This is a Plain English Papers summary of a research paper called VisuoThink: Visual-Text AI Beats Reasoning Limits with Multimodal Tree Search. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: Combining Vision and Language for Better AI Reasoning
Recent advancements in Large Vision-Language Models (LVLMs) have shown remarkable progress across various tasks. However, these models often struggle with complex reasoning challenges that humans typically solve using visual aids and step-by-step thinking. While humans naturally sketch auxiliary lines or visualize intermediate steps when solving geometry problems, current AI approaches fall short of replicating this integrated visual-verbal reasoning process.
Existing methods have explored either text-based slow thinking or rudimentary visual assistance, but they fail to capture the interleaved nature of human visual-verbal reasoning. Text-only approaches treat visual information merely as static input, while visual assistance methods like VisualSketchpad and VoT mainly focus on single-step assistance or simplified visual hints.
To address these limitations, researchers introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking through two key innovations:
- A step-by-step vision-text interleaved reasoning framework that dynamically utilizes multi-step visual aids from tool use
- A look-ahead tree search algorithm that explores multiple reasoning paths, enabling test-time scaling of the reasoning process
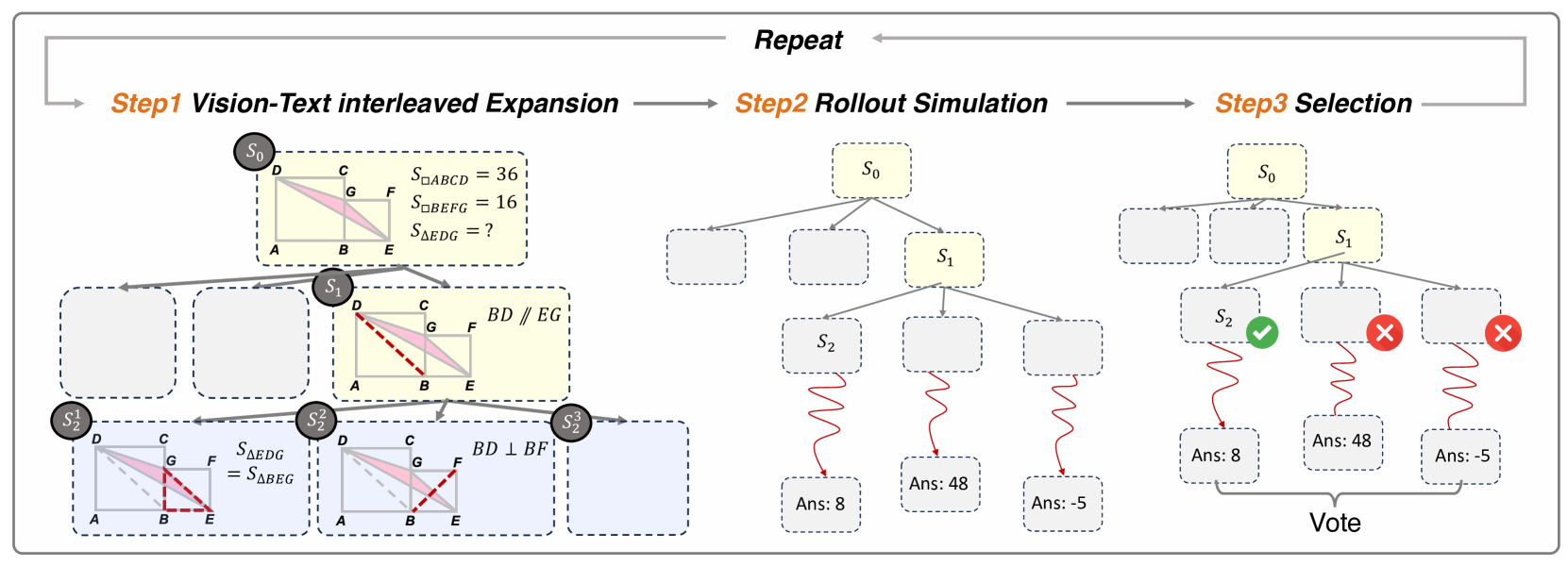
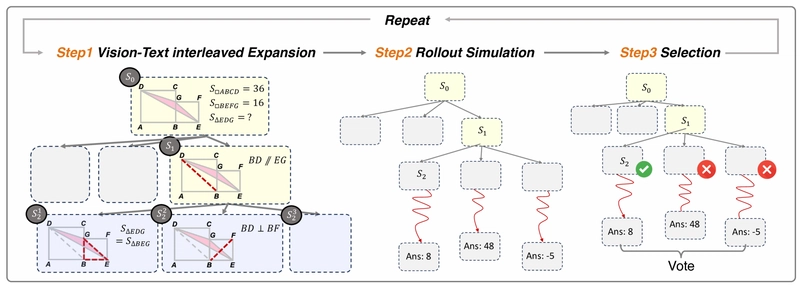
The illustration of the VisuoThink framework with three stages: vision-text interleaved expansion, rollout simulation, and selection.
