With size, complexity emerges.
Silent Scraping
While writing the scraper, we will first hide behind a VPN or proxy. Then we are going to scrape the target a significant number of times until we are satisfied with the results. But in the meantime, we’ll get blocked, then try another IP—which doesn't work... Then some sunbeam will hit the Lava Lamp in Cloudflare, and we’ll start receiving captchas... Solving a problem that maybe doesn’t even need solving. Why? Because during development, we’ll mostly abuse the targeted site, while in production, scraping might only run peacefully once a day. Also, our free proxy or VPN will throttle, causing delays for each execution.
This issue can be easily solved by caching the site during development. A scraping framework such as Scrapy already includes caching out-of-the-box. Otherwise, we could use Nginx to cache our requests.
This is a straightforward way to develop your scraper without raising red flags with suspicious requests while adjusting headers to circumvent anti-scraping measures. Also, the site data is cached locally—no more network issues or delays.
Maintainable scraper
Regression Tests
Using a cached version brings another benefit: the site data becomes immutable, and it’s a lot easier to hit a static target. If it moves, we can patch the code in the next version, but during development it won’t change and won’t cause more bugs than we already have.
This approach can be extended to the testing level. Let's store the current version of the scraper along with the site data it works with in VCS.
That way, maintaining the scraper when the target site changes becomes easier. We simply diff (automated or manual) the stored version of the site against the live one. From the diff, we know what changed—and where to fix the scraper. Finally, we store the expected results, and we’ve got ourselves a regression test suite.
Of course, this increases the complexity of the scraper and requires extra effort upfront. In the case of Scrapy, this can be done in such an elegant way that the added complexity is manageable. But ultimately, it depends on the context and the answers to key questions—such as the estimated lifetime of the scraper, number of targets, scraping frequency, and how often the targeted site changes.
Mitigating pre-rendering JS
However, in real life, we’re mostly dealing with fat clients using client-side rendering. Pre-rendered sites are either ancient relics or cutting-edge setups optimized for SEO (and scraping).
The fail-safe—but also most expensive—approach is using headless browsers. But rendering that mess is slow, resource-hungry, and most importantly, often avoidable.
We can often skip full JS rendering by simply fetching only the data we need. A basic analysis of the requests the site makes will quickly reveal the ones we're interested in scraping.
It might take a few steps to get there—for example, we first extract IDs from URI_1, then generate a list of endpoints like [URI_2_ID_1, URI_2_ID_2, ...] to fetch the actual data.
Some may argue this is more fragile than rendering the site and scraping the DOM. But I don’t see a strong reason why API endpoints would change more frequently than the HTML selectors in the rendered case. We're also closer to the actual data source, which means fewer moving parts and less that could break the scraper.
Source - Mitigating pre-rendering JS.
