1 Introduction
The XRP Ledger (XRPL) is constantly evolving to meet the needs of the community. Although the most visible of these changes are features, looking back at the last two years of development in the rippled GitHub repository about 80% of pull requests actually focused on non-feature work. As we do not have a public roadmap for these kinds of efforts, in this blog post we would like to provide transparency by highlighting what we have recently done and what we are currently working on to enhance the stability, scalability, and resiliency of the ledger.
2 Under the hood
The XRPL functions by having validators agree with each other on which transactions to include in a ledger and what the new state (e.g. the balance in each account) is after they are executed. As validators are not necessarily directly connected to each other, the consensus protocol involves exchanging and relaying lots of messages to ensure that the network as a whole has an up-to-date understanding of what is going on. Sometimes a node can run a bit behind or is missing some data, in which case it tries to catch up by asking its peers for the information it does not have, imposing an additional load on the network. Each node uses several caches with periodic deletion to find a good balance between memory and disk use, and availability of data.
The non-feature work we are principally focusing on can be categorized into four areas: (i) memory use, (ii) peering, (iii) lock contention, and (iv) test environments.
2.1 Memory use
Each ledger contains many objects, some of which can be represented hierarchically. The SHAMap and TaggedCache are internal structures that allow us to efficiently read and write these objects in memory. As there are many objects, these structures can grow to consume over 20GB, which in turn means that nodes need a substantial amount of RAM to participate in the XRPL.
Our aim is to lower the entry point for participation, as well as to support many more millions of transactions, accounts and trust lines in the future, for which optimizing memory use is critical.
2.1.1 Intrusive pointers
Our custom intrusive pointer can handle both strong and weak pointers. In comparison with the shared pointer that the cache used in the past, which has a size of around 40 bytes, the intrusive pointer only requires 12 bytes. When measuring memory usage on a mainnet validator, the change resulted in a 10-15% memory savings. This improvement was recently merged and will be included in the upcoming 2.5.0 release.
2.1.2 Cache reductions
From an analysis of how (pointers to) objects are used and stored in the caches, we have identified several areas that can be optimized.
Objects are unnecessarily stored in multiple caches
We believe we may be able to consolidate some caches and/or reduce the number of places where an object is stored to achieve additional memory savings.
Objects are kept around for longer than they are needed
The current design does not immediately remove an object when it is no longer referenced, as a peer request for that object might still arrive in the near future. We believe it is possible to evict unused objects sooner without having adverse effects.
Caches on top of databases may be removed
As databases have advanced significantly in the last 10 years and also use one or more caches internally, there should be no need for us to maintain our own cache on top of a database, which is the case in some parts of the codebase. A preliminary experiment achieved a 5% memory reduction by disabling one of them, and we will be performing more rigorous experiments to confirm these initial observations using realistic scenarios.
2.2 Peering
Robust and reliable inter-node communication, tolerant against malicious interference, forms the underpinnings of the network. As cryptocurrency has increased in popularity and consequently more transactions are being submitted than in the past, we have observed some instability in the network lately. Our aim is to bring stability back to the network, for which we are focusing on the following areas.
2.2.1 Cost per message
To prevent nodes from accidentally or intentionally behaving badly – the codebase is open source after all, and anyone can apply changes to their binary – each message incurs a "cost", loosely based on how much effort it takes to process it, with verifiably invalid messages getting penalized heavily. If the cost over a certain time period exceeds a threshold, the node will be dropped by its peers and is not allowed to connect again for a while.
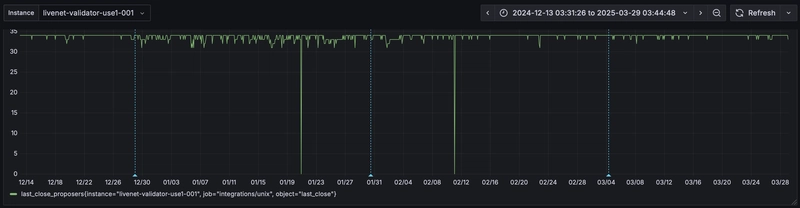
We recently noticed that peers started getting disconnected frequently, and discovered that we were applying incorrect charges to certain message types; coupled with handling an increased number of transactions, this caused nodes to exceed the disconnection thresholds. For UNL validators, loss of peers can have as a consequence that messages sent by or to other validators do not arrive. In release version 2.3.1 we deployed a change that addressed this issue, and have seen the network behave much better in response, see the figure below.
In the figure we show the number of validation messages received by our UNL node from other UNL nodes in the last few months. On 29 December 2024, indicated by the left vertical blue line, the instability manifested itself by a sudden increase in missing validation messages. The 2.3.1 hotfix was introduced on 30 January 2025, but as uptake was relatively slow the improvements took a while to materialize. On 4 March 2025 we released version 2.4.0, which requires nodes to upgrade lest they become amendment-blocked, resulting in even fewer dips since then.
