Let’s dive into the AWS LLM service and build a serverless AI agent with Lambda and API Gateway WebSockets
Hi People!
Bedrock is the AWS fully managed solution that offers access to AI foundation models from the most well-known companies, such as Anthropic, Cohere, DeepSeek, Meta, Mistral AI, and Amazon, in the cloud. Some of the models are also offered in the serverless mode, like Claud 3.5, which you can use directly without deploying any resources.
Instead of manually building and training the models, Bedrock offers this out of the box, making creating AI applications less complex.
You can find the code for this article under the folder bedrock in this repository.
What to expect?
We’ll be covering:
Bedrock — Cover the basic concepts, invoke and converse with foundation models, and add tool integrations.
Lambdas — We’ll use Go to write our lambdas, which will interact with Bedrock.
API Gateway — Use API Gateway with WebSockets to call our AI application and stream the results from our model.
Terraform — All our infrastructure will be provisioned using Terraform
Requirements
AWS Account
GitHub Account
Your favorite IDE/Text Editor
Basics
Let’s discuss some basic concepts regarding AWS Bedrock
Foundation Models
These AI models were already pre-trained with massive and diverse data, such as DeepSeek-R1, Claude 3.5, Claude 3.7, and others.
Each model has its specializations. For example:
Claude — Text generation, Code generation, Rich text formatting, Agentic computer use
Titan Text G1-Express — Text generation, Code generation, Instruction following
DeepSeek-R1 — Text generation, Code generation
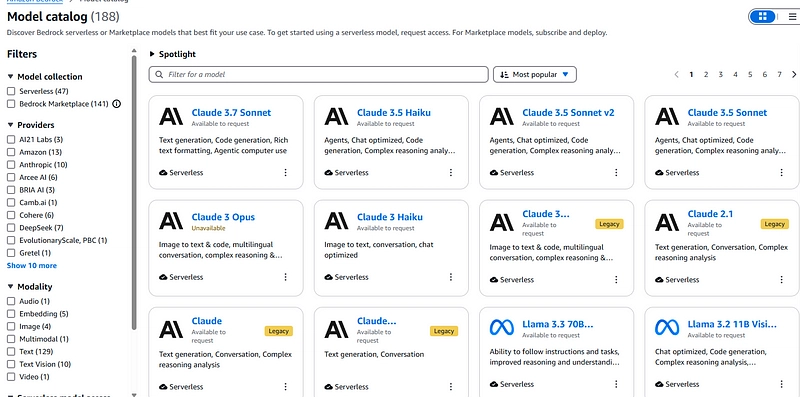
Model catalog
A marketplace-like console where you can select the desired foundation model. It has a range of models, from serverless deployment to models that AWS automatically deploys for you. Each model has its own pricing.
You can also find the pricing for each serverless model here. For the deployed models, you can click on it and the pricing should be available there.
Note that model availability depends on the region. To see the model supported for each region, you can check the documentation here.
Also, please note that some models are only available through cross-region inference. So, when calling Bedrock, you’ll pass the Inference Profile ID instead of the Model ID. And, if you are giving granular access, you’ll need to give InvokeModel access to all regions of the Inference Profile.
Agents
AI applications can interpret an input and decide which actions to take, such as calling an API. Bedrock Agents allows you to create and assign agents to action groups, connect to Lambda functions, access knowledge bases, and even call other agents.
Knowledge Base
A collection of custom data with a defined context that can be given to a foundation model or agent. Internal documentation, manuals, and custom data types can help your agent or model provide better results.
Custom model fine-tuning
It allows you to fine-tune/train a foundation model using your knowledge base (documentation, manuals, processes, …).
Prompt
This is the input or instructions to the foundation model. A good prompt can help your model return a better result.
The process of crafting instructions (prompts) to elicit the best possible output from a generative AI model, ensuring the AI understands the task and generates accurate, relevant results, is called Prompt Engineering.
Bedrock SDK
AWS SDK provides two APIs that allow us to interact with Bedrock foundation models. The InvokeModel API and the Converse API. Both offer a synchronous and a stream variant.
InvokeModel API — This was the first API to interact with Bedrock models. Its purpose is to send a prompt to the FMs and get a response from them. If you’d like to create conversations, then you need to write the conversation prompts and parameters according to the FMs specifications. You can find information about each supported model's parameters here.
Converse API — It is built on top of the
InvokeModelAPI and abstracts most of the model-specific parameters, so you can focus on quickly integrating with your desired FM.
