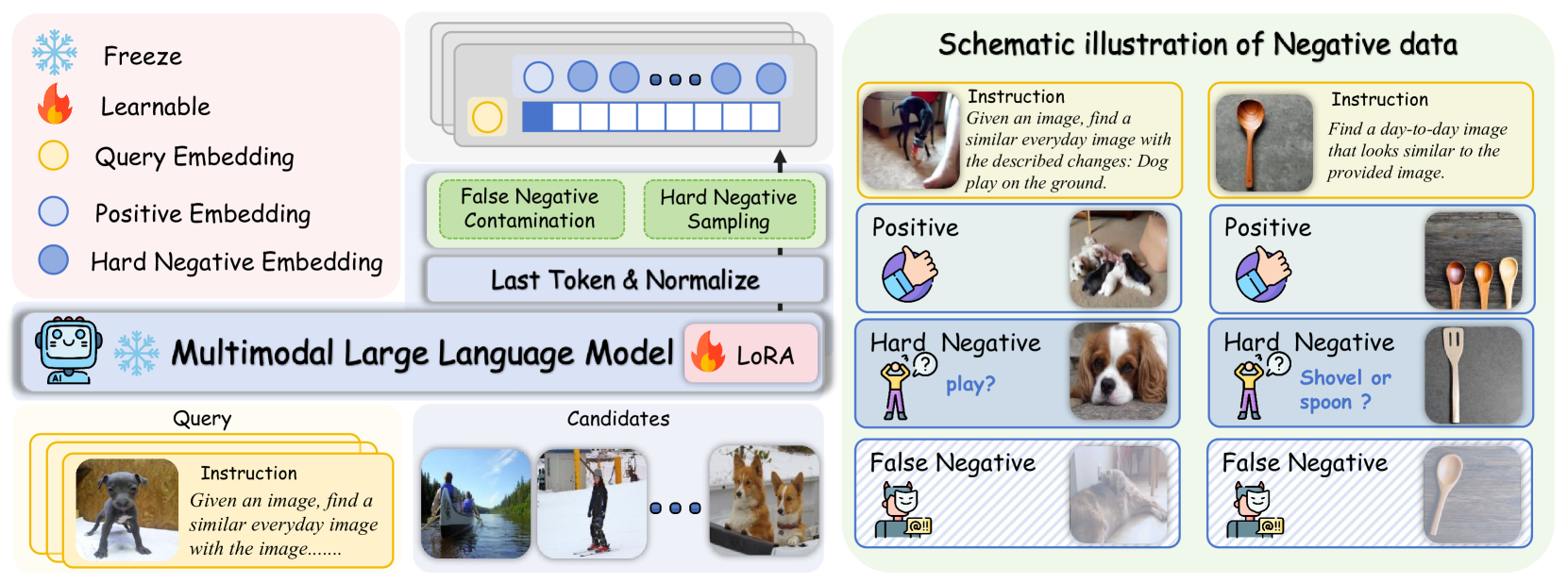
The framework of the Hard Negative Enhanced Instruction Tuning stage. This approach further improves the discriminative capabilities of the MLLM through false negative filtering and hard negative sampling.
After textual discriminative knowledge distillation, UniME develops preliminary discriminative capabilities but exhibits limited visual sensitivity. To address this limitation, the hard negative enhanced instruction tuning stage aims to:
- Further enhance discriminative capabilities
- Improve cross-modal alignment
- Strengthen instruction-following ability for downstream tasks
The presence of false negatives in training batches hinders effective hard negative differentiation under standard InfoNCE loss. To mitigate this, UniME introduces a filtering mechanism based on a similarity threshold between query and positive samples. During training, all negative samples whose similarity to the query exceeds the threshold are excluded, effectively eliminating false negatives while preserving challenging hard negatives.
