시니어 데이터 과학자를 위한 생성형 AI 분야 테크 인터뷰 대비용으로, 50개의 질문과 답변을 직접 정리해보았습니다.
I. 트랜스포머(Transformer) 기본
-
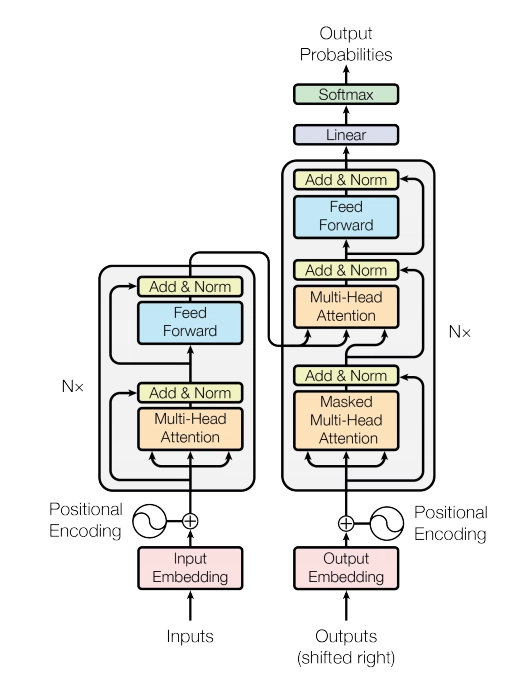
트랜스포머 아키텍처의 주요 구성 요소를 설명하고, 이들이 RNN/LSTM의 한계를 어떻게 극복하는지 설명해 주십시오.
트랜스포머는 순차적 처리 방식에 의존하는 RNN/LSTM의 병렬 처리 제약과 장거리 의존성 포착의 어려움을 셀프 어텐션 메커니즘을 통해 극복합니다. 셀프 어텐션은 시퀀스 내 모든 토큰 쌍의 관계를 동시에 계산하여 병렬 처리를 가능하게 하고, 각 토큰이 전체 시퀀스 정보를 활용하여 문맥을 파악하도록 돕습니다. 주요 구성 요소는 다음과 같습니다.- 셀프 어텐션(Self-Attention): 각 토큰이 시퀀스 내 다른 모든 토큰과의 관련성을 평가하여, 장거리 의존성을 효과적으로 포착하고 문맥 정보를 풍부하게 반영한 표현을 생성합니다.
- 멀티-헤드 어텐션(Multi-Head Attention, MHA): 셀프 어텐션을 병렬적으로 여러 번 수행합니다. 각 '헤드'는 입력 데이터의 서로 다른 특징 부분 공간(subspace)이나 관계에 집중하여, 모델이 더 다양하고 복합적인 패턴을 학습하도록 돕습니다.
- 포지션-와이즈 피드 포워드 네트워크(Position-wise Feed-Forward Network, FFN): 어텐션 계층을 통과한 각 토큰의 표현에 독립적으로 적용되는 완전 연결 신경망입니다. 비선형 변환을 통해 모델의 표현력을 높이고 계산 깊이를 더합니다.
- Add & Norm: 각 서브 계층(셀프 어텐션, FFN)의 입력과 출력을 더하는 잔차 연결(Residual Connection)과 레이어 정규화(Layer Normalization)를 적용합니다. 이는 깊은 네트워크에서 기울기 소실/폭발 문제를 완화하고 학습을 안정화하는 데 필수적입니다.
- 포지셔널 인코딩(Positional Encoding): 순서 정보가 없는 셀프 어텐션에 토큰의 위치 정보를 주입하여 시퀀스 순서를 모델이 인지하도록 합니다.
이러한 구성 요소들의 조합, 특히 병렬 처리 가능한 설계 덕분에 트랜스포머는 대규모 데이터셋과 모델 크기에 효과적으로 확장될 수 있습니다.
-
셀프 어텐션 메커니즘을 자세히 설명해 주십시오. 쿼리, 키, 밸류 벡터를 사용하여 어텐션 행렬은 어떻게 계산됩니까?
셀프 어텐션은 특정 토큰을 처리할 때 입력 시퀀스 내 다른 모든 토큰이 해당 토큰과 얼마나 관련 있는지 가중치를 계산하는 메커니즘입니다. 각 입력 토큰에 대해 학습 가능한 선형 변환을 통해 쿼리(Query, Q), 키(Key, K), 밸류(Value, V)라는 세 벡터를 생성합니다. 어텐션 가중치를 계산하는 과정은 다음과 같습니다:- 점수 계산: 현재 토큰의 쿼리 벡터(Q)와 시퀀스 내 모든 토큰(자기 자신 포함)의 키 벡터(K) 간의 유사도를 계산합니다. 일반적으로 스케일드 닷-프로덕트 어텐션(Scaled Dot-Product Attention) 방식, 즉 내적 후 키 벡터 차원의 제곱근으로 나누는 방식을 사용합니다. 이를 통해 어텐션 스코어(Attention Score)를 얻습니다.
- 정규화: 계산된 어텐션 스코어들에 소프트맥스(Softmax) 함수를 적용하여 합이 1이 되는 확률 분포 형태의 어텐션 가중치(Attention Weight)를 만듭니다. 이 가중치는 현재 토큰이 다른 각 토큰에 얼마나 '주의'를 기울여야 하는지를 나타냅니다.
- 가중 합: 각 토큰의 밸류 벡터(V)를 해당 어텐션 가중치로 가중 평균하여 현재 토큰의 최종 출력 표현을 생성합니다. 이 과정을 통해 각 토큰은 주변 문맥 정보를 효과적으로 통합한 풍부한 표현을 얻게 됩니다.
-
멀티 헤드 어텐션은 싱글 헤드 어텐션과 어떻게 다릅니까? 장점은 무엇입니까?
멀티-헤드 어텐션(Multi-Head Attention, MHA)은 단일 어텐션 연산을 수행하는 싱글-헤드 어텐션과 달리, 어텐션 메커니즘을 여러 개 병렬로 수행하는 방식입니다. 각 '헤드'는 독립적인 쿼리, 키, 밸류 투영(projection) 행렬을 학습하여, 입력 데이터의 서로 다른 특징 부분 공간(예: 구문적 관계, 의미적 유사성 등)이나 표현 관점에 집중합니다. 각 헤드에서 계산된 어텐션 출력들은 하나로 연결(concatenate)된 후, 추가적인 선형 변환을 거쳐 최종 출력을 형성합니다.MHA의 주요 장점은 모델이 다양한 관점에서 정보를 동시에 처리하고 통합하여, 단일 헤드보다 더 풍부하고 복합적인 관계를 포착할 수 있다는 것입니다. 이는 결과적으로 모델의 표현력과 성능을 향상시키며, 학습 과정을 안정화하는 데에도 기여할 수 있습니다.
-
포지셔널 인코딩이 필요한 이유는 무엇입니까? 절대적 방법과 상대적 방법(예: RoPE, ALiBi)을 비교해 주십시오.
트랜스포머의 셀프 어텐션 메커니즘은 토큰의 순서를 고려하지 않으므로(순서 불변성), 모델이 시퀀스 내 토큰의 위치 정보를 이해하도록 포지셔널 인코딩을 명시적으로 주입해야 합니다.- 절대적 포지셔널 인코딩: 각 토큰의 시퀀스 내 고정된 절대 위치에 기반하여 고유한 인코딩 벡터를 할당합니다. 원본 트랜스포머 논문에서 제안된 사인 및 코사인 함수를 이용한 방식이나, 각 위치별 임베딩을 학습하는 방식 등이 있습니다. 구현이 간단하지만, 훈련 시 보지 못한 길이의 시퀀스에 대한 일반화 성능이 떨어질 수 있다는 단점이 있습니다.
-
상대적 포지셔널 인코딩: 토큰의 절대 위치 대신 토큰 간의 상대적인 거리나 관계를 인코딩합니다. 이는 주로 어텐션 메커니즘 내에서 직접 이루어집니다.
-
RoPE (Rotary Position Embedding): 쿼리(Q)와 키(K) 벡터를 토큰의 위치에 따라 회전 변환시켜 상대적 위치 정보를 반영합니다.
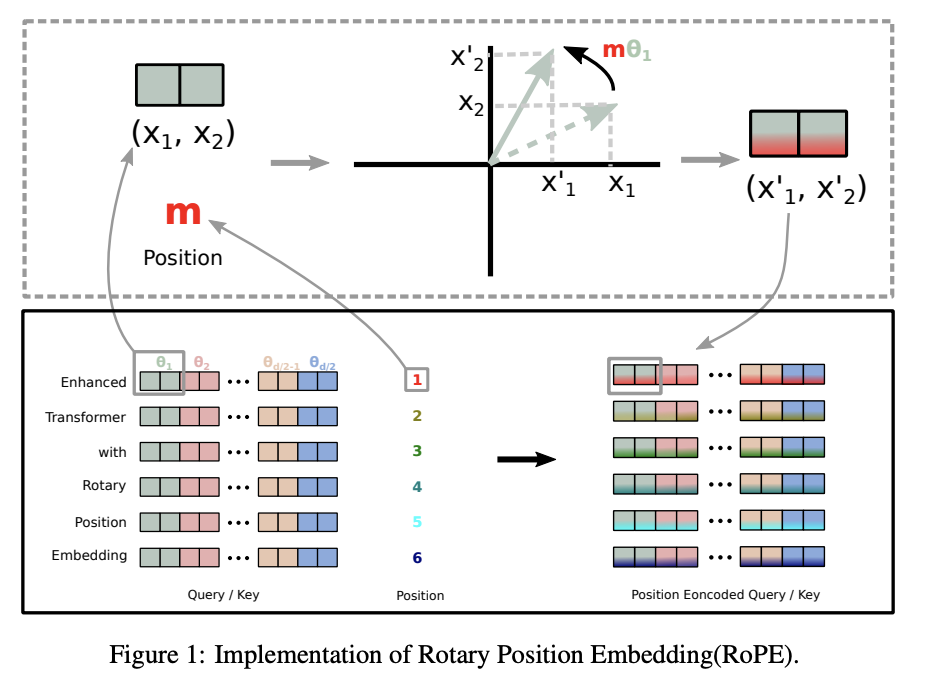
- ALiBi (Attention with Linear Biases): 어텐션 스코어를 계산할 때 토큰 간 거리에 비례하는 페널티(편향)를 추가하여 상대적 거리를 모델링합니다.
-
RoPE (Rotary Position Embedding): 쿼리(Q)와 키(K) 벡터를 토큰의 위치에 따라 회전 변환시켜 상대적 위치 정보를 반영합니다.
상대적 방법은 일반적으로 다양한 시퀀스 길이에 더 잘 일반화되는 경향이 있어 최신 트랜스포머 아키텍처에서 선호되며, 특히 ALiBi는 구현의 용이성으로 주목받습니다.
-
인코더-온리(예: BERT), 디코더-온리(예: GPT), 인코더-디코더(예: T5) 아키텍처를 구분하고 일반적인 적용 분야를 설명해 주십시오.
트랜스포머는 구성 요소(인코더, 디코더)의 조합 방식에 따라 크게 세 가지 아키텍처로 분류되며, 각각 다른 정보 처리 방식과 주된 적용 분야를 가집니다.- 인코더-온리 (Encoder-Only) 아키텍처 (예: BERT): 입력 시퀀스 전체를 한 번에 처리하며, 각 토큰의 표현을 계산할 때 양방향(bidirectional) 문맥 (앞뒤 토큰 모두)을 고려합니다. 입력 전체에 대한 깊은 이해가 중요한 자연어 이해(NLU) 작업(텍스트 분류, 개체명 인식, 질의응답 등)에 주로 사용됩니다.
- 디코더-온리 (Decoder-Only) 아키텍처 (예: GPT): 자기회귀적(autoregressive) 방식으로 작동하여, 출력 시퀀스를 한 토큰씩 순차적으로 생성합니다. 각 토큰을 예측할 때는 이전에 생성된 토큰들만을 참조합니다 (단방향(unidirectional) 또는 인과적(causal) 어텐션). 텍스트 생성, 챗봇, 요약 등 자연어 생성(NLG) 작업에 강점을 보입니다.
- 인코더-디코더 (Encoder-Decoder) 아키텍처 (예: 초기 트랜스포머, T5): 인코더가 입력 시퀀스를 처리하여 문맥 정보를 압축하고, 디코더가 이 정보를 (주로 크로스 어텐션(cross-attention)을 통해) 참조하여 출력 시퀀스를 생성합니다. 입력 시퀀스를 다른 형태의 출력 시퀀스로 변환하는 시퀀스-투-시퀀스(sequence-to-sequence) 작업(기계 번역, 문서 요약 등)에 적합합니다.
-
표준 트랜스포머(vanilla Transformer)의 계산적 한계는 무엇이며, 이를 해결하기 위한 접근 방식에는 어떤 것들이 있습니까?
표준 트랜스포머(Vanilla Transformer)의 주요 계산적 한계는 셀프 어텐션 연산량과 메모리 요구량이 시퀀스 길이(N)의 제곱(O(N²))에 비례하여 증가한다는 점입니다. 이는 모든 토큰 쌍 간의 어텐션 스코어를 계산하고 저장해야 하기 때문으로, 시퀀스 길이가 매우 길어지면(예: 수만 토큰 이상) 계산 비용이 감당하기 어려워집니다.
이러한 한계를 극복하기 위해 다양한 접근 방식이 제안되었습니다.-
희소 어텐션 (Sparse Attention): 모든 토큰 쌍을 계산하는 대신, 각 토큰이 미리 정의된 패턴(예: 인접 토큰, 특정 간격의 토큰, 일부 글로벌 토큰)에 따라 제한된 수의 다른 토큰에만 어텐션을 적용합니다. 이를 통해 계산 복잡도를 O(N log N) 또는 O(N) 수준으로 낮출 수 있습니다.
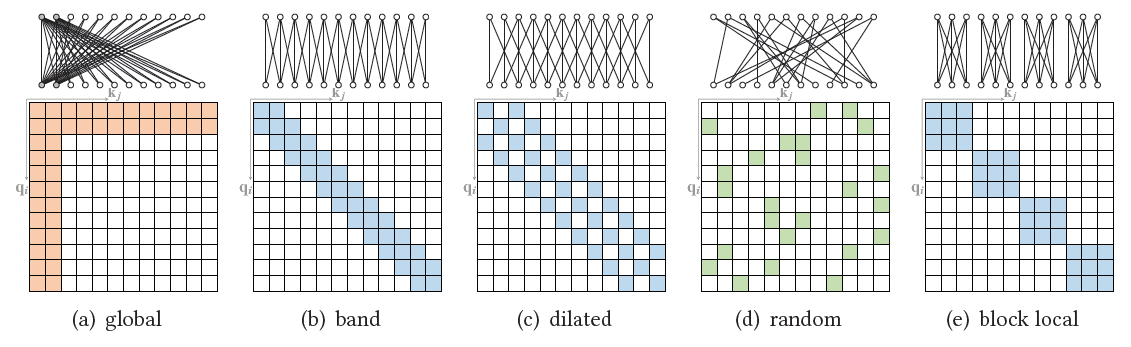
- 효율적/선형화 어텐션 (Efficient / Linearized Attention): 커널(kernel) 기법이나 저차원 근사(low-rank approximation) 등 수학적 방법을 사용하여 전체 어텐션 행렬을 명시적으로 계산하지 않고 어텐션 결과를 근사적으로 계산합니다. 선형 또는 거의 선형(near-linear) 복잡도를 목표로 합니다.
- 하드웨어 최적화: 어텐션 계산 자체는 변경하지 않지만, GPU 메모리 접근(읽기/쓰기) 병목 현상을 최소화하도록 연산 순서를 재구성하는 등 하드웨어 특성을 고려하여 실제 연산 속도를 높이는 기법입니다. FlashAttention이 대표적인 예시로, 정확한(exact) 어텐션 계산 속도를 크게 향상시킵니다.
- 대안 아키텍처: 트랜스포머와 다른 확장성 특성을 가진 상태 공간 모델(State Space Models, SSM)과 같은 새로운 시퀀스 모델링 아키텍처에 대한 연구도 활발히 진행 중입니다. 이러한 방법들은 트랜스포머가 더 긴 시퀀스를 효율적으로 처리하고 대규모 문제에 적용될 수 있도록 확장성을 개선하는 데 기여합니다.
-
희소 어텐션 (Sparse Attention): 모든 토큰 쌍을 계산하는 대신, 각 토큰이 미리 정의된 패턴(예: 인접 토큰, 특정 간격의 토큰, 일부 글로벌 토큰)에 따라 제한된 수의 다른 토큰에만 어텐션을 적용합니다. 이를 통해 계산 복잡도를 O(N log N) 또는 O(N) 수준으로 낮출 수 있습니다.
II. 고급 LLM 아키텍처 및 개념
스케일링 법칙(예: Kaplan, Chinchilla)이란 무엇이며, 사전 훈련 리소스 할당에 어떤 정보를 제공합니까?
스케일링 법칙(Scaling Laws)은 대규모 언어 모델(LLM)의 성능(주로 손실 값으로 측정)이 투입되는 자원, 즉 계산 예산(compute budget), 모델 크기(파라미터 수), 훈련 데이터 양(토큰 수)에 따라 예측 가능한 방식으로 개선되는 경험적 관계를 설명합니다. 이 관계는 종종 거듭제곱 법칙을 따르는 것으로 관찰되어, 자원 투입량에 따른 성능 향상을 어느 정도 예측하고 계획하는 것을 가능하게 합니다.
특히 Chinchilla 논문은 주어진 계산 예산 하에서 최적의 성능을 달성하기 위해서는 모델 크기(파라미터)와 훈련 데이터 양(토큰)을 거의 비슷한 비율로 함께 확장해야 한다고 제안하여 큰 영향을 미쳤습니다. 이는 모델의 학습 능력(파라미터 수)과 학습할 내용(데이터 양) 간의 균형이 중요함을 시사합니다. 이 연구는 이전의 많은 대형 모델들이 주어진 계산량 대비 모델 크기가 지나치게 크고 데이터 양은 상대적으로 부족했을 수 있으며('덜 훈련됨' 또는 '계산 비최적'), 동일 계산 예산으로 모델 크기를 줄이고 더 많은 데이터로 훈련했다면 더 나은 성능을 얻었을 수 있음을 암시했습니다.
따라서 스케일링 법칙은 사전 훈련 단계에서 제한된 계산 자원을 모델 크기와 데이터 양 사이에 어떻게 배분할지 결정하는 데 중요한 실증적 지침을 제공합니다. 단순히 가장 큰 모델을 만드는 것보다, 주어진 예산 내에서 최적의 성능을 위한 크기와 데이터 규모의 균형점을 찾는 것이 중요함을 강조합니다. 다만, 이러한 법칙은 경험적 관찰에 기반한 추정치이며, 실제 최적 비율이나 성능 개선 정도는 모델 아키텍처, 데이터 품질, 목표 태스크 등 다양한 요인에 따라 달라질 수 있음을 유의해야 합니다.-
LLM의 창발적 능력이란 무엇이며, 예를 들어 설명해 주십시오.
LLM의 창발적 능력(Emergent Capabilities)이란 모델의 규모(파라미터 수, 훈련 데이터, 계산량)가 특정 임계점을 넘어서면서 예측하기 어려웠던 방식으로 갑자기 나타나는 것처럼 보이는 새로운 능력들을 의미합니다. 이러한 능력들은 더 작은 규모의 모델에서는 관찰되지 않거나 성능이 매우 미미하며, 모델이 해당 능력을 갖도록 명시적으로 설계되거나 직접 훈련되지 않았다는 특징이 있습니다.
주요 예시는 다음과 같습니다.- 다단계 산술 연산 및 복잡한 논리 추론
- 별도의 미세 조정 없이 복잡한 지시사항을 이해하고 따르는 능력
- 아이러니, 유머 등 미묘한 언어적 뉘앙스 파악
- 일관성 있는 코드 생성
- 문제 해결 과정을 단계별로 설명하며 추론하는 연쇄적 사고(Chain-of-Thought) 추론
이러한 창발적 능력의 발견은 모델 규모를 확장하려는 강력한 동기가 되지만, 예측 불가능한 특성으로 인해 모델의 안전성, 신뢰성, 제어 가능성을 확보하는 데 어려움을 야기하기도 합니다.
-
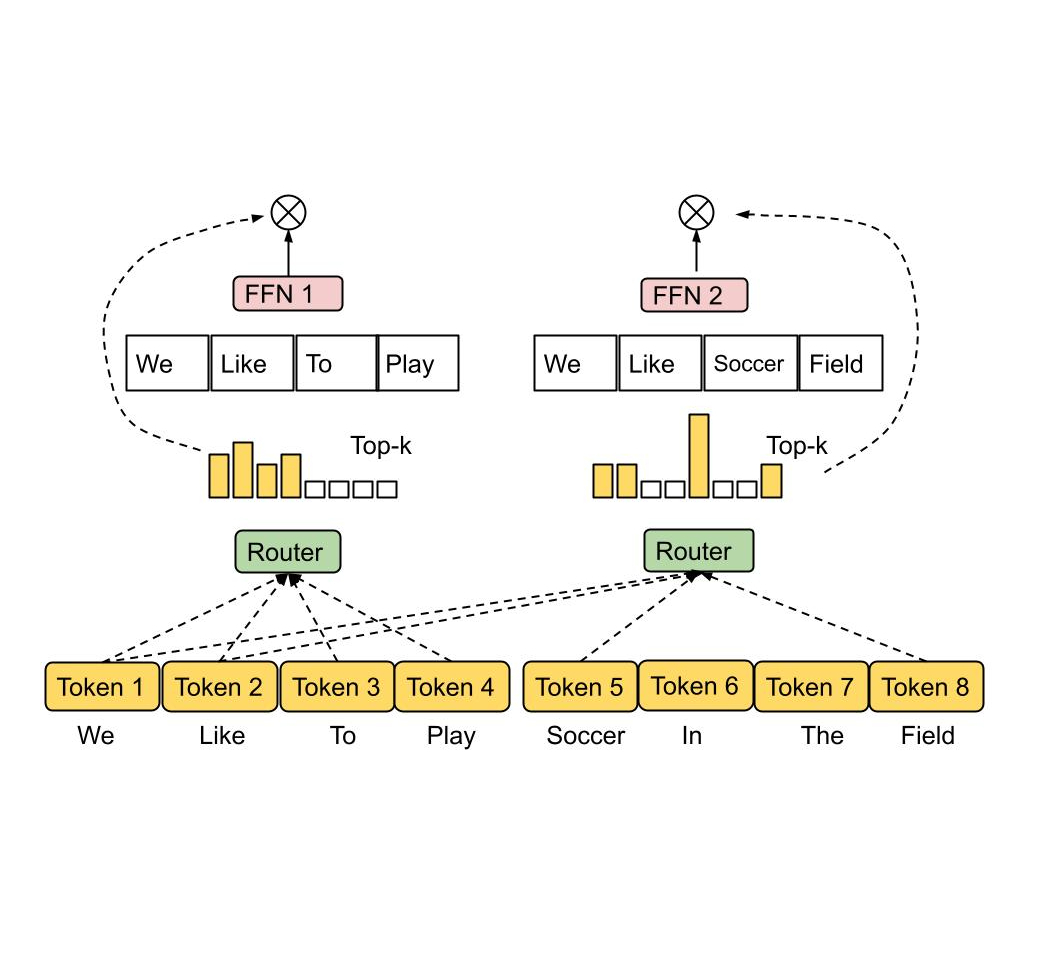
MoE 아키텍처를 설명해 주십시오. 밀집 모델(dense model)과 비교했을 때 장단점은 무엇입니까?