It allows you to send documents for processing, which was not available in theInvokeModelAPI.
It also allows you to define and pass tools to the FM easily.
Please check here for the models that support theConverseAPI.
Requesting Access
In this article, we’ll focus on the serverless models, and to use them, you first need to request access through the Model Access console in Bedrock.
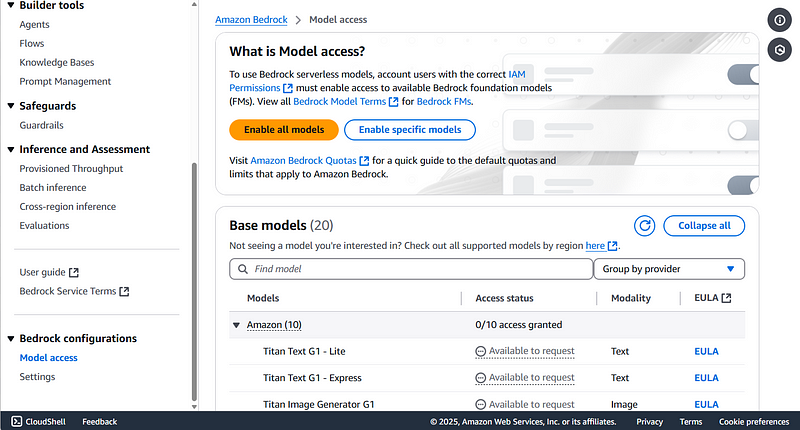
Then, you can enable access to all available or specific models.
Note that foundation model availability depends on the AWS region.
Here, I selected Titan Textg G1 — Express and Claude 3.5 Sonnet, then clicked on Next at the bottom of the page.
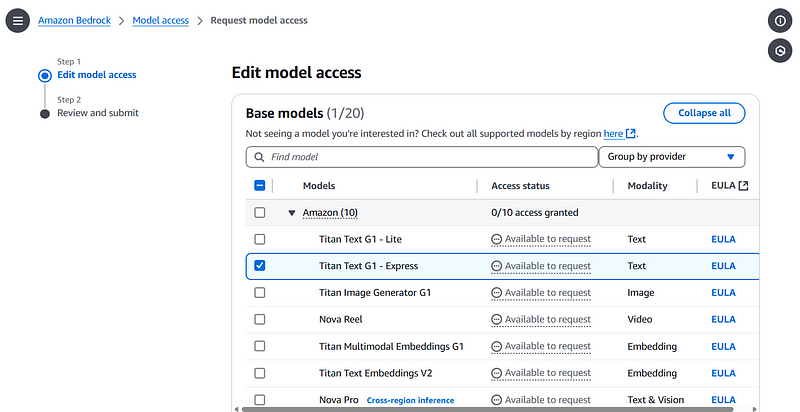
Titan Text G1 — Express selection
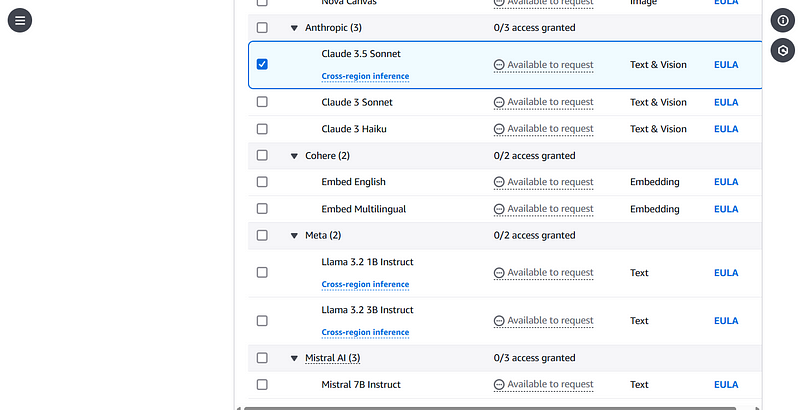
Claude 3.5 Sonnet selection
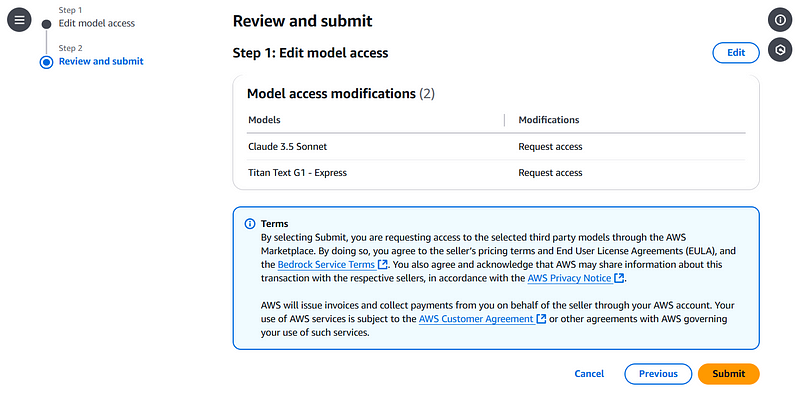
Then, you need to review the access and submit it.
