A reflection on vector databases and their usage by LLMs, by implementing a rudimentary one!
Introduction
TLDR;
Vector databases have emerged as a critical infrastructure component in the era of Large Language Models (LLMs). Traditional databases, designed for structured data and exact keyword matching, fall short when dealing with the nuanced, high-dimensional data that LLMs process and generate. LLMs excel at understanding the semantic meaning of text and other data types, transforming them into dense vector embeddings that capture these relationships. Vector databases are specifically engineered to store, index, and efficiently query these complex vector embeddings.
The necessity of vector databases for LLMs stems from the following key reasons:
- Semantic Understanding: LLMs convert text, images, audio, and other unstructured data into vector embeddings, which numerically represent the meaning and context of the data. Vector databases provide a way to store and retrieve these embeddings based on semantic similarity, enabling LLMs to understand the relationships between different pieces of information.
- Efficient Similarity Search: LLM applications often require finding information that is semantically similar to a query. Vector databases are optimized for performing fast and accurate similarity searches across large volumes of high-dimensional vectors, a task that traditional databases struggle with.
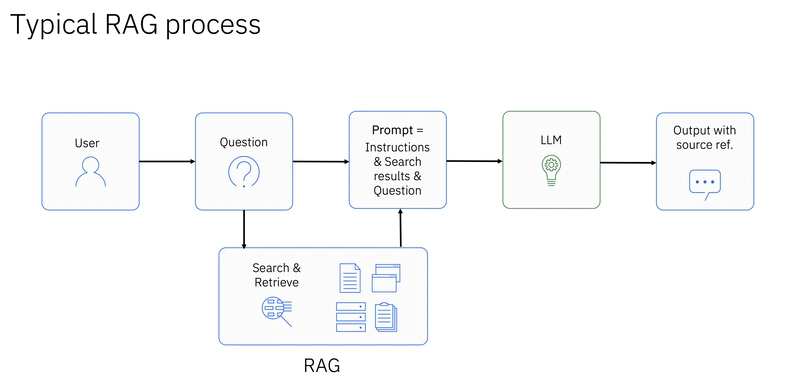
- Extending LLM Knowledge with External Data (RAG): A significant use case is Retrieval-Augmented Generation (RAG). LLMs have broad general knowledge from their training data, but they might lack specific or up-to-date information. By integrating LLMs with vector databases containing embeddings of domain-specific knowledge, relevant context can be retrieved and provided to the LLM before generating a response. This significantly improves the accuracy and relevance of the LLM’s output and mitigates the issue of “hallucinations.”
- Handling Unstructured Data: LLMs are adept at processing unstructured data. Vector databases provide a mechanism to store and query the vector representations of this unstructured data, allowing LLMs to work with and reason over diverse data formats effectively.
- Scalability and Performance: As the amount of data processed by LLMs grows, the underlying infrastructure needs to scale efficiently. Vector databases are designed to handle large datasets of vector embeddings and provide low-latency retrieval, which is crucial for real-time LLM applications.
In essence, vector databases act as a specialized memory and retrieval system for LLMs, enabling them to access and utilize vast amounts of information in a semantically meaningful and efficient way. This synergy unlocks a wide range of advanced AI applications, from enhanced search and question answering to personalized recommendations and sophisticated content generation.
Sources: Cisco, Jfrog, snowflake, aws and IBM 👍 (for example, refer to “What is vector embedding?”)
And RAG in all this?
A vector database is a crucial component in a Retrieval-Augmented Generation (RAG) system, acting as the knowledge repository that enhances the capabilities of Large Language Models (LLMs). Here’s how it’s used:
- Knowledge Encoding and Storage:
- Data Ingestion: External documents, articles, FAQs, or any relevant knowledge source are ingested into the RAG system.
- Chunking: Large documents are typically split into smaller, manageable chunks to improve retrieval granularity and efficiency.
- Embedding Generation: Each chunk of text (and sometimes other data types like images) is passed through an embedding model. This model converts the text into a high-dimensional vector embedding, capturing its semantic meaning. Similar concepts will have closer vectors in the vector space.
- Vector Storage: These generated vector embeddings, along with their corresponding text chunks (and potentially metadata like source and page number), are stored in the vector database. The vector database is specifically designed for efficient storage and indexing of these high-dimensional vectors.