전문가 혼합(Mixture of Experts, MoE) 모델은 표준 트랜스포머 아키텍처의 일부 피드 포워드 네트워크 계층을 다수의 더 작고 독립적인 '전문가(expert)' 네트워크들로 대체하는 방식입니다. 각 입력 토큰에 대해, 학습 가능한 라우팅 네트워크가 가장 적합하다고 판단되는 소수의 전문가(보통 1~2개)를 동적으로 선택하여 해당 토큰을 처리하도록 보냅니다. 선택된 전문가들의 출력은 조합되어 최종 결과로 사용됩니다.장점:
- 확장성: 각 입력 토큰 처리 시 활성화되는 파라미터 수를 제한하면서 전체 모델의 파라미터 수를 크게 늘릴 수 있습니다. 이는 동일 추론 속도 대비 더 큰 모델 용량 확보를 가능하게 합니다.
- 추론 효율성: 주어진 토큰에 대해 소수의 전문가만 계산에 참여하므로, 밀집 모델(dense model)에 비해 추론 시 계산 비용(FLOPs)이 훨씬 적습니다.
- 전문가 특화: 각 전문가 네트워크가 특정 종류의 데이터나 패턴 처리에 특화되도록 학습될 잠재력이 있습니다.
단점:
- 훈련 및 구현 복잡성: 모든 전문가가 균형 있게 활용되도록(일부 전문가만 과도하게 사용되거나 유휴 상태가 되지 않도록) 부하 분산(load balancing)을 위한 추가적인 메커니즘(예: 보조 손실 함수)이 필요하며, 전체적인 훈련 안정성을 확보하기 어렵습니다.
- 메모리 요구량: 추론 시 계산에는 일부 전문가만 사용되더라도, 모든 전문가의 파라미터를 메모리에 로드해야 하므로 밀집 모델보다 훨씬 큰 메모리 용량이 필요합니다.
- 라우팅 오버헤드: 토큰을 전문가에게 할당하는 라우팅 계산 자체가 추가적인 연산 부담이 될 수 있습니다.
-
파라미터 효율성: 때로는 동일한 성능을 달성하기 위해 밀집 모델보다 더 많은 총 파라미터 수가 필요할 수 있습니다.
-
KV 캐싱, 멀티 쿼리 어텐션, 그룹 쿼리 어텐션이 추론 효율성을 어떻게 향상시키는지 설명해 주십시오.
KV 캐싱, 멀티-쿼리 어텐션, 그룹-쿼리 어텐션은 주로 디코더-온리 모델의 자기회귀적 텍스트 생성 과정에서 추론 효율성을 높이기 위한 기법들입니다.-
KV 캐싱(KV Caching): 자기회귀적 생성 시, 각 스텝에서 새로운 토큰을 예측하기 위해 이전까지 생성된 모든 토큰들에 대한 어텐션을 계산해야 합니다. 이때, 이전 토큰들의 키 및 밸류 벡터는 변하지 않는다는 점을 이용하여, 이미 계산된 키와 밸류 벡터들을 메모리(캐시)에 저장해두고 다음 스텝에서 재활용하는 기법입니다. 이를 통해 매 스텝마다 전체 시퀀스에 대한 키/밸류 계산을 반복하는 것을 피해 계산량을 크게 줄일 수 있습니다. 하지만 시퀀스 길이가 길어질수록 캐시가 차지하는 메모리 양이 매우 커진다는 단점이 있습니다.
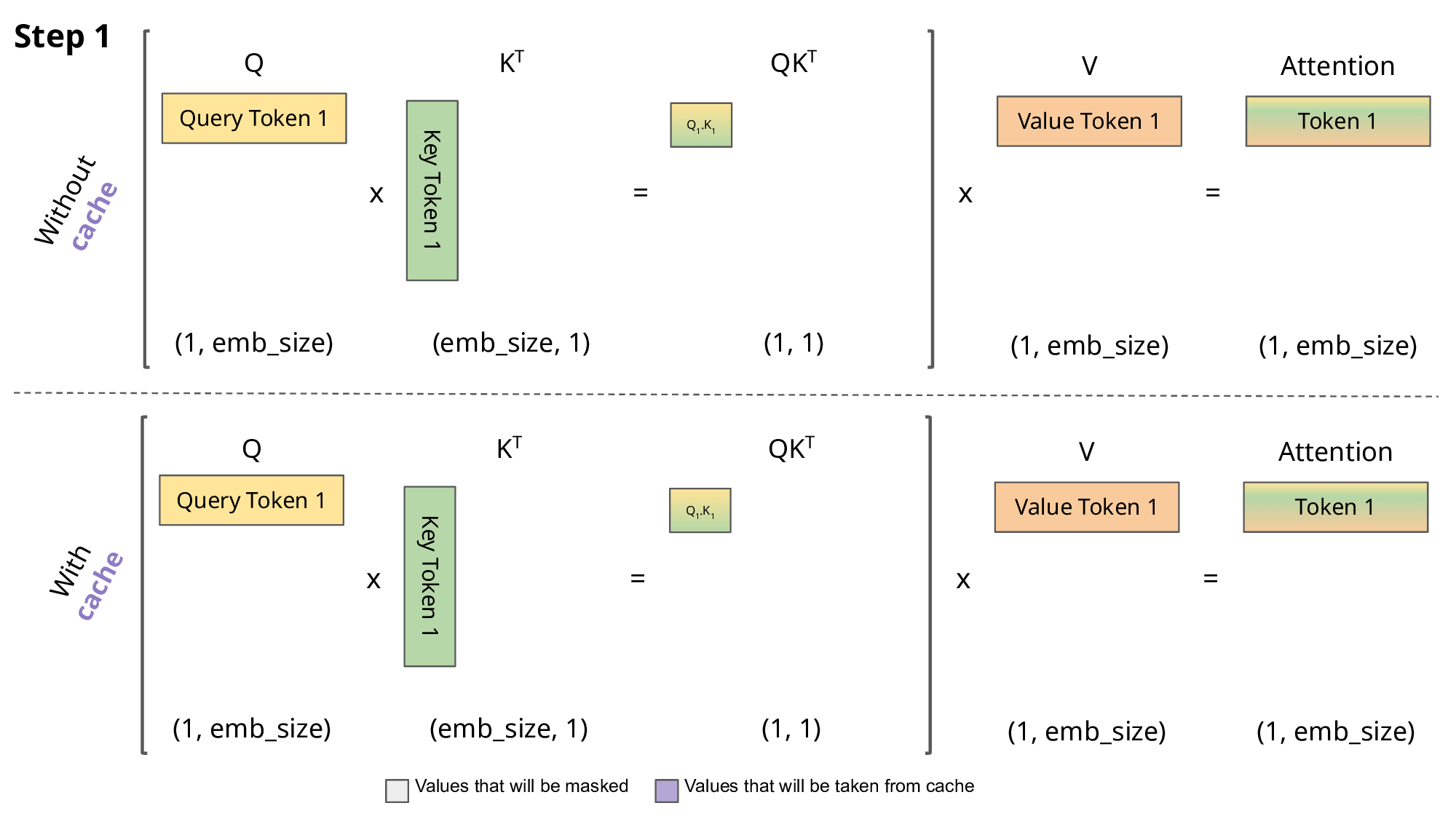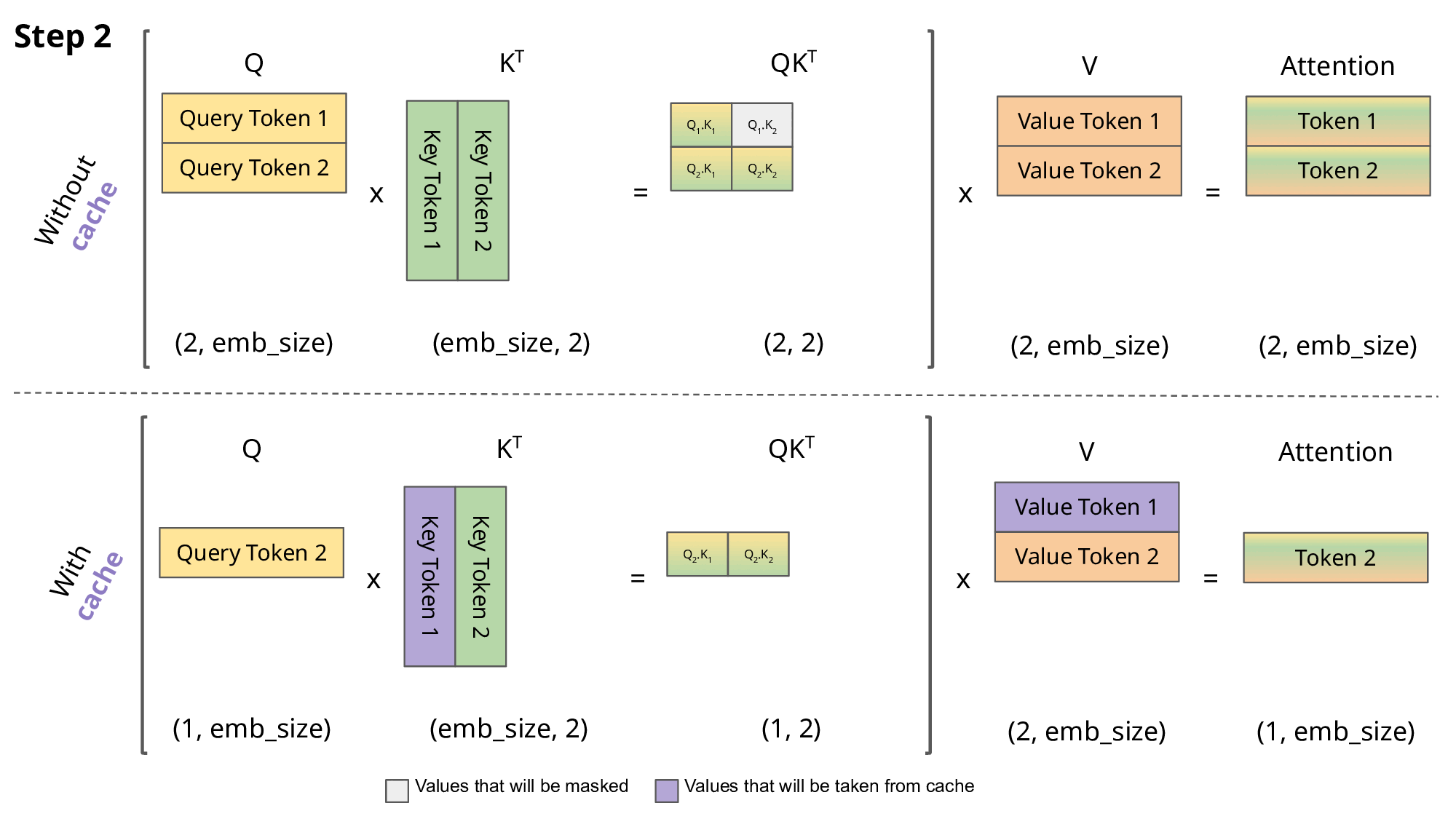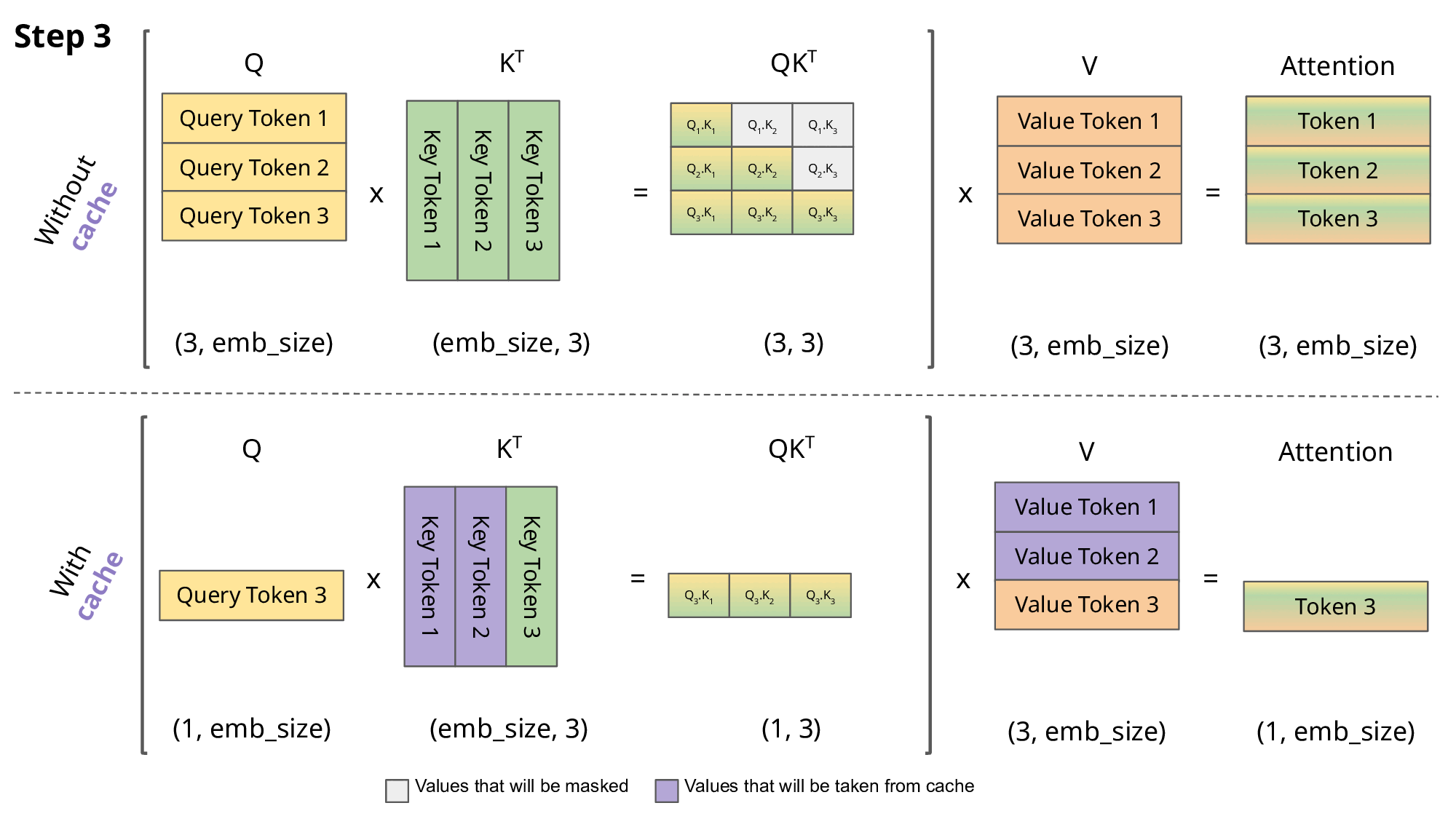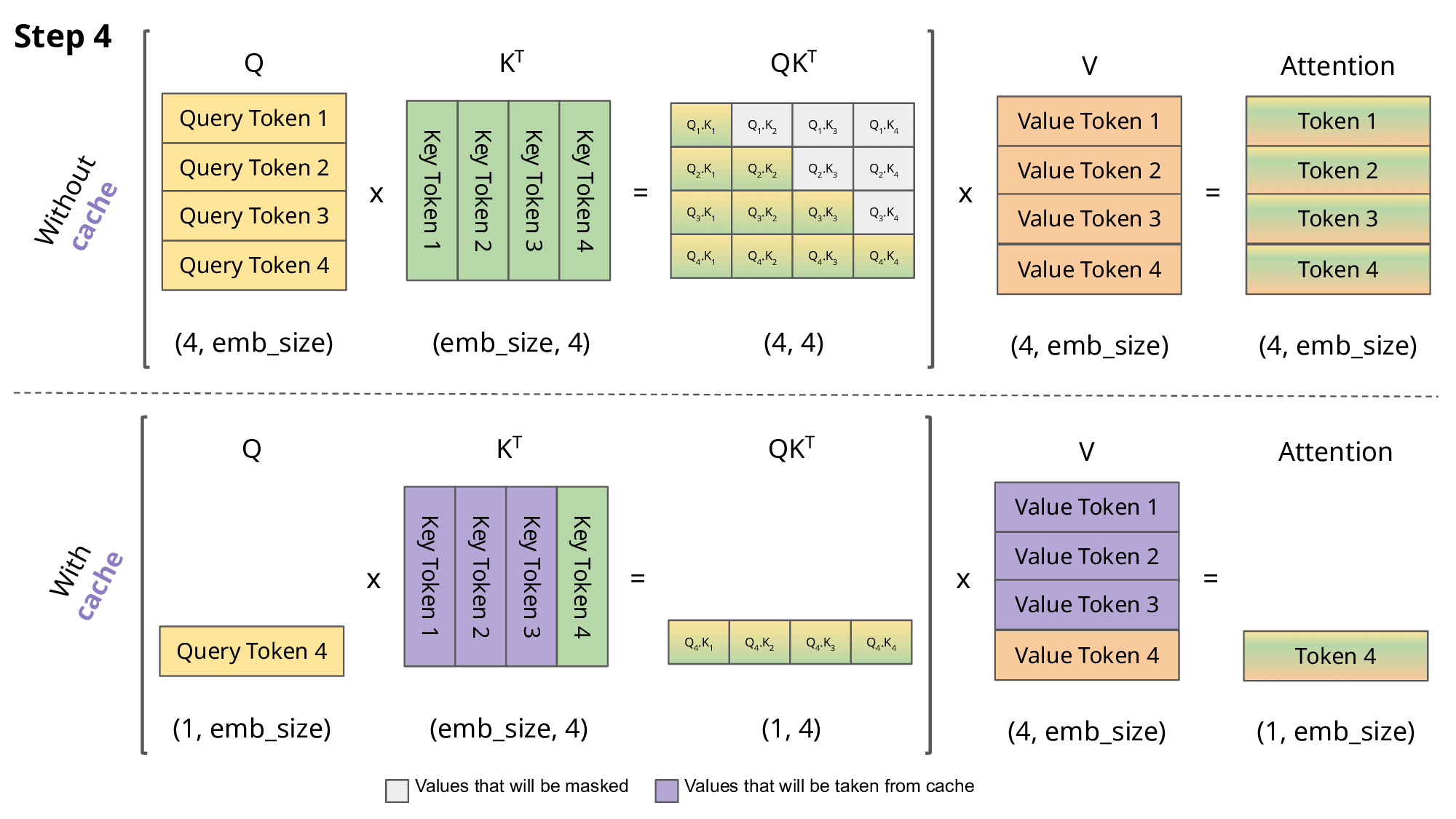
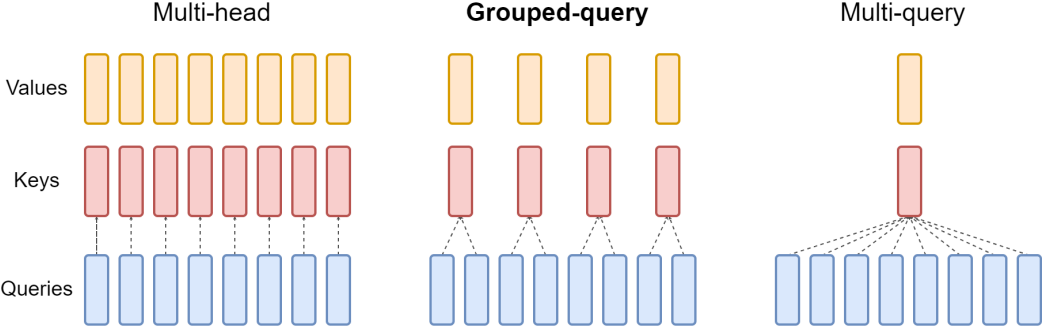
- 멀티-쿼리 어텐션 (Multi-Query Attention, MQA): 표준 멀티-헤드 어텐션(MHA)에서는 각 어텐션 헤드가 자신만의 키 및 밸류 투영 행렬을 가지지만, MQA에서는 모든 쿼리 헤드가 단 하나의 키와 밸류 헤드(즉, 투영 행렬)를 공유합니다. 이로 인해 저장해야 할 KV 캐시의 크기가 헤드 수만큼 줄어들어 메모리 사용량과 메모리 대역폭 요구량을 크게 절감할 수 있습니다.
-
그룹-쿼리 어텐션 (Grouped-Query Attention, GQA): GQA는 표준 MHA와 MQA 사이의 절충안입니다. 쿼리 헤드들을 여러 그룹으로 나누고, 각 그룹 내의 쿼리 헤드들이 하나의 키 및 밸류 헤드를 공유합니다. MQA보다는 KV 캐시 크기가 크지만, 표준 MHA보다는 훨씬 작습니다. 이를 통해 메모리 사용량을 크게 줄이면서도, MQA에서 발생할 수 있는 품질 저하를 완화하여 MQA보다 더 나은 성능 균형을 보이는 경우가 많습니다.
-
KV 캐싱(KV Caching): 자기회귀적 생성 시, 각 스텝에서 새로운 토큰을 예측하기 위해 이전까지 생성된 모든 토큰들에 대한 어텐션을 계산해야 합니다. 이때, 이전 토큰들의 키 및 밸류 벡터는 변하지 않는다는 점을 이용하여, 이미 계산된 키와 밸류 벡터들을 메모리(캐시)에 저장해두고 다음 스텝에서 재활용하는 기법입니다. 이를 통해 매 스텝마다 전체 시퀀스에 대한 키/밸류 계산을 반복하는 것을 피해 계산량을 크게 줄일 수 있습니다. 하지만 시퀀스 길이가 길어질수록 캐시가 차지하는 메모리 양이 매우 커진다는 단점이 있습니다.
III. 고급 훈련 및 파인튜닝 기법
-
데이터 정제, 전처리, 그리고 토크나이저(예: BPE) 선택이 LLM 훈련 및 성능에 어떤 영향을 미칩니까?
데이터 품질과 이를 처리하는 방식은 LLM 훈련 결과와 최종 성능에 결정적인 영향을 미칩니다. 모델은 제공된 데이터로부터 직접 학습하므로, 데이터 내의 결함, 편향, 노이즈까지 그대로 학습하게 됩니다. 따라서 고품질 LLM을 위해서는 세심한 데이터 전처리 과정이 필수적입니다. 주요 단계는 다음과 같습니다.- 데이터 정제: 노이즈(예: HTML 태그 제거), 불일치성, 형식 오류 등을 수정합니다.
- 중복 제거: 훈련 데이터 내 중복된 내용을 제거하여 학습 효율성을 높이고 모델이 단순히 데이터를 암기하는 것을 방지합니다.
- 품질 필터링: 저품질 또는 부적절한 콘텐츠(예: 욕설, 스팸)를 식별하고 제거합니다.
- 개인정보 및 민감정보 처리: 개인 식별 정보나 민감한 내용을 제거하거나 마스킹합니다.
토크나이저(Tokenizer) 선택 역시 중요합니다. 토크나이저는 텍스트를 모델이 이해할 수 있는 정수 시퀀스(토큰 ID)로 변환하는 역할을 합니다. 바이트 페어 인코딩(Byte Pair Encoding, BPE)과 같은 서브워드(subword) 기반 토크나이저가 널리 사용됩니다. BPE는 빈번하게 등장하는 문자열 쌍을 점진적으로 병합하여 어휘 사전을 구축합니다.
- 어휘 사전 크기: 큰 어휘 사전은 텍스트를 더 적은 수의 토큰으로 압축하여 시퀀스 길이를 줄이고 계산 효율성을 높일 수 있지만, 모델의 임베딩 행렬 크기가 커져 메모리 요구량이 증가하는 트레이드오프가 있습니다.
- 효율성 및 성능: 데이터 특성(예: 코드, 다국어)에 잘 맞는 효율적인 토크나이저를 사용하면 시퀀스 길이를 줄여 계산 부담을 낮추고, 모델이 처리할 수 있는 유효 컨텍스트 길이를 늘릴 수 있습니다. 반대로, 부적절한 토크나이저는 모델 성능 저하를 유발하고, 때로는 보안 취약점으로 이어질 수도 있습니다.