Hard negative samples, which are distinct in label from positive samples but closely embedded, offer the greatest utility through substantial gradient information in contrastive learning. Drawing inspiration from prior research, UniME proposes a hard negative sampling strategy to optimize both training efficiency and discriminative performance. The model samples corresponding hard negatives within each training batch, forcing it to focus on challenging samples and thereby learning more discriminative multimodal representations.
Efficient Training Implementation
UniME employs a streamlined training recipe to balance computational efficiency with model performance:
Stage 1: Textual Discriminative Knowledge Distillation
- Employs QLoRA (Quantized Low-Rank Adaptation) for parameter-efficient fine-tuning
- Uses text-only inputs with minimal trainable parameters (less than 5% of total)
- Complete training requires approximately 1-2 hours depending on the model
Stage 2: Hard Negative Enhanced Instruction Tuning
- Implements GradCache to decouple backpropagation between contrastive loss computation and encoder updates
- Employs QLoRA for parameter-efficient fine-tuning of all MLLM parameters
- This combined approach facilitates effective training with manageable memory consumption
Comprehensive Experimental Validation
Implementation Details
UniME was evaluated through extensive experiments on different multimodal large language models: Phi3.5-Vision and LLaVA-1.6. The implementation leveraged PyTorch with DeepSpeed ZeRO stage-2 optimization to enhance training efficiency. Training was conducted on 8 NVIDIA A100 (80GB) GPUs.
In the textual discriminative knowledge distillation stage, the training used gradient accumulation with a batch size of 768, a learning rate of 5e-4, and a LoRA rank of 32. NV-Embed V2 served as the teacher model, with training completing within two epochs.