Scrapy Implementation Example
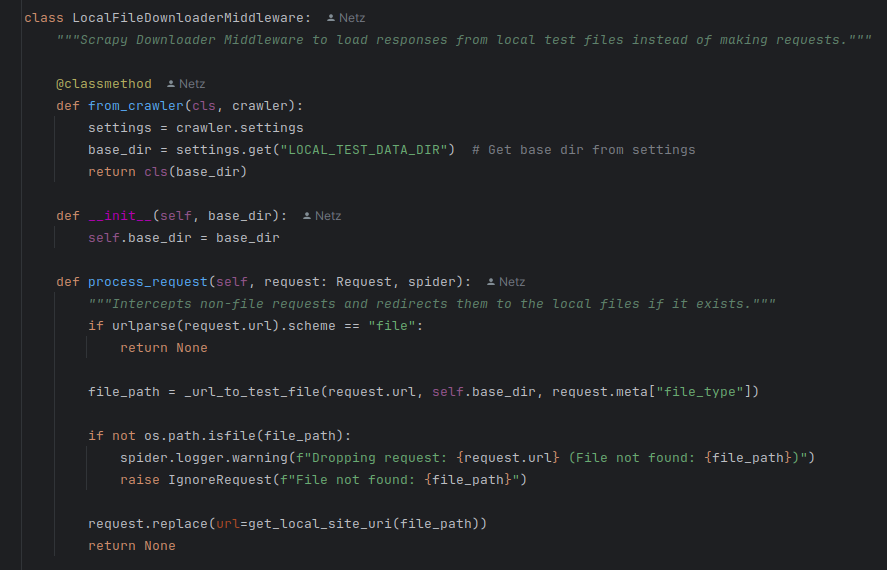
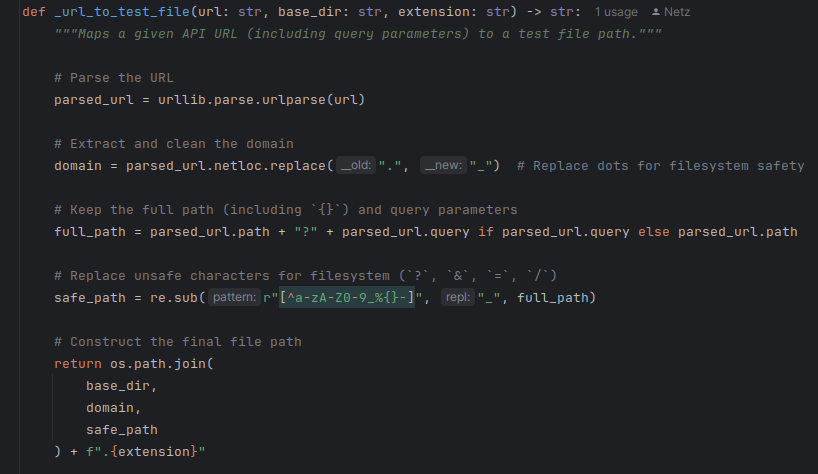
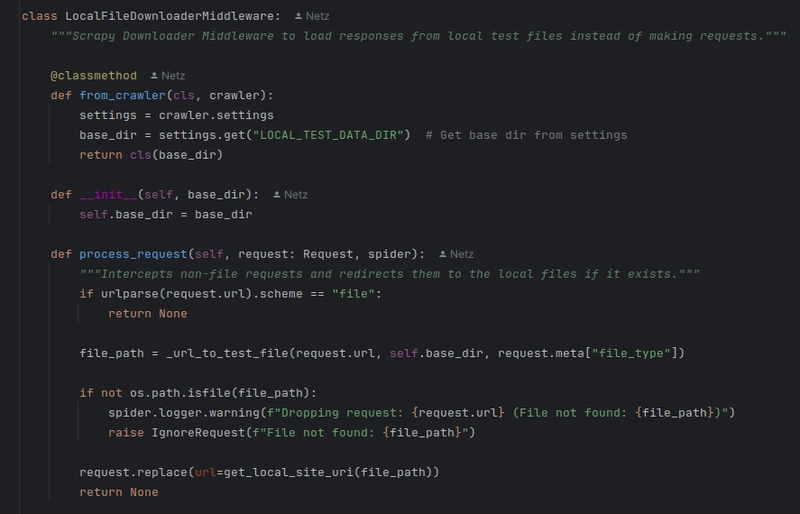
One solution is to use a downloader middleware. This way, our spiders don’t need to be aware of it. The spider requests https://dev.to, and inside the downloader middleware, we simply map that URL to a local file where the site is stored and forward the request.
This setup can be extended by using an env variable for dev / prod modes, allowing us to include the middleware conditionally in the settings.
Storing the site can be as simple as using CTRL + S, or handled through an extra mode like init, which scrapes the sites and saves them with filenames mapped from their URLs.
Now, one could simply extend this with tests and the init mode if necessary, but explaining that wouldn't add much value at this point. Stopping here.