Introduction
Apache Airflow is a piece of open sourced orchestration software, originally developed at Airbnb and now part of the apache software foundation, that provides functionality for authoring, monitoring, and scheduling Workflows. Some of the features available in Airflow include stateful scheduling, a rich user interface, core functionality for logging, monitoring, and alerting, and a code-based approach to authoring pipelines.
What is Apache Airflow?
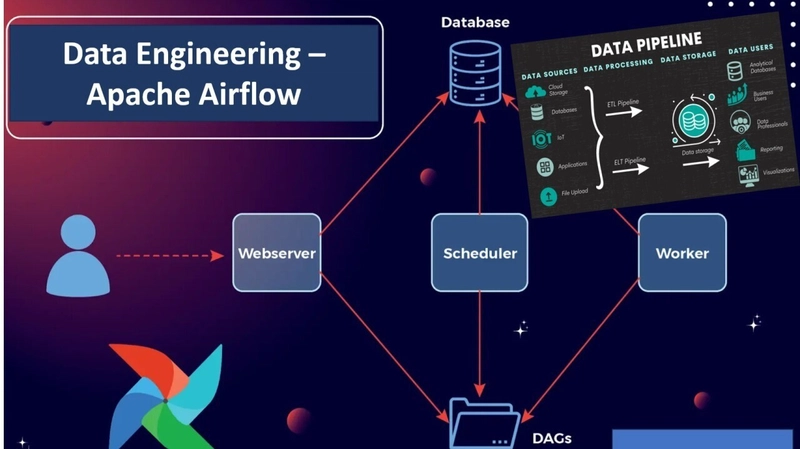
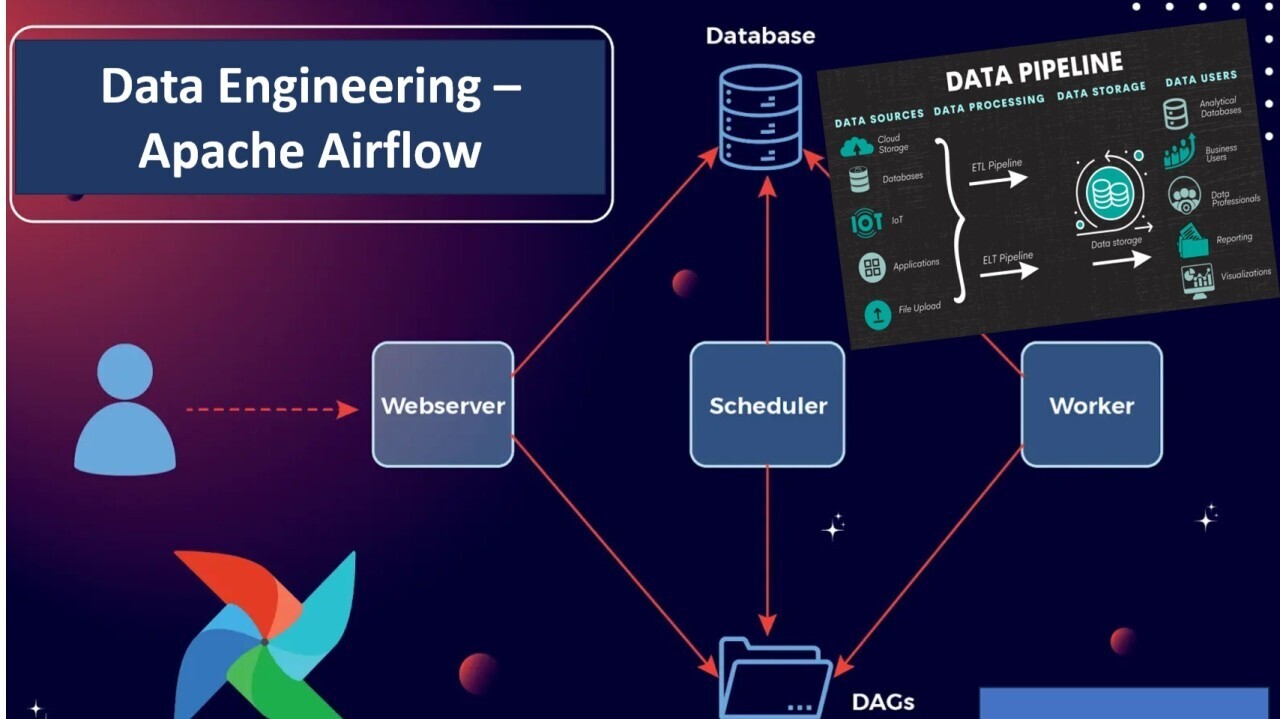
At its core, it's used for orchestrating complex data processing tasks, enabling users to define and manage workflows as code (using Python). Airflow leverages Directed Acyclic Graphs (DAGs) to represent workflows, with individual tasks within a DAG representing specific operations like data extraction, transformation, or loading
Why Use Apache Airflow in Data Engineering?
