
We often hear the term 'Scalability,' especially when discussing robust systems. But what does it really mean, and why does it matter? Let's break it down in a simple yet impactful way.
Imagine you've built a fantastic application, and a handful of users are enjoying it. But as time goes on, more and more people start using it. With every new user, the demand on your system grows, requiring more processing power, storage, and network capacity. This is where scalability comes in. Simply put, scalability is the ability of your system to handle increasing workloads efficiently without compromising performance.

Imagine a small bar with just one bartender like the one above. In the beginning, serving a handful of customers is easy. But as the crowd grows, the bartender struggles to keep up. To handle the rush, the bar can either hire more bartenders (scale horizontally) or equip the existing bartender with better tools like automated drink dispensers (scale vertically). Similarly, systems scaled by adding more servers or improving the power of existing ones to ensure every user gets served without long waits.
Long story short, when building a system, it often starts with a basic client-server architecture — a client sends a request, and the server receives it and responds. Simple as that.
But what happens when 100 clients are connected to a single server? The load increases. To handle this, we can either increase the server’s resource capacity (Vertical Scaling) or add more servers (Horizontal Scaling).
Each scaling method has its pros and cons.
Vertical Scaling
Pros
- No data inconsistency, as all data is handled by a single system.
- No need for load balancing.
Cons
- Hardware limitations cap the maximum load.
- Single point of failure.
- Can become costly.
Horizontal Scaling
Pros
- More resilient with backups available.
- Easily handles user growth.
Cons
- Requires load balancing.
- Communication happens through network calls, which can be slower.
- Data inconsistency might occur as multiple servers manage the data and requests.
So which way you prefer, I would say both, to eliminate the cons of each one.
Now that we’ve nailed down what scalability is and how it works, it’s time to get our hands dirty and see how we can actually achieve it.
This is where the real game begins!💥💥

Current Architecture: Laying the Groundwork
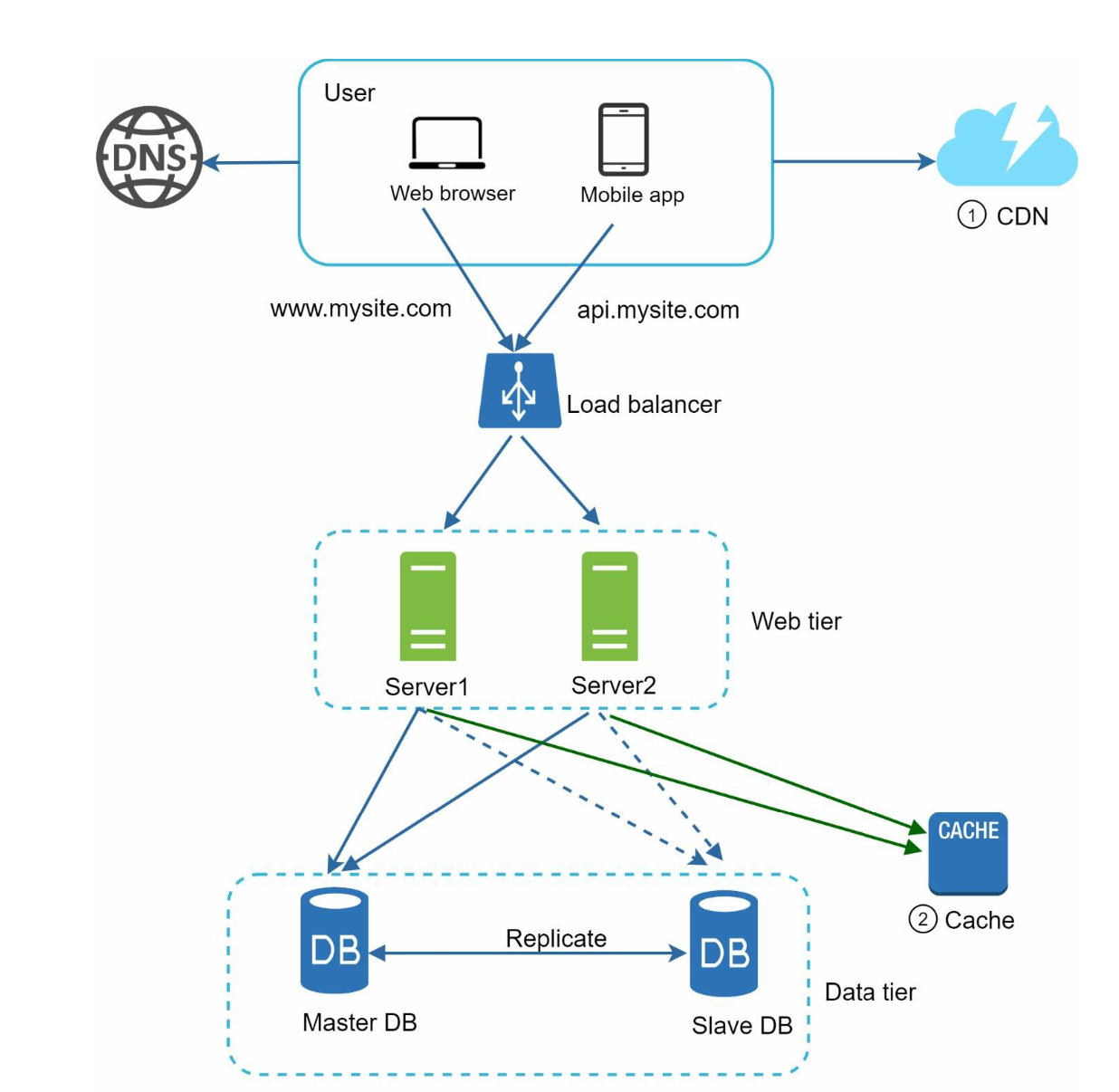
The above system has a swarm of clients sending requests, web servers handling the traffic, and database servers dishing out responses. Throw in some caching for speed and load-balancing for stability, and you've got a solid setup. Now, let's zero in on how we can scale this system to handle even more action.
Three Pillars of Scalability
To make a system scalable, we focus on three key areas:
