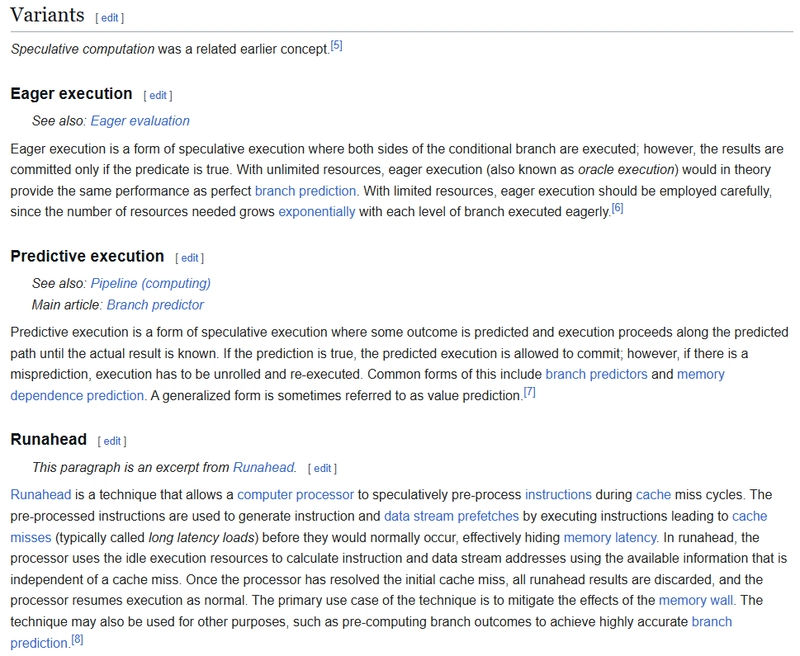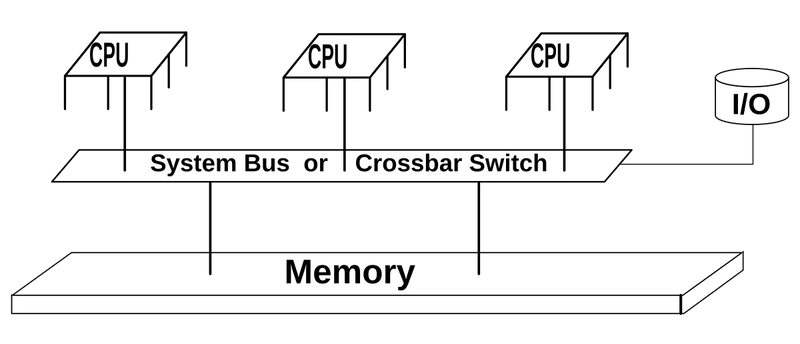
Shared memory is a fundamental concept in multi-core System-on-Chip (SoC) designs that enables efficient communication and data sharing between processor cores. Here's a comprehensive explanation of its implementation and usage:
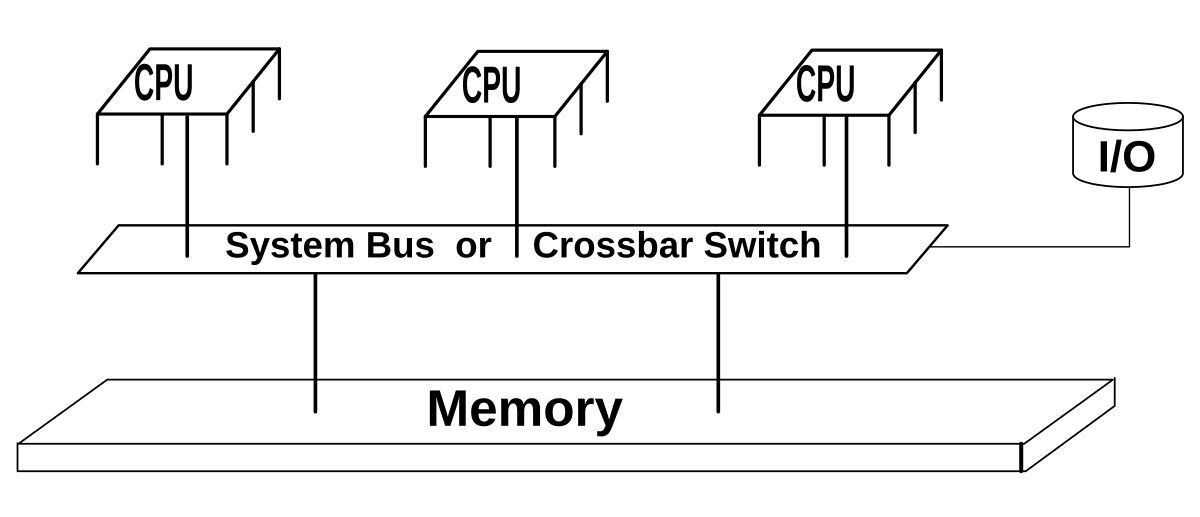
What is Shared Memory?