Once the access is granted, you should see it as Access granted.
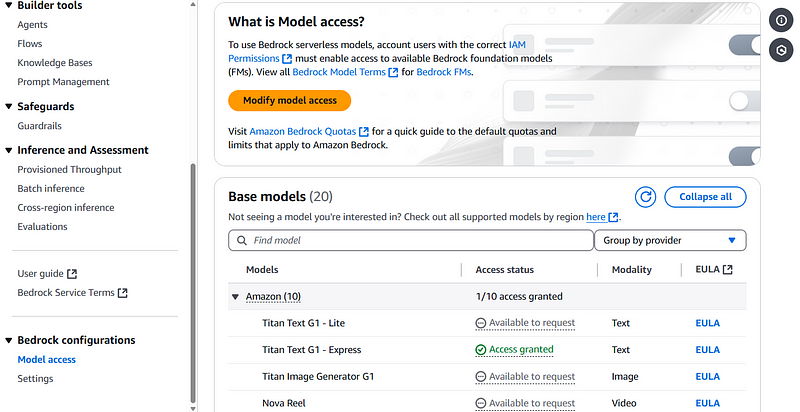
Now, we are ready to start building our application.
Getting started
Now that we've seen how to access Bedrock’s serverless foundation models, let’s start by building a Lambda that will call Bedrock for us. We’ll be building this function using Go 1.24.
In a iac folder, let’s initialize our Terraform code in a terraform.tf file:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.84"
}
}
backend "s3" {
bucket = "YOUR_BUCKET"
key = "state.tfstate"
}
}
provider "aws" {
}Don’t forget to change YOUR_BUCKET for your S3 bucket. Or remove the backend block if you don’t want to use a remote backend.
We’ll start with a simple text model from Amazon, the Titan Text G1 — Express model. If the model is not available in your region, you can pick any model of your choice, just make sure, for this first part, that it can be accessed without a cross-region inference profile. You can check here by seeing if your region has an asterisk(*) in front of it.
So, let’s get a data source for it. For that, we’ll need the Model ID, which you can find by clicking on the model in the Model Catalog:
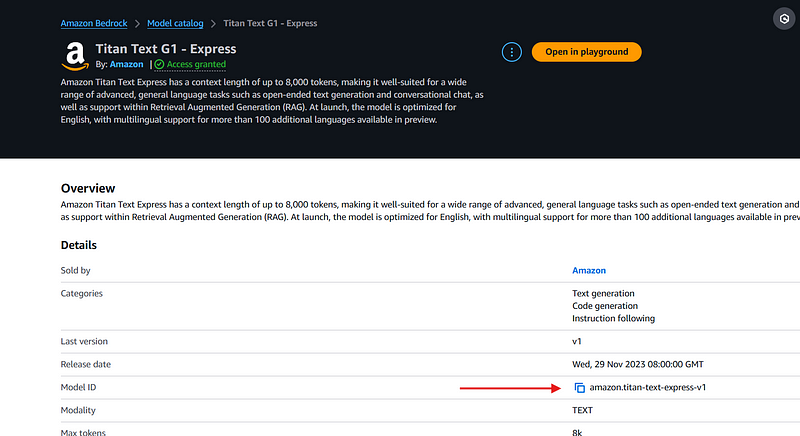
In a bedrock.tf file, let’s add a data source pointing to the model:
data "aws_bedrock_foundation_model" "model" {
model_id = "amazon.titan-text-express-v1"
}This will return the model information, or nothing, if the model doesn’t exist. We could reference the model ID directly in our lambda, but this approach is more graceful.