-
대규모 트랜스포머 훈련을 안정화하는 기술에는 어떤 것들이 있습니까?
매우 큰 트랜스포머 모델을 훈련하는 과정은 불안정하여 손실 값이 갑자기 급증하거나 발산하는 문제가 발생하기 쉽습니다. 이러한 훈련 불안정성을 완화하고 안정적인 학습을 위해 다음과 같은 기술들이 조합되어 사용됩니다.- 학습률 스케줄링 (Learning Rate Scheduling): 훈련 초기에는 학습률을 서서히 증가시키는 워밍업(warm-up) 단계를 거치고, 이후 학습률을 점진적으로 감소시키는 감쇠(decay) (예: 코사인 감쇠)를 적용하여 최적화 과정을 안정시킵니다.
- 그래디언트 클리핑 (Gradient Clipping): 그래디언트 벡터의 크기가 특정 임계값을 넘지 않도록 조정하여, 그래디언트 폭발 현상을 방지합니다.
- 안정적인 옵티마이저 사용: 표준 Adam 옵티마이저와 L2 정규화를 함께 사용하는 것보다 가중치 감쇠(weight decay) 처리가 개선된 AdamW와 같은 옵티마이저가 일반적으로 더 안정적인 훈련을 제공합니다.
- 신중한 가중치 초기화: 모델 파라미터의 초기값을 적절히 설정하여 훈련 시작 시 활성화 값과 그래디언트가 안정적인 범위 내에 있도록 합니다.
- 레이어 정규화: 트랜스포머 블록 내에서 활성화 값의 분포를 정규화하여 네트워크 전체의 신호 전달을 안정화하는 핵심 요소입니다.
- 적절한 수치 정밀도 사용: 표준 16비트 부동소수점(FP16) 대신 BFloat16을 사용하거나, 옵티마이저 상태 등 중요한 부분에 더 높은 정밀도를 사용하는 혼합 정밀도(mixed precision) 훈련을 통해 수치적 안정성을 향상시킬 수 있습니다.
-
명령어 튜닝은 일반적인 SFT와 어떻게 다릅니까? 거부 샘플링은 무엇입니까?
지도 파인튜닝(Supervised Fine-tuning, SFT)은 사전 훈련된 모델을 특정 작업에 대한 레이블된 예시 데이터(입력과 정답 출력 쌍)를 사용하여 미세 조정하는 일반적인 과정을 의미합니다.
명령어 튜닝(Instruction Tuning)은 SFT의 한 형태로, 훈련 데이터가 명시적인 '지시사항'과 그에 따른 '바람직한 출력' 쌍으로 구성된다는 특징이 있습니다. (예: "다음 문장을 요약하세요: [긴 문장]" → "[요약된 문장]"). 명령어 튜닝의 목표는 단순히 특정 다운스트림 태스크 성능을 높이는 것을 넘어, 모델이 다양한 형태의 자연어 지시를 이해하고 이를 따르는 일반적인 능력을 학습하도록 하는 것입니다. 이는 모델의 범용성을 높이고, 처음 보는 새로운 작업에 대한 제로샷(zero-shot) 또는 퓨샷(few-shot) 일반화 성능을 향상시키는 데 기여합니다.
거부 샘플링(Rejection Sampling)은 명령어 튜닝 또는 일반적인 SFT를 위한 데이터셋의 품질을 향상시키는 데 사용되는 데이터 큐레이션 기법 중 하나입니다. 과정은 다음과 같습니다.- 주어진 지시사항(프롬프트)에 대해 현재 모델을 사용하여 여러 개의 응답 후보를 생성합니다.
- 미리 정의된 기준(예: 별도의 보상 모델 점수, 특정 규칙 만족 여부, 인간 평가)을 사용하여 각 응답의 품질을 평가합니다.
- 평가 점수가 가장 높은, 즉 가장 품질이 좋은 응답만을 선별하여 최종 파인튜닝 데이터셋에 포함시킵니다. 이를 통해 품질이 낮은 응답을 걸러내고 양질의 예시 데이터만으로 모델을 학습시켜 최종 모델의 성능과 정렬 수준을 높일 수 있습니다.
-
RLHF, RLAIF, DPO/GRPO 같은 정렬 방법을 비교 설명해 주십시오. 핵심 메커니즘과 장단점은 무엇입니까?
LLM을 인간의 의도 및 가치와 일치하도록 만드는 '정렬(alignment)' 과정, 즉 모델이 유용하고(helpful), 정직하며(honest), 무해하도록(harmless) 만드는 과정에는 다양한 기법이 사용됩니다. 주요 방법들을 비교하면 다음과 같습니다.-
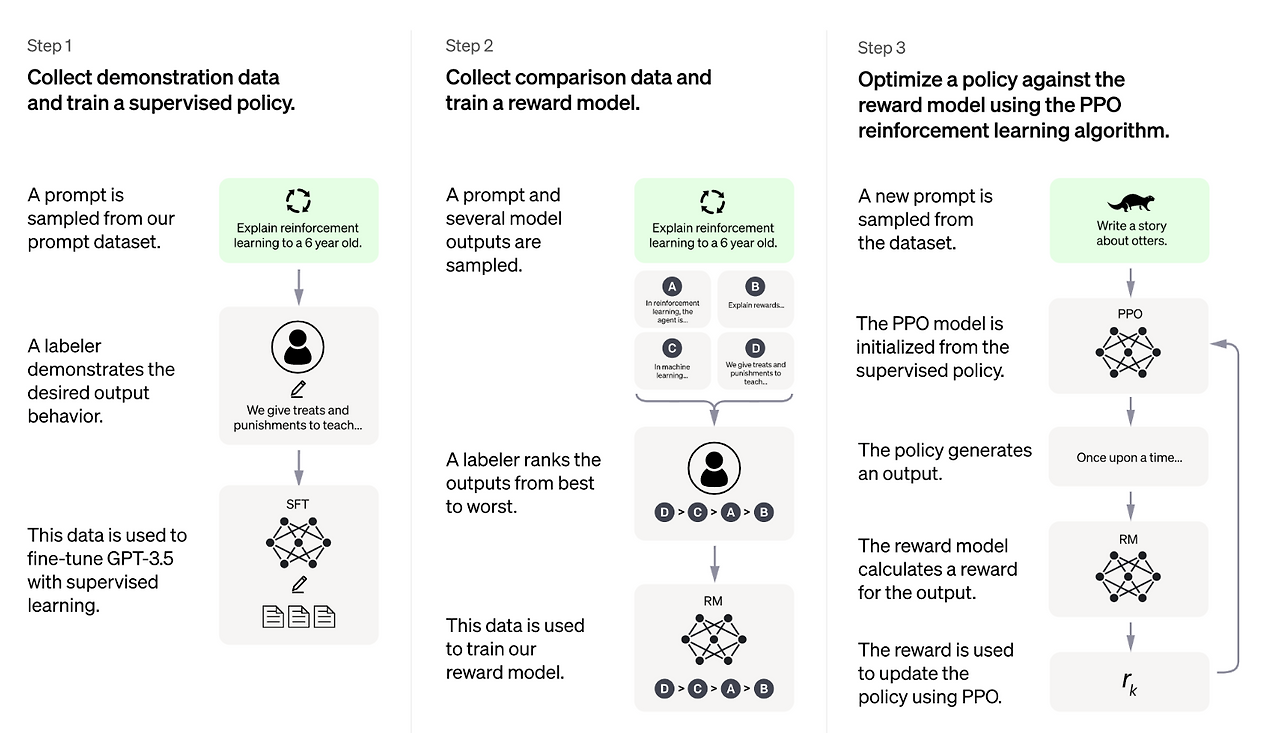
인간 피드백 기반 강화 학습 (Reinforcement Learning from Human Feedback, RLHF):
- 핵심 메커니즘: 1) 인간 평가자가 LLM이 생성한 여러 응답 중 선호하는 것을 선택하여 선호도 데이터를 구축합니다. 2) 이 데이터를 사용하여 어떤 응답이 더 좋은지를 예측하는 별도의 '보상 모델(Reward Model, RM)'을 학습시킵니다. 3) 이 보상 모델을 강화 학습(RL, 예: PPO) 알고리즘의 보상 함수로 사용하여 원래 LLM을 파인튜닝합니다.
- 장점: 인간의 미묘한 선호도를 직접 반영하여 정렬 품질이 높을 수 있습니다.
-
단점: 인간 선호도 데이터 수집 비용이 높고, 전체 프로세스가 복잡하며, 학습된 보상 모델의 품질에 최종 성능이 크게 의존합니다.
-
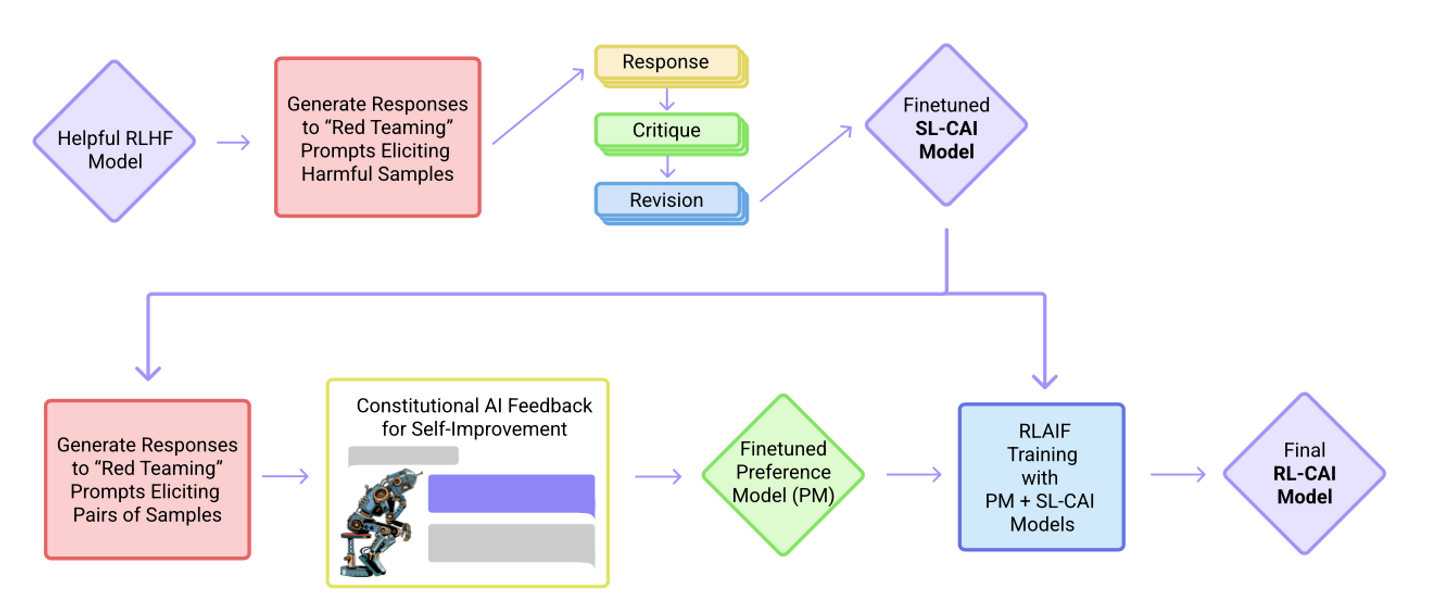
AI 피드백 기반 강화 학습 (Reinforcement Learning from AI Feedback, RLAIF):
- 핵심 메커니즘: RLHF와 유사하나, 비용이 많이 드는 인간 평가자 대신 강력한 다른 AI 모델을 사용하여 선호도 레이블을 생성합니다. 이후 과정은 RLHF와 동일합니다 (AI 생성 데이터로 RM 학습 → RL로 LLM 파인튜닝).
- 장점: 대규모 선호도 데이터 생성이 용이하여 확장성이 좋습니다.
-
단점: 최종 정렬 품질이 레이블 생성에 사용된 AI 모델의 성능과 편향에 의존합니다.
-
직접 선호도 최적화 (Direct Preference Optimization, DPO):
- 핵심 메커니즘: 별도의 보상 모델 학습이나 강화 학습 단계 없이, 선호도 데이터(선호 응답, 비선호 응답 쌍)를 사용하여 LLM을 직접 파인튜닝합니다. 특정 손실 함수를 사용하여 선호되는 응답의 생성 확률은 높이고 비선호 응답의 생성 확률은 낮추도록 직접 학습합니다.
- 장점: 구현이 RLHF/RLAIF보다 훨씬 간단하고 훈련이 안정적입니다.
- 단점: 때로는 RLHF만큼 정교한 제어나 최대 성능 달성이 어려울 수 있습니다.
-
그룹 상대 정책 최적화 (Group Relative Policy Optimization, GRPO):
- 핵심 메커니즘: RL 기반 접근법이지만, 개별 응답 대신 여러 응답 그룹 간의 상대적 선호도를 활용합니다. 특히, 보상 모델이나 별도의 가치 함수(value/critic model)를 명시적으로 학습하는 대신, 그룹 내 응답 점수의 통계량(예: 평균)을 암시적 베이스라인으로 사용하여 정책 그래디언트를 계산합니다.
- 장점: 별도의 가치 모델이 필요 없어 훈련 중 메모리 등 자원 효율성을 높일 수 있습니다.
- 단점: 비교적 최신 방법론이며, 적용 및 최적화에 노하우가 필요할 수 있습니다.
요약하면, RLHF와 RLAIF는 보상 모델링과 강화 학습을 결합하며 피드백 소스(인간/AI)에서 차이가 납니다. DPO는 보상 모델링과 RL을 생략하여 단순성을 추구합니다. GRPO는 RL 프레임워크 내에서 그룹 비교와 효율적인 베이스라인 추정을 통해 자원 효율성을 개선합니다. 적합한 방법은 목표 정렬 수준, 가용 데이터, 계산 자원, 구현 복잡성 등을 고려하여 선택됩니다.
-
인간 피드백 기반 강화 학습 (Reinforcement Learning from Human Feedback, RLHF):
-
RLHF를 위한 보상 모델 설계 시 주요 고려 사항은 무엇입니까?
RLHF의 성공은 LLM 파인튜닝 과정에서 인간의 판단을 대리하는 보상 모델의 품질에 크게 좌우됩니다. 효과적인 RM을 설계하고 훈련할 때 주요 고려 사항은 다음과 같습니다.- 선호도 데이터의 품질과 다양성: 훈련 데이터에 사용되는 인간 선호도 데이터의 품질이 낮거나 특정 방향으로 편향되어 있다면, 학습된 RM 역시 편향되거나 부정확해져 최종 정렬 결과에 악영향을 미칩니다. 따라서 고품질의 다양하고 일관성 있는 데이터 확보가 매우 중요합니다.
- 선호도 강도 반영: 이상적으로 RM은 단순히 어떤 응답이 더 낫다는 이진적인 판단을 넘어, 그 선호도의 강도(얼마나 더 나은지)까지 포착할 수 있어야 합니다.
- 보정 (Calibration): RM이 출력하는 점수 차이가 실제 인간이 느끼는 선호도 강도의 차이를 정확하게 반영하도록 보정하는 것이 중요합니다. 보정되지 않은 RM은 최적화 과정에서 잘못된 방향으로 유도할 수 있습니다.
- 모델 아키텍처 및 손실 함수: RM의 아키텍처(종종 정렬 대상 LLM 기반으로 초기화)와 훈련에 사용될 손실 함수를 신중하게 선택해야 합니다.
- 보상 해킹 (Reward Hacking) 방지: LLM이 실제 인간 선호도를 따르기보다 단순히 RM으로부터 높은 점수를 받기 위해 RM의 허점이나 잘못 학습된 패턴을 악용하는 '보상 해킹' 현상에 강건해야 합니다.
- RM 평가의 어려움: RM 자체의 성능을 평가하는 것은 까다롭습니다. 선호도 쌍 데이터에 대한 예측 정확도가 높다고 해서 반드시 최종 정렬된 LLM의 품질이 우수하다는 보장은 없습니다.
- 일반화 성능: RM은 훈련 데이터에만 과적합되지 않고, 처음 보는 응답들에 대해서도 인간의 선호도를 잘 예측할 수 있도록 일반화 성능을 갖추어야 합니다.
-
추론 모델 학습에서 RLHF와 RLVR은 어떤 차이가 있으며, DeepSeek-R1 개발에는 어떤 방식이 주로 사용되었나요?
RLHF와 RLVR(검증 가능한 보상 기반 강화 학습, Reinforcement Learning from Verifiable Rewards)은 모두 강화 학습을 통해 LLM을 개선하는 방법이지만, 보상을 정의하고 제공하는 방식에서 핵심적인 차이가 있습니다.- RLHF: 보상의 기준이 인간의 주관적인 선호도에 있습니다. 인간 평가자가 모델 응답들 간의 선호도를 판단하고(예: 어떤 응답이 더 유용하고, 안전한지), 이를 바탕으로 학습된 보상 모델이 강화 학습 과정에서 보상 신호를 제공합니다. 주로 모델의 대화 능력, 스타일, 안전성 등 주관적이고 복합적인 품질을 개선하는 데 사용됩니다.
-
RLVR: 보상의 기준이 객관적으로 검증 가능한 외부 규칙이나 도구에 있습니다. 예를 들어, 수학 문제 해결 시 외부 계산기를 통해 정답 여부를 확인하거나, 코드 생성 시 컴파일러로 실행 가능 여부 및 테스트 케이스 통과 여부를 확인하여 보상을 제공합니다. 별도의 보상 모델 학습이 필요 없는 경우가 많아 과정이 더 단순하고, 보상 기준이 명확하며 객관적입니다. 특정 작업의 정확성, 규칙 준수 능력 향상에 효과적입니다.
DeepSeek-R1 개발, 특히 추론 능력 강화에는 주로 RLVR 방식이 핵심적으로 활용되었습니다. 초기 강화 학습 단계에서 수학 문제 정답 확인, 코드 실행 결과 검증 등 규칙 기반의 '정확성 보상(accuracy rewards)'과 모델이 추론 과정을 특정 형식(
)으로 생성하도록 유도하는 '형식 보상(format rewards)' (RLVR의 일종)을 사용하여 추론 능력을 집중적으로 학습시켰습니다. 이후, 최종 단계에서는 이렇게 확보된 추론 능력 위에 인간 선호도를 반영하는 RLHF 방식 (또는 유사한 보상 모델 기반 방식)을 보조적으로 사용하여 모델의 전반적인 대화 능력, 유용성, 무해성 등을 추가로 개선했습니다. 즉, DeepSeek-R1의 추론 능력 향상에는 RLVR이 중추적인 역할을 담당했고, RLHF는 보완적으로 기여했다고 볼 수 있습니다.
-
LoRA/QLoRA와 같은 PEFT 방법을 설명해 주십시오. 왜 사용하며, 특히 QLoRA는 어떤 문제를 해결합니까?
파라미터 효율적 파인튜닝(Parameter-Efficient Fine-tuning, PEFT) 기법들은 사전 훈련된 대규모 언어 모델 전체를 미세 조정하는 대신, 모델 파라미터 중 극히 일부만을 업데이트하여 특정 작업이나 요구사항에 맞게 모델을 조정하는 방법론입니다. 이를 통해 파인튜닝에 필요한 계산 자원, 특히 메모리 사용량을 크게 절감할 수 있습니다.-
LoRA (Low-Rank Adaptation): 널리 사용되는 PEFT 기법 중 하나입니다. 핵심 아이디어는 사전 훈련된 모델의 원래 가중치는 동결시킨 채로, 특정 계층(주로 어텐션 계층)에 작고 학습 가능한 '어댑터' 행렬을 추가하는 것입니다. 이 어댑터는 일반적으로 원래 가중치 행렬의 변화량을 나타내는 두 개의 저차원(low-rank) 행렬의 곱으로 표현되며, 파인튜닝 시에는 이 작은 어댑터 행렬들만 학습합니다.
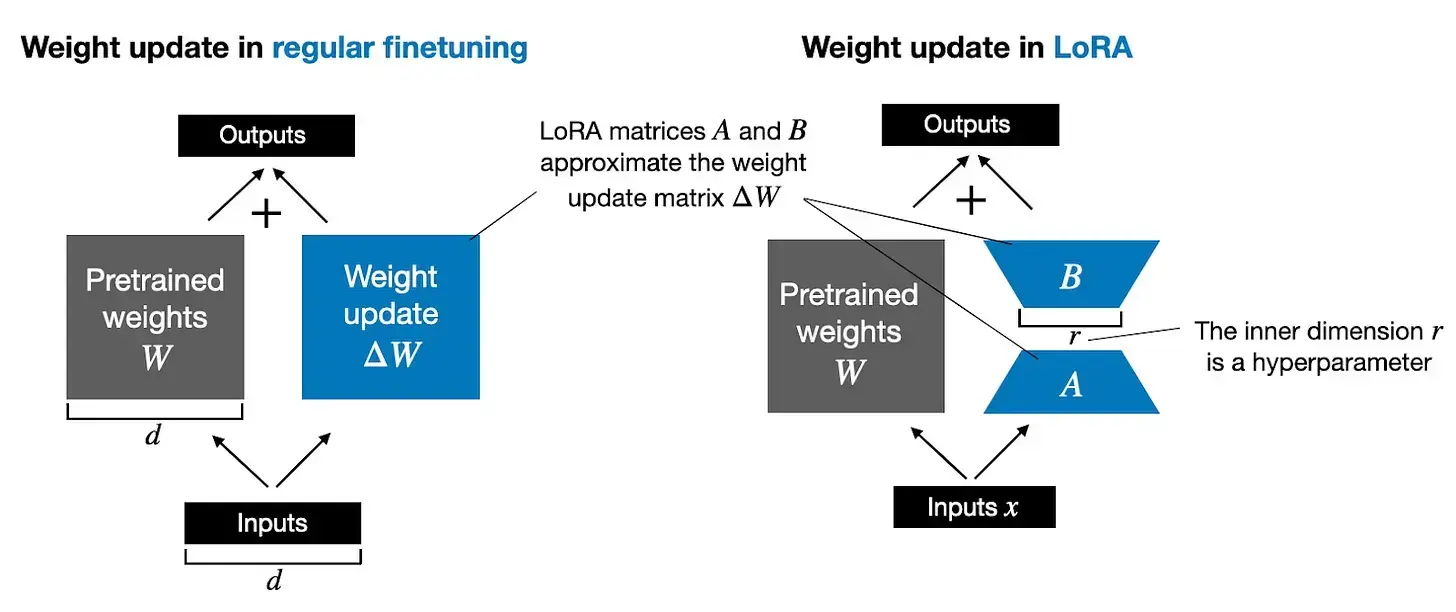
- QLoRA (Quantized LoRA): LoRA를 기반으로 메모리 사용량을 더욱 극적으로 줄이는 기법입니다. 핵심은 동결된 거대 기본 모델의 가중치를 4비트와 같은 매우 낮은 정밀도로 양자화(quantization)하여 메모리에 로드하는 것입니다. 그래디언트 계산은 이 양자화된 가중치를 통해 이루어지지만, 실제 업데이트는 여전히 더 높은 정밀도(예: BFloat16)로 유지되는 작은 LoRA 어댑터에만 적용됩니다. 추가적으로 이중 양자화(double quantization), 페이징된 옵티마이저(paged optimizers) 등의 메모리 최적화 기술을 함께 사용합니다. QLoRA는 매우 큰 모델(수십~수백억 파라미터)도 메모리가 제한된 환경(예: 단일 소비자용 GPU)에서 파인튜닝하는 것을 가능하게 만들어 LLM 접근성을 크게 높였습니다.
-
LoRA (Low-Rank Adaptation): 널리 사용되는 PEFT 기법 중 하나입니다. 핵심 아이디어는 사전 훈련된 모델의 원래 가중치는 동결시킨 채로, 특정 계층(주로 어텐션 계층)에 작고 학습 가능한 '어댑터' 행렬을 추가하는 것입니다. 이 어댑터는 일반적으로 원래 가중치 행렬의 변화량을 나타내는 두 개의 저차원(low-rank) 행렬의 곱으로 표현되며, 파인튜닝 시에는 이 작은 어댑터 행렬들만 학습합니다.