For the hard negative enhanced instruction turning stage, low-resolution (336×336) image inputs were used with an accumulated batch size of 1024. The learning rate was reduced to 1e-4 for Phi3.5-V and 2e-5 for LLaVA-1.6, with a decreased LoRA rank of 16. Each model underwent 1,000 training steps during this stage, sampling 8 hard negatives within a batch with a similarity threshold of β=0.1.
Datasets and Evaluation Metrics
For training, the Natural Language Inference (NLI) dataset containing around 273k sentence pairs was used for the first stage. The second stage employed 20 in-distribution datasets from the MMEB benchmark, covering four core multimodal tasks: classification, visual question answering, multimodal retrieval, and visual grounding.
Evaluation was conducted across both in-distribution (20 test sets) and out-of-distribution (16 test sets) benchmarks from MMEB. The model was also tested on multiple cross-modal retrieval tasks, including short-caption image-text retrieval (Flickr30K and COCO2014), long-caption image-text retrieval (ShareGPT4V and Urban1K), and compositional retrieval (SugarCrepe). Precision@1 served as the primary evaluation metric across all datasets.
Performance Analysis on Multiple Benchmarks
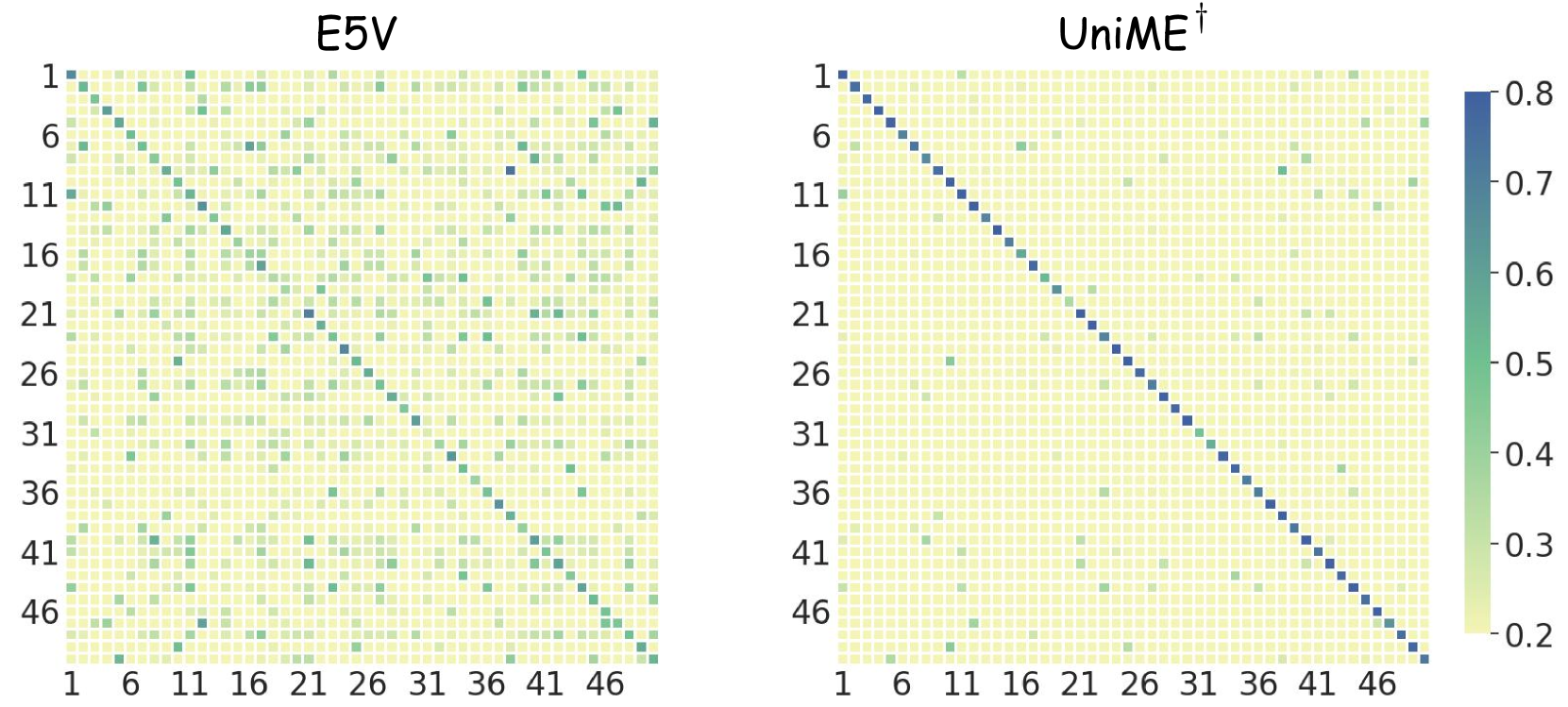
The discrimination comparison between E5-V and UniME†. † represents the UniME model trained only on the first textual discrimination knowledge distillation stage.
Multimodal Retrieval Results
| Models | #Parameters | Per Meta-Task Score | Average Score | |||||
|---|---|---|---|---|---|---|---|---|
| Classification | VQA | Retrieval | Grounding | IND | OOD | Overall | ||
| # of Datasets → | 10 | 10 | 12 | 4 | 20 | 16 | 36 | |
| Zero-shot on MMEB | ||||||||
| CLIP(ViT-L) [22] | 0.4B | 42.8 | 9.1 | 53.0 | 51.8 | 37.1 | 38.7 | 39.2 |
| OpenCLIP(ViT-L) [42] | 0.4B | 41.5 | 6.9 | 44.6 | 53.5 | 32.8 | 36.0 | 36.6 |
| Magiclens(ViT-L) [64] | 0.4B | 38.8 | 8.3 | 35.4 | 26.0 | 31.0 | 23.7 | 27.1 |
| SigLIP(So/14) [61] | 0.9B | 40.3 | 8.4 | 31.6 | 59.5 | 32.3 | 38.0 | 35.0 |
| BLIP2(ViT-L) [28] | 1.2B | 27.0 | 4.2 | 33.9 | 47.0 | 25.3 | 25.1 | 28.0 |