The look-ahead tree search incorporates a predictive rollout mechanism that simulates likely outcomes of different reasoning states, allowing the model to prioritize promising paths and avoid less effective ones. Through this test-time scaling capability, the model can thoroughly explore and optimize reasoning paths dynamically during inference.
Extensive experiments show that VisuoThink significantly outperforms existing methods across various reasoning tasks, particularly in geometry and spatial reasoning domains. On Geomeverse, VisuoThink achieves an accuracy of up to 48.5%, representing an improvement of up to 21.8% over state-of-the-art baselines. This demonstrates the strong performance of VisuoThink on problems requiring multi-step visual reasoning.
The Landscape of Visual-Language Reasoning
Text-centric Reasoning in LVLMs
With the emergence of models like the o1 series from OpenAI, the importance of slow thinking has become increasingly evident. Several works have attempted to extend this to LVLMs through methods like stage-wise reasoning, curriculum learning, tree search-based data generation, and LLM distillation.
However, these methods treat visual information as static input, relying only on textual data during reasoning. This creates a "visual blind spot" where the potential for visual information throughout the reasoning process is largely ignored. Such approaches limit the model's ability to fully leverage multimodal information for complex tasks, failing to capture how humans naturally integrate visual thinking into their reasoning process.
Vision-aided Reasoning
Recent advancements in multimodal reasoning have demonstrated that incorporating visual information provides richer context and hints compared to text-only approaches. Early studies adopted a two-stage approach, where visual information is first transformed and grounded into text, graph structures (like scene graphs or knowledge graphs), or bounding boxes, followed by reasoning.
Other approaches leverage existing vision models (such as segmentation and detection) to process input images into valuable cues for perception, enabling more precise image understanding with fine-grained visual information.
Another line of research focuses on intermediate visual representations to enhance reasoning. For instance, Visual Sketchpad employs Python-based drawing tools to generate sketches as intermediate visual aids for geometric problems, while Visualization of Thought (VoT) formalizes visual thinking by generating emoji-like textual representations. MVOT fine-tunes multimodal models to generate images during reasoning, allowing the model to create visual aids dynamically.
Despite these advancements, most existing methods rely on single-step or unreliable visual representations, lacking search mechanisms to test-time scaling through exploring multiple reasoning paths. In contrast, VisuoThink develops a multimodal tree search framework that both leverages multi-step visual cues during reasoning and systematically explores reasoning paths through tree search.
Test-time Scaling with Tree Search
Scaling compute at test time has emerged as a powerful strategy to enhance LLMs' reasoning capabilities without increasing model parameters. Various approaches including Bag-of-n (BoN), guided beam search, and Monte Carlo Tree Search (MCTS) have been explored for text models, demonstrating improved performance through different search strategies.
However, the exploration of test-time scaling in LVLMs remains limited. Prior work like AtomThink has only investigated basic methods such as beam search, with text-only reasoning chains. In contrast, VisuoThink introduces vision-text interleaved thinking with look-ahead search, extending test-time scaling to multimodal reasoning and providing a more comprehensive approach to enhancing LVLMs' reasoning capabilities.
How VisuoThink Works: Combining Visual and Textual Reasoning
Vision-Text Interleaved Thinking
VisuoThink facilitates vision-text interleaved reasoning through an iterative cycle of Thought, Action, and Observation, enabling natural and dynamic interactions with external tools:
Thought phase: The model leverages visual information for textual reasoning (such as analyzing patterns based on previously added auxiliary lines) and determines the next step by planning what visual hints should be added to enhance understanding.
