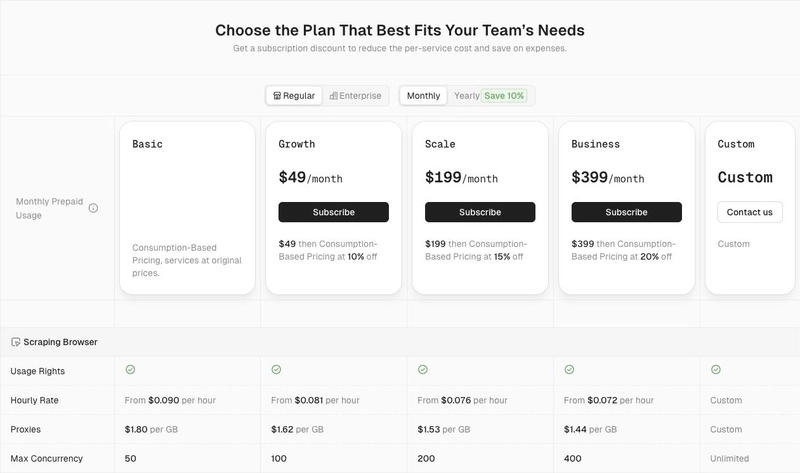
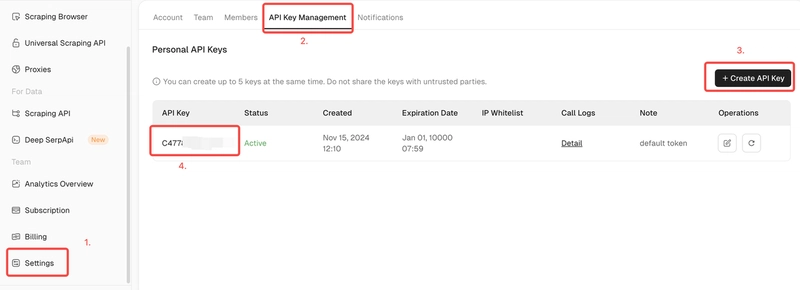
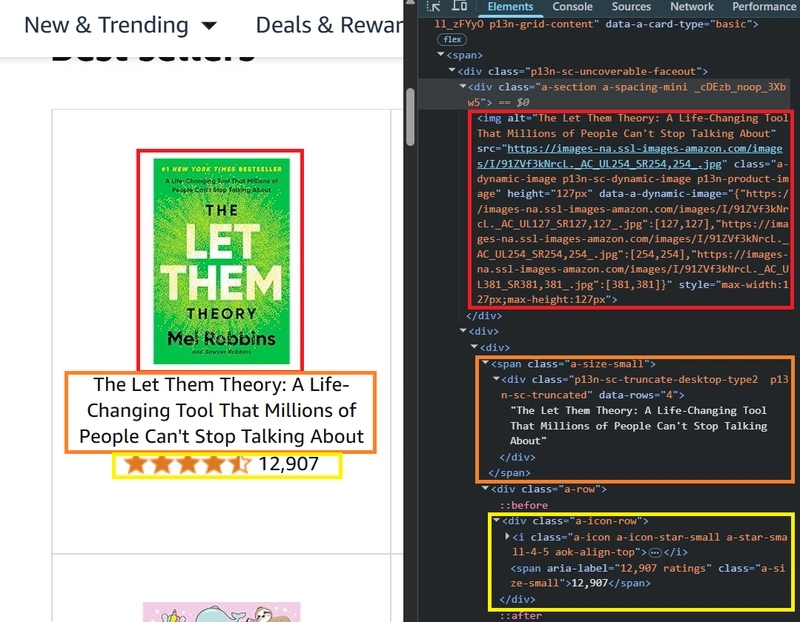
The Ultimate Guide to Improving Data Scraping Efficiency
In the era of big data, efficient data crawling is the key for enterprises to analyze market trends and formulate strategies. However, facing the complexity of the network environment and the increasi...