| CLIP(ViT-BigG/14) [8] | 2.5B | 52.3 | 14.0 | 50.5 | 60.3 | 38.9 | 45.8 | 44.3 |
| EVA-CLIP [48] | 8B | 56.0 | 10.4 | 49.2 | 58.9 | 38.1 | 45.6 | 43.7 |
| E5-V(Phi3.5-V) [21] | 4.2B | 39.1 | 9.6 | 38.0 | 57.6 | 33.1 | 31.9 | 36.1 |
| E5-V(LLaVA-1.6) [21] | 7B | 39.7 | 10.8 | 39.4 | 60.2 | 34.2 | 33.4 | 37.5 |
| UniME † (Phi3.5-V) | 4.2B | 42.5(+3.4) | 18.3(+8.7) | 40.5(+2.5) | 59.9(+2.3) | 36.0(+2.9) | 38.3(+6.4) | 40.3(+4.2) |
| UniME † (LLaVA-1.6) | 7B | 43.0(+3.3) | 17.7(+6.9) | 42.5(+3.1) | 63.2(+3.0) | 37.6(+3.4) | 38.6(+5.2) | 41.6(+4.1) |
| Fine-tuning on MMEB | ||||||||
| CLIP(ViT-L) [22] | 0.4B | 55.2 | 19.7 | 53.2 | 62.2 | 47.6 | 42.8 | 47.6 |
| VLM2Vec(Phi3.5-V) [22] | 4.2B | 54.8 | 54.9 | 62.3 | 79.5 | 66.5 | 52.0 | 62.9 |
| VLM2Vec(LLaVA-1.6) [22] | 7B | 56.8 | 50.4 | 63.3 | 82.6 | 64.9 | 53.9 | 63.3 |
| UniME † (Phi3.5-V) | 4.2B | 54.8(+0.0) | 55.9(+1.0) | 64.5(+2.2) | 81.8(+2.3) | 68.2(+1.7) | 52.7(+0.7) | 64.2(+1.3) |
| UniME † (LLaVA-1.6) | 7B | 60.6(+3.8) | 52.9(+2.5) | 67.9(+4.6) | 85.1(+2.5) | 68.4(+3.5) | 57.9(+4.0) | 66.6(+3.3) |
Table 1: Results on the MMEB benchmark. IND represents the in-distribution dataset, and OOD represents the out-of-distribution dataset. The reported scores are the average Precision@1 over the corresponding datasets. The best results are marked in bold. † : UniME with textual discrimination distillation only. ‡ : UniME with both textual discrimination distillation and hard negative enhanced instruction tuning.
UniME consistently achieves significant performance improvements over E5-V across different foundation models. Specifically, UniME exhibits an average performance improvement of 4.2% over E5-V using the Phi3.5-V model and 4.1% with LLaVA-1.6 as the base model. The diagonal clarity of the UniME similarity matrix is significantly enhanced compared to E5-V, indicating that UniME learns representations with superior distinctiveness. Compared with VLM2Vec, UniME achieves 1.3% and 3.3% performance improvement when using Phi3.5-V and LLaVA-1.6 as the base models.