- Information Retrieval during Querying:
- Query Embedding: When a user poses a question or provides a query to the LLM-powered application, this query is also passed through the same embedding model used for the knowledge base. This generates a vector embedding of the user’s intent.
- Similarity Search: The query vector is then used to perform a similarity search within the vector database. The database employs efficient indexing techniques (like Approximate Nearest Neighbors — ANN) to quickly find the stored vector embeddings that are most similar to the query vector based on a distance metric (e.g., cosine similarity, Euclidean distance).
- Context Retrieval: The text chunks associated with the top-k most similar vector embeddings are retrieved from the vector database. These chunks represent the pieces of knowledge that are most semantically relevant to the user’s query.
- Augmenting the LLM for Response Generation:
- Contextualization: The retrieved text chunks are added to the original user query as context within the prompt that is fed to the LLM. This process is often facilitated by prompt engineering techniques to guide the LLM on how to utilize the provided context.
- Enhanced Generation: The LLM then uses both its pre-trained knowledge and the retrieved contextual information to generate a more accurate, relevant, and grounded response to the user’s query. By having access to the specific knowledge from the vector database, the LLM can provide answers that go beyond its general training data and are tailored to the user’s question and the available information.
- In essence, the vector database acts as an efficient and semantically aware external memory for the LLM in a RAG system. It allows the LLM to access and leverage a vast amount of domain-specific or up-to-date information that it was not trained on, leading to more knowledgeable and reliable AI applications.
Sources: the same mentioned above…
Implementation of my tiny vector DB
As always I like to develop my own stuff to understand technical stuff (actually if it’s possible) and also to have some fun as a geeky person😉!
So finally I had some time to realise my own vector DB!
Disclaimer: very rudimentary code with lots of shortcomings! 🫨

- Here goes the code of my implementation in Typescript ⬇️
// server.ts
import express, { Request, Response, NextFunction, Router } from 'express';
import cors from 'cors';
class VectorDB {
private data: Map<string, number[]>;
constructor() {
this.data = new Map<string, number[]>();
}
private cosineSimilarity(vector1: number[], vector2: number[]): number {
if (vector1.length !== vector2.length) {
throw new Error('Vectors must have the same dimensions.');
}
let dotProduct = 0;
let magnitude1 = 0;
let magnitude2 = 0;
for (let i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
magnitude1 += vector1[i] * vector1[i];
magnitude2 += vector2[i] * vector2[i];
}
magnitude1 = Math.sqrt(magnitude1);
magnitude2 = Math.sqrt(magnitude2);
if (magnitude1 === 0 || magnitude2 === 0) {
return 0;
}
return dotProduct / (magnitude1 * magnitude2);
}
addVector(id: string, vector: number[]): void {
this.data.set(id, vector);
}
getVector(id: string): number[] | undefined {
return this.data.get(id);
}
deleteVector(id: string): boolean {
return this.data.delete(id);
}
query(queryVector: number[], k: number): { id: string; similarity: number; vector: number[] }[] {
if (k > this.data.size) {
throw new Error(`k (${k}) cannot be greater than the number of vectors in the database (${this.data.size}).`);
}
const results: { id: string; similarity: number; vector: number[] }[] = [];
this.data.forEach((vector, id) => {
const similarity = this.cosineSimilarity(queryVector, vector);
results.push({ id, similarity, vector });
});
results.sort((a, b) => b.similarity - a.similarity);
return results.slice(0, k);
}
get size(): number {
return this.data.size;
}
}
const app = express();
const port = 3000;
app.use(cors());
app.use(express.json());
const db = new VectorDB();
app.get('/health', (req: Request, res: Response) => {
res.status(200).send('OK');
});
const postVectorHandler: express.RequestHandler = (
req: express.Request,
res: express.Response,
next: express.NextFunction,
) => {
const { id, vector } = req.body;
if (!id || !vector || !Array.isArray(vector)) {
res.status(400).json({ error: 'Invalid request.' });
return;
}
try {
db.addVector(id, vector);
res.status(201).json({ message: 'Vector added.' });
} catch (error: any) {
res.status(500).json({ error: `Error: ${error.message}` });
}
};
app.post('/vector', postVectorHandler);
app.get('/vector/:id', (req: express.Request, res: express.Response) => {
const { id } = req.params;
const vector = db.getVector(id);
if (vector) {
res.status(200).json({ id: id, vector: vector });
} else {
res.status(404).json({ error: 'Vector not found.' });
}
});
app.delete('/vector/:id', (req: express.Request, res: express.Response) => {
const { id } = req.params;
const deleted = db.deleteVector(id);
if (deleted) {
res.status(200).json({ message: 'Vector deleted.' });
} else {
res.status(404).json({ error: 'Vector not found.' });
}
});
const postQueryHandler: express.RequestHandler = (
req: express.Request,
res: express.Response,
next: express.NextFunction,
) => {
const { queryVector, k } = req.body;
if (!queryVector || !Array.isArray(queryVector) || typeof k !== 'number') {
res.status(400).json({ error: 'Invalid request.' });
return;
}
try {
const results = db.query(queryVector, k);
res.status(200).json(results); /
} catch (error: any) {
res.status(500).json({ error: `Query error: ${error.message}` });
}
};
app.post('/query', postQueryHandler);
app.get('/size', (req: express.Request, res: express.Response) => {
res.status(200).json({ size: db.size });
});
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
});- Client code with hard-coded information.