-
파인튜닝한 모델을 병합하는 기술(예: Task Arithmetic, SLERP)과 그 목적을 간략히 설명해 주십시오.
모델 병합(Model Merging)은 일반적으로 동일한 기본 모델에서 파인튜닝된 두 개 이상의 모델 파라미터를 결합하여, 추가적인 훈련 없이 새로운 단일 모델을 만드는 기술입니다. 주된 목적은 다음과 같습니다.- 다중 능력 결합: 서로 다른 작업(예: 코딩 능력, 대화 능력)에 특화된 모델들을 합쳐 다재다능한 모델 만들기
- 성능 향상: 개별 모델의 장점을 통합하여 일반화 성능 개선 기대
- 배포 간소화: 여러 특화 모델 대신 단일 통합 모델을 배포하여 관리 용이성 증대
주요 병합 기법들은 다음과 같습니다.
- 가중치 평균: 각 모델의 파라미터에 특정 가중치를 부여하여 단순 평균 또는 가중 평균을 계산하는 가장 기본적인 방식입니다.
- 구면 선형 보간법 (SLERP, Spherical Linear Interpolation): 모델 파라미터 벡터 공간 상에서 단순 직선(선형 보간)이 아닌, 구면 상의 호(arc)를 따라 보간하여 더 자연스러운 중간 지점을 찾으려는 기법입니다.
- 태스크 산술 (Task Arithmetic): 파인튜닝된 모델과 원본 기본 모델 간의 파라미터 차이, 즉 '태스크 벡터'를 계산한 뒤, 이 벡터들을 (때로는 가중치를 적용하여) 원본 모델에 더하거나 빼는 방식으로 병합합니다.
- 고급 병합 기법: 여러 모델을 병합할 때 발생하는 파라미터 간 충돌(예: 부호 불일치) 문제를 해결하기 위해, TIES-Merging이나 DARE와 같이 불필요하거나 충돌하는 파라미터를 제거(pruning)하거나, 부호를 조정하거나, 선택적으로 파라미터 값을 리셋하는 등의 전략을 사용하는 더 정교한 방법들도 제안되었습니다.
이러한 모델 병합 기술들은 추가적인 훈련 비용 없이, 이미 학습된 지식과 능력을 효과적으로 결합할 수 있는 방법을 제공합니다.
-
지속적 사전 훈련 또는 연속 학습 시스템을 설계할 때 마주하게 되는 핵심적인 기술적 어려움들과 그에 따른 실질적인 트레이드오프는 무엇이며, 이러한 문제들을 완화하기 위해 주로 어떤 접근 방식들이 사용됩니까?
지속적 사전 훈련(Continuous Pre-training) 또는 연속 학습(Continual Learning)은 모델을 주기적으로 처음부터 재훈련하는 대신, 시간이 지남에 따라 들어오는 새로운 데이터로 모델을 점진적으로 업데이트하는 시스템을 목표로 합니다. 이러한 시스템을 구축하고 운영하는 데에는 다음과 같은 주요 기술적 어려움과 트레이드오프가 존재합니다:- 파국적 망각 (Catastrophic Forgetting): 모델이 새로운 데이터나 작업을 학습하면서 이전에 학습했던 지식이나 능력을 급격히 잃어버리는 현상입니다. 이는 연속 학습의 가장 근본적인 문제입니다. 이를 완화하기 위해 정규화 기법, 이전 데이터의 일부를 재학습시키는 리플레이 기법, 모델 파라미터의 중요도를 계산하여 변화를 제한하는 방법 등이 연구됩니다.
- 계산 효율성: 대규모 모델을 새로운 데이터로 업데이트하는 과정을 과도한 계산 비용 없이 효율적으로 수행해야 합니다. 전체 재훈련보다는 비용이 적어야 의미가 있습니다.
- 데이터 관리 복잡성: 지속적으로 유입되는 데이터 스트림을 관리하는 것은 복잡합니다. 데이터 품질 관리, 저장, 중복 제거, 시간이 지남에 따라 데이터 분포가 변하는 '데이터 드리프트(data drift)' 현상에 대한 대응 등이 필요합니다.
- 훈련 안정성: 지속적인 업데이트 과정 중에도 모델 훈련이 불안정해지거나 발산하지 않고 안정적으로 수렴하도록 보장하는 것이 어려울 수 있습니다.
- 평가의 어려움: 모델 성능을 평가하기 위해 새로운 데이터에 대한 학습 능력뿐만 아니라, 이전 지식의 유지(망각 방지) 정도도 함께 측정해야 하므로 평가가 더 복잡해집니다.
- 아키텍처 적합성: 현재 표준 트랜스포머 아키텍처가 연속 학습에 본질적으로 최적화되어 있지 않을 수 있습니다. 지속적인 학습을 용이하게 하는 동적 아키텍처나 모듈식 구조에 대한 연구가 필요합니다.
- 정렬 유지: 모델이 지속적으로 업데이트되면서, 초기에 설정된 정렬(유용성, 정직성, 무해성) 기준이 저하되거나 바람직하지 않은 방향으로 표류하지 않도록 지속적으로 관리하고 평가해야 합니다. 특히, 새 데이터가 완전히 큐레이션되지 않을 수 있는 경우 더욱 중요합니다.
이러한 어려움들 때문에, 연속 학습 시스템은 종종 성능(새로운 지식 습득)과 안정성(기존 지식 유지), 그리고 계산 비용 간의 트레이드오프를 가집니다.
IV. 검색 증강 생성
-
RAG 시스템의 주요 구성 요소는 무엇입니까? 파인튜닝보다 RAG가 선호되는 경우는 언제입니까?
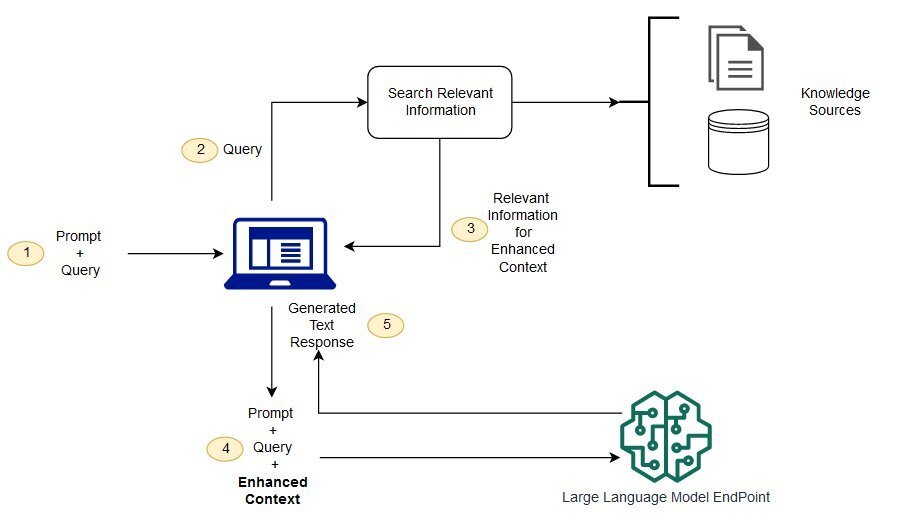
검색 증강 생성(Retrieval-Augmented Generation, RAG)는 LLM이 답변을 생성하기 전에 외부 지식 소스에서 관련된 정보를 먼저 검색하고, 검색된 정보를 컨텍스트로 활용하여 최종 응답을 생성하도록 하는 기술입니다. 이를 통해 LLM의 답변 정확성을 높이고 최신 정보를 반영하며, 환각(hallucination)을 줄일 수 있습니다.
RAG 시스템의 주요 구성 요소는 다음과 같습니다.- 검색기: 사용자 쿼리(질문)가 주어지면, 미리 구축된 지식 베이스에서 관련성이 높은 문서나 텍스트 구절을 찾는 역할을 합니다.
- 지식 베이스: 검색 대상이 되는 정보의 모음입니다. 외부 문서, 데이터베이스 내용 등을 색인(indexing)하여 구축합니다.
- 생성기: 일반적으로 LLM을 의미하며, 사용자의 원본 쿼리와 검색기가 찾아낸 관련 정보를 함께 입력받아, 이를 바탕으로 최종 답변을 생성합니다.
RAG가 파인튜닝보다 선호되는 경우:
- 외부 지식 통합: 모델의 파라미터 내에 저장하기 어려운 방대하거나, 빠르게 변화하거나, 특정 도메인에 특화된 외부 지식을 실시간으로 활용해야 할 때 유용합니다.
- 최신성 및 사실 기반 응답: 지식 베이스만 업데이트하면 최신 정보를 반영할 수 있으며(모델 재훈련보다 훨씬 저렴), 검색된 문서를 근거로 제시하여 답변의 신뢰도를 높이고 출처를 명확히 할 수 있습니다.
- 환각 감소: 모델이 잘 모르는 내용에 대해 추측하는 대신 검색된 사실에 기반하여 답변하도록 유도하여 환각 현상을 줄일 수 있습니다.
- 특정 정보 접근: 파인튜닝 시 발생할 수 있는 지식 망각 위험 없이 특정 정보를 정확하게 참조해야 할 때 효과적입니다.
반면, 파인튜닝은 모델의 스타일, 톤, 말투를 바꾸거나, 특정 기술이나 복잡한 행동 패턴을 내재화시키는 등 모델 자체의 근본적인 특성이나 능력을 변화시키고자 할 때 더 적합합니다.
-
어휘적, 의미적, 하이브리드 검색 방법을 비교 설명해 주십시오.
RAG 시스템에서 검색기는 다양한 방식으로 관련 정보를 찾을 수 있습니다. 주요 검색 방법은 다음과 같습니다.-
어휘적(lexical) 검색:
- 작동 방식: 주로 키워드 일치에 기반합니다. 텍스트 내 단어의 빈도, 문서 내 분포 등을 계산하여 점수를 매기는 희소 벡터 방식(예: TF-IDF, BM25)을 사용합니다.
- 장점: 계산 효율성이 높고, 쿼리에 포함된 정확한 키워드가 포함된 문서를 찾는 데 효과적입니다.
- 단점: 단어의 의미적 유사성(예: 동의어, 다른 표현)을 파악하기 어렵습니다. '자동차 사고'와 '차량 충돌'을 다른 것으로 인식할 수 있습니다.
- 의미론적(semantic) 검색:
-
하이브리드(hybrid) 검색:
- 작동 방식: 어휘적 검색과 의미론적 검색을 결합하여 사용하는 방식입니다. 각 방식의 검색 점수를 조합(fusion)하거나, 한 방식으로 후보군을 추린 뒤 다른 방식으로 순위를 재조정(re-ranking)하는 전략 등을 사용합니다.
- 장점: 각 방식의 단점을 보완하고 장점을 활용하여 전반적으로 더 강력하고 안정적인 검색 성능을 기대할 수 있습니다.
- 단점: 시스템 구현 및 튜닝의 복잡도가 증가합니다.
-
어휘적(lexical) 검색:
-
RAG 성능(예: RAGAS 프레임워크)은 어떻게 평가합니까? 주요 지표는 무엇입니까?
RAG 시스템의 성능을 평가하는 것은 검색과 생성 두 단계의 품질을 모두 고려해야 하므로 다면적입니다. 단순히 최종 답변의 품질만 보는 것이 아니라, 각 구성 요소가 제 역할을 잘 수행하는지 개별적으로, 그리고 전체적으로 평가해야 합니다. RAGAS와 같은 프레임워크는 이러한 평가 과정을 자동화하고 표준화하려는 시도 중 하나이며, 종종 다른 LLM을 평가자로 활용합니다.
주요 평가 지표는 다음과 같습니다.1. 검색기 성능 평가:
- 컨텍스트 정밀도 (Context Precision): 검색된 문서들 중 실제로 질문과 관련 있는 문서의 비율이 얼마나 되는지를 측정합니다. 관련 없는 정보가 많이 검색되었다면 이 점수가 낮아집니다.
- 컨텍스트 재현율 (Context Recall): 질문에 답하기 위해 필요한 모든 관련 정보가 검색 결과 내에 포함되었는지를 측정합니다. 중요한 정보가 누락되었다면 이 점수가 낮아집니다.
2. 생성기 성능 평가:
- 충실성 (Faithfulness): 생성된 답변이 제공된 컨텍스트(검색된 문서)의 내용과 얼마나 일치하는지, 즉 컨텍스트에 없는 내용을 지어내지 않았는지(환각 방지)를 평가합니다.
- 답변 관련성 (Answer Relevancy): 생성된 답변이 사용자의 원본 질문에 대해 직접적이고 명확하게 답하고 있는지를 평가합니다. 답변이 장황하거나 질문의 요점을 벗어나면 이 점수가 낮아집니다.
3. 종단간(end-to-end) 평가 (필요시 정답 데이터 활용):
- 답변 정확성 (Answer Correctness): 생성된 답변이 실제 정답 또는 사실과 얼마나 일치하는지를 평가합니다. (정답 데이터가 있는 경우)
- 답변 의미 유사성 (Answer Semantic Similarity): 생성된 답변이 참조(정답) 답변과 의미적으로 얼마나 유사한지를 평가합니다. (정답 데이터가 있는 경우)
이처럼 다양한 지표를 통해 RAG 시스템의 성능 병목 지점이 검색 단계의 문제인지, 생성 단계의 문제인지, 혹은 두 단계 모두의 문제인지를 진단하고 개선 방향을 설정하는 데 도움을 받을 수 있습니다.
-
기본적인 검색-생성 파이프라인을 개선하기 위한 고급 RAG 기법에는 어떤 것들이 있습니까? HyDE와 같은 쿼리 변환 기법, 재순위화, 또는 순환적 검색과 같은 전략들은 어떻게 작동하며, 표준 RAG에 비해 어떤 이점을 제공합니까?
기본적인 검색-생성 방식의 RAG도 효과적이지만, 검색된 정보의 관련성이 부족하거나 복잡한 질문에 대한 답변 능력이 제한되는 경우가 있습니다. 이러한 한계를 극복하고 성능을 개선하기 위해 다음과 같은 고급 RAG 기법들이 사용됩니다.-
쿼리 변환: 사용자의 원본 쿼리가 검색에 비효율적일 수 있다는 점에 착안하여, 검색 성능을 높이기 위해 쿼리를 변형하는 기법입니다.
- HyDE (Hypothetical Document Embeddings): 원본 쿼리 대신, LLM을 사용하여 해당 쿼리에 답할 만한 '가상의 이상적인 문서'를 먼저 생성합니다. 이 가상 문서는 내용이 풍부하므로, 이를 임베딩하여 검색하면 원본 쿼리만 사용할 때보다 관련성 높은 실제 문서를 찾을 확률이 높아집니다. 특히 짧거나 모호한 쿼리에 효과적입니다.
- 이 외에도 쿼리를 여러 개의 하위 쿼리로 분해하거나, 쿼리 내 핵심 키워드를 추출/확장하는 등의 변환 방법이 있습니다.
- 재순위화 (Re-ranking): 초기 검색 단계에서는 속도를 위해 비교적 간단한 방식으로 다수의 후보 문서를 검색하는 경우가 많습니다. 재순위화는 이 초기 후보 문서들을 대상으로, 더 정확하지만 계산 비용이 높은 모델(예: 쿼리와 문서를 함께 입력받는 크로스-인코더)을 사용하여 관련성 점수를 다시 계산하고 순위를 조정하는 단계입니다. 이를 통해 최종적으로 생성기(LLM)에게 전달되는 문서들의 평균적인 관련성을 높여 답변 품질을 향상시킵니다.
-
순환적/반복적 검색: 한 번의 검색만으로는 충분한 정보를 얻기 어려운 복잡한 질문에 대응하기 위한 전략입니다.
- 작동 방식: 초기 검색 결과를 분석하여 정보가 부족하다고 판단되면, 이전 결과를 바탕으로 새로운 쿼리를 생성하여 추가 검색을 수행합니다. 이 '검색 → 분석 → (필요시) 새 쿼리 생성 → 검색' 과정을 필요한 정보가 충분히 모일 때까지 반복합니다.
- 이점: 여러 단계의 추론이 필요하거나 다양한 관점의 정보를 종합해야 하는 질문에 대해 더 깊이 있고 포괄적인 답변 생성이 가능해집니다.
이 외에도 지식 그래프를 활용하는 Graph RAG, 작은 텍스트 조각에서 시작하여 점차 큰 단위로 검색 범위를 넓히는 Small-to-Big 검색 등 다양한 고급 RAG 기법들이 연구되고 있습니다. 이러한 기법들은 표준 RAG 파이프라인의 약점을 보완하고 특정 유형의 질문이나 데이터에 대한 성능을 극대화하는 데 기여합니다.
-
쿼리 변환: 사용자의 원본 쿼리가 검색에 비효율적일 수 있다는 점에 착안하여, 검색 성능을 높이기 위해 쿼리를 변형하는 기법입니다.
V. 멀티모달 모델
-
멀티모달 모델(예: CLIP, Flamingo, LLaVA)은 일반적으로 텍스트와 이미지 정보를 어떻게 융합합니까?
멀티모달 모델은 텍스트, 이미지, 오디오 등 서로 다른 모달리티의 정보를 함께 처리하고 이해하기 위해 다양한 정보 융합(fusion) 전략을 사용합니다. 주요 접근 방식은 다음과 같습니다.-
공유 임베딩 공간:
- 예시: CLIP
- 작동 방식: 각 모달리티(예: 텍스트, 이미지)를 처리하는 별도의 인코더를 사용하여 각각의 임베딩을 생성한 뒤, 이 임베딩들을 하나의 공유된 잠재 공간으로 투영하도록 학습합니다. 대조 학습(contrastive learning) 목표를 사용하여, 서로 연관된 데이터 쌍(예: 이미지와 그 설명을 담은 텍스트)의 임베딩은 이 공유 공간에서 서로 가까워지도록, 관련 없는 쌍은 멀어지도록 훈련합니다. 융합은 이 임베딩 공간에서의 근접성을 통해 암묵적으로 이루어집니다.
-
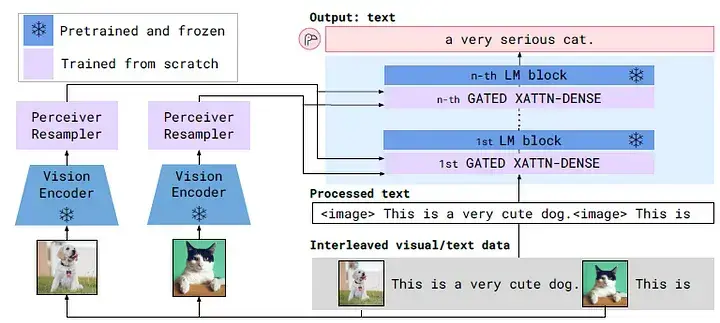
크로스 어텐션:
- 예시: Flamingo
-
작동 방식: 한 모달리티의 정보가 다른 모달리티의 정보를 직접 참조하도록 명시적인 어텐션 메커니즘을 사용합니다. 예를 들어, 사전 훈련된 LLM의 특정 계층들 사이에 크로스 어텐션 계층을 삽입하여, 텍스트 토큰(쿼리 역할)이 비전 인코더로부터 추출된 시각적 특징 토큰 시퀀스(키/밸류 역할)에 직접 주의를 기울이도록 합니다. 이를 통해 텍스트 생성 과정에서 시각 정보를 능동적으로 활용합니다.
-
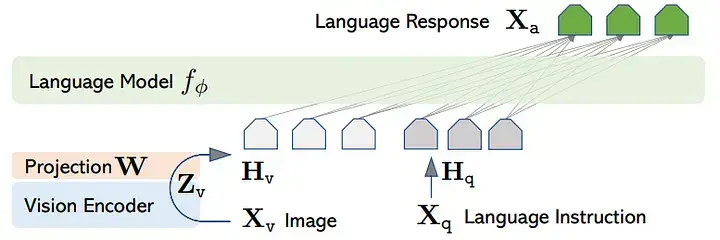
입력 수준 융합:
- 예시: LLaVA
-
작동 방식: 이미지 인코더(예: ViT)를 통해 추출된 시각적 특징을 텍스트 토큰 임베딩과 동일한 차원으로 변환하는 투영 계층을 사용합니다. 이렇게 변환된 시각적 특징 벡터들을 일종의 '가상 시각 토큰'으로 간주하고, 이를 텍스트 토큰 임베딩 시퀀스와 단순히 연결합니다. 이후, 표준 LLM(생성기)이 이 결합된 시퀀스(텍스트 토큰 + 시각 토큰)를 입력으로 받아, 내부의 셀프 어텐션 메커니즘을 통해 자연스럽게 텍스트 정보와 시각 정보를 함께 처리하며 융합합니다.
이 외에도 네트워크의 여러 지점에서 특징을 병합하기 위해 게이팅 메커니즘 등을 사용하는 전용 융합 모듈을 설계하는 방식도 있습니다.
-
공유 임베딩 공간:
-
멀티모달 모델 설계/훈련의 주된 어려움은 무엇입니까?
효과적인 멀티모달 모델을 설계하고 훈련하는 과정에는 다음과 같은 주요 어려움들이 존재합니다.- 고품질 대규모 데이터셋 확보: 서로 다른 모달리티(예: 이미지와 정확히 일치하는 상세 텍스트 설명)가 잘 정렬된 대규모의 고품질 데이터셋을 구축하는 것은 비용과 시간이 많이 소요되며 어려운 작업입니다. 데이터의 품질이나 정렬 상태가 나쁘면 모델 성능에 치명적입니다.
- 의미 있는 융합 전략 개발: 단순히 피상적인 연관성을 넘어, 여러 모달리티 정보를 깊이 있게 통합하고 상호 추론할 수 있는 효과적인 융합 메커니즘을 설계하는 것은 여전히 중요한 연구 주제입니다.
- 높은 계산 비용: 멀티모달 모델은 종종 각 모달리티를 처리하기 위한 여러 개의 대형 인코더(예: 비전 인코더 + 언어 모델)를 포함하므로, 사전 훈련 및 파인튜닝에 막대한 계산 자원이 필요합니다.
- 모달리티 간극 (Modality Gap): 이론적으로는 공유된 임베딩 공간을 사용하더라도, 실제로는 서로 다른 모달리티에서 온 임베딩들이 공간 내에서 분리되어 군집을 이루는 경향이 나타날 수 있습니다. 이는 모달리티 간의 원활한 정보 통합을 방해할 수 있습니다.
- 확장성 문제: 더 많은 종류의 모달리티를 지원하거나, 이미지/비디오의 해상도를 높이는 등 모델의 처리 능력을 확장하는 것은 계산 및 메모리 요구량을 기하급수적으로 증가시켜 상당한 기술적 어려움을 야기합니다.
- 평가의 복잡성: 특정 벤치마크 점수를 넘어서 모델이 진정으로 멀티모달 정보를 이해하고 추론하는지 평가하는 것은 어렵습니다. 또한, 모델의 결정 과정을 해석하고, 여러 모달리티 간 상호작용을 통해 증폭될 수 있는 잠재적 편향을 관리하는 것도 중요한 과제입니다.
VI. 이미지 생성 및 확산 모델
-
확산 과정의 핵심 원리를 설명해 주십시오. 잠재 확산 모델은 어떻게 효율성을 향상시킵니까?
확산 모델(Diffusion Models)은 고품질 이미지를 생성하는 강력한 생성 모델 계열로, 순방향 과정과 역방향 과정이라는 두 단계로 작동합니다.- 순방향 과정: 원본 데이터(예: 실제 이미지)에 여러 시간 단계에 걸쳐 점진적으로 가우시안 노이즈를 추가합니다. 충분한 단계를 거치면 데이터는 원래 형태를 알아볼 수 없는 순수한 노이즈 상태가 됩니다. 이 과정은 미리 정해진 스케줄에 따라 진행됩니다.