Cross-Modal Retrieval Performance
| Models | #Parameters | Short Caption Retrieval | Long Caption Retrieval | Compositional Retrieval | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30K | COCO | ShareGPT4V | Urban1K | SugarCrepe | ||||||||
| $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | $q^{2} \rightarrow c^{2}$ | Replace | Swap | Add | ||
| OpenCLIP(VIT-L) [42] | 0.4B | 67.3 | 87.2 | 37.0 | 58.1 | 81.8 | 84.0 | 47.0 | 47.0 | 79.5 | 62.7 | 74.9 |
| CLIP(VIT-BigG) (14) [8] | 2.5B | 79.5 | 92.9 | 51.5 | 67.3 | 98.1 | 95.6 | 77.8 | 80.7 | 86.5 | 68.9 | 88.4 |
| EVA-CLIP [48] | 8B | 80.3 | 94.5 | 52.0 | 70.1 | 93.1 | 91.2 | 80.4 | 77.8 | 85.9 | 70.3 | 86.7 |
| E5-V(Phi3.5-V) [21] | 4.2B | 72.2 | 79.6 | 44.7 | 53.4 | 86.0 | 88.5 | 83.8 | 83.6 | 88.2 | 66.6 | 75.5 |
| E5-V(LLaVA-1.6) [21] | 7B | 77.3 | 85.7 | 49.1 | 57.6 | 85.1 | 82.1 | 88.9 | 83.2 | 86.3 | 68.7 | 66.9 |
| UniME † (Phi3.5-V) | 4.2B | 72.0(-0.2) | 80.6(-1.0) | 44.9(-0.2) | 57.2(-0.5) | 86.8(-1.5) | 92.3(-1.3) | 85.1(-2.3) | 86.9(-3.3) | 90.2(-2.0) | 67.6(-1.0) | 91.2(-15.9) |
| UniME † (LLaVA-1.6) | 7B | 77.2(-0.1) | 84.6(-1.1) | 51.8(-1.9) | 56.4(-1.2) | 89.8(-1.7) | 86.9(-1.5) | 91.3(-2.3) | 82.4(-3.5) | 89.5(-3.2) | 64.8(-3.9) | 94.2(-27.5) |
| VLM2Vec(Phi3.5-V) [22] | 4.2B | 68.7 | 83.0 | 43.7 | 59.8 | 98.1 | 92.0 | 87.9 | 86.8 | 86.2 | 66.7 | 84.2 |
| VLM2Vec(LLaVA-1.6) [22] | 7B | 76.0 | 90.6 | 46.8 | 66.6 | 85.8 | 90.7 | 84.7 | 90.8 | 85.8 | 66.3 | 86.5 |
| UniME † (Phi3.5-V) | 4.2B | 77.0(-11.3) | 88.2(-3.2) | 49.8(-0.1) | 66.8(-7.3) | 92.1(-2.0) | 96.4(-4.4) | 92.7(-4.0) | 95.1(-5.3) | 90.1(-5.9) | 70.9(-4.2) | 95.5(-5.1) |
| UniME † (LLaVA-1.6) | 7B | 81.9(-3.9) | 93.4(-2.8) | 53.7(-0.1) | 70.1(-3.5) | 93.9(-5.1) | 97.2(-6.5) | 95.2(-10.5) | 93.9(-5.1) | 89.0(-5.2) | 71.5(-5.2) | 94.4(-7.9) |
Table 2: Results of zero-shot text-image retrieval on short caption datasets (Flickr30K and MS-COCO), long caption datasets (ShareGPT4V and Urban1K) and compositional benchmark (SugarCrepe). The reported scores are the average Recall@1 over the corresponding datasets. The best results are marked in bold. † : UniME with textual discrimination distillation only. ‡ : UniME with both textual discrimination distillation and hard negative enhanced instruction tuning.
For short-caption datasets (Flickr30K and MS-COCO), after the textual discrimination knowledge distillation stage, UniME achieves comparable retrieval performance to E5-V. The subsequent hard negative enhanced instruction tuning further boosts performance, yielding a significant improvement of 5.2%–11.3% over VLM2Vec.
On long-caption retrieval tasks (ShareGPT4V and Urban1K), UniME demonstrates superior performance across all metrics. Specifically, following the textual discriminative knowledge distillation stage, UniME exhibits a performance improvement of 1.3%-3.8% based on the Phi3.5-V model. After hard negative enhanced instruction tuning, UniME outperforms VLM2Vec by 2.0%-8.3%.
For compositional cross-modal retrieval on SugarCrepe, UniME consistently delivers superior performance. After the textual discriminative knowledge distillation phase, the Phi3.5-V-based UniME outperforms E5-V by 2.0% in relation replacement, 1.0% in object swapping, and 15.9% in attribute addition tasks. After the second stage, UniME achieves 3.9%, 4.2%, and 9.1% performance improvement compared with VLM2Vec.
