Hey, imagine you're binge-watching your favorite series on platforms like YouTube, Netflix, or Amazon Prime, and suddenly, bam—suggestions pop up for shows from creators you love, videos in the same style, or even ads for stuff that matches your vibe, all happening right as you're clicking around. That's the power of smart recommendations fueled by what you've watched before, the types of stories you dig, and how long you stick around. For companies, this info is like striking oil. But if you're the tech whiz behind it, the big question is: How do you handle this constant flood of valuable details without everything crashing?
Picture yourself stepping into the role of lead tech designer at a massive video service like YouTube. Your mission? Design a setup that grabs and sifts through an endless torrent of this precious information, keeping things smooth and responsive. That's when you lean on something called stream processing to make it all work.
Breaking Down Stream Processing
Let's chat about what stream processing really means. According to data expert Martin Kleppmann, it's all about this:
“Stream processing is a computing paradigm focused on continuously processing data as it is generated, rather than storing it first and processing it in batches. It allows systems to react to events in near real-time, enabling low-latency analytics, monitoring, and decision making. Stream processing systems ingest data streams, apply transformations or computations, and emit results while the input is still being produced.”
In simple terms, forget about piling up data and tackling it in one big overnight crunch. Instead, you jump on it immediately as it rolls in, making decisions and tweaks on the spot. Cool, right? But putting this into action? That's where a tool like Kafka Streams shines.
Getting to Know Kafka Streams
By the book, here's how it's described:
“Kafka Streams is a lightweight, Java-based library for building real-time, scalable stream processing applications that read from and write to Apache Kafka topics. It provides high-level abstractions for continuous processing such as filtering, mapping, grouping, windowing, and aggregations, while handling fault tolerance and state management internally.”
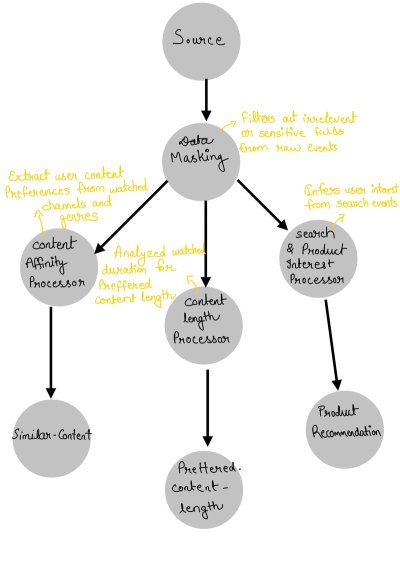
With the basics down—what we're aiming for and the toolkit at hand—let's think through constructing one of these data-handling pipelines.
NOTE: This is a simplified mental model to explain the role of stream processing and Kafka Streams, not an exact representation of YouTube’s internal architecture. A giant like YouTube uses multiple stream processors, batch + streaming, ML pipelines, feature stores, etc to provide a seamless user experience.
Diving Deeper into the Setup—from here, we'd explore building out the components, but let's keep it rolling with how this tech transforms everyday challenges into efficient solutions.