Action phase: The model executes the planned operations by calling external tools (like using Python code to draw auxiliary lines or highlight key features) to generate or modify visual information.
Observation phase: The model processes the visual feedback from the Action phase, incorporating these new visual hints into the next reasoning step.
The importance of visual information for LVLM reasoning is highlighted in VisuoThink, which utilizes tool invocations to construct reliable visual hints step by step in a visual construction process. This tool-based design allows VisuoThink to flexibly adapt to various visual reasoning tasks. Moreover, unlike approaches like VisualSketchpad that generate all visual aids at once, VisuoThink's step-by-step visual guidance naturally integrates with search techniques, enabling effective test-time scaling.
Predictive Rollout Search
Based on tree search methods and inspired by Monte Carlo Tree Search, VisuoThink proposes a predictive rollout search mechanism that interleaves visual-text thinking. By anticipating the outcomes of intermediate states, the model can make timely corrections, enabling more accurate and powerful reasoning.
The predictive rollout search consists of three key components:
Vision-Text Interleaved Expansion: Given the current node in the reasoning chain, the model samples multiple candidate nodes. Each candidate follows the vision-text interleaved thinking process, generating a sequence of Thought, Action, and Observation steps. This expansion creates a tree of possible reasoning paths, each representing a different problem-solving strategy.
Rollout Simulation: Visual reasoning often requires multiple steps to reach a conclusion, making it crucial to evaluate the full potential of each path. For each candidate node, the model simulates the complete reasoning process to predict final outcomes, rather than relying solely on immediate state evaluation.
Selection: The selection of the optimal path is performed through a self-voting mechanism. The model considers the task description, historical nodes, and the simulated path with predicted results for each candidate node.
This approach allows the model to explore multiple reasoning paths systematically and select the most promising one based on predicted outcomes, significantly enhancing its reasoning capabilities.
Solving Geometry Problems with VisuoThink
The core of VisuoThink's methodology is rooted in multi-step visual information processing and search-based reasoning, enabling LVLMs to address strongly constrained mathematical problems like geometry challenges.
Geometry problem-solving is formalized as a two-phase process integrating visual construction and algebraic computation:
- Phase I: The model generates auxiliary lines defined by geometric constraints, such as connecting points, constructing perpendicular or parallel lines, or forming line segments.
- Phase II: Geometric relationships are translated into solvable equations through Python code execution.
| Model | GPT-4o | Qwen2-VL-72B-Instruct | Claude-3.5-sonnet |
|---|---|---|---|
| Geomverse-109 | |||
| CoT | 11.1 | 5.6 | 14.4 |
| VisualSketchpad | 8.9 | 6.7 | 16.7 |
| VisualSketchpad + Equation Solver | 13.3 | 11.1 | 17.8 |
| VisuoThink w/o rollout search (ours) | 24.4 | 19.0 | 26.7 |
| VisuoThink (ours) | 28.9 | 25.6 | 27.8 |
| Geometry3K (Lu et al., 2021) | |||
| CoT | 20.8 | 18.8 | 37.5 |
| VisualSketchPad | 22.9 | 17.0 | 39.6 |
| VisualSketchpad + Equation Solver | 25.0 | 14.9 | 41.7 |
| VisuoThink w/o rollout search (ours) | 27.1 | 20.8 | 37.5 |
| VisuoThink (ours) | 33.3 | 25.0 | 43.8 |
Table 1: The 1-shot benchmark results (Accuracy@1) on Geometry including Geomverse-109 and Geometry3k of SOTA large visual language models. For GPT-4o and Claude-3.5-sonnet, the newest model versions were used. The highlighted results are from VisuoThink, with bold representing the best performance.
Empirical Results
The empirical results reveal that, even without rollout search augmentation, VisuoThink substantially enhances LVLM reasoning capabilities compared to Chain-of-Thought (CoT) and Visual Sketchpad baselines. On the Geomverse-109 benchmark, VisuoThink outperforms CoT and Visual Sketchpad by an average of 17.1% and 16.7% across all evaluated models, and predictive rollout search further enhances models' performance by an average of 4.1%.