2.2.2 Connectivity
Although the fix described above resolved the missing validations in our nodes, the network as a whole is still experiencing frequent peer disconnects, which remain under investigation. We observed in our logs that peers are often being dropped due to not responding to a heartbeat message, which we had not seen before.
The recent network halt was a result of the consensus process getting stuck. After cycling through various theories we believe nodes were unable to obtain a transaction set due to repeated timeouts and then permanently gave up participating. We included a fix in the 2.4.0 release that resets this timeout variable on receipt of an inbound transaction set. We separately created two failsafes to prevent a consensus round from remaining in the establish phase indefinitely, which will be included in the 2.5.0 release.
2.2.3 Debugging
Whenever an issue occurs, due to the decentralized nature of the network, it is challenging to see the whole picture as we only have full insights into our nodes. We have been working on, and will soon launch, an effort to allow UNL validators to opt into sharing their logs and metrics to enable collaborative debugging. These node operators will be able to redact the data they expose, for instance to hide their node's IP address. In the meantime, we invite UNL validators to share their logs with the community each time they experience problems.
2.2.4 Squelching
Currently, the messaging technique used by the consensus protocol is flooding, which ensures that every node in the network receives the message at least once. A node will discard any duplicate message it receives. These discarded messages are a form of waste, as they consume unnecessary bandwidth and even cost money, as cloud providers commonly charge for outbound transmission. One of our analyses showed that these messages produce between 14.4 TB and 43 TB of data in the network daily, while only around 1.8 TB contribute meaningfully to the consensus – the rest are redundant.
In the figure below we show the amount of consensus message data received per second by one of our nodes over a recent 24h time period, shown using a base-2 log scale for the right Y-axis, together with the number of peers the node is connected to. As can be seen, the vast majority of messages are duplicates or are sent by untrusted validators.
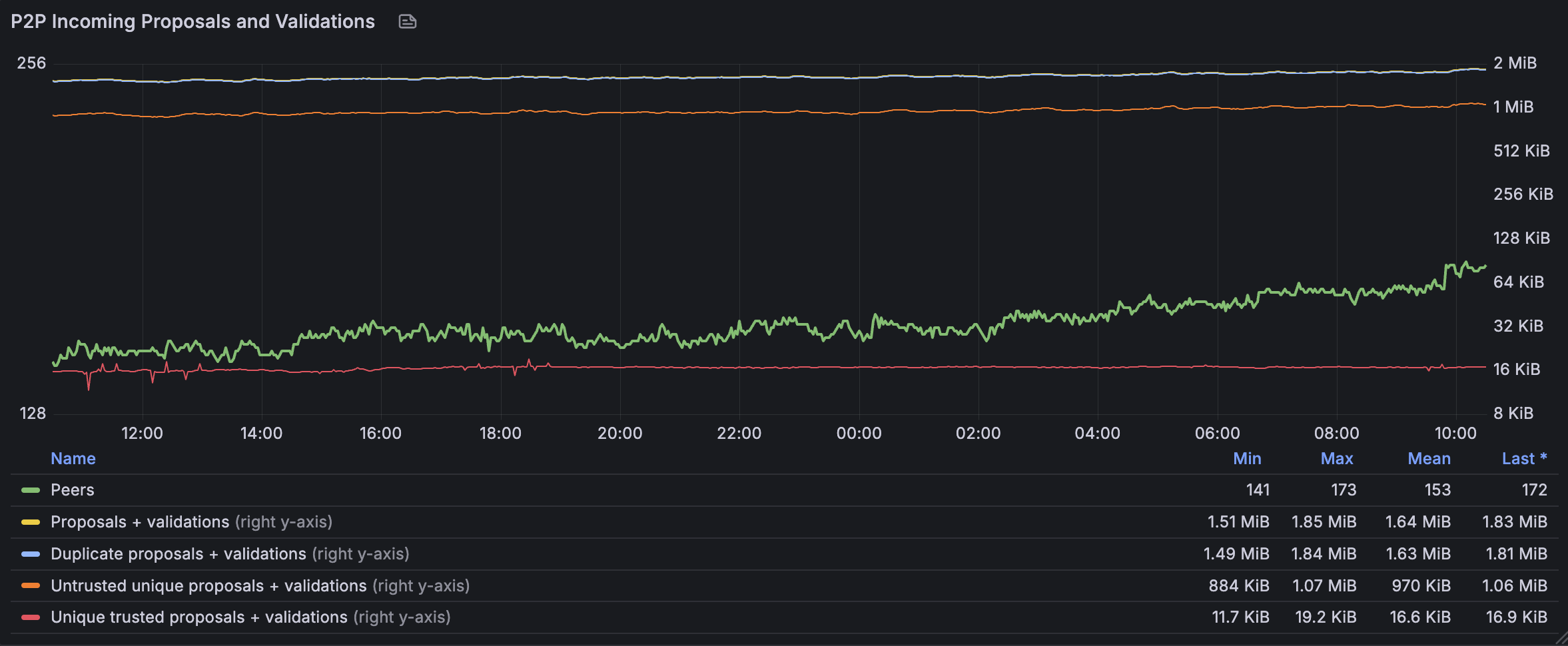
We are therefore looking at ways to reduce network traffic, lower operational costs, and support future growth. One promising technique is squelching, which limits the number of peers that forward a given validator’s messages, substantially lowering redundant traffic. Our experiments with setting the peer limit to 5 have shown that the consensus process is unaffected while the number of exchanged messages is reduced to between 8.9 TB and 16.8 TB daily. Squelching was first proposed a few years ago, but never fully implemented. We aim to include this approach in the upcoming 2.5.0 release, anticipated for June.
