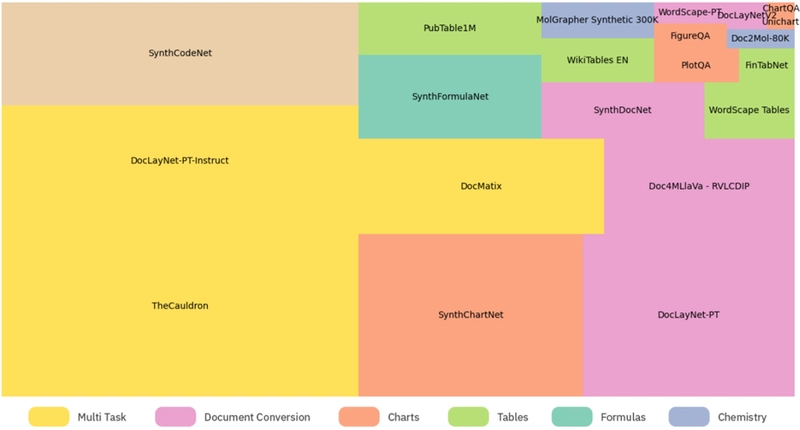
Multilevel RAG
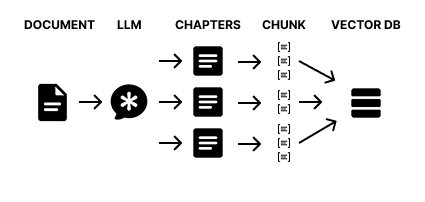
PREMISE
Simply breaking an entire document into regular CHUNKs has some disadvantages:
It does not allow you to incorporate all the semantics of the context because the cut can potentially oc...