Let’s then create our lambda that will interact with AWS Bedrock. First, we need the lambda’s policies. In a policies.tf, add:
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
data "aws_iam_policy_document" "policies" {
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = ["arn:aws:logs:*:*:*"]
}
statement {
effect = "Allow"
actions = [
"bedrock:InvokeModel",
]
resources = [data.aws_bedrock_foundation_model.model.model_arn]
}
}Now, in a lambda.tf, let’s create our lambda function:
resource "aws_lambda_function" "bedrock" {
function_name = "bedrock"
runtime = "provided.al2023"
handler = "bootstrap"
architectures = ["arm64"]
filename = data.archive_file.file.output_path
source_code_hash = data.archive_file.file.output_base64sha256
role = aws_iam_role.role.arn
timeout = 30
environment {
variables = {
MODEL_ID = "${data.aws_bedrock_foundation_model.model.model_id}"
}
}
}
resource "aws_iam_role" "role" {
name = "bedrock-lambda-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
}
resource "aws_iam_role_policy" "policies" {
role = aws_iam_role.role.name
policy = data.aws_iam_policy_document.policies.json
}
data "archive_file" "file" {
source_file = "${path.module}/init_code/bootstrap"
output_path = "lambda_payload.zip"
type = "zip"
}Since 2024, AWS has retired the old go1.x runtime. Now, we need to use the Amazon Linux runtime, here is the provided.al2023.
Because Bedrock responses can take a bit long, it is important to increase the timeout to a reasonable value. Here we are setting it to 30 seconds, as it is also the timeout for API Gateway.
The handler is the execution file. And it needs to be named bootstrap. You can get the bootstrap file, the compiled code here, or follow the README.md instructions in the base folder to compile the code by yourself. The base code is this one:
package main
import (
"context"
"encoding/json"
"log"
"github.com/aws/aws-lambda-go/lambda"
)
type response struct {
Body string `json:"body"`
StatusCode int `json:"statusCode"`
}
type message struct {
Message string `json:"message"`
}
type handler struct{}
func (h *handler) handleRequest(ctx context.Context, event json.RawMessage) (*response, error) {
log.Printf("Received event %s", event)
body, _ := json.Marshal(message{Message: "Hello from Lambda!"})
message := &response{
Body: string(body),
StatusCode: 200,
}
return message, nil
}
func main() {
h := handler{}
lambda.Start(h.handleRequest)
}Now, we can deploy this initial infrastructure with GitHub Actions. Create a .github/workflows/deploy-infra.yml file:
name: Deploy Infra
on:
workflow_dispatch:
push:
branches:
- main
paths:
- iac/**/*
defaults:
run:
working-directory: iac
jobs:
deploy:
name: 'Deploy'
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Configure AWS Credentials Action For GitHub Actions
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: YOUR_REGION
# Install the latest version of Terraform CLI and configure the Terraform CLI configuration file with a Terraform Cloud user API token
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
# Initialize a new or existing Terraform working directory by creating initial files, loading any remote state, downloading modules, etc.
- name: Terraform Init
run: terraform init
# Checks that all Terraform configuration files adhere to a canonical format
- name: Terraform Format
run: terraform fmt -check
# Generates an execution plan for Terraform
- name: Terraform Plan
run: |
terraform plan -out=plan -input=false
# On push to "main", build or change infrastructure according to Terraform configuration files
# Note: It is recommended to set up a required "strict" status check in your repository for "Terraform Cloud". See the documentation on "strict" required status checks for more information: https://help.github.com/en/github/administering-a-repository/types-of-required-status-checks
- name: Terraform Apply
run: terraform apply -auto-approve -input=false planDon’t forget to change YOUR_REGION for your region.