Apache Airflow is beneficial in data engineering for its robust workflow orchestration capabilities, allowing for the creation, scheduling, and monitoring of complex data pipelines. It helps automate tasks, manage dependencies, and provides a centralized platform for visualizing and debugging workflows, ultimately leading to more efficient and reliable data processing.
Here's a more detailed look at why Airflow is a valuable tool for data engineers:
- Orchestration and Scheduling: Airflow allows data engineers to define and schedule workflows as Directed Acyclic Graphs (DAGs), using Python code. This enables the orchestration of complex data pipelines, ensuring tasks are executed in the correct order and dependencies are managed effectively. Airflow provides a scheduler that can handle various scheduling intervals, from daily to hourly or weekly, simplifying the process of setting up recurring workflows.
- Automation and Scalability: Airflow automates data pipelines, reducing manual intervention and potential errors. It's highly scalable, allowing you to manage a large number of pipelines and tasks concurrently. The open-source nature of Airflow makes it readily accessible and customizable for various data engineering needs.
- Monitoring and Alerting: Airflow provides a user-friendly web interface for monitoring the progress of workflows, allowing you to visualize dependencies, logs, and task statuses. You can set up alerts to be notified of any issues or failures in your pipelines, ensuring timely intervention. This real-time monitoring helps prevent data inconsistencies and ensures downstream tasks only run when their prerequisites are met.
- Flexibility and Extensibility: Airflow's Python-based architecture allows for easy integration with various tools and libraries, making it adaptable to different data engineering environments. Its modular design enables you to extend Airflow's functionality with custom operators and plugins. Airflow supports asynchronous task execution, data-aware scheduling, and tasks that adapt to input conditions, providing flexibility in designing workflows.
- Collaboration and Documentation: Airflow's web UI facilitates collaboration among data engineers, allowing them to share and manage pipelines effectively. The Python-based DAG definitions provide clear documentation of your data pipelines, making them easier to understand and maintain.
Real-World Use Cases
Apache Airflow is commonly used for orchestrating various data pipelines, including ETL (Extract, Transform, Load) processes, machine learning workflows, and data warehousing tasks. It excels at automating and monitoring these pipelines, making them reliable and scalable. Here's a more detailed look at its real-world applications:
- ETL Pipelines:
- Data Extraction:Airflow can be used to pull data from various sources like databases, APIs, and cloud storage.
- Data Transformation:It orchestrates the steps needed to clean, validate, and transform the extracted data.
- Data Loading:Airflow loads the transformed data into data warehouses or other target systems.
- Machine Learning Workflows:
- Data Preparation:Airflow can automate tasks like data cleaning, feature engineering, and validation for machine learning models.
- Model Training:It can trigger and manage model training processes, including tasks like running experiments and tuning hyperparameters.
- Model Deployment:Airflow helps automate the deployment of trained models to various platforms.
- Data Warehousing:
- Data Updates:Airflow schedules and automates the process of updating and managing data lakes and warehouses.
- Data Refresh:It can be used to refresh data views and materialized views in data warehouses.
Best Practices for Using Apache Airflow
- Keep DAGs Lightweight: Avoid writing heavy logic directly in the DAG file. Move business logic to separate Python modules or scripts.
- Use Task Retries and Alerts: Add retries and email/Slack alerts to catch and recover from transient failures.
default_args = {
'retries': 3,
'retry_delay': timedelta(minutes=5),
'email_on_failure': True,
'email': ['[email protected]']
}- Leverage XComs for Task Communication: Use XCom (cross-communication) for small metadata passing between tasks—but avoid for large data!
- Dynamic DAGs for Scale: Generate DAGs dynamically if you have multiple similar pipelines (e.g., per customer or data source).
- Parameterize for Reusability: Use dagrun.conf or templates for passing dynamic parameters into DAGs for flexibility and reuse.
- Version Control DAGs: Keep your DAGs in Git and use CI/CD pipelines to deploy updates. This ensures reproducibility and collaboration.
- Monitor with the UI and Logs: Always check the Airflow UI to monitor execution, task duration, and inspect logs for troubleshooting.
- Use Sensors and Hooks Efficiently: Sensors wait for conditions to be met (e.g., file existence), while Hooks abstract external system connections (e.g., S3, PostgreSQL).
conclusion
Apache Airflow is a powerful ally in the data engineer’s toolkit. When used properly, it brings clarity, automation, and resilience to your data pipelines. Whether you're running simple ETL jobs or orchestrating ML workflows, following best practices and learning from real-world patterns will set you up for success.