The employment of an equation solver on Visual Sketchpad also increases average performance by 3.3%. This performance gap likely stems from Geomverse's emphasis on geometric relationship construction, where VisuoThink's equation-solving framework helps to accurately get intermediate answers and enables efficient resolution of structurally complex problems. The systematic integration of geometric analysis tools further mitigates error propagation inherent in conventional LVLM reasoning baselines.
Applying VisuoThink to Spatial Reasoning Tasks
Spatial reasoning, defined as the cognitive capability to interpret spatial object relationships, motion dynamics, and environmental interactions, constitutes a foundational requirement for mission-critical applications such as robotic systems, autonomous navigation, and augmented reality. These domains demand robust integration of visual perception and precise manipulation of spatial-temporal constraints for optimal action planning.
Building upon the Visualization of Thought (VoT) benchmarks, VisuoThink designs two challenging spatial reasoning benchmarks with enhanced complexity: Visual Navigation and Visual Tiling.
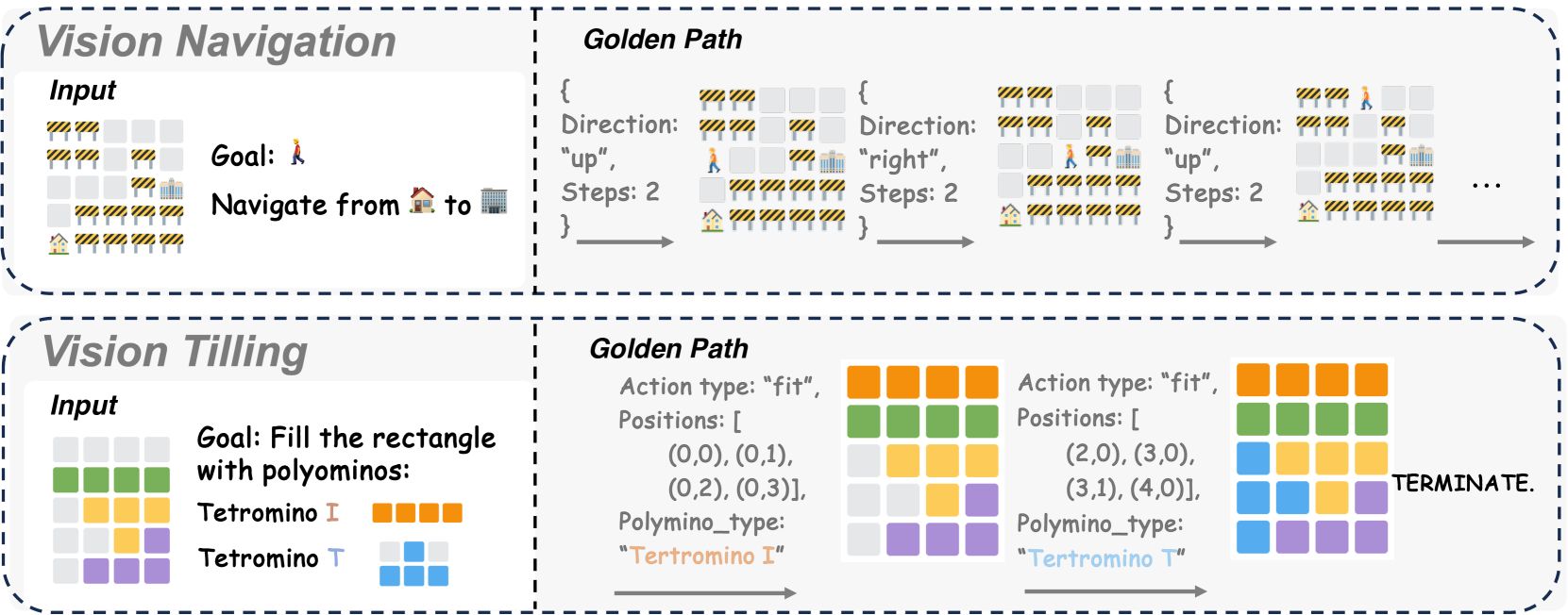
The illustration of spatial reasoning tasks including Visual Navigation and Visual Tiling. The LVLM must execute a sequence of actions to complete specific goals in settings that more closely resemble real-world deployment environments.
During task execution, robots deployed in true environments typically receive environmental feedback following each action, which facilitates perception and subsequent decision-making processes. VisuoThink leverages environmental interaction tools to enhance the model's spatial reasoning capabilities. In each action, an executor is employed to implement the corresponding action, returning textual execution feedback and visuospatial hints representing the map state.