Push this code to GitHub and wait for it to deploy. After it is complete, you should have your lambda in AWS. And you can test it in the Lambda console:
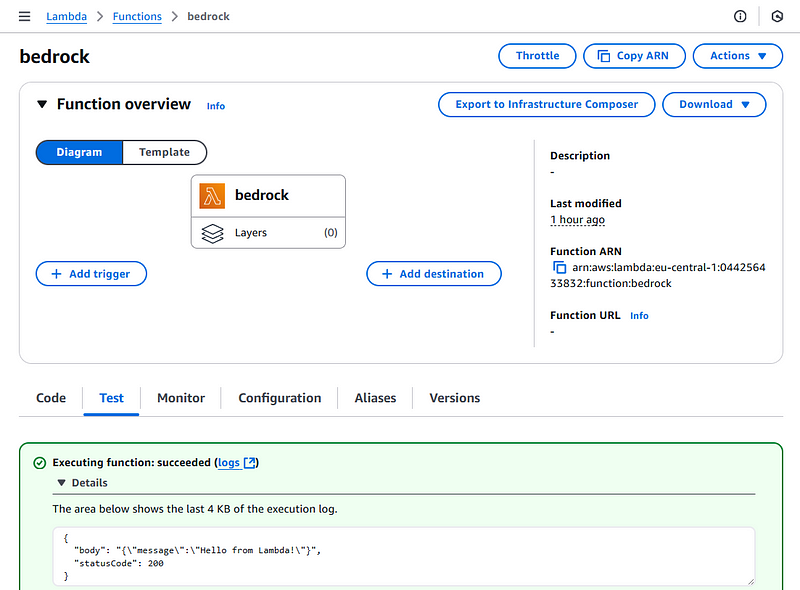
Lambda Code
Now that we have a functioning initial lambda, we can move to code the application. Let’s create an appfolder and run the following commands in it:
go mod init ai-app.com
go get github.com/aws/aws-lambda-go
go get github.com/aws/aws-sdk-go-v2
go get github.com/aws/aws-sdk-go-v2/config
go get github.com/aws/aws-sdk-go-v2/service/bedrockruntimeWe need to create the request and response models, which will be mapped from the body of the input event. In a models.go:
package main
type Request struct {
Prompt string `json:"prompt"`
}
type Response struct {
Text string `json:"text"`
}We will now create the Lambda handler. In a handler.go, we will a struct that will represent our
package main
import (
"context"
"encoding/json"
"log"
"github.com/aws/aws-lambda-go/events"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/service/bedrockruntime"
"github.com/aws/aws-sdk-go-v2/service/bedrockruntime/types"
)
type Handler struct {
bedrockClient *bedrockruntime.Client
modelID string
}In the same file, we will then create a method callBedrock, that will get the prompt and then call the Converse API:
func (h *Handler) callBedrock(prompt string, ctx *context.Context) (string, error) {
input := &bedrockruntime.ConverseInput{
ModelId: aws.String(h.modelID),
Messages: []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
},
}
response, err := h.bedrockClient.Converse(*ctx, input)
if err != nil {
log.Printf("Failed to invoke model with error %s", err.Error())
return "", err
}
outputMessage, _ := response.Output.(*types.ConverseOutputMemberMessage)
text, _ := outputMessage.Value.Content[0].(*types.ContentBlockMemberText)
return text.Value, nil
}Now, we have the HandleRequest method, which gets the context and the event that was used to invoke that lambda function, and then calls the callBedrock method:
func (h *Handler) HandleRequest(ctx context.Context, event events.APIGatewayWebsocketProxyRequest) (*events.APIGatewayProxyResponse, error) {
log.Printf("Received event %+v", event)
var request Request
err := json.Unmarshal([]byte(event.Body), &request)
if err != nil {
log.Fatal("Could not unmarshal request body")
}
response, err := h.callBedrock(request.Prompt, &ctx)
if err != nil {
log.Fatal("Failed to call bedrock")
}
responseBody, _ := json.Marshal(Response{
Text: response,
})
apiResponse := &events.APIGatewayProxyResponse{
StatusCode: 200,
Body: string(responseBody),
}
return apiResponse, nil
}To finish the handler, we add a help method to initialize it:
func NewHandler(config aws.Config) *Handler {
modelID := os.Getenv("MODEL_ID")
return &Handler{
bedrockClient: bedrockruntime.NewFromConfig(config),
modelID: modelID,
}
}And now, to start the lambda, in a main.go, we initialize our handler and pass it to the lambda.Start method:
package main
import (
"context"
"log"
"os"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go-v2/config"
)
func main() {
cfg, err := config.LoadDefaultConfig(context.Background())
if err != nil {
log.Fatal(err)
}
h := NewHandler(cfg)
lambda.Start(h.HandleRequest)
}We need to deploy it. In the .github/workflows folder, create a file deploy-lambda.yml:
name: Deploy Lambda
on:
workflow_dispatch:
push:
branches:
- main
paths:
- app/**/*
defaults:
run:
working-directory: app
jobs:
deploy:
name: 'Deploy Lambda'
runs-on: ubuntu-latest
steps:
# Checkout the repository to the GitHub Actions runner
- name: Checkout
uses: actions/checkout@v3
- uses: actions/[email protected]
with:
go-version: '1.24.1'
- name: Configure AWS Credentials Action For GitHub Actions
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: YOUR_REGION
- name: Build Lambda
run: GOOS=linux GOARCH=arm64 CGO_ENABLED=0 go build -o build/ .