// client.ts
import axios from 'axios';
const SERVER_URL = 'http://localhost:3000'; // Replace with your server URL if different
async function addVector(id: string, vector: number[]): Promise<void> {
try {
const response = await axios.post(`${SERVER_URL}/vector`, { id, vector });
console.log('Add Vector:', response.data);
} catch (error: any) {
console.error('Error adding vector:', error.response?.data || error.message);
throw error; // Re-throw to allow further handling if needed
}
}
async function getVector(id: string): Promise<number[] | null> {
try {
const response = await axios.get(`${SERVER_URL}/vector/${id}`);
console.log('Get Vector:', response.data);
return response.data.vector;
} catch (error: any) {
if (error.response?.status === 404) {
console.log(`Vector with id "${id}" not found.`);
return null;
}
console.error('Error getting vector:', error.response?.data || error.message);
throw error;
}
}
async function deleteVector(id: string): Promise<void> {
try {
const response = await axios.delete(`${SERVER_URL}/vector/${id}`);
console.log('Delete Vector:', response.data);
} catch (error: any) {
console.error('Error deleting vector:', error.response?.data || error.message);
throw error;
}
}
async function query(queryVector: number[], k: number): Promise<{ id: string; similarity: number; vector: number[] }[]> {
try {
const response = await axios.post(`${SERVER_URL}/query`, { queryVector, k });
console.log('Query:', response.data);
return response.data;
} catch (error: any) {
console.error('Error querying:', error.response?.data || error.message);
throw error;
}
}
async function getSize(): Promise<number> {
try {
const response = await axios.get(`${SERVER_URL}/size`);
console.log('Size:', response.data);
return response.data.size;
} catch (error: any) {
console.error('Error getting size:', error.response?.data || error.message);
throw error;
}
}
async function healthCheck(): Promise<string> {
try {
const response = await axios.get(`${SERVER_URL}/health`);
console.log('Health Check:', response.data);
return response.data;
} catch (error: any) {
console.error('Health Check Failed:', error.response?.data || error.message);
throw error;
}
}
async function main() {
try {
const health = await healthCheck();
console.log(`Server Health: ${health}`);
// Add some vectors
await addVector('v1', [1, 2, 3]);
await addVector('v2', [4, 5, 6]);
await addVector('v3', [1, 1, 1]);
// Get size
const size = await getSize();
console.log(`Database Size: ${size}`);
// Get a vector
const vector1 = await getVector('v1');
console.log('Retrieved vector v1:', vector1);
// Delete a vector
await deleteVector('v2');
const sizeAfterDelete = await getSize();
console.log(`Database Size after delete: ${sizeAfterDelete}`);
// Query
const results = await query([2, 3, 4], 2);
console.log('Query results:', results);
// Get non-existing vector
const nonExistentVector = await getVector('nonexistent');
console.log('Non-existent vector:', nonExistentVector);
} catch (error) {
console.error('An error occurred:', error);
}
}
main();- The simple output.
