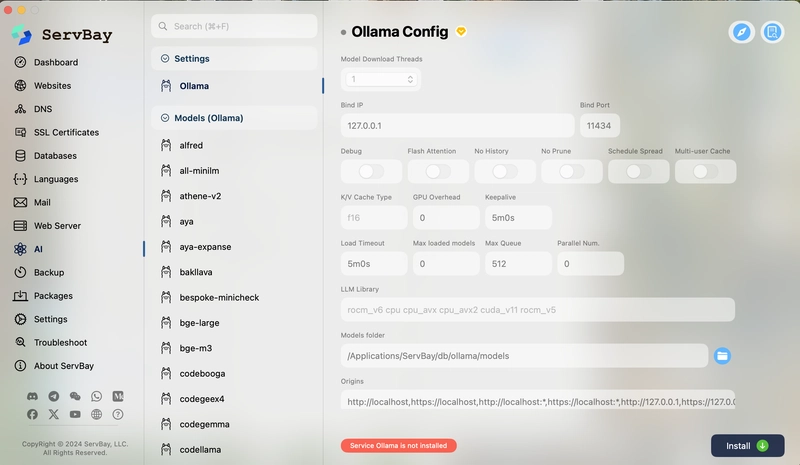
In today’s rapidly evolving AI landscape, many developers and organizations are seeking to deploy large language models (LLMs) securely, with low latency and full control. ServBay 1.12.0 introduces seamless one-click integration with the open-source project ’Ollama‘, transforming what used to be a complex command-line deployment into an intuitive GUI experience. This guide dives deep into the principles, best practices, and advanced optimizations for combining ServBay and Ollama, empowering you to build a production-ready local AI environment.
- Why Local AI?
Data Privacy & SecurityAll requests, logs, and training data remain on your own hardware, eliminating the risk of third-party breaches or unintended data sharing.
Millisecond-Level LatencyWith no network hops to the cloud, inference requests return in 10–50 ms, ideal for real-time applications like chatbots or interactive agents.
Predictable CostsOnce you invest in hardware, there are no per-call fees or unpredictable cloud billing spikes. You control your resource utilization.
Yet local deployment traditionally brings challenges: complex model installation, dependency conflicts, and resource scheduling headaches. ServBay × Ollama resolves these pain points with containerization, plug-and-play model management, and automated resource allocation.