Web Tier Scaling: Expanding the capacity of web servers to handle growing user requests efficiently.
Data Tier Scaling: Ensuring databases can store, manage, and retrieve data quickly as demand increases.
Decoupling for Boosted Scaling: Breaking down tightly integrated components to enable independent growth and reduce bottlenecks.
Scaling the Web Tier: Beyond Just Adding Servers
When it comes to scaling the web tier, we often hear about two approaches: Vertical Scaling and Horizontal Scaling. Vertical scaling is like upgrading your PC—more RAM, faster CPU, and extra storage. Simple, but limited. So, let’s shift our focus to the real star of the show: Horizontal Scaling.
Why Just Adding Servers Isn’t Enough
It’s easy to think horizontal scaling means just tossing in more servers when traffic spikes and pulling them back when it cools down. But nope, it’s not that simple. There are two major issues to tackle:
1. Stateful Web Tier and Sticky Sessions
Imagine this: A client sends a request, and a server responds. During this interaction, the server maintains state data (session data). This data includes everything from login credentials to user preferences, enhancing the user experience since the server “remembers” the client. This is called a Sticky Session because the client sticks to the same server throughout the session.
Now, here’s the problem. When you add or remove servers, how do you ensure the client still connects to the right one? Load balancers step in to distribute traffic, but transferring sessions between servers causes delays and complicates things. It’s like trying to switch bartenders mid-drink order—not ideal!
2. Consistent Hashing to the Rescue
To avoid the mess of sticky sessions, we can turn to a smarter strategy called Consistent Hashing. Think of it as assigning unique spots on a circular ring to servers. When a new server is added, only a small portion of requests need to be remapped, reducing disruption. This ensures smoother scaling without overwhelming the system.
3. Stateless Web Tier: The Game Changer
For an even cleaner solution, consider going stateless. Here, all session data is stored in a centralized storage system instead of the server. With no attachment to any particular server, clients can connect to any available one. The load balancer can then freely assign requests to the least busy server. Faster responses, easier scaling, and no session juggling — it’s a win-win!
Final Thoughts
Scaling the web tier is more than just multiplying servers. Addressing the challenges of sticky sessions with consistent hashing or going fully stateless can make scaling efficient and seamless. Now that we’ve tackled this, it’s time to dive deeper into the other pillars of scalability. Onward!