Health Check: OK
Server Health: OK
Add Vector: { message: 'Vector added.' }
Add Vector: { message: 'Vector added.' }
Add Vector: { message: 'Vector added.' }
Size: { size: 12 }
Database Size: 12
Get Vector: { id: 'v1', vector: [ 1, 2, 3 ] }
Retrieved vector v1: [ 1, 2, 3 ]
Delete Vector: { message: 'Vector deleted.' }
Size: { size: 11 }
Database Size after delete: 11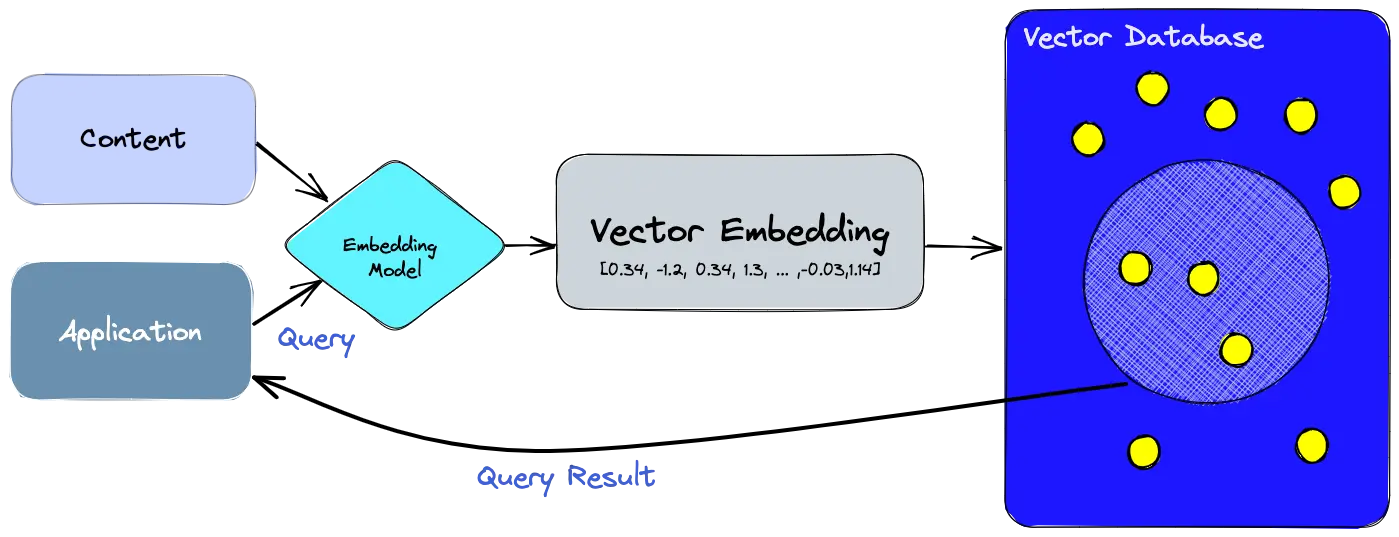
- And the client code with an input;
// client.ts
import * as express from 'express';
import { Request, Response, NextFunction } from 'express';
import * as cors from 'cors';
import * as fs from 'fs';
import * as readline from 'readline';
import axios from 'axios';
const SERVER_URL = 'http://localhost:3000';
// Function to simulate vectorization of text.