- Architecture Overview
ServBay’s Containerized Service Management
Multi-Service Isolation ServBay is a development-environment management platform that supports the simultaneous operation of multiple languages and services—PHP, MySQL, Redis, and now Ollama’s model server—all within a unified interface, without relying on containerization.
Unified GUI Dashboard Start, stop, or inspect logs for any service with a single click. Monitor CPU, memory, and network usage in real time.
Ollama’s LLM Orchestration
Local Model Repository Ollama maintains a directory of downloaded models (e.g., Llama 3, Mistral, DeepSeek-R1), all stored on your machine.
Built-in Inference APILaunches a lightweight HTTP/gRPC server on install—no extra configuration required.
Automatic Resource AllocationDetects available GPUs and CPU cores, slicing memory so that multiple models coexist without stepping on each other.
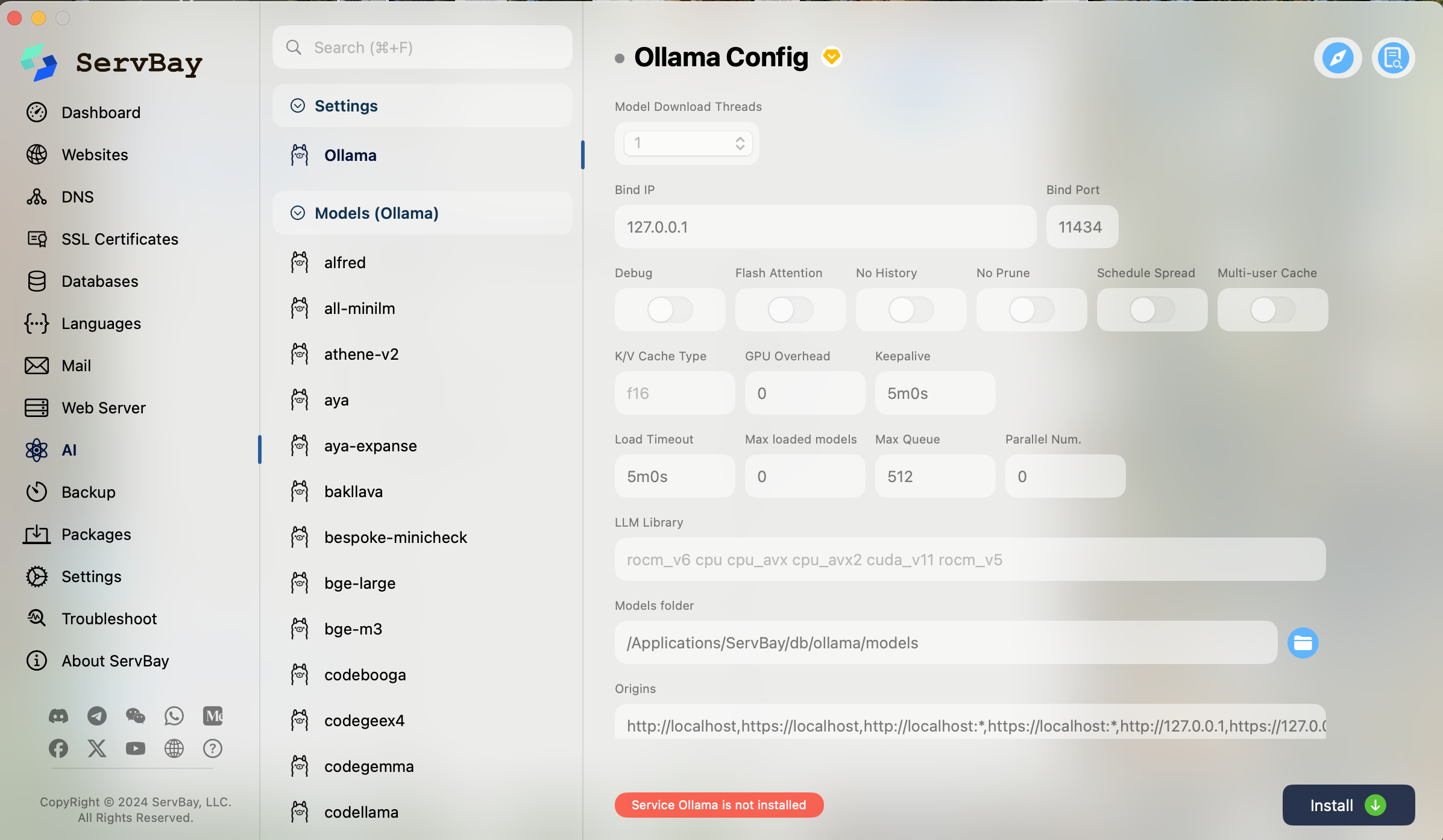
Together, ServBay’s GUI and Ollama’s CLI converge in a new “AI Models” panel, where you can browse, install, deploy, and invoke any supported LLM with zero manual setup.
- Updated “Quick Start in Three Steps”
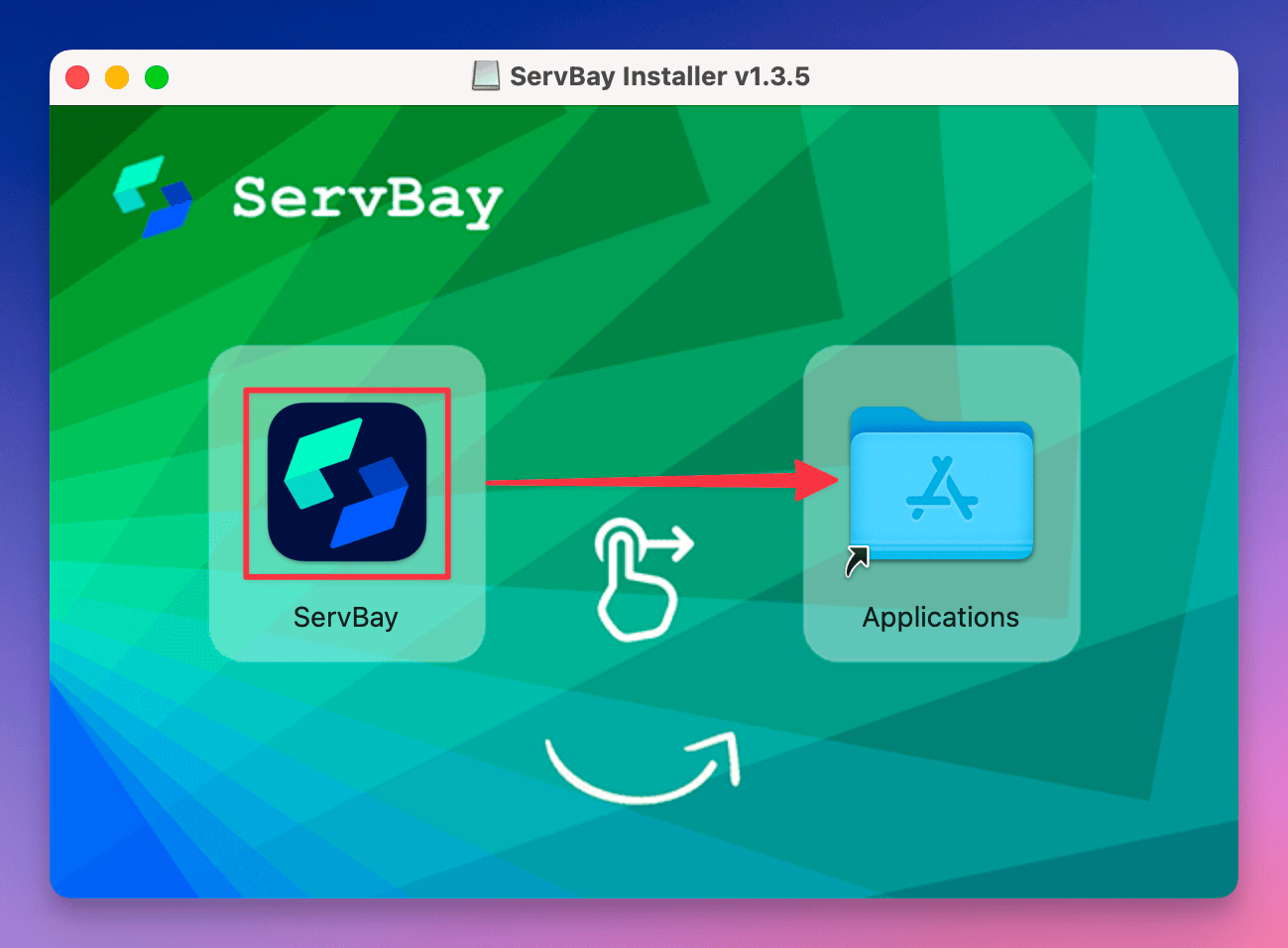
Download and Install ServBay
- Go to the ServBay official website and download the macOS installer.
- Open the installer and follow the on-screen prompts—no command-line required. Install Ollama
- Launch ServBay and navigate to Packages → AI.
- Locate Ollama and click Download. Deploy a Model
- Still under Packages → AI, find the Latest 8B model and click Deploy.
- ServBay will handle the setup automatically.
Congratulations—you now have a fully local AI service, with no cloud dependencies and total data sovereignty.
- Advanced Play & Optimization
Custom Models & Fine-Tuning
- Drop-in Your Own Models Ollama natively supports adding custom model checkpoints (e.g., Bloom, RWKV) by placing them into its local models directory. ServBay will detect any deployed models, but importing and managing these custom models must be done through Ollama’s CLI rather than via the ServBay interface.
- LoRA Micro-tuning Fine-tuning on small, domain-specific datasets is handled through Ollama’s LoRA scripts on the command line. This micro-tuning workflow isn’t exposed in ServBay’s GUI and must be executed directly with Ollama.
GPU Acceleration & Model Pruning
- Memory Sharding: Distribute a single model across multiple GPUs for maximal utilization.
- Quantization & Pruning: Convert weights to 8-bit or prune unimportant parameters with the Hugging Face transformers toolkit to boost throughput by 1.5×–2×.