Empirical Results
| Model | Dataset Subset (Num. Samples) |
Visual Navigation | Visual Tiling level-2 (119) |
||
|---|---|---|---|---|---|
| level-3 (16) | level-4 (31) | level-5 (62) | |||
| GPT-4o | CoT | 18.8 | 3.2 | 0.0 | 0.8 |
| VoT | 25.0 | 0.0 | 0.0 | 1.7 | |
| VoT + Executer | 62.5 | 9.7 | 4.8 | 12.6 | |
| VisuoThink w/o rollout search (ours) | 81.2 | 32.3 | 11.3 | 19.3 | |
| VisuoThink (ours) | 93.8 | 61.3 | 19.4 | 51.2 | |
| Qwen2-VL-72B-Instruct | CoT | 6.7 | 3.2 | - | 0.0 |
| VoT | 0.0 | 0.0 | - | 0.8 | |
| VoT + Executer | 25.0 | 3.2 | - | 6.7 | |
| VisuoThink w/o rollout search (ours) | 50.0 | 6.5 | - | 9.2 | |
| VisuoThink (ours) | 81.3 | 12.9 | - | 20.2 | |
| Claude-3.5-sonnet | CoT | 37.5 | 3.2 | 0.0 | 0.8 |
| VoT | 56.3 | 0.0 | 0.0 | 2.5 | |
| VoT + Executer | 68.8 | 22.6 | 16.1 | 10.1 | |
| VisuoThink w/o rollout search (ours) | 81.2 | 38.7 | 41.9 | 80.7 | |
| VisuoThink (ours) | 93.8 | 61.3 | 53.2 | 84.0 |
Table 2: The Pass@1 performance comparison on spatial reasoning benchmarks including Visual Navigation and Visual Tiling across SOTA LVLMs. The highlighted results are from VisuoThink, with bold representing the best performance.
In spatial reasoning experiments, VisuoThink demonstrates significant performance improvements over baseline methods, particularly when augmented with predictive rollout search. As shown in Table 2, VisuoThink achieves the highest accuracy across all tasks, outperforming both CoT and VoT baselines. For instance, on the Visual Navigation task, VisuoThink on GPT-4o achieves a 93.8% accuracy at level-3, compared to 62.5% for VoT with an executor and 18.8% for CoT.
Similar to the geometry experiments, the integration of tool interactions and multi-step visual reasoning plays a critical role in enhancing performance. The executor's feedback mechanism, which provides visual updates after each action, mirrors the incremental visual refinement seen in geometry tasks, where auxiliary lines are progressively constructed.
VisuoThink without rollout search demonstrates an average improvement of 34.7% on Visual Tiling across diverse models. While VoT augmented with textual feedback achieves an average increase of 8.1%, its performance gain is notably less pronounced compared to VisuoThink without rollout search. This underscores the critical role of reliable visual cues in enhancing reasoning capabilities.
Key Insights from the VisuoThink Approach
The Impact of Longer Reasoning Chains
In practical applications of LVLMs for spatial reasoning tasks, each tool invocation can be seen as an agent attempting an action in the environment and receiving feedback. Although many attempts may be inaccurate, allowing the model more trial-and-error opportunities before achieving the final goal could potentially enhance its reasoning capabilities.
By setting different upper limits on the number of reasoning steps in visual navigation tasks, a positive correlation between the number of reasoning steps and the model's task completion rate was observed. This suggests that the model indeed benefits from more tool invocations and longer reasoning.
However, as the number of reasoning steps increases, the completion rate gradually converges, making further significant improvements challenging. For instance, increasing reasoning steps from 10 to 20 resulted in substantial performance gains (+54.1% and +48.4%) across different LVLM architectures (GPT-4o and Claude-3.5-sonnet). However, when reasoning steps were increased from 20 to 40, the performance growth slowed dramatically, dropping to +6.5% and +2.1%, respectively.
This phenomenon aligns with expectations, as merely increasing the number of tool invocations does not enable the model to better solve the most challenging samples. This underscores the necessity of techniques like rollout search within the broader context of test scaling.