- 역방향 과정: 순방향 과정을 거꾸로 되돌리는 노이즈 제거 모델(일반적으로 U-Net 아키텍처 사용)을 학습합니다. 이 모델은 현재의 노이즈가 낀 데이터와 해당 시간 단계 정보를 입력받아, 해당 단계에서 추가되었을 노이즈를 예측합니다. 추론(이미지 생성) 시에는 무작위 노이즈에서 시작하여, 학습된 노이즈 제거 모델을 사용하여 각 단계별로 예측된 노이즈를 반복적으로 제거해 나갑니다. 이를 통해 점진적으로 노이즈를 제거하고 최종적으로 깨끗한 원본 데이터와 유사한 샘플(예: 사실적인 이미지)을 생성합니다.
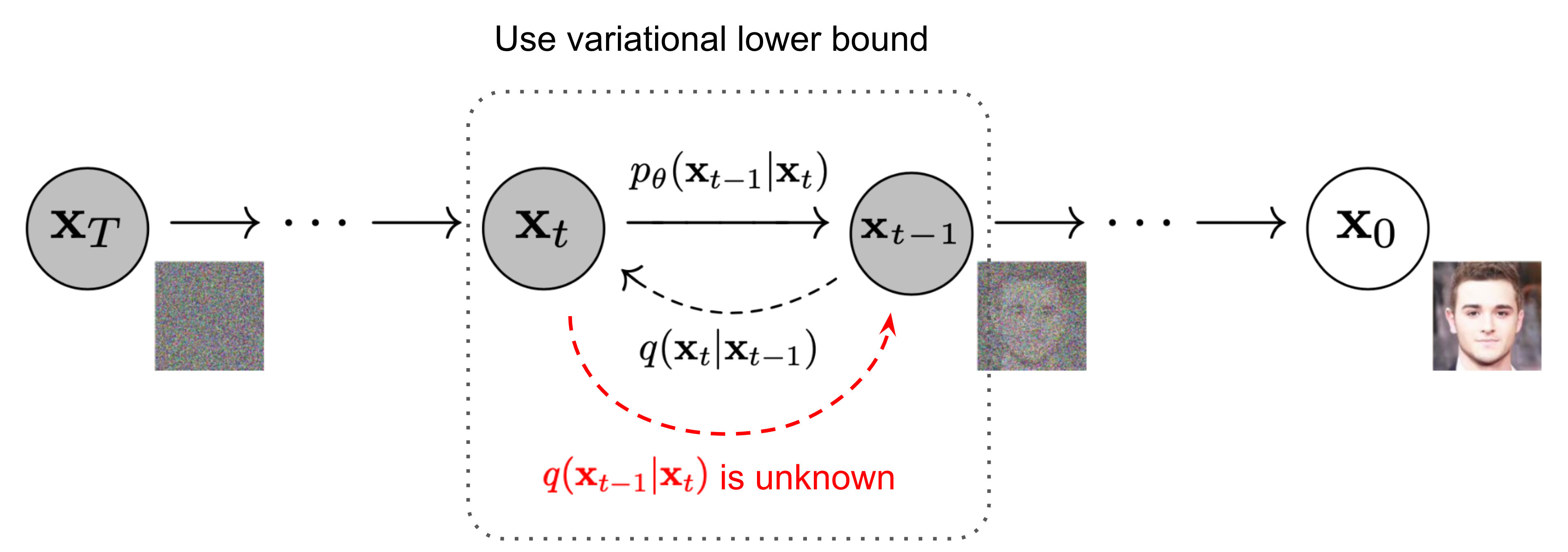
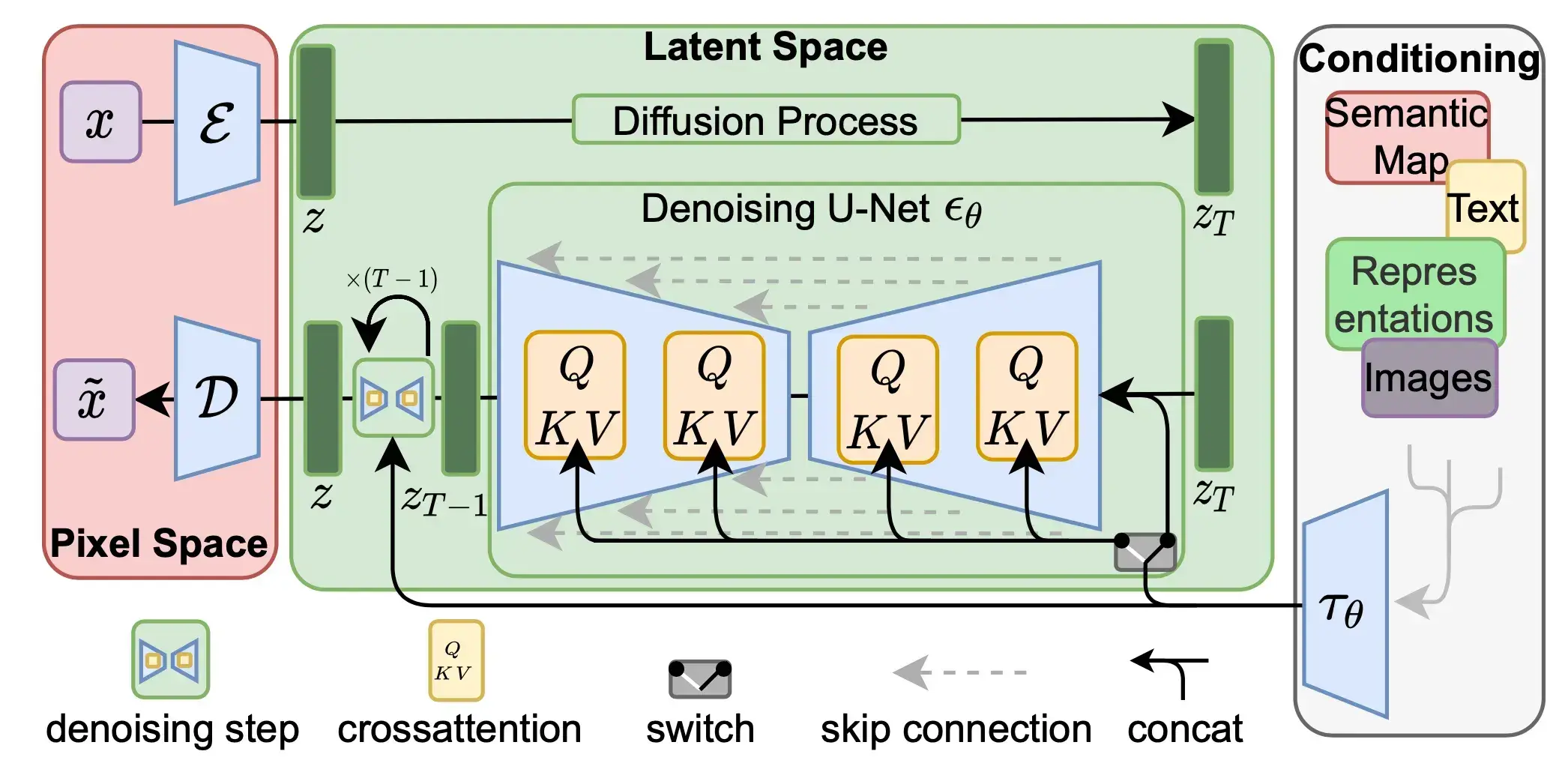
잠재 확산 모델 (Latent Diffusion Model, LDM) (Stable Diffusion 등의 기반 기술)은 이 과정의 효율성을 크게 개선합니다. 고해상도 이미지의 픽셀 공간에서 직접 확산 과정을 수행하는 대신, 다음 단계를 따릅니다:
- 압축: 사전 훈련된 오토인코더(특히 VAE)를 사용하여 원본 고해상도 이미지를 훨씬 저차원의 잠재 공간 표현으로 압축합니다.
- 잠재 공간 확산: 순방향(노이즈 추가) 및 역방향(노이즈 제거 학습 및 추론) 확산 과정을 이 저차원 잠재 공간 내에서 수행합니다.
- 복원: 역방향 과정을 통해 잠재 공간에서 노이즈가 제거된 최종 잠재 벡터를 얻은 후, 오토인코더의 디코더를 사용하여 이를 다시 원래의 고해상도 픽셀 공간 이미지로 복원합니다.
고차원 픽셀 공간 대신 저차원 잠재 공간에서 연산함으로써, LDM은 노이즈 제거 네트워크(U-Net)의 계산 부담과 메모리 요구량을 대폭 감소시켜, 고해상도 이미지 생성을 훨씬 빠르고 효율적으로 만듭니다.
-
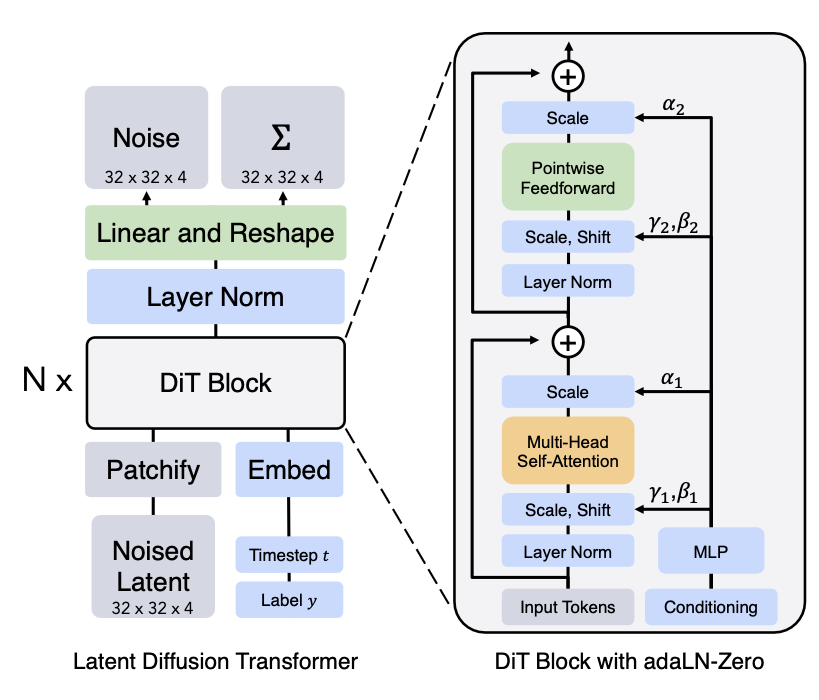
확산 트랜스포머란 무엇입니까? 기존 U-Net 기반 확산 모델과 어떻게 다르며, 잠재적인 장단점은 무엇입니까?
확산 트랜스포머(Diffusion Transformer, DiT)는 확산 모델의 역방향 노이즈 제거 과정에서 전통적으로 사용되던 U-Net 아키텍처 대신 트랜스포머 아키텍처를 사용하는 모델을 의미합니다.
기존 U-Net 기반 모델과의 차이점:- 핵심 네트워크: U-Net은 컨볼루션 신경망(CNN) 기반으로, 다운샘플링 경로와 업샘플링 경로 간의 스킵 연결을 특징으로 합니다. 반면, DiT는 비전 트랜스포머(ViT)와 유사하게, 이미지를 여러 개의 작은 패치(patch)로 나누고 이를 시퀀스로 처리하는 트랜스포머를 노이즈 제거 네트워크로 사용합니다.
- 입력 처리: DiT는 일반적으로 (노이즈가 추가된) 잠재 공간 이미지 패치 시퀀스, 시간 단계 임베딩, 그리고 텍스트 임베딩과 같은 조건 정보를 입력으로 받아, 트랜스포머의 셀프 어텐션을 통해 이들 간의 관계를 학습하고 최종적으로 각 패치에 포함된 노이즈를 예측합니다.
잠재적 장점:
- 확장성: 트랜스포머는 NLP, 비전 등 다양한 분야에서 모델 크기 및 데이터 규모 확장에 따른 성능 향상(스케일링)이 입증되었습니다. DiT는 이러한 트랜스포머의 우수한 확장성을 확산 모델에 적용할 수 있는 가능성을 제시합니다.
- 기존 생태계 활용: 기존 트랜스포머 관련 연구, 사전 훈련 기법, 최적화된 구현 등을 활용할 수 있습니다.
잠재적 단점:
- 귀납적 편향 (Inductive Bias) 손실: CNN은 이미지 처리에 유용한 공간적 계층 구조 등의 귀납적 편향을 내재하고 있으나, 트랜스포머는 상대적으로 이러한 편향이 적습니다. (단, 이미지를 패치 단위로 처리하는 것이 이를 일부 완화합니다.)
- 계산 비용: 트랜스포머의 셀프 어텐션 연산은 시퀀스 길이에 따라 계산 비용이 증가할 수 있습니다. (단, LDM처럼 잠재 공간에서 작동하면 이 부담이 크게 줄어듭니다.)
고도로 최적화된 U-Net 아키텍처 대비 DiT의 상대적인 성능 및 효율성은 현재 활발히 연구되고 있는 분야입니다.
-
클래시파이어-프리 가이던스란 무엇입니까?
클래시파이어-프리 가이던스 (Classifier-Free Guidance, CFG)는 텍스트-이미지 생성과 같은 조건부 확산 모델에서, 생성된 이미지가 주어진 조건(예: 텍스트 프롬프트)에 더 잘 부합하도록 유도하는 기법입니다. 이름에서 알 수 있듯이, 이 과정에서 별도의 분류기 모델을 사용하지 않는다는 특징이 있습니다.작동 원리:
- 훈련: 확산 모델(노이즈 예측 네트워크)을 훈련할 때, 두 가지 방식으로 훈련합니다.
- 조건부 훈련: 노이즈가 추가된 이미지와 조건 정보(예: 텍스트 임베딩)를 함께 입력하여 노이즈를 예측하도록 학습합니다.
- 비조건부 훈련: 때때로(일정 확률로) 조건 정보를 제거하거나 빈 값으로 대체하고, 노이즈가 추가된 이미지만으로 노이즈를 예측하도록 학습합니다. 즉, 동일한 모델이 조건이 있을 때와 없을 때 모두 노이즈를 예측하는 법을 배웁니다.
- 추론 (이미지 생성): 이미지를 생성하는 각 노이즈 제거 단계에서, 모델은 두 가지 노이즈 예측값을 계산합니다. 하나는 조건이 주어졌을 때의 노이즈 예측이고, 다른 하나는 조건이 없을 때(비조건부)의 노이즈 예측입니다.
- 가이던스 적용: 최종적으로 사용할 노이즈 예측값은 이 두 예측값을 조합하여 계산합니다. 비조건부 예측값에 (조건부 예측값과 비조건부 예측값의 차이)를 특정 가중치(guidance scale, 'w')만큼 곱해서 더해줍니다. 이 가중치 'w'가 클수록 조건부 예측 방향으로 더 많이 이동(외삽)하게 됩니다.
- 이미지 업데이트: 계산된 최종 노이즈 예측값을 사용하여 현재 노이즈 이미지에서 노이즈를 제거하고 다음 단계 이미지를 얻습니다.
효과: 가이던스 스케일 'w' 값을 조절함으로써, 생성되는 이미지가 주어진 조건(텍스트 프롬프트)에 얼마나 충실할지 제어할 수 있습니다. 'w'가 높으면 프롬프트 내용을 더 잘 따르지만 이미지의 다양성이나 품질이 다소 저하될 수 있고, 'w'가 낮으면 다양성은 높아지지만 프롬프트와의 관련성이 떨어질 수 있습니다. CFG는 이 충실도와 다양성 간의 균형을 사용자가 쉽게 조절할 수 있게 해주는 매우 효과적인 기법입니다.
! 이름의 유래: CFG 이전에는, 별도의 분류기 모델을 훈련시켜 노이즈 낀 이미지로부터 원하는 클래스나 속성을 예측하고, 이 분류기의 그래디언트를 이용해 확산 과정을 원하는 방향으로 유도하는 방식(클래시파이어 가이던스)이 있었습니다. CFG는 이러한 별도의 분류기 없이 가이던스를 제공하므로 "Classifier-Free"라는 이름이 붙었습니다.
- 훈련: 확산 모델(노이즈 예측 네트워크)을 훈련할 때, 두 가지 방식으로 훈련합니다.
-
샘플링 전략(예: DDIM, DPM-Solver)을 속도 대 품질 측면에서 비교 설명해 주십시오.
확산 모델 샘플링 전략 또는 솔버(solver)는 학습된 확산 모델로부터 이미지를 생성(샘플링)하는 알고리즘입니다. 확산 모델의 원래 공식인 DDPM 샘플러는 고품질 이미지를 생성할 수 있지만, 수백~수천 번의 노이즈 제거 단계를 거쳐야 하므로 매우 느리다는 단점이 있습니다. 샘플링 전략들은 더 적은 노이즈 제거 단계를 사용하면서도 최대한 높은 품질의 이미지를 생성하여 추론 속도를 높이는 것을 목표로 합니다. 주요 전략들을 속도와 품질 측면에서 비교하면 다음과 같습니다.-
DDIM (Denoising Diffusion Implicit Models):
- DDPM을 개선한 초기 샘플러 중 하나입니다. DDPM보다 훨씬 큰 시간 간격으로 건너뛰며 샘플링하는 것이 가능하여, 필요한 총 단계를 수십~수백 개 수준(예: 50~250 단계)으로 크게 줄여 속도를 향상시켰습니다.
- 합리적인 단계 수에서는 양호한 품질을 유지하지만, 매우 적은 단계(예: 10~20 단계 미만)에서는 생성 품질이 눈에 띄게 저하되는 경향이 있습니다.
-
DPM-Solver (Diffusion Probabilistic Model Solver) 계열:
- 확산 과정을 확률적 미분 방정식(SDE) 또는 상미분 방정식(ODE)을 푸는 문제로 해석하고, 이를 더 빠르고 정확하게 풀기 위한 고차 수치 해석 기법들을 적용한 샘플러입니다.
- DDIM보다 훨씬 적은 단계, 종종 10~25 단계만으로도 매우 높은 품질의 이미지를 생성할 수 있어, 유사 품질 대비 상당한 속도 향상을 제공합니다.
- DPM-Solver++, UniPC 등 다양한 변형들이 있으며, 특히 CFG와 함께 사용할 때 안정성이 뛰어난 것으로 알려져 있습니다.
결론: 현재로서는 DPM-Solver 계열 샘플러들이 생성 속도와 샘플 품질 간의 가장 우수한 균형을 제공하는 것으로 평가받으며, 확산 모델의 실용성을 크게 높이는 데 기여하고 있습니다. 어떤 샘플러를 선택할지는 요구되는 품질 수준과 허용 가능한 생성 시간 사이의 트레이드오프를 고려하여 결정됩니다.
-
DDIM (Denoising Diffusion Implicit Models):
-
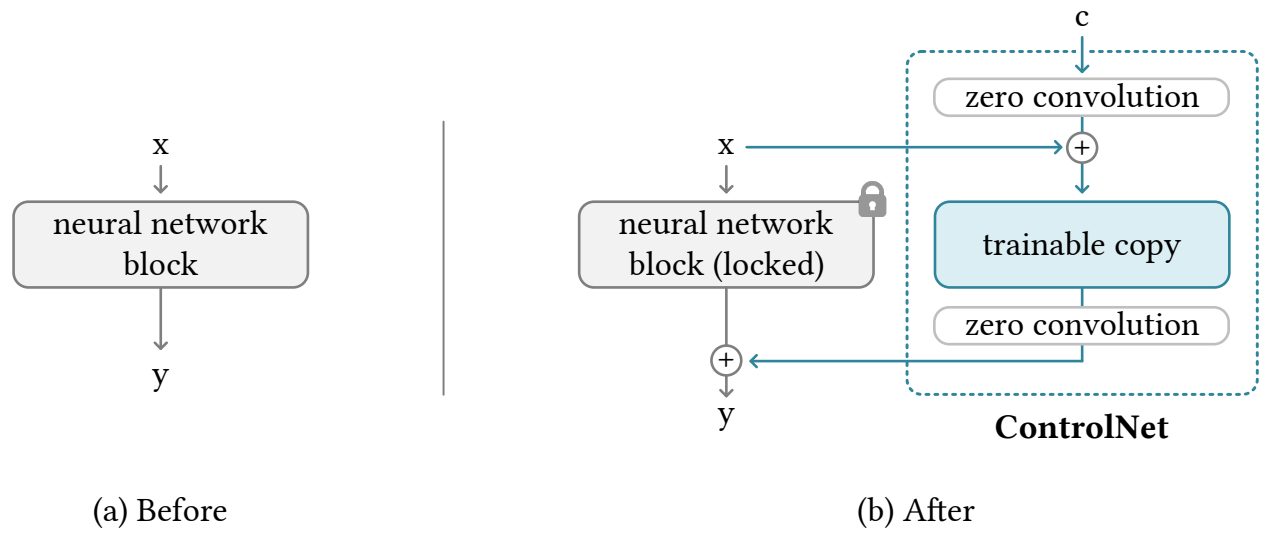
ControlNet이란 무엇이며, 어떻게 제어 가능한 이미지 생성을 가능하게 합니까?
ControlNet은 사전 훈련된 대규모 텍스트-이미지 확산 모델(예: Stable Diffusion)에 추가적인 공간적 제어 능력을 부여하기 위해 설계된 애드온(add-on) 신경망 모듈입니다. 이를 통해 사용자는 텍스트 프롬프트 외에도 다양한 종류의 조건 이미지를 입력하여 생성될 이미지의 구조, 형태, 포즈 등을 세밀하게 제어할 수 있습니다. 예를 들어 다음과 같은 제어 조건들을 사용할 수 있습니다.- 캐니 엣지(canny edges) 맵
- 깊이(depth) 맵
- 인간 골격 포즈 (human pose, 예: OpenPose)
- 의미론적 분할 맵 (semantic segmentation map)
- 낙서(scribble) 등
작동 방식 및 특징:
- 기반 모델 동결: ControlNet은 기존의 강력한 사전 훈련된 확산 모델의 가중치를 전혀 수정하지 않고 그대로 사용(동결)합니다.
- 인코더 블록 복사 및 학습: 기반 모델의 노이즈 제거 네트워크(보통 U-Net) 내부의 인코딩 부분(다운샘플링 블록들)만을 복사하여, 이 복사본을 학습 가능 상태로 만듭니다.
- 제어 조건 입력: 사용자가 제공한 제어 조건 이미지(예: 엣지 맵)는 이 학습 가능한 인코더 복사본에 입력됩니다.
- '제로 컨볼루션' 연결: 학습 가능한 복사본의 각 블록에서 나온 출력 특징들은 '제로 컨볼루션(zero convolution)' (가중치가 0으로 초기화된 1x1 컨볼루션 계층)을 통과한 후, 원본 동결된 U-Net의 해당 디코딩 부분(업샘플링 블록)의 입력에 더해집니다.
- 훈련: ControlNet을 훈련할 때는 오직 복사된 인코더 블록들과 제로 컨볼루션 레이어의 가중치만 업데이트합니다. 훈련 데이터는
(원본 이미지, 텍스트 프롬프트, 제어 조건 이미지)쌍으로 구성됩니다.
이러한 구조 덕분에 ControlNet은 기반 모델이 가진 방대한 지식과 생성 능력은 그대로 활용하면서, 추가된 제어 조건에 따라 이미지의 공간적 구조를 효과적으로 제어할 수 있습니다. 제로 컨볼루션은 훈련 초기에는 제어 조건의 영향을 주지 않다가 점차 학습을 통해 제어 정보를 주입하는 역할을 합니다.
-
사전 훈련된 이미지 생성 모델을 특정 스타일이나 주제에 맞게 조정할 때 주로 사용되는 파인튜닝 기법들은 무엇이며, 각 방식의 특징은 어떤가요? 또한, 이러한 기법들을 적용할 때 주의해야 할 주요 기술적 어려움은 무엇인가요?