Given that this change is very impactful, it will be disabled by default and we will perform a careful incremental rollout on our nodes first, while closely monitoring metrics to avoid any side effects. Once we are confident squelching is performing as expected, we will encourage other validators to enable it on their nodes as well, one at a time.
2.3 Lock contention
How the ledger functions is relatively easy to explain, but the way it is implemented is anything but. The complexity stems from the need to efficiently collaborate across a decentralized network to process many transactions efficiently. The application heavily uses threads to execute code paths in parallel, and locks that guard against concurrent modifications of the same object. Lock contention occurs when multiple threads have to wait on each other in turn to access a guarded object.
2.3.1 Profiling
While some lock contention is to be expected, threads should not be waiting on each other for more than a fraction of a second. We are employing various profiling techniques, such as eBPF, to identify where in the code performance bottlenecks occur, and then investigate what kind of changes we can make to reduce the contention. For instance, where appropriate, we may adopt lockless techniques to help mitigate or eliminate some of these problems. One specific part we are homing into is the aforementioned TaggedCache, where the sweeping operation to evict expired objects interferes with update and fetch operations, as it occupies the lock for a long time.
2.4 Test environments
The codebase is subjected to various types of tests, namely unit tests, integration tests, performance tests, and fuzzing tests. For some of these tests a small network of nodes is used to confirm that their behavior matches what we expect. The XRPL, in contrast, consists of a large number of decentralized nodes with varying degrees of connectivity, where we may see vastly different behavior from time to time that we are unable to simulate in our test network.
2.4.1 Testbed
To improve our test network, we are building a platform that allows us to deploy a network of any size, with different types of nodes and connectivity between them, and submit a set of predefined transactions to simulate what would happen. A special monitoring node scrapes the logs and metrics of every other node, so that we can analyze how the network acts and reacts to the transactions. Although the platform is still in the early stages, we are aiming to use the platform to create a realistic network, both on-demand and at a regular cadence, to catch regressions early and to measure the performance of proposed changes. Our eventual goal is to open source the testbed and testing tools for the benefit of the broader community.
2.4.2 Live node testing
Even with a testbed at our disposal, nothing beats the real thing. As we run several nodes in devnet, testnet, and mainnet, we occasionally replace the binary on one or more of these nodes to provide us with additional insights beyond clean lab testing. This allows us to test out a new change before releasing it, or even before merging it. In particular, we deploy betas and release candidates onto some of the nodes to increase our confidence that the actual release will happen smoothly.
2.4.3 Antithesis
We leverage an autonomous testing platform called Antithesis to find bugs in our code. We provide the platform with workloads that test certain functionality, and the platform then performs fuzzing to try to make these tests fail. Antithesis helps us find the gnarly application bugs that we cannot otherwise detect easily when unintended but practical situations occur, such as a node crashing, the application is starved of cpu/memory, or a rare deadlock occurs.
Actual instances of bugs that Antithesis has helped find are a missing ledger in the SHAMap causing a crash – usually a node will just fetch the missing ledger from its peers – as well as a deadlock occurring in the job queue. In total we have found and fixed 4 moderate/minor bugs so far, and have diagnosed 3 moderate bugs for which we are collecting more data.
3 Conclusion
Although non-feature work is not as visible as the shiny features that are highlighted when a release is made, it is of critical importance to the stability and reliability of the XRPL. We are pursuing a multipronged approach, focusing on memory use reduction, peer communication improvements, avoiding lock contention, and leveraging various testing strategies, to safely scale and enhance the capabilities of the ledger. The upcoming 2.5.0 release should result in significantly lower memory and bandwidth use for node operators, and we will continue working on the other non-feature improvements to release as soon as they are ready. We will share more updates when we have made meaningful progress, so please stay tuned.
We invite you to participate in our research, evaluation, and testing efforts. Please reach out or share your feedback and questions in the comments – we love to collaborate with you.