In-Depth Analysis of Model Components
The Power of Hard Negatives
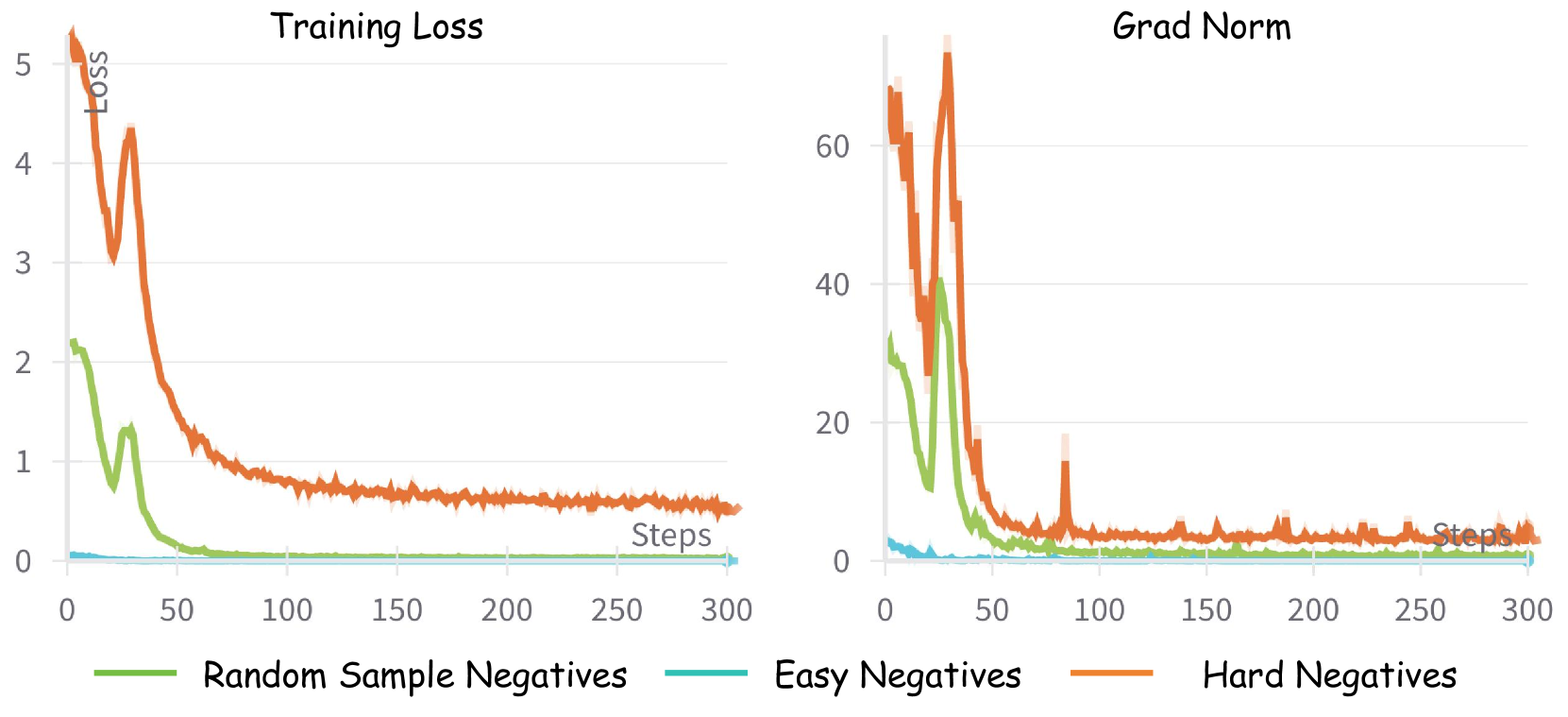
The comparison of training loss and pre-clip gradient norms for hard negatives, easy negatives, and random sample negatives.
The training loss and pre-clip gradient norms visualization for three negative types reveals important insights. Easy negatives (least similar in batch) are easily distinguishable, leading to rapid convergence of training loss to nearly zero and minimal gradient norms. Random negatives (randomly sampled in batch) show slower convergence than easy negatives, but eventually approach zero loss. In contrast, hard negatives (most similar in batch after removing positives and false negatives) pose considerable challenges, sustaining elevated training losses and generating substantially higher gradient norms, differing by orders of magnitude from easy negatives.