사전 훈련된 강력한 이미지 생성 모델을 특정 스타일, 인물, 사물, 또는 개념에 맞게 조정(파인튜닝)하기 위해 여러 기법들이 사용됩니다. 각 기법은 맞춤 설정의 깊이, 필요한 데이터 양, 계산 자원 요구량 등에서 특징을 가집니다.
주요 파인튜닝 기법:-
전체(full) 파인튜닝:
- 방식: 모델의 전체 또는 대부분의 가중치를 새로운 목표 데이터셋(특정 스타일의 이미지 등)으로 다시 훈련합니다.
- 특징: 모델의 동작을 근본적으로 크게 바꿀 수 있어 깊은 수준의 맞춤 설정이 가능하지만, 매우 많은 계산 자원(GPU 메모리, 시간)이 필요하고, 잘못하면 모델이 기존에 가지고 있던 방대한 지식이나 다양한 생성 능력을 잃어버릴 위험이 큽니다.
-
PEFT: 모델의 대부분 가중치는 고정한 채, 일부 파라미터만 학습하여 자원 효율성을 높이는 방식입니다. 이미지 생성 분야에서는 다음과 같은 기법들이 널리 쓰입니다.
- LoRA: 기존 모델의 특정 계층(주로 어텐션 관련)에 저차원 행렬 형태의 작은 '어댑터'를 추가하고 이 어댑터만 학습합니다. 비교적 적은 자원으로 특정 스타일이나 미세 조정을 적용하는 데 효과적입니다.
-
DreamBooth: 소수의 특정 대상(예: 특정 인물, 애완동물) 이미지(보통 3~5장)와 고유한 식별자 문자열(예: "a photo of sks dog")을 사용하여 모델이 해당 대상을 매우 사실적으로 학습하도록 하는 기법입니다. 모델의 일부 가중치를 업데이트합니다.
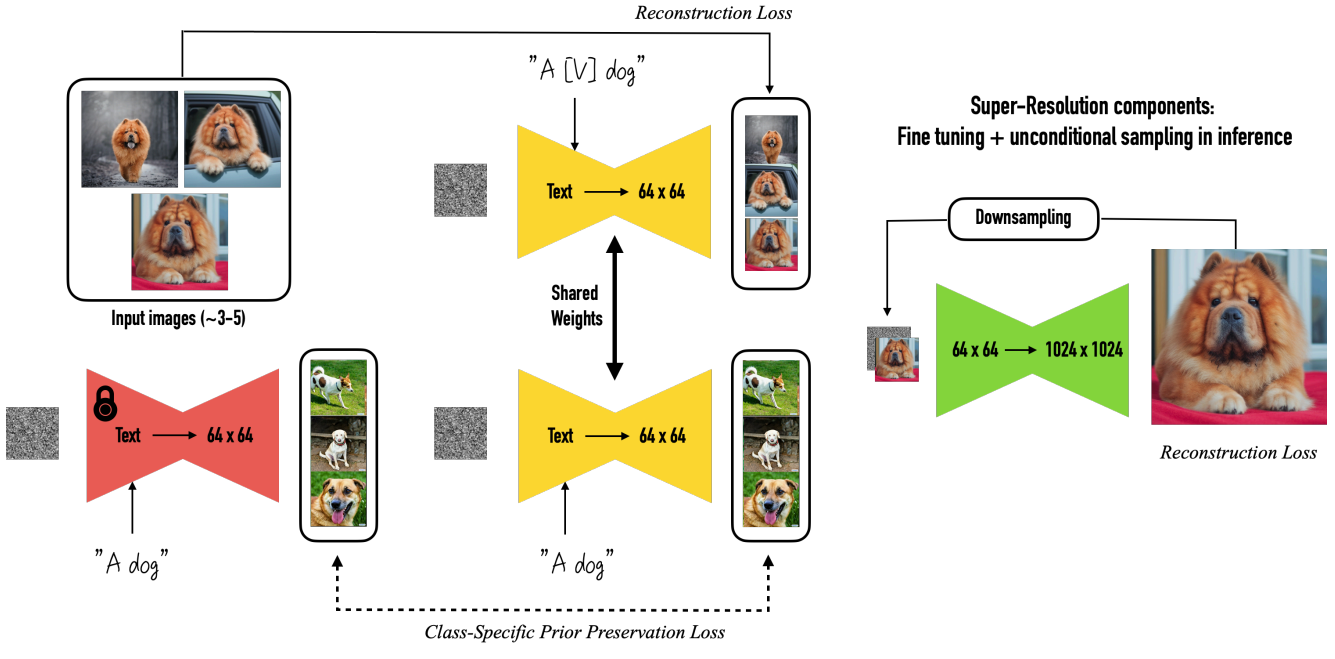
-
Textual Inversion: 모델의 가중치는 전혀 변경하지 않고, 새로운 개념(스타일, 객체)을 나타내는 새로운 단어에 대한 임베딩 벡터만 학습합니다. 훈련이 매우 가볍고 빠르지만, DreamBooth만큼 특정 대상을 강하게 학습시키기는 어려울 수 있습니다.
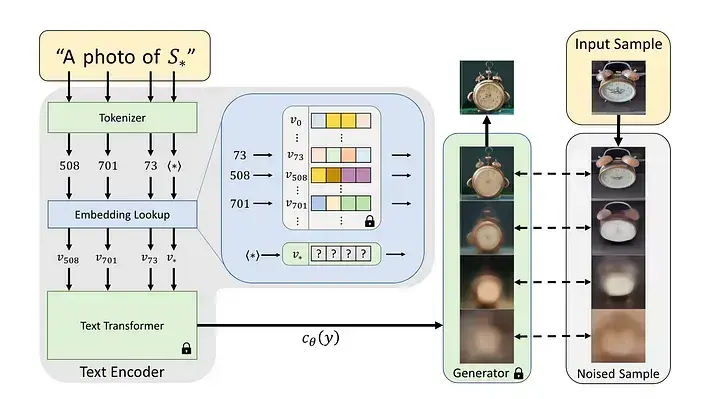
주요 기술적 어려움:
어떤 파인튜닝 기법을 사용하든 다음과 같은 어려움에 직면할 수 있습니다:- 파국적 망각: 새로운 스타일이나 개념을 학습하면서 모델이 이전에 학습했던 다양한 지식과 생성 능력을 잃어버리는 문제입니다. 특히 전체 파인튜닝 시 두드러질 수 있습니다.
- 과적합: 파인튜닝 데이터에 모델이 지나치게 맞춰져, 생성 결과가 해당 데이터와 너무 유사하게만 나오거나 새로운 프롬프트에 대한 일반화 성능이 떨어지는 문제입니다. 결과물이 획일적이 되거나 다양성이 줄어들 수 있습니다.
- 균형 찾기: 원하는 수준의 맞춤 설정을 달성하면서도 모델의 일반적인 생성 능력과 안정성을 유지하는 섬세한 균형점을 찾는 것이 중요합니다. 학습률, 훈련 데이터 양, 훈련 단계 수 등을 신중하게 조절해야 합니다.
-
전체(full) 파인튜닝:
VII. 파운데이션 모델 엔지니어링 및 인프라
-
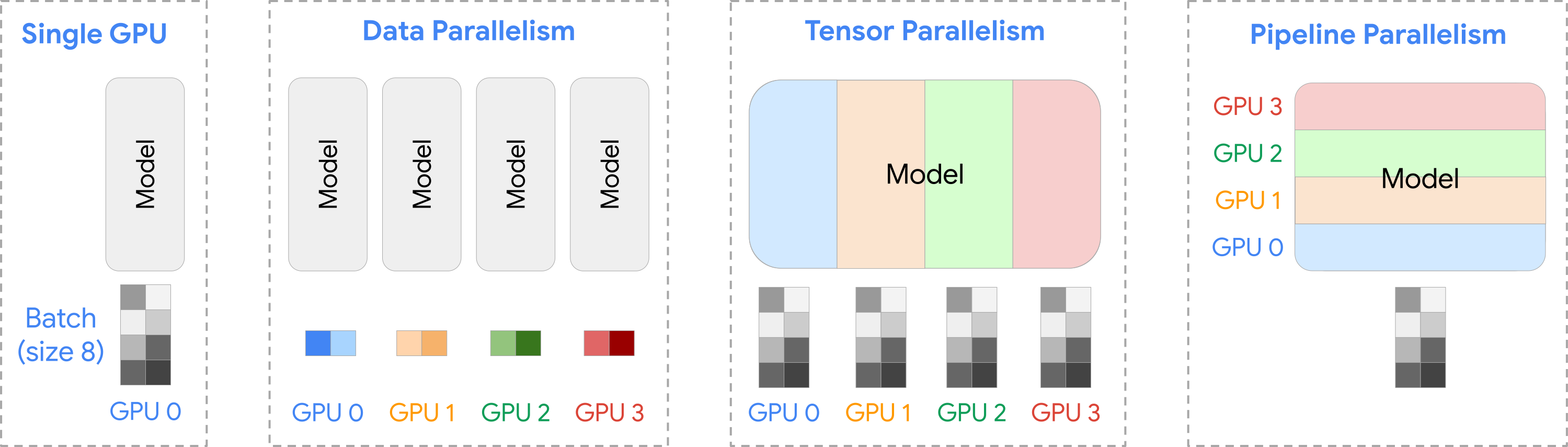
데이터, 텐서, 파이프라인 병렬 처리를 설명해 주십시오. 각각 언제 사용됩니까? DeepSpeed/FSDP와 같은 프레임워크는 무엇입니까?
매우 큰 모델은 단일 가속기(GPU 등)의 메모리에 모두 들어가지 않거나, 단일 장치로 훈련하기에는 시간이 너무 오래 걸리므로, 여러 장치를 함께 사용하는 분산 훈련 전략이 필수적입니다. 주요 병렬 처리 기법은 다음과 같습니다:-
데이터 병렬 처리 (Data Parallelism, DP):
-
방식: 모델 전체를 여러 장치에 복제하고, 각 장치가 전체 데이터 배치의 서로 다른 부분(미니배치)을 처리하여 그래디언트를 계산합니다. 이후 계산된 그래디언트들을 모든 장치에서 평균 내어(예:
AllReduce연산) 모델 가중치를 동시에 업데이트합니다. - 사용 시점: 모델 자체는 단일 장치 메모리에 맞지만, 더 많은 데이터를 병렬로 처리하여 훈련 속도를 높이고 싶을 때 주로 사용됩니다. 가장 기본적인 병렬 처리 방식입니다.
-
방식: 모델 전체를 여러 장치에 복제하고, 각 장치가 전체 데이터 배치의 서로 다른 부분(미니배치)을 처리하여 그래디언트를 계산합니다. 이후 계산된 그래디언트들을 모든 장치에서 평균 내어(예:
-
텐서 병렬 처리 (Tensor Parallelism, TP):
-
방식: 모델 내의 개별 연산(텐서 연산), 예를 들어 거대한 행렬 곱셈(어텐션이나 FFN 내부) 자체를 여러 장치에 걸쳐 분할하여 수행합니다. 특정 계층의 가중치 행렬이 여러 장치에 분산되어 저장되고, 해당 계층의 순방향 및 역방향 계산 시 장치 간 통신(예:
AllReduce,AllGather)이 필요합니다. - 사용 시점: 모델의 단일 계층조차 너무 커서 하나의 장치 메모리에 맞지 않을 때 사용됩니다.
-
방식: 모델 내의 개별 연산(텐서 연산), 예를 들어 거대한 행렬 곱셈(어텐션이나 FFN 내부) 자체를 여러 장치에 걸쳐 분할하여 수행합니다. 특정 계층의 가중치 행렬이 여러 장치에 분산되어 저장되고, 해당 계층의 순방향 및 역방향 계산 시 장치 간 통신(예:
-
파이프라인 병렬 처리 (Pipeline Parallelism, PP):
- 방식: 모델의 전체 계층들을 여러 개의 연속적인 단계로 나누고, 각 단계를 서로 다른 장치에 할당합니다. 데이터는 마치 조립 라인처럼 파이프라인을 따라 한 단계에서 다음 단계로 전달됩니다 (순방향 계산 시 활성화 값 전달, 역방향 계산 시 그래디언트 전달).
- 사용 시점: 모델 전체가 (텐서 병렬 처리를 사용하더라도) 단일 장치에 맞지 않을 때, 또는 중간 계산 결과(활성화 값) 저장을 위한 메모리 부담을 줄이고 싶을 때 사용됩니다.
실제 대규모 모델 훈련에서는 이러한 세 가지 병렬 처리 기법을 복합적으로 사용하는 하이브리드 방식이 일반적입니다. DeepSpeed나 PyTorch의 FSDP(Fully Sharded Data Parallel)와 같은 프레임워크는 ZeRO와 같은 메모리 최적화 기법과 함께 이러한 복잡한 병렬 처리 전략을 보다 쉽게 구현하고 관리할 수 있도록 다양한 도구와 추상화된 인터페이스를 제공합니다.
-
데이터 병렬 처리 (Data Parallelism, DP):
-
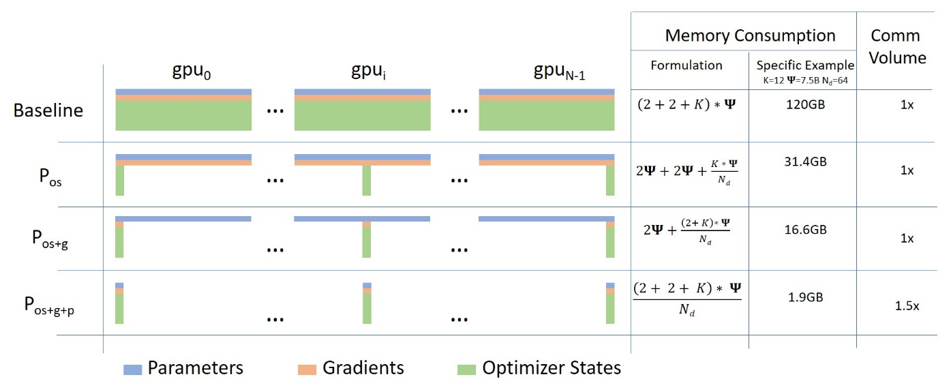
ZeRO 1, 2, 3 단계를 설명해 주십시오. 어떻게 메모리 요구 사항을 줄입니까?
ZeRO (Zero Redundancy Optimizer)는 데이터 병렬(DP) 훈련 환경에서 각 장치(GPU)가 중복으로 저장해야 했던 모델 상태 정보(옵티마이저 상태, 그래디언트, 모델 파라미터)를 여러 장치에 걸쳐 분할함으로써, 장치당 메모리 사용량을 획기적으로 줄이는 최적화 기법 모음입니다. 이를 통해 훨씬 더 큰 모델을 제한된 하드웨어로 훈련하는 것을 가능하게 합니다. ZeRO는 최적화 수준에 따라 3단계로 나뉩니다.-
ZeRO 1단계:
- 분할 대상: 옵티마이저 상태 (예: AdamW 옵티마이저의 모멘텀 및 분산 값)
- 작동 방식: 각 장치는 전체 모델 파라미터 중 자신이 담당하는 일부분(파티션)에 해당하는 옵티마이저 상태만 저장합니다. 표준 DP에서는 모든 장치가 전체 옵티마이저 상태를 복제하여 저장하지만, ZeRO 1단계에서는 이를 분할하여 메모리 중복을 제거합니다. 파라미터 업데이트 시에는 필요한 옵티마이저 상태를 통신을 통해 가져옵니다.
-
ZeRO 2단계:
- 분할 대상: 옵티마이저 상태 + 그래디언트
-
작동 방식: 1단계의 옵티마이저 상태 분할에 더해, 그래디언트 또한 장치 간에 분할하여 저장합니다. 역방향 전파(backward pass) 후, 각 장치는 자신이 담당하는 파라미터 파티션에 대한 그래디언트만 계산하고 저장합니다 (
ReduceScatter연산 사용). 표준 DP에서 모든 장치가 전체 그래디언트를 계산하고AllReduce하는 것과 비교하여 메모리를 추가로 절약합니다.
-
ZeRO 3단계:
- 분할 대상: 옵티마이저 상태 + 그래디언트 + 모델 파라미터
-
작동 방식: 가장 높은 수준의 최적화로, 모델 파라미터 자체까지 분할합니다. 각 장치는 대부분의 시간 동안 자신이 담당하는 파라미터 파티션만 메모리에 유지합니다. 특정 계층의 순방향 또는 역방향 계산이 필요할 때만, 해당 계산에 필요한 파라미터들을 모든 관련 장치로부터 통신을 통해 일시적으로 불러와(
AllGather) 사용하고, 계산이 끝나면 즉시 해제하여 메모리를 확보합니다. - 효과: 가장 큰 메모리 절약 효과를 제공하며, 이론적으로 장치 수만 충분하다면 모델 크기와 거의 무관하게 훈련이 가능해집니다.
ZeRO 단계가 높아질수록 메모리 절약 효과는 커지지만, 분할된 데이터를 필요할 때마다 가져와야 하므로 장치 간 통신량은 일반적으로 증가하는 트레이드오프가 있습니다.
-
ZeRO 1단계:
-
양자화 기법(PTQ 대 QAT)과 형식(FP16, BF16, INT8)에 대해 논의해 주십시오. 성능/크기/정확도에 미치는 영향은 무엇입니까? GPTQ/AWQ를 설명해 주십시오.
양자화는 모델의 가중치나 활성화 값을 표현하는 데 사용되는 수치 데이터의 정밀도(비트 수)를 낮추는 기술입니다. 일반적으로 표준인 32비트 부동소수점(FP32) 대신 16비트 부동소수점(FP16, BF16)이나 8비트 정수(INT8) 등을 사용합니다.목적 및 효과:
- 모델 크기 감소: 더 적은 비트를 사용하므로 모델 파일 크기가 작아져 저장 및 로딩에 유리합니다.
- 메모리 사용량 감소: 추론 시 모델을 메모리에 올릴 때 필요한 공간이 줄어듭니다. 특히 KV 캐시 등 메모리 사용량이 많은 부분에 적용하면 효과가 큽니다.
- 추론 속도 향상: 메모리 대역폭 사용량이 줄어들고, 특정 하드웨어(예: NVIDIA GPU의 Tensor Core)에서 저정밀도 연산 가속을 지원하는 경우 연산 속도 자체가 빨라질 수 있습니다.
주요 형식:
- FP16: FP32보다 절반의 비트를 사용하며, 속도와 정확도 간 균형이 비교적 좋습니다. 하지만 표현 가능한 수의 범위가 좁아 오버플로우/언더플로우 문제가 발생할 수 있습니다.
- BF16 (BFloat16): FP16과 같은 16비트지만, 지수부에 더 많은 비트를 할당하여 FP32와 유사한 넓은 표현 범위를 가집니다. 훈련 및 추론에서 FP16보다 수치적으로 더 안정적인 경향이 있습니다.
- INT8: 8비트 정수를 사용하며, 가장 큰 폭의 속도 향상 및 메모리 절감 효과를 기대할 수 있습니다. 하지만 부동소수점 수를 정수로 변환하는 과정에서 정보 손실이 커서, 정확도 하락을 최소화하기 위한 세심한 변환 과정(보정)이 중요합니다.
주요 양자화 기법:
- 훈련 후 양자화 (Post-Training Quantization, PTQ): 이미 훈련된 모델을 가지고 와서, 추가 훈련 없이 가중치 등을 저정밀도로 변환하는 방식입니다. 종종 소량의 보정 데이터를 사용하여 최적의 변환 스케일링 계수를 찾습니다. 구현이 비교적 간단하지만, 특히 4비트 이하의 매우 낮은 비트로 양자화할 경우 모델 정확도 손실이 발생할 수 있습니다.
- 양자화 인식 훈련 (Quantization-Aware Training, QAT): 모델 훈련 또는 파인튜닝 과정 중에 양자화 연산을 시뮬레이션(가짜 양자화 연산 삽입)합니다. 모델이 양자화로 인한 오차를 미리 경험하고 이에 강건해지도록 학습하므로, 일반적으로 동일 비트 수 대비 PTQ보다 더 높은 정확도를 달성할 수 있습니다. 하지만 추가적인 훈련 과정이 필요하여 시간과 계산 비용이 더 많이 듭니다.
모든 양자화 기법은 효율성(속도, 메모리) 향상과 모델 성능(정확도) 저하 가능성 사이의 트레이드오프를 가집니다.
-
추측 디코딩은 어떻게 LLM 추론 속도를 높입니까?
추측 디코딩(Speculative Decoding)은 LLM의 자기회귀적 텍스트 생성 과정, 즉 한 토큰씩 순차적으로 생성하는 과정의 추론 속도를 높이는 기법입니다. 핵심 아이디어는 두 개의 모델, 즉 작고 빠른 '초안(draft) 모델'과 크고 정확하지만 느린 '타겟(target) 모델'을 함께 사용하는 것입니다.작동 방식:
- 초안 생성: 현재까지 생성된 시퀀스가 주어지면, 작고 빠른 초안 모델이 먼저 앞으로 생성될 몇 개(예: 3~5개)의 토큰 후보 시퀀스를 빠르게 예측하여 제안합니다.
- 병렬 검증: 크고 느린 타겟 모델은 초안 모델이 제안한 후보 토큰 시퀀스 전체를 입력으로 받아, 단 한 번의 순방향 패스로 병렬 처리합니다. 이 과정에서 타겟 모델은 각 위치에서 자신이 예측했을 토큰과 초안 모델의 제안을 비교하며 검증합니다.
- 토큰 수락: 타겟 모델이 초안 모델의 제안 중 첫 번째부터 연속적으로 'k'개의 토큰까지는 자신의 예측과 일치한다고 판단하면, 이 'k'개의 토큰을 한꺼번에 최종 출력 시퀀스에 추가합니다.
- 불일치 처리: 만약 'k+1'번째 토큰에서 타겟 모델의 예측과 초안 모델의 제안이 달라지면, 앞에서 일치한 'k'개의 토큰까지만 수락하고, 'k+1'번째 토큰은 타겟 모델의 예측값을 사용합니다. 이후 다시 초안 모델이 다음 후보 시퀀스를 생성하는 과정을 반복합니다.
효과: 초안 모델이 어느 정도 정확하다면, 이 방식을 통해 비용이 많이 드는 타겟 모델의 순방향 패스 한 번으로 여러 개의 토큰을 동시에 확정할 수 있게 됩니다. 이는 표준적인 자기회귀 디코딩 방식(타겟 모델이 매번 한 토큰씩만 생성)에 비해 전체 생성 시간을 2배~4배 이상 크게 단축시키는 효과를 가져옵니다.