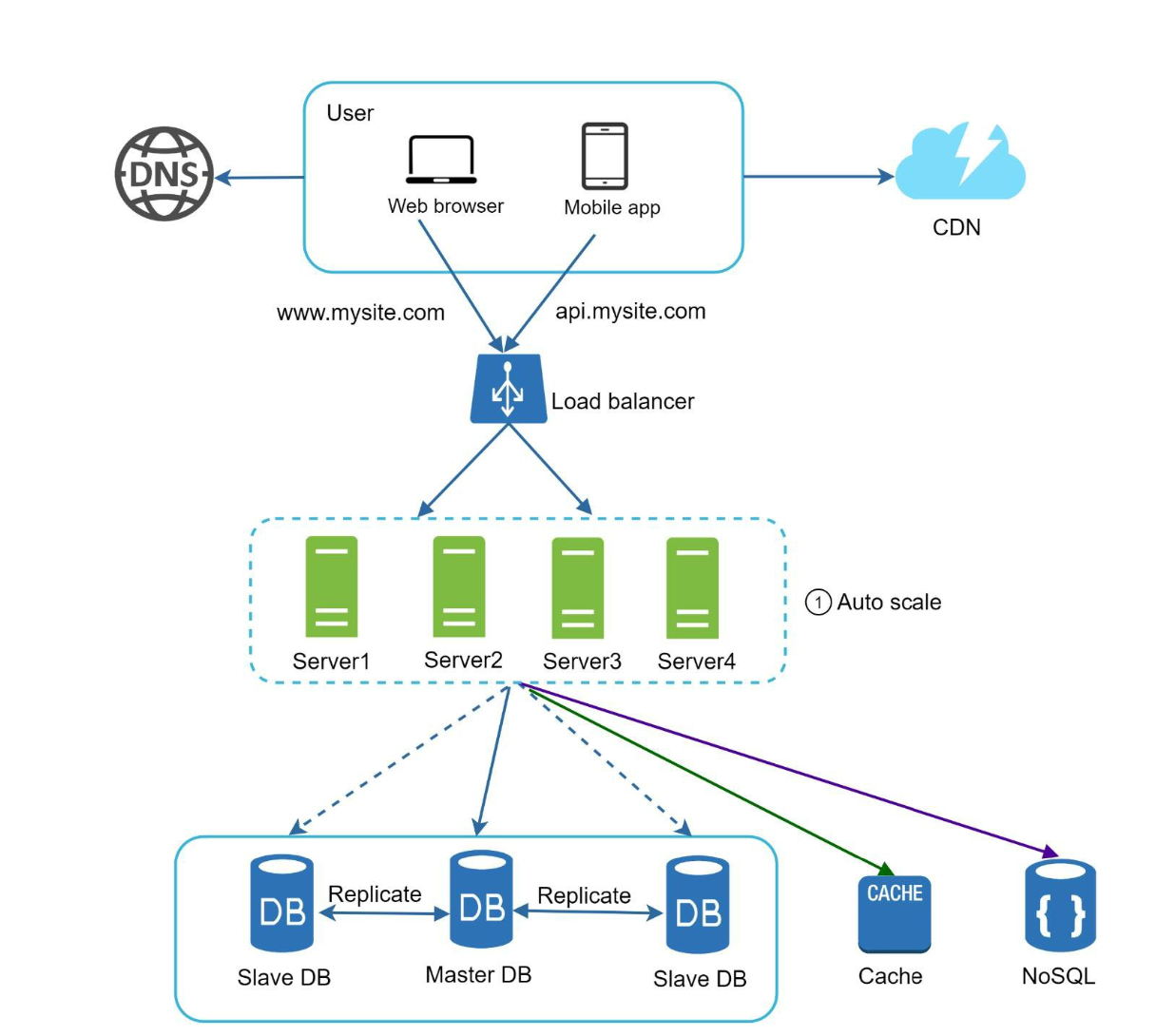
Data Tier Scaling: Distributing the Load Like a Pro
While vertical scaling is straightforward—adding more resources like CPU, RAM, or storage—it has its limits and can become costly. Horizontal scaling, on the other hand, is the real game-changer when it comes to data tier scaling.
But how do we scale horizontally in the data tier? Unlike web servers that scale based on user requests, the load on database servers is directly related to the amount of data they handle. The more data a server manages, the harder it works.