- Real-World Use Cases

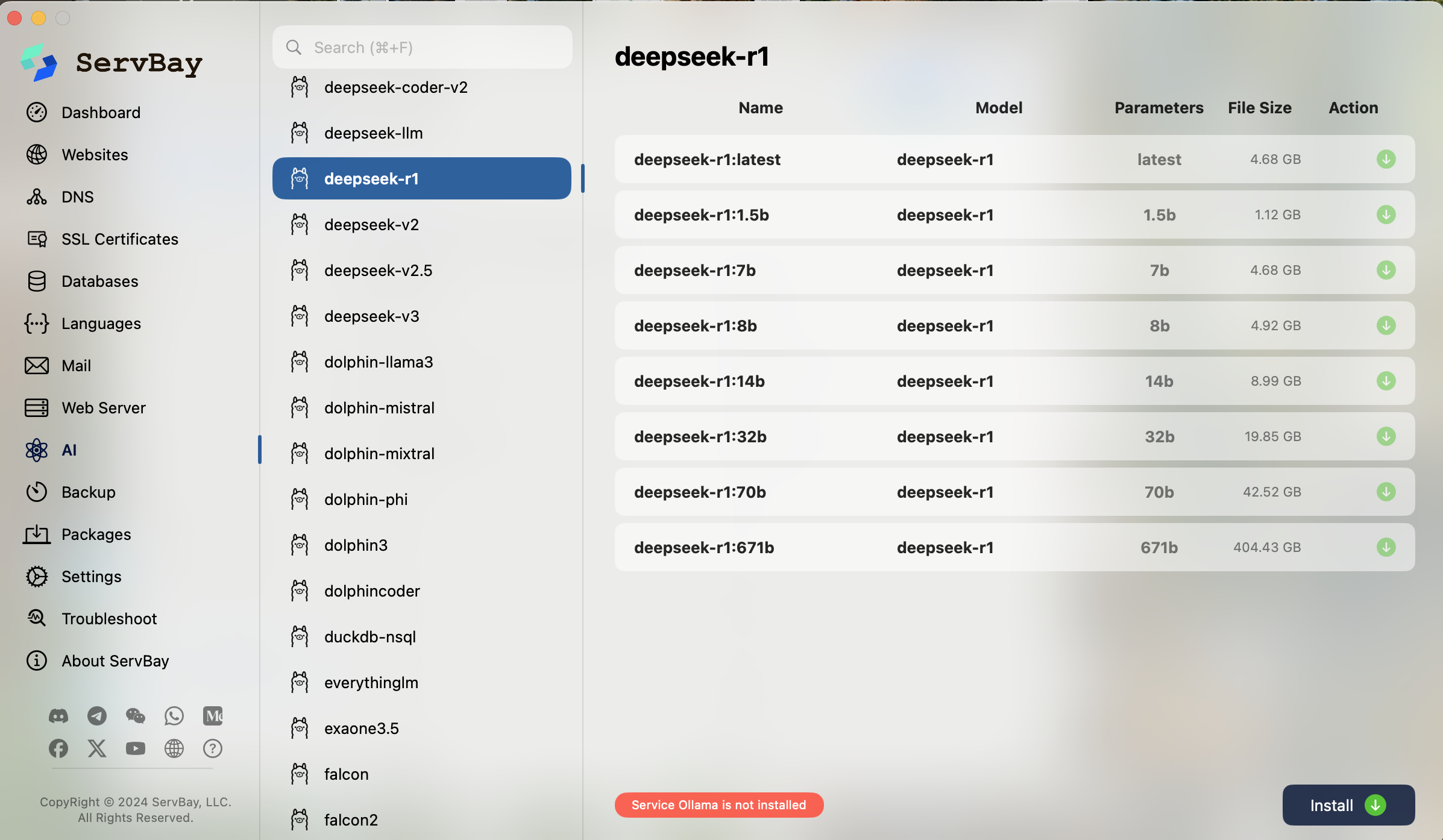
- Security & Distribution
Revised Security & Distribution Section (updated bullets only)
- Network Isolation ServBay isn’t container-based. Instead of exposing port 11434 directly, it provides a dedicated domain (https://ollama.servbay.host) for accessing your local Ollama API, keeping your model service safely encapsulated.
Fine-Grained Permissions
Control access to the Ollama executable and model files using your operating system’s file-permission mechanisms and user roles—ensuring only authorized accounts can read or run them.Version Control & Rollback:ServBay logs every model version you install. Instantly revert to a previous release from the dashboard.