-
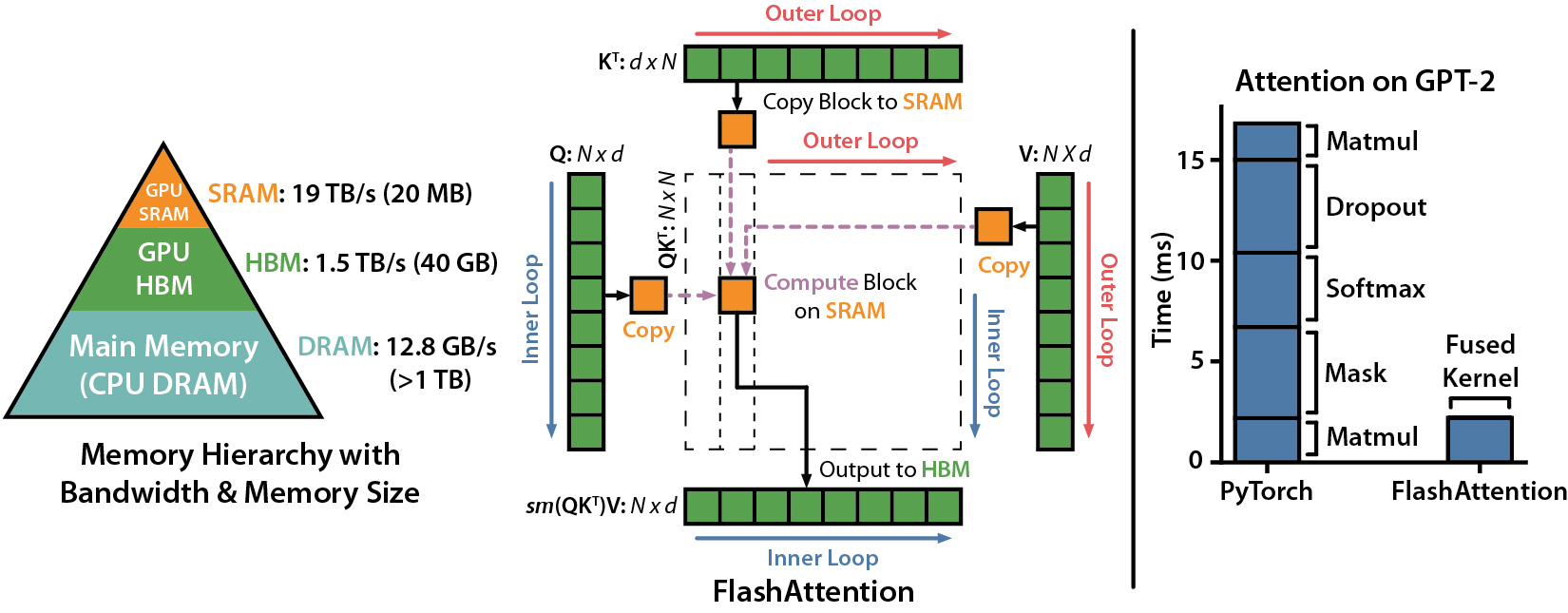
FlashAttention은 어떻게 어텐션 효율성을 향상시킵니까?
FlashAttention은 표준 셀프 어텐션 연산을 특히 긴 시퀀스에 대해 훨씬 더 빠르고 적은 메모리를 사용하여 수행하도록 최적화한 알고리즘입니다. 이는 GPU 메모리 계층 구조의 특성을 효율적으로 활용함으로써 가능해집니다.핵심 원리:
표준 어텐션 구현의 주요 성능 병목 현상은 종종 순수한 계산량 자체가 아니라, 계산 과정에서 생성되는 매우 큰 중간 결과물(특히, (시퀀스 길이)x(시퀀스 길이) 크기의 어텐션 스코어 행렬)을 상대적으로 느린 GPU의 주 메모리(High Bandwidth Memory, HBM)에 쓰고 다시 읽어오는 과정에서 발생합니다.FlashAttention은 이러한 느린 HBM 접근을 최소화하는 데 초점을 맞춥니다.
- 타일링 (Tiling): 입력 행렬들(쿼리 Q, 키 K, 밸류 V)을 GPU의 훨씬 빠른 온칩 메모리(SRAM)에 들어갈 수 있는 작은 블록(타일) 단위로 분할합니다.
- SRAM 내 연산: 각 블록에 대한 어텐션 계산(Q와 K의 행렬 곱셈으로 점수 계산, 소프트맥스 적용, V와의 가중 합 계산)을 전적으로 빠른 SRAM 내에서 수행합니다. 이를 통해 거대한 중간 어텐션 스코어 행렬 전체를 느린 HBM에 기록할 필요가 없어집니다. (블록 단위 소프트맥스 계산을 위해 수치적으로 안정적인 기법을 사용합니다.)
- 역방향 전파 최적화: 훈련 시 역방향 전파(그래디언트 계산)를 위해 일반적으로 순방향 계산 시 생성된 큰 어텐션 행렬을 저장해야 하지만, 이는 많은 메모리를 소모합니다. FlashAttention은 이를 저장하는 대신, 역방향 계산에 필요한 부분을 SRAM 내에서 즉석에서 재계산하는 방식을 사용하여, 약간의 추가 계산 비용으로 메모리 사용량을 크게 절약합니다.
결론적으로, FlashAttention은 GPU 메모리 계층 구조에 최적화된 IO-인식(aware) 접근 방식을 통해 HBM 읽기/쓰기를 최소화함으로써, 정확한 어텐션 계산 결과는 유지하면서도 연산 속도를 크게 높이고 메모리 사용량은 줄이는 효과를 달성합니다.
-
배포를 위해 ONNX 또는 TensorRT를 사용하는 목적은 무엇입니까?
훈련된 딥러닝 모델을 실제 서비스 환경에 배포하여 추론을 수행할 때는, 모델의 실행 속도를 높이고 자원 사용량을 줄이는 최적화 과정이 중요합니다. ONNX와 TensorRT는 이러한 목적을 위해 널리 사용되는 대표적인 도구 및 프레임워크입니다.-
ONNX (Open Neural Network Exchange):
- 목적: 다양한 딥러닝 프레임워크(PyTorch, TensorFlow 등) 간의 상호 호환성(interoperability)을 제공하는 개방형 표준 모델 포맷입니다.
- 작동 방식: 특정 프레임워크에서 훈련된 모델을 ONNX 포맷으로 변환하면, 이 포맷을 지원하는 다양한 하드웨어나 추론 엔진(예: ONNX Runtime)에서 모델을 실행할 수 있습니다. 개발 프레임워크와 배포 환경이 달라도 모델을 쉽게 이전하고 실행할 수 있게 해줍니다.
- 최적화: ONNX Runtime 자체도 모델 그래프 최적화(예: 연산자 융합)나 하드웨어 가속 기능 활용 등의 최적화를 수행하여 추론 성능을 개선합니다.
-
TensorRT:
- 목적: NVIDIA GPU 환경에서 추론 성능을 극대화하기 위해 NVIDIA에서 제공하는 소프트웨어 개발 키트(SDK) 및 런타임 라이브러리입니다.
- 작동 방식: 다양한 프레임워크(종종 ONNX를 통해 변환된 모델 포함)에서 개발된 모델을 입력받아, NVIDIA GPU 아키텍처에 특화된 매우 공격적인 최적화를 수행합니다.
-
주요 최적화 기법:
- 계층 및 텐서 융합: 여러 개의 연산을 하나의 GPU 커널로 통합하여 오버헤드를 줄입니다.
- 커널 자동 튜닝: 타겟 GPU 하드웨어에서 가장 빠른 성능을 내는 커널 구현을 자동으로 선택합니다.
- 정밀도 보정: FP16, INT8 등 저정밀도 연산을 사용하도록 모델을 최적화하여 속도를 높입니다.
- 다중 스트림 실행, 동적 텐서 메모리 관리 등.
- 결과: 일반적으로 NVIDIA GPU에서 가장 낮은 지연 시간과 가장 높은 처리량을 달성하는 것을 목표로 합니다.
요약하면, ONNX는 다양한 환경 간의 모델 호환성을 위한 표준 역할을 하며, TensorRT는 NVIDIA GPU에서의 최대 성능을 끌어내기 위한 심층적인 최적화 도구라고 볼 수 있습니다. 종종 ONNX로 모델을 변환한 뒤, 이를 TensorRT로 추가 최적화하는 워크플로우가 사용됩니다.
-
ONNX (Open Neural Network Exchange):
-
LLM 추론 시 사용되는 정적 배칭과 연속 배칭 기법은 어떻게 다르며, 왜 연속 배칭 방식이 LLM 환경에서 더 우수한 성능을 보이는 경우가 많습니까? 또한, vLLM과 같은 기술이 연속 배칭의 효율적인 구현에 구체적으로 어떻게 기여하는지 설명해 주십시오.
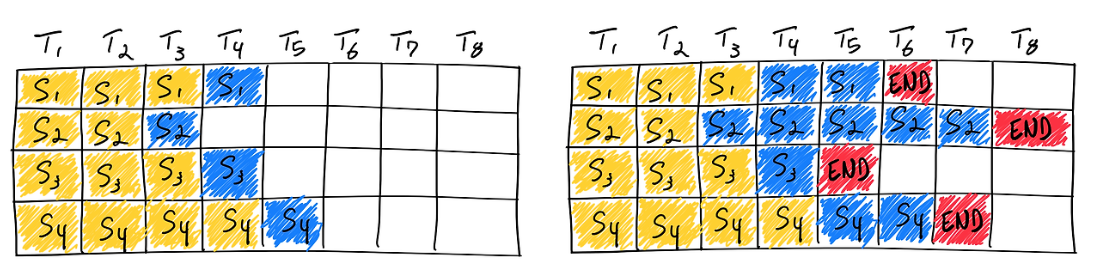
LLM 추론 시 배칭(Batching)은 여러 사용자의 요청을 한 번에 모아 처리함으로써 GPU와 같은 병렬 처리 하드웨어의 효율을 높이는 중요한 기법입니다. 배칭 방식에는 크게 정적 배칭과 연속 배칭이 있습니다.-
정적(static) 배칭:
- 방식: 들어오는 요청들을 미리 정해진 크기(개수)의 배치로 묶습니다. GPU는 이 배치 전체에 대한 연산이 모두 완료될 때까지 기다린 후 다음 배치를 처리합니다.
-
단점: LLM의 응답 길이는 요청마다 매우 가변적입니다. 정적 배칭에서는 배치 내에서 가장 긴 응답 생성이 필요한 요청이 끝날 때까지, 이미 생성이 끝난 다른 짧은 요청들도 함께 기다려야 합니다. 이는 GPU 자원의 낭비(유휴 시간 증가)를 초래하고 사용자의 평균 응답 시간을 늘려 비효율적입니다.
-
연속(continuous) 배칭 또는 동적(dynamic) 배칭:
- 방식: 고정된 배치를 사용하지 않고, 요청들을 동적으로 관리합니다. GPU에서 처리 중인 요청 그룹 내에서 어떤 요청이라도 응답 생성이 완료되면, 해당 요청이 사용하던 자원을 즉시 해제하고, 그 자리에 대기 중이던 새로운 요청을 바로 투입하여 다음 연산 단계를 수행합니다.
-
장점: 전체 그룹이 끝날 때까지 기다릴 필요 없이 GPU가 끊임없이 작업을 수행할 수 있습니다. LLM의 가변적인 출력 길이 문제를 효과적으로 해결하여 GPU 활용률을 극대화하고, 평균 지연 시간을 줄이며, 전체 시스템 처리량을 크게 향상시킵니다. 따라서 다양한 길이의 요청이 섞이는 실제 서비스 환경에 훨씬 적합합니다.
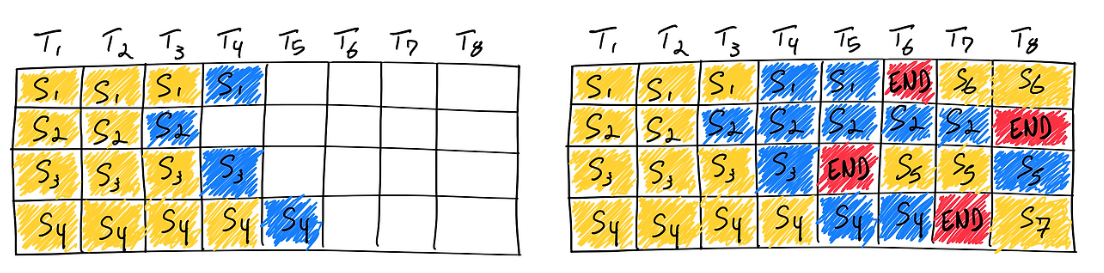
vLLM과 PagedAttention의 기여:
연속 배칭의 개념은 효율적이지만, 이를 실제로 구현하는 데는 기술적 난제가 있었습니다. 특히, 트랜스포머 어텐션 연산에 사용되는 KV 캐시의 메모리 관리가 문제였습니다. 요청마다 길이가 다르고 동적으로 요청이 추가/제거되다 보니, 메모리 공간이 잘게 조각나는 단편화(fragmentation) 현상이 심하게 발생하여 메모리를 효율적으로 재사용하기 어려웠습니다.
vLLM 라이브러리는 PagedAttention이라는 혁신적인 기술을 도입하여 이 문제를 해결했습니다.- PagedAttention: 운영체제의 메모리 페이징(paging) 기법에서 영감을 받아, KV 캐시를 물리적으로 연속될 필요가 없는 작은 고정 크기의 블록(페이지) 단위로 관리합니다.
- 효과: 각 요청은 필요한 만큼의 페이지만 할당받고, 요청이 완료되면 사용했던 페이지를 즉시 반환하여 다른 요청이 재사용할 수 있습니다. 이를 통해 메모리 단편화를 거의 없애고, KV 캐시 메모리 활용률을 90% 이상으로 높여 연속 배칭을 매우 효율적으로 구현할 수 있게 되었습니다.
결과적으로 vLLM과 PagedAttention은 연속 배칭의 이론적 장점을 현실화하여 LLM 추론 서빙 성능을 크게 향상시키는 데 핵심적인 역할을 하고 있습니다.
-
정적(static) 배칭:
VIII. 추론, 프롬프팅 및 에이전트
인 컨텍스트 학습 효과는 모델 크기에 따라 어떻게 확장됩니까?
인 컨텍스트 학습(In-Context Learning, ICL)은 LLM이 모델의 가중치를 전혀 변경하지 않고, 오직 프롬프트 내에 제시된 퓨샷 샘플이나 지시사항만 보고 새로운 작업을 수행하거나 특정 방식으로 응답하는 놀라운 능력을 의미합니다.
이 ICL 능력의 효과는 모델의 규모(크기)와 매우 강한 양의 상관관계를 보입니다. 즉, 모델의 파라미터 수, 학습 데이터 양, 사전 훈련에 사용된 계산량이 클수록 ICL 성능이 훨씬 뛰어납니다. 많은 연구에서 효과적인 ICL은 규모의 창발적 속성으로 나타나는 경향을 보입니다. 작은 모델에서는 거의 나타나지 않거나 미미하지만, 모델 크기가 특정 임계점을 넘어서면 성능이 급격하게 향상됩니다.
이는 더 큰 모델일수록 프롬프트 내의 퓨샷 샘플에 암시된 작업의 패턴이나 숨겨진 규칙을 더 잘 파악하고, 이를 동일 프롬프트 내의 새로운 문제에 일반화하여 적용하는 능력이 뛰어나기 때문으로 해석됩니다. 프롬프트에 예시를 더 많이 제공하는 것이 도움이 될 수도 있지만, 근본적인 ICL 능력 자체는 주로 사전 훈련된 모델의 규모에 의해 결정되는 것으로 보입니다.-
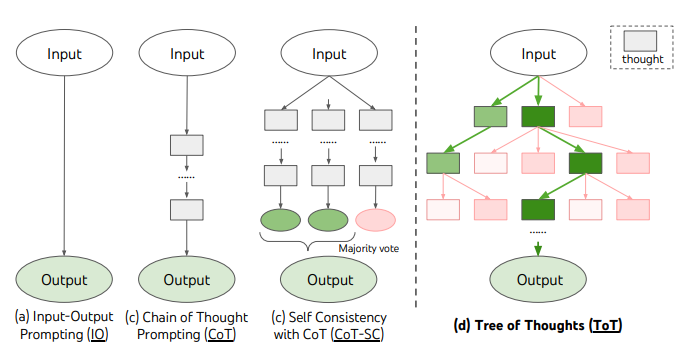
연쇄적 사고 프롬프팅을 설명해 주십시오. 사고의 트리와 같은 전략은 어떻게 다릅니까?
연쇄적 사고 (Chain-of-Thought, CoT) 프롬프팅은 LLM이 수학 문제 풀이, 논리 추론 등 복잡하고 여러 단계의 사고가 필요한 작업을 더 잘 수행하도록 유도하는 프롬프팅 기법입니다.작동 방식: 최종적인 답만 바로 요구하는 대신, 문제 해결에 이르는 중간 단계의 생각 또는 추론 과정을 명시적으로 생성하도록 유도합니다. 이는 프롬프트에 단계별 풀이 과정을 보여주는 퓨샷 샘플을 포함시키거나, 단순히 "단계별로 생각해보자(Let's think step by step)"와 같은 지시 문구를 추가하는 방식으로 이루어질 수 있습니다. 모델이 생각의 흐름을 따라가도록 함으로써 복잡한 문제에 대한 정답률을 크게 높일 수 있습니다.
사고의 트리 (Tree-of-Thought, ToT)는 CoT에서 더 나아간 개념으로, 단일한 선형적인, 사고의 연쇄 대신 여러 가능한 추론 경로를 동시에 탐색하는 방식입니다. 마치 나무의 가지처럼 여러 가능성을 고려합니다.
ToT 프레임워크의 일반적인 단계:
- 문제 분해: 복잡한 문제를 여러 하위 단계나 생각 단위로 나눕니다.
- 사고 생성: 현재 상태에서 가능한 다음 단계 또는 중간 생각들을 여러 개 생성합니다 (다른 가지 탐색).
- 상태 평가: 생성된 여러 중간 상태나 추론 경로의 유효성, 가능성, 유망성 등을 평가합니다 (때로는 LLM 자체를 평가자로 사용).
- 탐색: 너비 우선 탐색(BFS)이나 깊이 우선 탐색(DFS) 같은 알고리즘을 사용하여 이 '사고의 트리'를 탐색하며, 가능성이 낮은 가지는 잘라내거나 막다른 길에 다다르면 되돌아갑니다.
주요 차이점: CoT는 하나의 순차적인 추론 경로를 따르는 반면, ToT는 동시에 여러 가능성을 탐색하고 평가합니다. 따라서 ToT는 탐색, 대안 평가, 또는 자기 수정이 중요한 복잡한 문제 해결에 더 강건한 접근 방식이 될 수 있습니다.
-
LLM이 복잡한 다단계 추론이 필요한 문제에 대해 프롬프트 엔지니어링 기법(예: CoT)만으로는 근본적인 한계에 부딪히는 이유는 무엇이며, 이러한 한계는 LLM 자체의 어떤 내재적 특성들과 관련이 있습니까?
CoT와 같은 프롬프트 엔지니어링 기법은 LLM의 복잡한 추론 능력을 눈에 띄게 향상시키지만, 다음과 같은 LLM 자체의 내재적 특성으로 인해 근본적인 한계에 부딪힙니다.- 표면적 패턴 민감성: LLM은 프롬프트의 단어 선택이나 문장 구조 등 표면적 형태에 매우 민감하게 반응합니다. 의미는 동일하더라도 표현 방식이 조금만 달라져도 결과가 불안정해질 수 있습니다. 이는 모델이 깊은 의미론적 이해보다는 통계적 패턴 학습에 크게 의존하기 때문입니다.
- 내재된 추론 능력의 한계: 프롬프팅은 모델이 가진 잠재된 추론 능력을 이끌어내는 역할을 할 뿐, 모델이 원래 가지고 있지 않은 새로운 논리적, 수학적, 또는 상식적 추론 능력을 창조하지는 못합니다. CoT 역시 모델의 추론 과정을 단지 명시적으로 보여주는 것이며, 그 과정 자체에 오류가 포함될 수 있습니다. 이는 LLM이 명시적인 기호 조작이나 추론 엔진을 갖춘 것이 아니라, 방대한 텍스트 데이터로부터 암묵적인 지식과 패턴을 학습했기 때문입니다.
- 환각 경향성: LLM은 학습 데이터의 지식 경계를 벗어나거나 매우 복잡한 추론을 요구받을 때, 사실이 아니거나 논리적으로 맞지 않는 내용을 그럴듯하게 생성(환각)하는 경향이 있습니다. 프롬프팅만으로는 생성된 내용의 사실성이나 논리적 건전성을 완벽하게 보장하기 어렵습니다.
- 오류 누적 및 수정의 어려움: CoT와 같이 선형적인 단계별 추론 방식에서는 초기 단계의 작은 오류가 후속 단계로 전파되어 최종 결과에 큰 영향을 미칠 수 있습니다. 또한, LLM의 자기회귀적 생성 방식은 한번 잘못된 방향으로 진행된 추론을 중간에 스스로 수정하거나 다른 대안적인 경로를 탐색하기 어렵게 만듭니다 (ToT 등이 이를 보완하려 함).
- 컨텍스트 길이 제한: 프롬프트에 담을 수 있는 정보의 양(예시, 지시사항)과 CoT 같은 추론 과정의 길이가 물리적으로 제한됩니다. 매우 길고 복잡한 문제는 프롬프트만으로 해결하기 어렵습니다.
결론적으로, 프롬프트 엔지니어링은 LLM의 능력을 최대한 활용하기 위한 강력한 인터페이스이지만, LLM 아키텍처와 학습 방식 자체의 근본적인 한계를 극복할 수는 없습니다. 진정으로 복잡한 추론 능력을 획기적으로 향상시키기 위해서는 프롬프팅 기법의 발전과 더불어 모델 아키텍처, 학습 알고리즘, 데이터 전략 등의 근본적인 개선이 병행되어야 합니다.
-
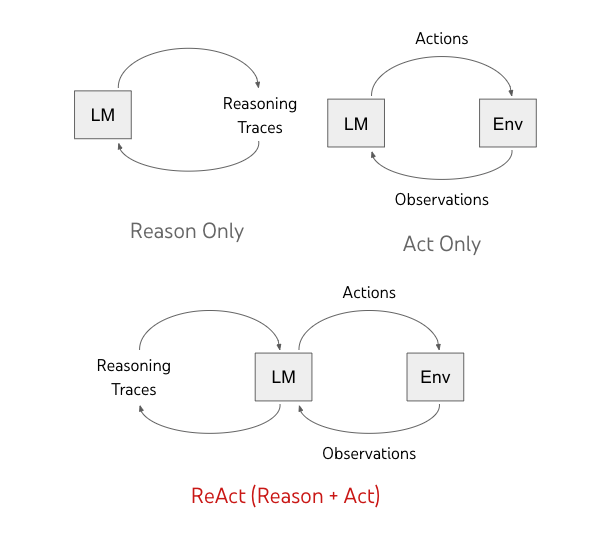
프롬프트는 어떻게 계획을 유도할 수 있습니까? 도구 사용을 위한 ReAct와 같은 프레임워크를 설명해 주십시오.
LLM에게 명시적으로 계획을 세우도록 요청하는 프롬프트를 통해 계획 행동을 유도할 수 있습니다. 예를 들어, "이 문제를 해결하기 위한 단계별 계획을 먼저 세우고, 그 다음 계획에 따라 실행하세요." 와 같이 지시할 수 있습니다.ReAct (Reason + Act) 프레임워크는 LLM이 추론과 행동을 번갈아 수행하며 복잡한 작업을 해결하도록 하는 보다 구조화된 접근 방식입니다. 특히 검색 엔진, 계산기, API 호출 등 외부 도구(tool) 사용이 필요한 작업에 효과적입니다.
ReAct의 작동 방식:
ReAct는 일반적으로 LLM이 다음과 같은 생각-행동-관찰의 순환 고리 안에서 작동하도록 프롬프트를 구성합니다.- 사고 (thought): LLM은 현재 주어진 문제 상황, 이전 단계의 결과(관찰), 최종 목표 등을 고려하여 상황을 분석하고, 다음 행동 계획을 세웁니다. (예: "현재 정보가 부족하니, 관련 정보를 검색해야겠다.")
- 행동 (action): LLM은 계획한 내용을 바탕으로 수행할 구체적인 행동을 결정합니다. 주로 사용할 외부 도구와 해당 도구에 전달할 입력(인수)을 특정 형식으로 지정합니다. (예:
Action: Search[검색할 키워드]) - 관찰 (observation): 외부 시스템(ReAct 실행 환경)이 LLM이 지정한 행동(예: 검색 엔진 API 호출)을 실제로 수행하고, 그 결과(예: 검색 결과 요약)를 얻습니다. 이 결과는 '관찰' 정보로서 다음 번 LLM의 입력 프롬프트에 포함됩니다.
