Kicking the tyres on the new DuckDB UI
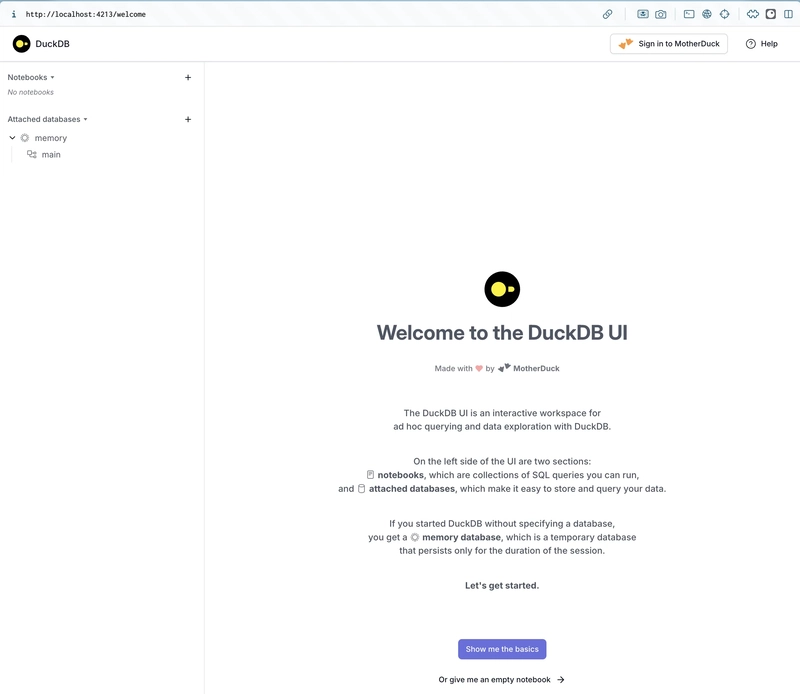
I wrote a couple of weeks ago about using DuckDB and Rill Data to explore a new data source that I’m working with. I wanted to understand the data’s structure and distribution of values, as well a...
DUCKDB, S3 Tables with iceberg using Iceberg Rest API
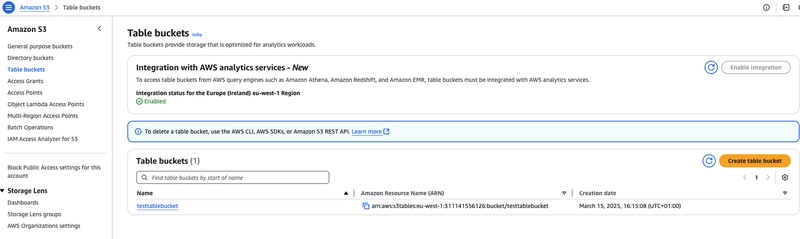
I wrote my previous article about Duckberg, a combination of PyIceberg with Duckdb to access iceberg tables on aws.But on Pi-Day (3 March) DuckDB released a preview with native iceberg glue integratio...
esProc SPL: Combining the Strengths of DuckDB and Python

That DuckDB is gaining more and more attention is no accident. As a rising star in desktop analytics, it masters SQL with ease, effortlessly handling CTE recursive queries, multi-layered window functi...
DuckDB 🦆: Unleashing the Powerhouse Query Engine Within
Introduction
DuckDB is widely recognized for its analytical processing capabilities, but its true power lies in its exceptional query engine. Unlike traditional databases that require extensi...
Working with Parquet files
Parquet files offer significant advantages over traditional formats like CSV or JSON. This is more relevant in analytical workloads and processing. Tools like parquet-tools and DuckDB make it easy to ...
Local Data Analysis: DuckDB or esProc SPL?
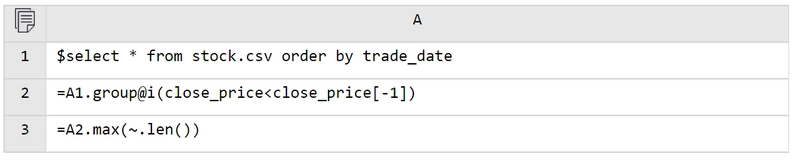
DuckDB can directly read common files such as CSV, Parquet, and JSON. With just a single SQL statement, it can load the file and perform a query, such as SELECT * FROM ‘data.csv’ WHERE price>10...
SPL Operates Multi-layer JSON Data Much More Conveniently than DuckDB
esProc SPL is much more convenient than DuckDB in operating multi-layer JSON data, particularly when preserving JSON hierarchy and performing complex calculations are required.DuckDB’s ability to op...
Personal Picks: Data Product News (April 30, 2025)
Modern Data Stack Updates: April 2025
※This article is an English translation of my original Japanese post.As a consultant specializing in the Modern Data Stack, I've noticed that there's a...
DuckDB 1.20 Released! Exploring the New Features
Introduction
DuckDB has been updated to version 1.20. 🙌
It seems that various features have been added, so I tried out some of the new functionality mentioned in the official blog.
...