Optimizing Tree Width in VisuoThink
Predictive rollouts enhance the model's reasoning capabilities by expanding the model's reasoning search space. A natural question arises: Can we further improve the model's reasoning performance simply by increasing the number of candidate child nodes at each selection step?
Researchers conducted comparative experiments on geometry tasks using GPT-4o and Claude-3.5-sonnet, keeping the depth of the reasoning tree constant while varying the number of candidate child nodes.
An inverted U-shaped trend in overall performance was observed as the number of candidate tree nodes increased across different model architectures. When the number of candidate child nodes equals 1, the model follows a single reasoning path, effectively bypassing predictive rollout search.
Contrary to expectations, the performance trend initially rises and then declines. This counterintuitive result can be attributed to the inherent errors in the model's evaluation of child nodes. Simply and aggressively increasing the tree width leads to confusion in selecting child nodes, which in turn reduces overall reasoning efficiency. Thus, an interesting conclusion emerges: we cannot expect to continuously improve model performance by merely increasing the number of child nodes in rollout search.
Strong vs. Weak Supervision in Predictive Rollout Search
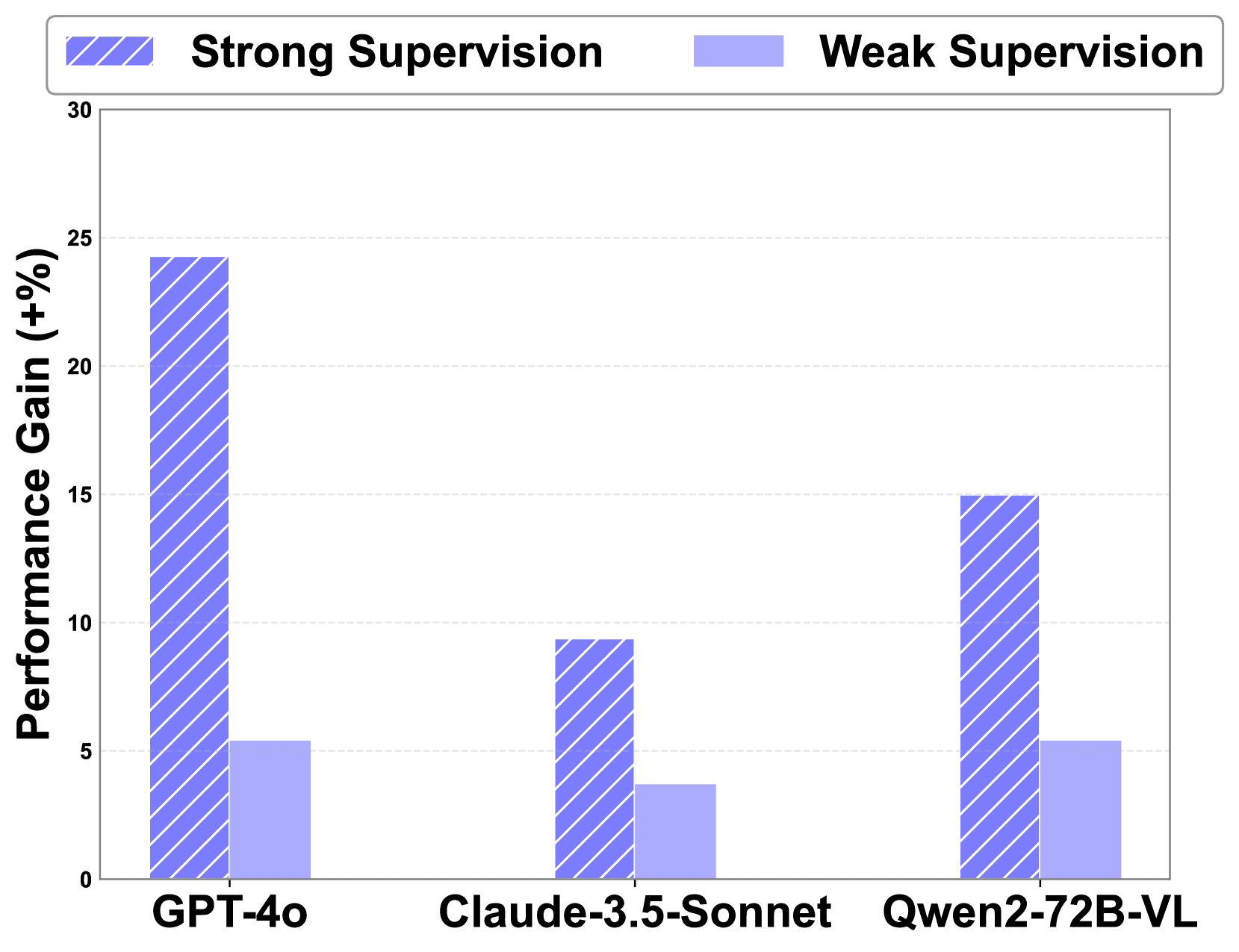
The performance gain (%) on tasks through predictive rollout search, calculated as the performance gap between VisuoThink without rollout search and VisuoThink with rollout search.