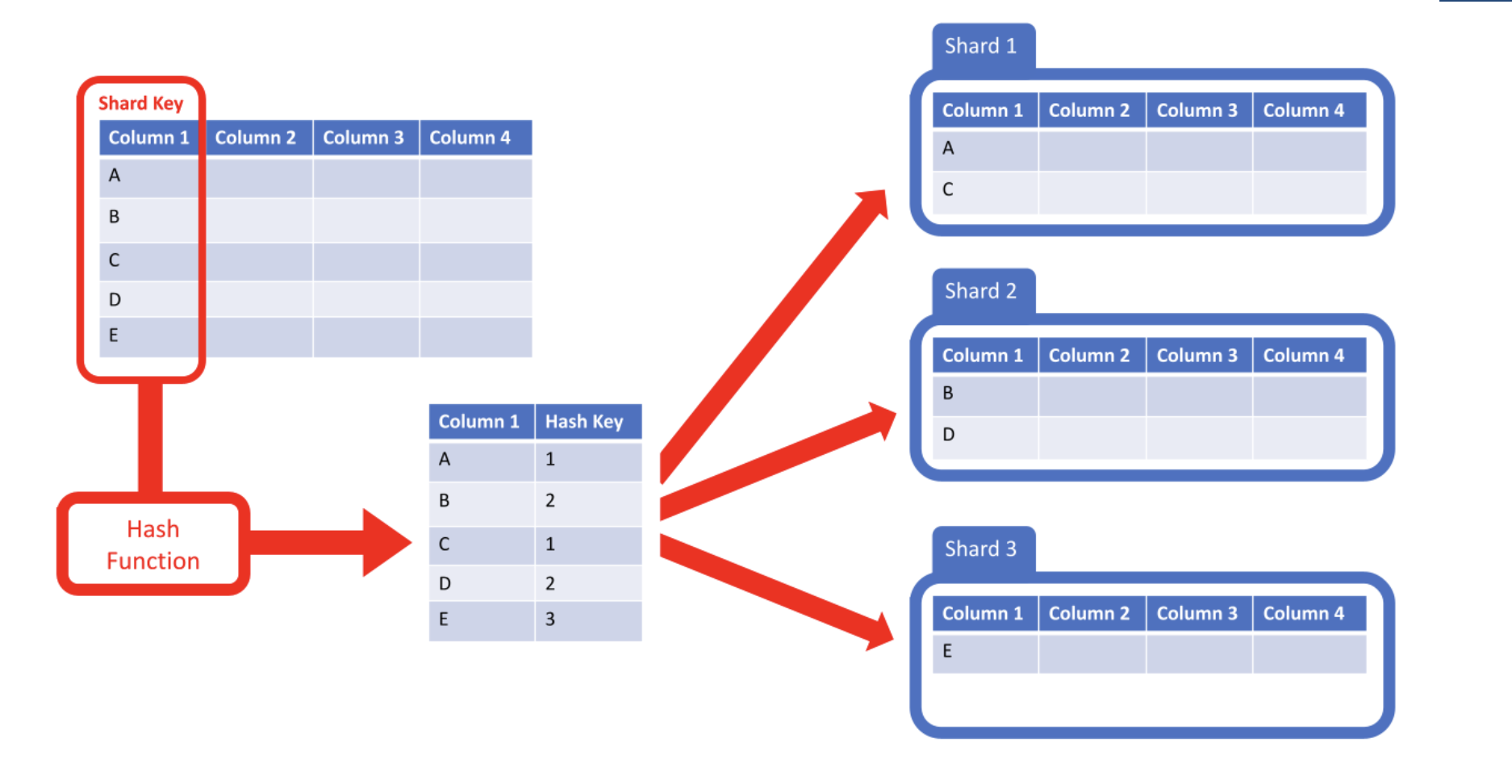
Enter Sharding: Divide and Conquer
The key to horizontal scaling is sharding. This means splitting large datasets into smaller, manageable pieces (called shards) and distributing them across multiple servers. This way, instead of one database server doing all the heavy lifting, the workload is spread out.
Choosing the Right Sharding Strategy
Picking the right sharding key is crucial. The sharding key determines how data is distributed, and a poor choice can lead to unbalanced shards, creating performance issues. Here are two popular sharding techniques:
Hash Sharding:
Best for write-intensive workloads.
Data is distributed using a hashing function, ensuring even distribution across shards.
Prevents hotspots, where one server handles a disproportionate load.
Range Sharding:
Best for read-intensive workloads.
Data is partitioned based on a defined range of values (e.g., customer IDs from 1-1000 on one shard, 1001-2000 on another).
Efficient for range queries but can lead to hotspots if certain ranges are queried more often.
Real-World Example: Avoiding Hotspots
Let’s say we run an e-commerce platform. Every time a customer places an order, we update the product inventory and trigger an email confirmation. We have a table with order_id and product_id.
Sharding by product_id: If one product becomes a best-seller, the shard containing that product data will experience a massive load, creating a hotspot.
Sharding by order_id: Since orders are typically more evenly distributed, using order_id as the sharding key ensures a balanced workload across multiple servers.