The Value of Each Training Stage
| Stage1 | Stage2 | MMEB | $\mathrm{R}_{\text {Short }}$ | $\mathrm{R}_{\text {Long }}$ | $\mathrm{R}_{\text {Compos }}$ |
|---|---|---|---|---|---|
| $\boldsymbol{X}$ | $\boldsymbol{X}$ | 25.3 | 44.2 | 62.9 | 63.1 |
| $\boldsymbol{\checkmark}$ | $\boldsymbol{X}$ | 40.3 | 63.7 | 87.8 | 83.0 |
| $\boldsymbol{X}$ | $\boldsymbol{\checkmark}$ | 63.8 | 61.5 | 84.2 | 77.1 |
| $\boldsymbol{\checkmark}$ | $\boldsymbol{\checkmark}$ | $\mathbf{6 4 . 2}$ | $\mathbf{7 0 . 4}$ | $\mathbf{9 4 . 1}$ | $\mathbf{8 4 . 8}$ |
Table 3: Ablation study of different training stages. We report the mean scores on the MMEB benchmark, short and long cross-modal retrieval, as well as compositional cross-modal retrieval.
An ablation study based on Phi3.5-V demonstrates the contribution of each training stage. The initial embeddings from Phi3.5-V exhibit weak discriminative properties. After the first stage of textual discriminative knowledge distillation, the model registers performance improvements of 15%, 19.5%, 24.9%, and 19.9% on the MMEB benchmark, short and long caption cross-modal retrieval, and compositional retrieval tasks, respectively.
Focusing solely on the second stage (hard negative enhanced instruction tuning) results in performance gains of 38.5%, 17.3%, 21.3%, and 14.0% in the same tasks. The enhancement in MMEB benchmark performance after the second stage markedly exceeds that of the first, primarily due to improved model capabilities in following complex instructions.
By integrating both training stages, UniME achieves optimal performance across all evaluated downstream tasks, demonstrating the complementary nature of the two stages.
Optimizing False Negative Filtering
| Model | $\beta$ | FalseNeg(%) | Average Score | ||
|---|---|---|---|---|---|
| IND | OOD | Overall | |||
| Phi3.5-V | $-0.1$ | $81.7 \%$ | 61.0 | 43.4 | 55.3 |
| 0.0 | $53.2 \%$ | 66.1 | 49.0 | 61.1 | |
| 0.1 | $22.9 \%$ | 68.2 | 52.7 | 64.2 | |
| 0.2 | $18.2 \%$ | 68.2 | 51.9 | 63.7 | |
| 0.3 | $13.1 \%$ | 68.3 | 52.1 | 63.9 |
Table 4: Ablation study of the false negative filtering threshold β. FalseNeg(%): proportion of samples which filtered false negatives.
The threshold β directly influences the percentage of filtered false negatives. Setting β to -0.1 results in filtering false negatives for 81.7% of samples, but the inclusion of some hard negative samples in the filtered set results in poor model performance. Increasing β from -0.1 to 0.1 reduces the proportion of samples with filtered false negatives from 81.7% to 22.9%, thereby significantly improving performance. Further increasing β to 0.3 filters false negatives in only 13.1% of samples, resulting in a slight performance decline due to persistent false negatives.
Finding the Ideal Number of Hard Negatives
| Model | Top- $k$ | HardNeg(%) | Average Score | ||
|---|---|---|---|---|---|
| IND | OOD | Overall | |||
| Phi3.5-V | 4 | $0.4 \%$ | 67.8 | 52.4 | 63.8 |
| 8 | $0.8 \%$ | 68.2 | 52.7 | 64.2 | |
| 16 | $1.6 \%$ | 68.1 | 51.6 | 63.5 | |
| 32 | $3.2 \%$ | 68. |