function vectorizeText(text: string, expectedDimension: number | null): number[] {
const vector = text.split('').map(char => char.charCodeAt(0));
const maxCharCode = 127;
const normalizedVector = vector.map(code => code / maxCharCode);
const fixedSize = expectedDimension !== null ? expectedDimension : 100;
if (normalizedVector.length < fixedSize) {
const padding = Array(fixedSize - normalizedVector.length).fill(0);
return normalizedVector.concat(padding);
} else if (normalizedVector.length > fixedSize) {
return normalizedVector.slice(0, fixedSize);
}
return normalizedVector;
}
async function addVector(id: string, vector: number[]): Promise<void> {
try {
console.log(`Adding vector with id: ${id} and length: ${vector.length}`);
const response = await axios.post(`${SERVER_URL}/vector`, { id, vector });
console.log('Add Vector:', response.data);
} catch (error: any) {
console.error('Error adding vector:', error.response?.data || error.message);
throw error;
}
}
async function getVector(id: string): Promise<number[] | null> {
try {
const response = await axios.get(`${SERVER_URL}/vector/${id}`);
console.log('Get Vector:', response.data);
return response.data.vector;
} catch (error: any) {
if (error.response?.status === 404) {
console.log(`Vector with id "${id}" not found.`);
return null;
}
console.error('Error getting vector:', error.response?.data || error.message);
throw error;
}
}
async function deleteVector(id: string): Promise<void> {
try {
const response = await axios.delete(`${SERVER_URL}/vector/${id}`);
console.log('Delete Vector:', response.data);
} catch (error: any) {
console.error('Error deleting vector:', error.response?.data || error.message);
throw error;
}
}
async function query(queryVector: number[], k: number): Promise<{ id: string; similarity: number; vector: number[] }[]> {
try {
console.log(`Querying with vector of length: ${queryVector.length} and k: ${k}`);
const response = await axios.post(`${SERVER_URL}/query`, { queryVector, k });
console.log('Query:', response.data);
return response.data;
} catch (error: any) {
console.error('Error querying:', error.response?.data || error.message);
throw error;
}
}
async function getSize(): Promise<number> {
try {
const response = await axios.get(`${SERVER_URL}/size`);
console.log('Size:', response.data);
return response.data.size;
} catch (error: any) {
console.error('Error getting size:', error.response?.data || error.message);
throw error;
}
}
async function healthCheck(): Promise<string> {
try {
const response = await axios.get(`${SERVER_URL}/health`);
console.log('Health Check:', response.data);
return response.data;
} catch (error: any) {
console.error('Health Check Failed:', error.response?.data || error.message);
throw error;
}
}
async function main() {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
try {
// Health Check
const health = await healthCheck();
console.log(`Server Health: ${health}`);
rl.question('Enter the path to your text file: ', async (filePath) => {
try {
const text = fs.readFileSync(filePath, 'utf-8');
console.log(`Read ${text.length} characters from ${filePath}`);
const initialVector = vectorizeText(text, null); // Get the initial vector
const vectorId = `file_vector_${Date.now()}`;
await addVector(vectorId, initialVector);
// Get size *after* adding the vector
const size = await getSize();
console.log(`Database Size: ${size}`);
const retrievedVector = await getVector(vectorId);
console.log("Retrieved Vector: ", retrievedVector);
// Perform a query. Use the *current* size of the database.
const queryResult = await query(initialVector, size);
console.log("Query result: ", queryResult);
rl.close();
} catch (err: any) {
console.error('Error processing file:', err.message);
rl.close();
}
});
} catch (error: any) {
console.error('An error occurred:', error);
rl.close();
}
}
main();- To test this, as entry I gave a simple “readme.txt” from the “httrack” tool (which is not relevant at all to this post but it was a text file I had in reach 😂).
- The output (containing errors regarding the dimensions…) is below.
Health Check: OK
Server Health: OK
Enter the path to your text file: ./input/readme.txt
Read 587 characters from ./input/readme.txt
Adding vector with id: file_vector_1745999287921 and length: 100
Add Vector: { message: 'Vector added.' }
Size: { size: 11 }
Database Size: 11
Get Vector: {
id: 'file_vector_1745999287921',
vector: [
0.6850393700787402, 0.8188976377952756, 0.7637795275590551,
0.9133858267716536, 0.30708661417322836, 0.905511811023622,
0.25196850393700787, 0.8267716535433071, 0.8661417322834646,