- Cloud vs. Local AI: A Comparative Snapshot
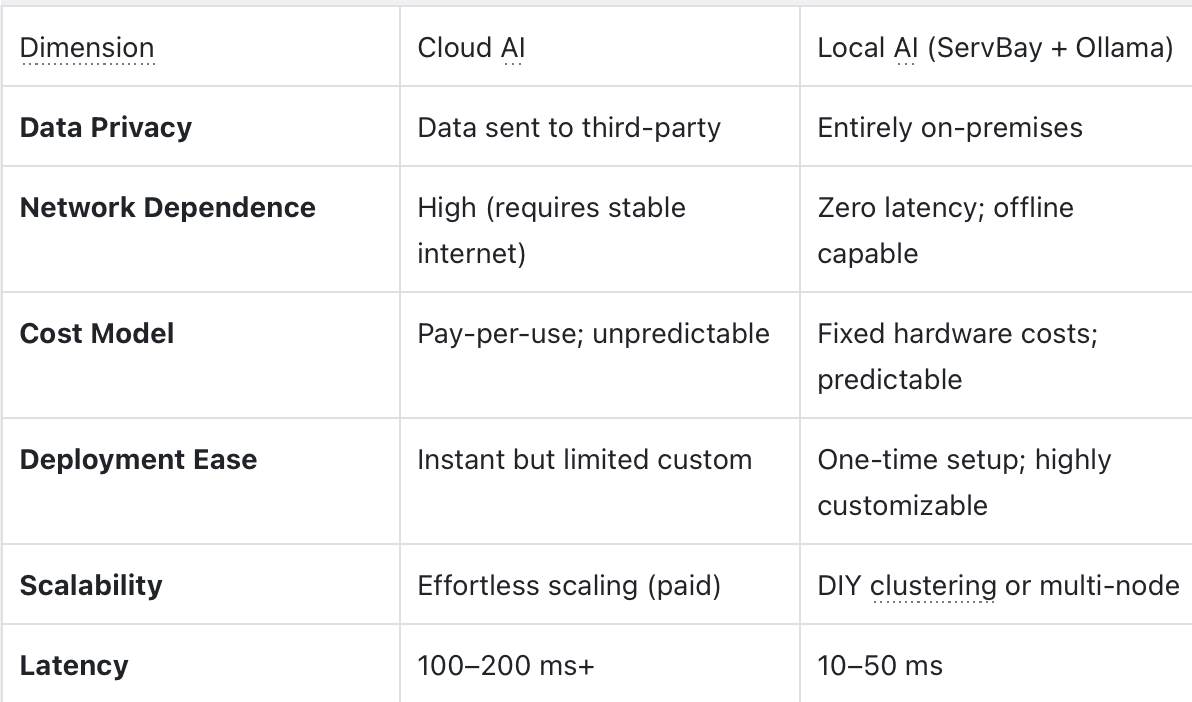
This comparison highlights why many enterprises prefer local AI for privacy, control, and cost stability—while ServBay × Ollama bridges the deployment gap with a polished GUI experience.
- Integration Examples
Web App Integration (Python)
import requests, json
response = requests.post(
"http://localhost:11434/v1/completions",
headers={"Content-Type": "application/json"},
json={
"model": "mistral-7b-instruct",
"prompt": "Generate an HTML template for a user registration page.",
"max_tokens": 200
}
)
print(response.json()["choices"][0]["text"])- Performance Benchmarks & Tips
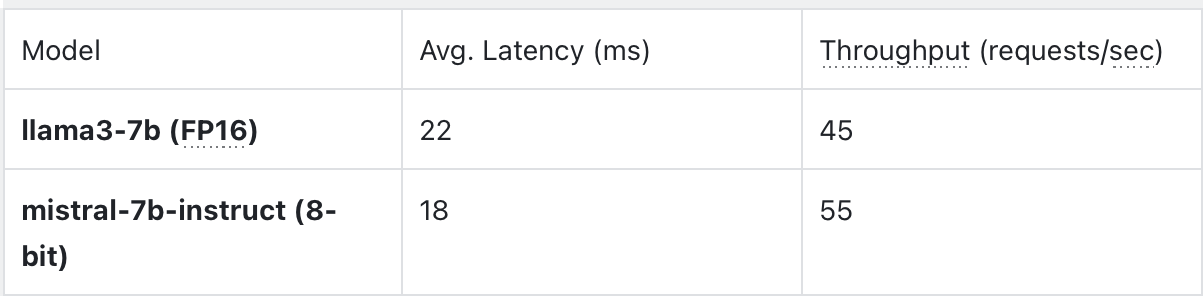
Optimization Strategies:
- Quantize to 8-bit first for general-purpose inference.
- Shard across GPUs when running multiple large models simultaneously.
- Parallelize on CPU if GPU isn’t available—spawn multiple Ollama workers.
- ServBay & Ollama Community Ecosystem
-
ServBay Community
- Official docs, tutorials, and an upcoming plugin marketplace for environment scripts and dashboard extensions.
- GitHub issues are actively managed with a typical response time under 24 hours.
-
Ollama Open-Source Hub
- Expanding model catalog, now featuring dozens of popular LLMs.
- Regular updates with quantization, pruning, and fine-tuning utilities.
Together, these vibrant communities ensure you stay on the cutting edge of local AI innovations.
FAQ
-
What if I hit GPU memory limits?
- Enable 8-bit quantization, reduce parallel requests, or shard across multiple GPUs.
-
How do I share my local AI on the LAN?
- Enable port mapping in ServBay’s network settings and share the host port.
Conclusion: Your Local AI Frontier
From privacy and latency benefits to advanced optimizations and community support, ServBay × Ollama delivers the end-to-end tooling to make local AI accessible, secure, and high-performance. Upgrade to ServBay 1.12.0 now and unlock effortless, zero-code AI deployment—empowering your projects with blazing performance and absolute data control.