An intriguing observation is that the strength of guidance provided by predictive rollout results varies between geometry and spatial reasoning tasks. In geometry tasks, the model only receives the final numerical results of the problem, whereas in spatial reasoning tasks, the model has access to visual states of stronger supervision (e.g., the agent's final position, the position of the destination, etc.). In other words, predictive rollouts in geometry tasks offer weaker supervision, while those in spatial reasoning tasks provide stronger supervision.
This observation aligns with the findings of the Deepseek R1 report, which highlights that outcome-based supervision in reinforcement learning can significantly enhance reasoning capabilities. The effectiveness of such supervision stems from its strong supervisory signal, and predictive rollouts with strong supervision are more effective in improving model reasoning performance.
| Supervision Type | Performance Gain | GPT-4o | Qwen2-VL-72B | Claude-3.5-Sonnet |
|---|---|---|---|---|
| Strong Supervision | $\Delta$ Visual Navigation (%) | +16.6 | +18.9 | +15.5 |
| $\Delta$ Visual Tiling (%) | +31.9 | +11.0 | +3.3 | |
| $\Delta$ Average (%) | +24.3 | +15.0 | +9.4 | |
| Weak Supervision | $\Delta$ Geometry3K (%) | +4.5 | +6.6 | +1.1 |
| $\Delta$ Geomverse-109 (%) | +6.2 | +4.2 | +6.3 | |
| $\Delta$ Average (%) | +5.4 | +5.4 | +3.7 |
Table 3: Detailed performance gain of VisuoThink through predictive rollout search on benchmarks from Geometry and Spatial Reasoning over variable LVLM models.
As illustrated in Table 3, predictive rollouts demonstrated more substantial performance gains in spatial reasoning tasks compared to geometry tasks, across both open-source and closed-source models. For instance, under strong supervision, GPT-4o achieves an average improvement of +24.3%, while under weak supervision, the average improvement is only +5.4%.
Conclusion: Advancing Multimodal Reasoning in AI
VisuoThink presents a significant advance in multimodal reasoning through a framework that seamlessly integrates visuospatial and linguistic domains. By enabling dynamic integration of visual and verbal reasoning paths throughout the problem-solving search process, VisuoThink significantly enhances the reasoning capabilities of LVLMs.
The framework extends test-time scaling methods to the visual domain through a predictive rollout mechanism that explores and optimizes visual reasoning paths by predicting future states. This approach allows the model to make timely corrections and select more promising reasoning paths, leading to more accurate solutions.
Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning. These improvements are particularly notable in complex reasoning tasks that require multi-step visual reasoning.
The insights gained from this research, particularly regarding the impacts of reasoning chain length, tree width optimization, and supervision strength, open new possibilities for advancing LVLM capabilities in complex reasoning tasks. By bridging the gap between human-like visual-verbal reasoning and AI capabilities, VisuoThink represents a promising direction for enhancing the reasoning abilities of large vision-language models.
Limitations
Despite its strong performance, VisuoThink has several limitations. First, the predictive rollout search process introduces significant computational overhead, making it potentially impractical for real-time applications. Second, the approach particularly relies on tool interactions for stronger capability, which may require more effort in some specific deployment environments.
Third, the framework's effectiveness is constrained by the quality of the base VLM's reasoning capabilities - while it enhances performance, it cannot overcome fundamental model limitations. Finally, the evaluation focuses primarily on geometric and spatial reasoning tasks, leaving open questions about its effectiveness in other domains requiring multimodal reasoning.