Shared memory refers to a memory region that is accessible by multiple processing units (CPUs, GPUs, DSPs) in a multi-core system. Unlike private memory that is core-specific, shared memory allows different processors to access the same data without explicit data transfers.
Key Characteristics
- Unified Address Space: All cores see the same memory addresses for shared regions
- Concurrent Access: Multiple cores can read/write simultaneously (with synchronization)
- Coherency Management: Hardware/software maintains data consistency across cores
- Low-Latency Communication: Faster than message passing for frequent data exchange
Implementation in Modern SoCs
1. Hardware Architectures
A. Uniform Memory Access (UMA)
All cores share equal access latency to memory
Example: Smartphone application processors (e.g., ARM big.LITTLE)
B. Non-Uniform Memory Access (NUMA)
Memory access time depends on physical location
Example: Server CPUs (AMD EPYC, Intel Xeon)
C. Hybrid Architectures
Combination of shared and distributed memory
Example: Heterogeneous SoCs (CPU+GPU+DSP)
2. Memory Hierarchy
┌───────────────────────┐
│ Core 1 Core 2 │ Cores
└───┬───────┬─────┬─────┘
│L1 Cache│ │L1 Cache
└───┬────┘ └───┬────┘
│L2 Cache │L2 Cache
└───────┬──────┘
│Shared L3 Cache
└───────┬──────┘
│DRAM Controller
└───────┬──────┘
│Main MemoryUtilization Techniques
1. Cache Coherency Protocols
- MESI/MOESI: Maintain consistency across core caches
- Hardware-Managed: Transparent to software (ARM CCI, AMD Infinity Fabric)
- Directory-Based: Tracks which cores have cache lines
2. Synchronization Mechanisms
A. Atomic Operations
c
// ARMv8 atomic increment
LDREX R0, [R1] // Load with exclusive monitor
ADD R0, R0, #1 // Increment
STREX R2, R0, [R1] // Store conditionallyB. Hardware Spinlocks
- Dedicated synchronization IP blocks
- Lower power than software spinlocks
C. Memory Barriers
c
// ARM Data Memory Barrier
DMB ISH // Ensure all cores see writes in order3. Shared Memory Programming Models
A. OpenMP
c
#pragma omp parallel shared(matrix)
{
// Multiple threads access matrix
}B. POSIX Shared Memory
c
int fd = shm_open("/shared_region", O_CREAT|O_RDWR, 0666);
ftruncate(fd, SIZE);
void* ptr = mmap(NULL, SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);C. Linux Kernel Shared Memory
c
// Reserve shared memory region
void *shmem = memremap(resource, size, MEMREMAP_WB);Performance Optimization Techniques
- False Sharing Mitigation
Align data to cache line boundaries (typically 64B)
c
struct __attribute__((aligned(64))) {
int core1_data;
int core2_data;
};- NUMA-Aware Allocation
c
// Linux NUMA policy
set_mempolicy(MPOL_BIND, nodemask, sizeof(nodemask));- Write-Combining Buffers
- Batch writes to shared memory
- ARM STLR/STNP instructions
- Hardware Accelerator Access
- Shared virtual memory (SVM) for CPU-GPU sharing
- IOMMU address translation
Real-World SoC Examples
- ARM DynamIQ
- Shared L3 cache with configurable slices
- DSU (DynamIQ Shared Unit) manages coherency
- Intel Client SoCs
- Last Level Cache (LLC) partitioning
- Mesh interconnect with home agents
- AMD Ryzen
- Infinity Fabric coherent interconnect
- Multi-chip module shared memory
Debugging Challenges
- Race Conditions
- Use hardware watchpoints (ARM ETM, Intel PT)
- Memory tagging (ARM MTE)
- Coherency Issues
- Cache snoop filters
- Performance monitor unit (PMU) events
- Deadlocks
- Hardware lock elision (Intel TSX)
- Spinlock profiling
Emerging Trends
- Chiplet Architectures
- Shared memory across dies (UCIe standard)
- Advanced packaging (2.5D/3D)
- Compute Express Link (CXL)
- Memory pooling between SoCs
- Type 3 devices for shared memory expansion
- Persistent Shared Memory
- NVDIMM integration
- Asynchronous DRAM refresh (ADR)
Shared memory remains the most efficient communication mechanism for tightly-coupled processors in modern SoCs, though it requires careful design to avoid contention and maintain consistency in increasingly complex multi-core systems.