Ensuring Consistency and Availability
Once data is spread across shards, maintaining data consistency and high availability becomes essential. Techniques like replication ensure that copies of data exist on multiple servers, providing resilience in case of failures.
Final Thoughts
Horizontal scaling at the data tier is all about smart data distribution. By understanding your workload patterns and choosing the right sharding strategy, you can ensure your database remains scalable and responsive even as your user base grows. Ready to break free from data bottlenecks? Let’s keep scaling!
🎯 Checkpoint: You're Almost There!
Great job making it this far! By scaling both the web and data tiers, we've already improved our system's scalability by around 80%. That's a huge leap!
But wait — there's more. While tier-based scaling is a powerful move, making the entire system inherently scalable and robust requires an extra touch. This means working beyond just the tiers and focusing on how to design a system that welcomes growth with open arms.
Ready to level up? Let's explore how to build a system that’s not only scalable but also resilient, flexible, and ready to handle whatever comes its way.
Next up: Strategies to decouple and optimize, making your system scale like never before.
Enhancing Scalability Through Decoupling
Now that we’ve tackled web and data tier scaling, we’re already 80% ahead in making our system scalable. But achieving true scalability isn’t just about upgrading individual tiers — it’s about making the system itself more adaptable and resilient. So, let’s shift our focus to decoupling the system.
What is Decoupling?
When we hear the term decoupling, our minds often jump to microservices — and rightly so! Microservices involve breaking down the system into independent components that operate asynchronously. This separation allows services to scale independently and perform tasks in parallel. But how does this work in practice?
That’s where the concept of Message Queues comes in.
Producers, Consumers, and Message Queues
In a decoupled architecture, we have two main actors: Producers and Consumers. Producers generate tasks or events, while Consumers process those tasks. Think of it like a bustling restaurant kitchen — the chefs (Consumers) cook the food, while the waiters (Producers) take the orders.
Now, what happens when the kitchen gets overwhelmed with too many orders? Instead of forcing waiters to wait for chefs to catch up, we introduce a message queue — a holding area that temporarily stores orders (tasks) until the kitchen is ready. This acts as a buffer, preventing data loss and ensuring no request is dropped.
Why Not Just Use a Load Balancer?
You might be thinking — isn’t it the load balancer’s job to ensure requests are evenly distributed? (It's great if you are thinking that way.) Absolutely! But a load balancer can’t help if all the Consumers are maxed out. Without a queue, incoming requests would pile up and potentially get dropped. With a message queue, even if Consumers are busy, the system won’t lose track of tasks.
Real-World Example — Ordering Your Favorite Gadget
Imagine placing an order online for a cool new gadget. You click “Buy Now”, and several services spring into action.
Payment Service: Think of it as the cashier verifying your payment.
Inventory Service: The warehouse manager checks and updates the stock.
Email Notification Service: A cheerful assistant sends a confirmation email.
Now, without a message queue, each service would have to wait for the previous one to finish. But with a queue, once the payment is approved, a “Payment Successful” message is thrown into the queue.
The inventory service quickly shouts, “Reduce stock!”
The email service happily chirps, “Time to send that thank-you email!”
Both work at the same time without waiting on each other. It’s like a well-orchestrated dance.
And if something goes wrong? Say the inventory service crashes — no problem! The message queue acts like a reliable friend, calmly holding onto the task until the service is back up. The email service can still proceed without a hitch.
This asynchronous processing ensures efficiency, reliability, and no downtime. Using a message queue, services can listen for events such as "payment successful" or "payment failed" and respond accordingly. This approach follows an event-driven architecture. Every time you receive that “Order Confirmed!” email, just know a message queue was silently working behind the scenes, ensuring everything went smoothly.
That’s the beauty of decoupling with message queues — robust, resilient, and ready to scale.