LLM은 이 '사고 → 행동 → 관찰' 주기를 반복하면서, 동적으로 계획을 수정하고, 외부 도구를 활용하여 필요한 정보를 얻거나 계산을 수행하며, 그 결과를 바탕으로 다시 추론합니다. 이를 통해 LLM은 자신의 내부 지식만으로는 해결하기 어려운 복잡한 문제나 최신 정보가 필요한 질문에 효과적으로 답할 수 있게 됩니다.
-
AutoGen이나 MetaGPT와 같은 AI 에이전트 프레임워크가 LLM을 활용하여 해결하고자 하는 핵심적인 한계점은 무엇이며, 이러한 프레임워크들은 LLM을 단순한 텍스트 생성 도구를 넘어 목표 지향적인 문제 해결 시스템으로 전환시키기 위해 구체적으로 어떤 기능적 구성요소들을 제공하고 있습니까?
AutoGen, MetaGPT와 같은 AI 에이전트 프레임워크는 LLM의 강력한 언어 이해 및 생성 능력을 기반으로 하되, 단순한 질의응답이나 텍스트 생성을 넘어 복잡하고 여러 단계로 이루어진 목표 지향적인 작업을 자율적으로 수행하도록 설계되었습니다. 즉, LLM을 단순한 '도구'에서 스스로 계획하고, 행동하며, 상호작용하고, 협업할 수 있는 '지능형 에이전트'로 발전시키는 것을 목표로 합니다.
이러한 프레임워크들이 해결하고자 하는 LLM의 핵심적인 한계점은 다음과 같습니다.- 상태 및 기억 관리의 부재: LLM은 제한된 컨텍스트 윈도우 내의 정보만 처리 가능하며, 장기적인 상태나 기억을 유지하기 어렵습니다.
- 외부 세계와의 상호작용 능력 부족: LLM 자체만으로는 외부 도구(API, 데이터베이스, 검색 엔진 등)를 사용하거나 실제 환경과 상호작용할 수 없습니다.
- 복잡한 계획 및 작업 분해 능력 부족: 복잡한 목표를 달성하기 위해 체계적인 계획을 세우고 이를 하위 작업으로 분해하는 능력이 부족합니다.
- 자기 성찰 및 개선 능력 부족: 자신의 결과물이나 계획의 문제점을 스스로 인지하고 수정하는 능력이 제한적입니다.
AI 에이전트 프레임워크는 이러한 한계를 극복하기 위해 LLM을 핵심 엔진으로 사용하면서 다음과 같은 기능적 구성요소들을 제공합니다:
- 계획 수립 및 작업 분해: 사용자의 복잡한 목표를 분석하여 실행 가능한 하위 작업들의 순서나 구조로 이루어진 계획을 생성하고 관리합니다.
- 도구 사용: LLM이 필요에 따라 외부 API, 계산기, 코드 실행기, 검색 엔진 등 다양한 외부 도구를 호출하고 그 결과를 활용할 수 있도록 인터페이스를 제공합니다 (예: ReAct 방식 활용).
- 메모리 관리: 단기 기억(컨텍스트 윈도우)의 한계를 넘어, 작업 수행 중 얻은 정보나 이전 상호작용 기록을 저장하고 필요할 때 검색하여 활용할 수 있는 장기 기억 메커니즘을 제공합니다 (예: 벡터 데이터베이스 활용).
- 다중 에이전트 협업: 각기 다른 역할이나 전문성을 가진 여러 LLM 기반 에이전트들이 서로 대화하고 상호작용하며 공동으로 복잡한 문제를 해결하도록 지원합니다. (예: AutoGen의 대화형 에이전트, MetaGPT의 역할 기반 소프트웨어 개발 프로세스 시뮬레이션).
- 자기 성찰 및 개선: 에이전트가 스스로 생성한 계획, 코드, 문서 등의 중간 결과물을 평가하고 문제점을 파악하여 수정하도록 함으로써 최종 결과물의 품질과 신뢰도를 높입니다.
결론적으로, AI 에이전트 프레임워크는 LLM의 핵심 능력에 계획, 도구 사용, 기억, 협업, 자기 성찰 등의 기능을 결합하여 그 한계를 보완하고, LLM을 단순한 API 호출의 대상을 넘어 복잡하고 실용적인 문제를 해결하는 정교한 시스템으로 발전시키는 것을 목표로 합니다.
IX. 평가 및 벤치마킹
-
생성 모델 평가의 어려움에 대해 논의하고, 자동화된 지표와 인간 평가를 대조 설명해 주십시오.
생성 모델의 성능을 평가하는 것은 여러 가지 이유로 본질적인 어려움을 내포합니다.
어려움의 원인:- 주관성 및 개방형 결과: 생성 모델의 결과물(텍스트, 이미지 등)은 정답이 하나로 정해진 분류나 예측 문제와 달리, 그 품질을 판단하는 기준이 주관적일 수 있고 결과물의 형태가 매우 다양합니다. 창의성, 문체, 미적 감각 등은 정량화하기 어렵습니다.
- 다면적 평가 기준: 좋은 생성 결과물은 관련성, 사실 정확성, 논리성, 일관성, 유창성, 안전성, 유용성 등 여러 기준을 동시에 만족해야 하는 경우가 많습니다. 하지만 단일 지표로 이 모든 측면을 포괄적으로 평가하기는 어렵습니다.
평가 방법 비교:
-
자동화된 지표:
- 예시: 텍스트 생성 평가의 BLEU, ROUGE 점수, 이미지 생성 평가의 FID(Fréchet Inception Distance), IS(Inception Score) 등
- 작동 방식: 주로 결과물의 표면적 특징(예: 단어 중복률, 픽셀 분포 유사도)을 계산합니다.
- 장점: 빠르고, 비용이 적게 들며, 대규모 평가가 가능하여 모델 개발 과정에서 반복적인 테스트에 유용합니다.
- 단점: 생성물의 실제 품질이나 의미론적 정확성, 논리적 오류, 창의성, 유해성 등 깊이 있는 측면을 제대로 반영하지 못하며, 인간의 선호도와 상관관계가 낮은 경우가 많습니다.
-
인간 평가:
- 작동 방식: 실제 사람이 직접 생성 결과물을 보고 정해진 기준(예: 유창성, 관련성, 창의성, 안전성 등)에 따라 점수를 매기거나 선호도를 비교합니다.
- 장점: 자동 평가 지표가 놓치는 미묘한 품질 차이, 문맥 이해도, 창의성, 실제 사용자가 느끼는 유용성 및 안전성 등을 평가하는 데 가장 신뢰도 높은 방법입니다.
- 단점: 시간과 비용이 많이 들고, 노동 집약적입니다. 평가자 간의 주관성, 판단 불일치, 잠재적 편향이 존재할 수 있으며, 평가의 일관성을 유지하기 어렵습니다. 결론적으로, 자동화된 지표로 쉽게 측정 가능한 것과 인간이 실제로 고품질 또는 유용하다고 인식하는 것 사이에는 종종 상당한 간극이 존재합니다. 따라서 생성 모델 평가는 보통 자동화된 지표와 인간 평가를 상호 보완적으로 활용합니다.
-
LLM의 내재적 사실성(예: TruthfulQA 사용)을 어떻게 체계적으로 평가합니까?
LLM이 사실에 기반한 정보를 생성하는지, 아니면 잘못된 정보를 그럴듯하게 만들어내는지(환각)를 평가하는 것은 LLM의 신뢰도 측면에서 매우 중요하며, 단순 정확도 측정 이상의 체계적인 접근이 필요합니다.
평가 방법 및 벤치마크:-
특수 목적 벤치마크 활용:
- TruthfulQA: 일부러 흔한 오해나 잘못된 상식을 정답처럼 보이도록 유도하는 질문들을 포함합니다. 모델이 인터넷 등에서 학습했을 수 있는 잘못된 정보를 단순히 반복하는 대신, 진실된 답변을 생성하는 능력을 평가합니다.
- HaluEval: 모델이 생성한 환각을 탐지하는 능력을 평가하기 위해, 의도적으로 환각이 포함된 텍스트 데이터셋을 제공합니다.
-
정량적 지표 측정:
- 사실 기반 질문 정확도: 정답이 명확하게 알려진 사실적 질문에 대해 모델이 얼마나 정확하게 답변하는지 측정합니다.
- 충실성 평가: RAG(검색 증강 생성) 시스템의 경우, 모델이 생성한 답변이 참조한 외부 문서(컨텍스트)의 내용과 얼마나 일치하는지 평가합니다.
- 보정 분석: 모델이 답변에 대해 표현하는 자신감(confidence) 수준이 실제 정답률과 얼마나 일치하는지 분석합니다. 자신감과 정확도가 일치하지 않으면 모델의 신뢰도를 판단하기 어렵습니다.
-
다양한 방법론 적용:
- 지식 탐색: 특정 도메인에 대한 모델의 지식 보유 정도를 평가합니다.
- 적대적 질문: 모델을 혼동시키거나 잘못된 답변을 유도하도록 설계된 질문을 사용합니다.
- 외부 지식 검증: 모델이 생성한 주장을 위키피디아와 같은 외부 지식 베이스나 신뢰할 수 있는 데이터베이스와 대조하여 사실 여부를 확인합니다.
- LLM 심사위원 (LLM-as-a-Judge): 다른 강력한 LLM을 사용하여 모델 답변의 사실성이나 품질을 평가하기도 합니다. (단, 심사위원 LLM의 편향이 개입될 수 있습니다.)
LLM의 사실성을 체계적으로 평가하기 위해서는 이처럼 환각이라는 특정 실패 유형을 겨냥한 다양한 벤치마크와 평가 지표를 사용해야 하며, 종종 자동화된 평가 결과를 세심한 인간의 분석으로 보완하는 것이 필요합니다.
-
특수 목적 벤치마크 활용:
-
LLM 추론 능력은 어떻게 평가됩니까? 주요 벤치마크를 언급해 주십시오.
LLM의 추론 능력을 평가하는 것은 단순한 정보 검색이나 패턴 암기 능력을 넘어, 논리적 사고, 수학적 문제 해결, 단계적 추론, 상식 이해 등 고차원적인 인지 능력을 측정하는 것을 목표로 합니다. 이를 위해 정답을 맞히기 위해 반드시 추론 과정이 필요한 문제들로 구성된 다양한 벤치마크가 사용됩니다. 주요 벤치마크는 다음과 같습니다.- MMLU (Massive Multitask Language Understanding): 과학, 기술, 공학, 수학(STEM)부터 인문학, 사회과학까지 총 57개의 다양한 주제를 포괄하는 객관식 질문으로 구성되어, 모델의 광범위한 지식과 문제 해결 능력을 종합적으로 평가합니다.
- GSM8K (Grade School Math 8K): 여러 단계의 산술 연산이 필요한 초등학교 수준의 수학 응용 문제들로 구성되어, 모델의 수학적 추론 및 단계적 문제 해결 능력을 측정합니다. 주로 연쇄적 사고(CoT) 프롬프팅과 함께 평가됩니다.
- BIG-Bench (Beyond the Imitation Game Benchmark): 매우 다양하고 어려운 인지 능력 (까다로운 추론 문제 포함)을 평가하기 위해 설계된 대규모 협업 벤치마크입니다.
- HellaSwag: 주어진 문맥 다음에 이어질 가장 자연스러운 문장을 고르는 객관식 문제를 통해 모델의 상식 추론 능력을 평가합니다.
- ARC (AI2 Reasoning Challenge): 추론이 필요한 까다로운 과학 질문(초등 및 중학교 수준)들로 구성되어 있습니다.
- DROP (Discrete Reasoning Over Paragraphs): 주어진 지문을 읽고 답을 찾아야 하지만, 답을 찾기 위해 덧셈, 개수 세기, 비교 등 추가적인 불연속적 추론 단계가 필요한 독해력 벤치마크입니다.
- MATH: 대수학, 기하학, 정수론 등 고급 수학적 추론 능력이 요구되는 어려운 경시대회 수준의 수학 문제들을 포함합니다.
- HumanEval: 코드 생성 능력을 평가하는 벤치마크로, 정확한 코드를 작성하는 데 필요한 논리적 추론 능력을 간접적으로 측정합니다.
이러한 벤치마크들은 모델이 단순한 정보 암기나 표면적 패턴 매칭을 넘어, 보다 견고하고 복잡한 추론 능력을 갖추도록 개발 방향을 유도하는 데 중요한 역할을 합니다.
-
프롬프트 정렬(CLIP 스코어), 품질/사실성(FID), 다양성 등 텍스트-이미지 모델 평가에 대해 설명해 주십시오.
텍스트 설명(프롬프트)을 입력받아 이미지를 생성하는 텍스트-이미지 모델을 평가할 때는 주로 다음과 같은 세 가지 측면을 종합적으로 고려합니다.- 프롬프트 정렬 및 충실성:
- 의미: 생성된 이미지가 입력된 텍스트 프롬프트의 내용과 의미를 얼마나 충실하게 반영하는지를 나타냅니다. 프롬프트에 묘사된 객체, 속성, 관계, 스타일 등이 이미지에 잘 표현되었는지가 중요합니다.
- 주요 지표: CLIP 스코어가 널리 사용됩니다. CLIP과 같은 비전-언어 모델을 사용하여 입력 텍스트 프롬프트의 임베딩과 생성된 이미지의 임베딩 간의 의미론적 유사도(코사인 유사도 등)를 계산합니다. 점수가 높을수록 일반적으로 프롬프트와의 정렬이 잘 되었다고 간주합니다.
- 이미지 품질 및 사실성:
- 의미: 생성된 이미지가 시각적으로 얼마나 자연스럽고 사실적인지, 기술적인 결함은 없는지 등을 평가합니다.
- 주요 지표: FID가 표준적으로 사용됩니다. 사전 훈련된 Inception 네트워크를 사용하여 생성된 이미지들의 특징 분포와 실제 이미지들의 특징 분포 간의 거리를 측정합니다. FID 점수가 낮을수록 생성된 이미지들이 실제 이미지와 통계적으로 유사하며, 이는 더 높은 품질과 사실성을 의미하는 경향이 있습니다.
- 다양성:
- 의미: 모델이 동일하거나 유사한 프롬프트에 대해 다양하고 서로 다른 이미지를 생성하는 능력을 의미합니다. 다양성이 부족하면 모델이 특정 종류의 이미지 만을 반복적으로 생성하는 '모드 붕괴(mode collapse)' 현상을 겪고 있을 수 있습니다.
- 평가: FID가 간접적으로 다양성을 일부 반영하지만, 완벽하지는 않습니다. 생성된 이미지들 간의 유사도를 측정하거나, 특정 지표를 사용하거나, 인간이 직접 평가하여 다양성을 판단하는 경우가 많습니다.
이처럼 텍스트-이미지 모델 평가는 자동화된 지표(CLIP 스코어, FID 등)와 함께, 인간 평가를 통한 정성적인 분석(미적 만족도, 세부 묘사의 정확성, 프롬프트의 미묘한 뉘앙스 반영 여부 등)을 병행하여 종합적으로 이루어지는 것이 일반적입니다.
- 프롬프트 정렬 및 충실성:
-
멀티모달 모델은 어떻게 평가합니까? 특별한 어려움은 무엇입니까?
텍스트, 이미지, 오디오 등 여러 유형의 정보를 동시에 처리하는 멀티모달 모델을 평가하는 것은 각 모달리티를 개별적으로 평가하는 것을 넘어, 모달리티 간의 상호 작용을 이해하고 이를 바탕으로 추론하는 능력까지 측정해야 하므로 더 복잡합니다.
평가 방법:-
작업별 벤치마크 활용: 멀티모달 능력을 요구하는 특정 작업에 대한 성능을 측정하는 것이 일반적입니다.
- 시각 질의응답 (Visual Question Answering, VQA): 이미지와 관련된 질문에 답하는 능력 평가 (예: VQAv2, GQA 데이터셋).
- 이미지 캡셔닝: 주어진 이미지에 대한 자연어 설명을 생성하는 능력 평가 (예: COCO Captions 데이터셋, BLEU, CIDEr, SPICE 등 지표 사용).
- 텍스트-이미지 검색: 텍스트 설명에 해당하는 이미지를 찾거나, 이미지에 해당하는 텍스트 설명을 찾는 능력 평가 (예: Flickr30k, COCO 데이터셋, Recall@K 지표 사용).
- 이 외에도 비디오 이해, 오디오-시각 연관 등 다양한 멀티모달 벤치마크가 있습니다.
주요 어려움:
- 진정한 크로스 모달 추론 검증: 모델이 실제로 여러 모달리티 정보를 통합하여 추론하는지, 아니면 단일 모달리티 내의 편향이나 지름길에 의존하여 정답을 맞히는지 구분하기 어렵습니다.
- 크로스 모달 일관성 평가: 예를 들어, 모델이 이미지와 그에 대한 설명을 함께 생성했을 때, 생성된 텍스트가 생성된 이미지를 정확하고 일관성 있게 묘사하는지 자동으로 평가하기 어렵습니다.
- 추론 과정 평가의 부재: 최종 결과물의 정답 여부뿐만 아니라, 모델이 결론에 도달하기까지의 크로스 모달 추론 과정 자체가 타당한지 평가하는 표준화된 방법론이 부족합니다.
- 데이터 부족: 복잡한 멀티모달 추론 능력을 평가하기 위한 대규모 고품질 벤치마크 데이터가 아직 부족한 경우가 많습니다.
- 주관성 및 인간 평가 의존: 생성된 멀티모달 콘텐츠의 품질, 관련성, 창의성 등을 판단하는 데에는 본질적인 주관성이 개입될 수밖에 없어, 신뢰도 높은 평가를 위해 세심하게 설계된 인간 평가가 필수적인 경우가 많습니다.
-
작업별 벤치마크 활용: 멀티모달 능력을 요구하는 특정 작업에 대한 성능을 측정하는 것이 일반적입니다.
-
생성 모델 벤치마크의 알려진 한계나 '게임화' 문제는 무엇입니까?
벤치마크는 생성 모델 연구의 진척 상황을 측정하고 모델 간 성능을 비교하는 데 필수적인 도구이지만, 다음과 같은 잘 알려진 한계점과 문제점(소위 '게임화' 또는 '벤치마크 해킹')을 가지고 있습니다.- 데이터 오염: 평가에 사용되어야 할 테스트셋 데이터가 의도치 않게 모델의 사전 훈련 데이터에 포함되는 경우입니다. 이 경우 모델은 단순히 정답을 '암기'하여 비정상적으로 높은 점수를 받게 되며, 공정한 성능 비교가 불가능해집니다. 대규모 웹 스크레이핑 데이터 사용 시 발생하기 쉽습니다.
- 벤치마크 과적합: 모델이 벤치마크 자체의 특정 형식, 문제 유형, 데이터 분포에 과도하게 최적화되는 현상입니다. 이 경우 벤치마크 점수는 높지만, 실제 세상의 다양하고 새로운 문제에 대한 일반적인 능력은 향상되지 않았을 수 있습니다.
- 지표와 실제 성능 간의 괴리: 앞서 언급했듯이, BLEU, FID 등 자동화된 평가 지표 점수가 높다고 해서 반드시 인간이 느끼는 품질, 유용성, 창의성, 안전성 등이 높은 것은 아닙니다.
- 평가 설정 민감성: 모델 성능은 어떤 프롬프트를 사용했는지, 어떤 샘플링 파라미터를 적용했는지 등 평가 설정에 따라 크게 달라질 수 있습니다. 평가 조건이 표준화되지 않거나 명확히 보고되지 않으면 모델 간의 직접적인 비교가 어렵습니다.
- 벤치마크의 정체성 및 노후화: 대부분의 벤치마크는 한번 구축되면 잘 변하지 않습니다. 시간이 지나 모델 성능이 향상되면 벤치마크 문제들이 너무 쉬워져('해결(solved)'됨) 더 이상 최신 모델들의 성능 차이를 변별하지 못하게 될 수 있습니다.
- 평가자 편향: 인간 평가나 LLM을 심사위원으로 사용하는 평가 방식은 평가자의 주관성, 선입견, 일관성 부족 등의 문제로부터 자유롭기 어렵습니다.
이러한 한계들 때문에 벤치마크 점수는 항상 비판적인 시각으로 해석해야 하며, 가능하면 정성적 분석, 추가적인 인간 평가, 실제 응용 환경에서의 테스트 결과 등으로 보완하여 모델의 성능을 종합적으로 판단하는 것이 중요합니다.
-
트랜스포머 행동을 해석하는 기법(예: 어텐션 시각화, 특징 기여도)은 무엇입니까?
트랜스포머 모델이 특정 예측이나 출력을 생성하는 이유, 즉 모델의 내부 작동 방식을 이해하는 것은 디버깅, 신뢰도 구축, 성능 개선, 안전성 확보 등에 매우 중요합니다. 이를 위해 다음과 같은 다양한 해석 기법들이 사용됩니다.-
어텐션 시각화:
- 방식: 모델의 어텐션 계층에서 계산된 어텐션 가중치를 시각화하여, 특정 토큰이 예측을 생성할 때 입력 시퀀스의 어떤 다른 토큰들에 더 많은 '주의'를 기울였는지 살펴보는 방법입니다.
- 한계: 어텐션 가중치가 높은 것이 항상 해당 토큰의 중요도가 높다는 것을 의미하지는 않을 수 있다는 연구 결과도 있습니다.
-
특징 기여도 / 중요도 분석 (Feature Attribution / Saliency):
- 방식: 각 입력 특징(예: 특정 단어 토큰)이 모델의 최종 출력(예: 특정 예측 확률)에 얼마나 기여했는지 또는 얼마나 중요했는지를 정량적으로 측정하는 것을 목표로 합니다.
- 기법 예시: 입력에 대한 출력의 그래디언트를 활용하는 그래디언트 기반 방법(예: Integrated Gradients), 입력의 일부를 변경했을 때 출력이 얼마나 변하는지 관찰하는 섭동 기반 방법(예: LIME) 등이 있습니다.
-
내부 활성화 탐색:
- 방식: 모델 내부의 특정 뉴런이나 계층의 활성화 패턴을 분석하여, 이들이 특정 언어적 속성(예: 품사, 구문 구조), 개념, 또는 작업 관련 특징과 상관관계가 있는지 조사합니다.
- 최신 동향: 희소 오토인코더(Sparse AutoEncoders, SAEs)를 사용하여 고차원 활성화 벡터 내에서 해석 가능한 소수의 핵심 특징을 추출하려는 연구가 활발히 진행 중입니다.
-
기계적 해석 가능성:
- 방식: 모델의 가중치와 개별 구성 요소(어텐션 헤드, MLP 계층 등)가 상호작용하는 방식을 면밀히 분석하여, 모델이 특정 작업을 수행하기 위해 학습한 실제 알고리즘이나 '회로(circuit)'를 역공학(reverse-engineer)하려는 매우 야심 찬 접근 방식입니다.
-
절제 연구 (Ablation Studies):
- 방식: 모델의 일부 구성 요소(예: 특정 어텐션 헤드, 특정 계층)를 체계적으로 제거하거나 비활성화한 후, 모델의 성능 변화를 관찰하여 해당 구성 요소의 기능이나 중요도를 파악하는 방법입니다.
이러한 해석 기법들은 각각 장단점을 가지므로, 단일 방법에 의존하기보다는 여러 기법을 조합하여 사용하는 것이 모델의 행동에 대한 더 깊고 포괄적인 통찰력을 얻는 데 도움이 됩니다.
-
어텐션 시각화:
부록: 추천 학습 자료
- 트랜스포머 기본
- 고급 LLM 아키텍처 및 개념
- 고급 훈련 및 파인튜닝 기법
- 멀티모달 모델
- 이미지 생성 및 확산 모델
- 파운데이션 모델 엔지니어링 및 인프라
- 추론, 프롬프팅 및 에이전트