0.25196850393700787, 0.9133858267716536, 0.8188976377952756,
0.8267716535433071, 0.905511811023622, 0.25196850393700787,
0.8031496062992126, 0.8740157480314961, 0.8503937007874016,
0.7874015748031497, 0.7952755905511811, 0.8976377952755905,
0.49606299212598426, 0.07874015748031496, 0.07874015748031496,
0.6614173228346457, 0.8188976377952756, 0.8267716535433071,
0.905511811023622, 0.25196850393700787, 0.8031496062992126,
0.8740157480314961, 0.8503937007874016, 0.7874015748031497,
0.7952755905511811, 0.8976377952755905, 0.25196850393700787,
0.31496062992125984, 0.8188976377952756, 0.9133858267716536,
0.905511811023622, 0.3543307086614173, 0.7795275590551181,
0.7637795275590551, 0.7795275590551181, 0.8188976377952756,
0.7952755905511811, 0.3228346456692913, 0.25196850393700787,
0.8188976377952756, 0.7637795275590551, 0.905511811023622,
0.25196850393700787, 0.7716535433070866, 0.7952755905511811,
0.7952755905511811, 0.8661417322834646, 0.25196850393700787,
0.8110236220472441, 0.7952755905511811, 0.8661417322834646,
0.7952755905511811, 0.8976377952755905, 0.7637795275590551,
0.9133858267716536, 0.7952755905511811, 0.7874015748031497,
0.25196850393700787, 0.7716535433070866, 0.952755905511811,
0.25196850393700787, 0.6850393700787402, 0.8267716535433071,
0.8661417322834646, 0.5669291338582677, 0.6614173228346457,
0.6614173228346457, 0.8976377952755905, 0.7637795275590551,
0.7795275590551181, 0.84251968503937, 0.25196850393700787,
0.4015748031496063, 0.36220472440944884, 0.4094488188976378,
0.44881889763779526, 0.3543307086614173, 0.3937007874015748,
0.07874015748031496, 0.7637795275590551, 0.8661417322834646,
0.7874015748031497, 0.25196850393700787, 0.8267716535433071,
0.905511811023622, 0.25196850393700787, 0.9212598425196851,
0.905511811023622, 0.7952755905511811, 0.7874015748031497,
0.25196850393700787
]
}
Retrieved Vector: [
0.6850393700787402, 0.8188976377952756, 0.7637795275590551,
0.9133858267716536, 0.30708661417322836, 0.905511811023622,
0.25196850393700787, 0.8267716535433071, 0.8661417322834646,
0.25196850393700787, 0.9133858267716536, 0.8188976377952756,
0.8267716535433071, 0.905511811023622, 0.25196850393700787,
0.8031496062992126, 0.8740157480314961, 0.8503937007874016,
0.7874015748031497, 0.7952755905511811, 0.8976377952755905,
0.49606299212598426, 0.07874015748031496, 0.07874015748031496,
0.6614173228346457, 0.8188976377952756, 0.8267716535433071,
0.905511811023622, 0.25196850393700787, 0.8031496062992126,
0.8740157480314961, 0.8503937007874016, 0.7874015748031497,
0.7952755905511811, 0.8976377952755905, 0.25196850393700787,
0.31496062992125984, 0.8188976377952756, 0.9133858267716536,
0.905511811023622, 0.3543307086614173, 0.7795275590551181,
0.7637795275590551, 0.7795275590551181, 0.8188976377952756,
0.7952755905511811, 0.3228346456692913, 0.25196850393700787,
0.8188976377952756, 0.7637795275590551, 0.905511811023622,
0.25196850393700787, 0.7716535433070866, 0.7952755905511811,
0.7952755905511811, 0.8661417322834646, 0.25196850393700787,
0.8110236220472441, 0.7952755905511811, 0.8661417322834646,
0.7952755905511811, 0.8976377952755905, 0.7637795275590551,
0.9133858267716536, 0.7952755905511811, 0.7874015748031497,
0.25196850393700787, 0.7716535433070866, 0.952755905511811,
0.25196850393700787, 0.6850393700787402, 0.8267716535433071,
0.8661417322834646, 0.5669291338582677, 0.6614173228346457,
0.6614173228346457, 0.8976377952755905, 0.7637795275590551,
0.7795275590551181, 0.84251968503937, 0.25196850393700787,
0.4015748031496063, 0.36220472440944884, 0.4094488188976378,
0.44881889763779526, 0.3543307086614173, 0.3937007874015748,
0.07874015748031496, 0.7637795275590551, 0.8661417322834646,
0.7874015748031497, 0.25196850393700787, 0.8267716535433071,
0.905511811023622, 0.25196850393700787, 0.9212598425196851,
0.905511811023622, 0.7952755905511811, 0.7874015748031497,
0.25196850393700787
]
Querying with vector of length: 100 and k: 11
Error querying: { error: 'Query error: Vectors must have the same dimensions.' }Conclusion
👨🚀 Exploring the landscape of open-source vector databases and their implementations on platforms like GitHub 📃 has proven invaluable in demystifying the process of information vectorization and its powerful synergy with Large Language Models. Witnessing firsthand how different projects tackle the challenges of embedding, storing, and querying high-dimensional data has illuminated the practical applications and underlying mechanisms that drive semantic understanding in AI systems.
Stay tuned for more insights as this exploration continues!