Final Scalable Architecture Overview
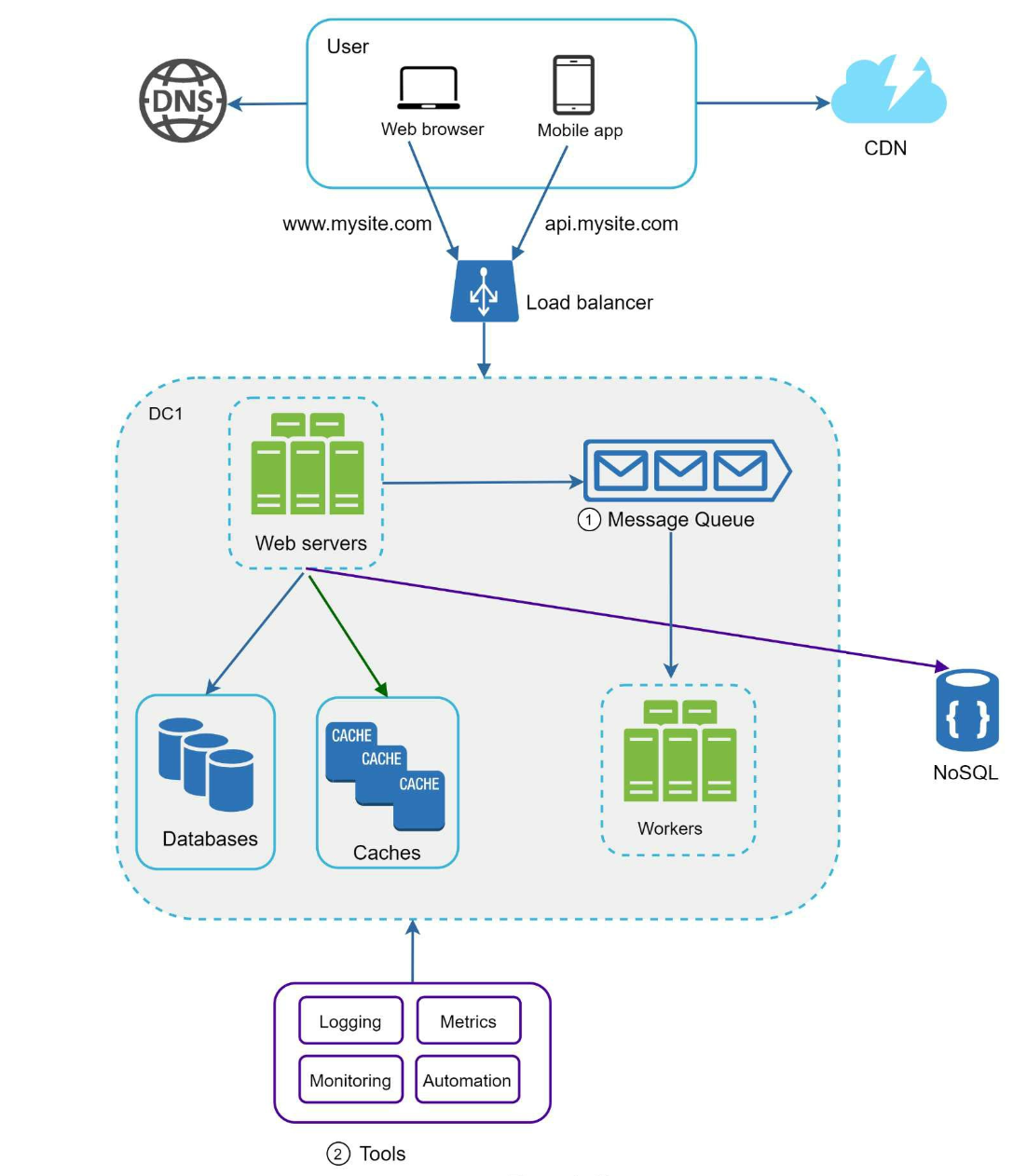
Conclusion: Celebrating the Path to Scalability
Congratulations on making it this far! You've navigated through the three pillars of achieving a scalable system: Web Tier Scaling, Data Tier Scaling, and Decoupling with Message Queues. Each layer plays a crucial role in ensuring your system can grow efficiently, handle large loads, and maintain seamless performance.
Web Tier Scaling: By effectively implementing horizontal scaling with the right load balancing strategies and managing state using stateless designs or external storage, you ensure that requests are handled swiftly and without interruptions.
Data Tier Scaling: Through intelligent sharding techniques and appropriate selection of shard keys, databases can distribute data evenly, balancing the load and enhancing both read and write operations.
Decoupling with Message Queues: Embracing event-driven architecture and leveraging message queues allows services to communicate asynchronously. This not only prevents data loss during peak loads but also ensures that failures in one component don’t bring down the entire system.
By mastering these principles, you're equipped to tackle real-world scaling challenges with confidence. Whether you're handling a surge of users on your platform or managing vast amounts of data, these scalable solutions will help your system remain robust and responsive.
Keep exploring, keep building, and remember — scalable systems are the backbone of every successful digital experience. Here's to building systems that grow as effortlessly as your ambitions!