# The lambda requires that the executing file be named "bootstrap"
- name: Rename file
run: mv ./build/bedrock ./build/bootstrap
- name: Zip build
run: zip -r -j main.zip ./build
- name: Update Lambda code
run: aws lambda update-function-code --function-name=bedrock --zip-file=fileb://main.zipDon’t forget to change YOUR_REGION for your region.
Now, push the code to GitHub and wait for the workflow to complete. Once it is completed, you can go to the Lambda console and send a test event with a similar structure:
{
"body": "{\"prompt\": \"What is the size of the earth?\"}"
}You should then get a response similar to:
{
"statusCode": 200,
"headers": null,
"multiValueHeaders": null,
"body": "{\"text\":\"\\nThe diameter of the Earth is 12,742 kilometers (7,917 miles).\"}"
}Conversation Flow
Now, let’s dive into message roles. You might have noticed that we assigned the types.ConversationRoleUser to our message Role. This is converted to user and is how the LLM understands that this is a prompt from the user, and an answer must be provided. We have three types of roles:
user — The user prompt. Tells the LLM that this is an input prompt. If it is the last message in the conversation, the LLM will typically interpret it as a prompt or a request for further information and will generate a response as an assistant message. Example: “Give me the weather for Lisbon.”
assistant — The LLM’s response. Example: “Now it is sunny and the temperature is 20 degrees Celsius”
system — This is the system contextual message. It provides instructions or context to the model about the task it should perform or the persona it should adopt during the conversation. Example: “You are a weather assistant. You return the weather conditions (for example: sunny, cloudy, windy), the humidity, and the temperature in Celsius.”
System prompts play an important role in your AI application. A well-written and structured prompt will improve your application performance. Some reasons are:
Contextual responses — The AI will be focused on the desired topic and will avoid deviating from it
Accuracy— With clear instructions, the AI will know which topic to stay on top of and will avoid irrelevant answers
Structured responses — You can instruct your AI to only answer in a prompt with a defined response structure. For example, if you want to generate a list of the best movies, it should return only 10 movies in bullet points. Also, the list should be ordered from best to worst rated.
Let’s add the system role in providing a better context for our AI. For this, we need to use a model that supports it. You can find all the information in the documentation here. Let’s change our model in the bedrock.tf file to use Claude 3.5. You can find the model ID in the model catalog.
data "aws_bedrock_foundation_model" "model" {
model_id = "anthropic.claude-3-5-sonnet-20240620-v1:0"
}We are going to be adding the following system prompt:
You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.In the callBedrock method, in the handler.go file, let’s add the system prompt :
func (h *Handler) callBedrock(prompt string, ctx *context.Context) (string, error) {
input := &bedrockruntime.ConverseInput{
ModelId: aws.String(h.modelID),
Messages: []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
},
System: []types.SystemContentBlock{
&types.SystemContentBlockMemberText{
Value: `You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.`,
},
},
}
response, err := h.bedrockClient.Converse(*ctx, input)
if err != nil {
log.Printf("Failed to invoke model with error %s", err.Error())
return "", err
}
outputMessage, _ := response.Output.(*types.ConverseOutputMemberMessage)
text, _ := outputMessage.Value.Content[0].(*types.ContentBlockMemberText)
return text.Value, nil
}Now, once it is deployed, you can try with a technology-related prompt, like:
{
"body": "{\"prompt\": \"What does RAM mean?\"}"
}And you should get something similar to:
{
"statusCode": 200,
"headers": null,
"multiValueHeaders": null,
"body": "{\"text\":\"Hey there! Great question about RAM. \\n\\nRAM stands for Random Access Memory. It's basically your computer's short-term memory - like a digital workspace where your computer keeps all the stuff it's actively working on.\\n\\nThink of it like your desk. When you're working on a project, you spread out all the materials you need on your desk so you can access them quickly. That's what RAM does for your computer. It holds the data and programs that are currently in use so the computer can access them super fast.\\n\\nThe more RAM you have, the more \\\"desk space\\\" your computer has to work with multiple programs or handle bigger tasks without slowing down. That's why adding more RAM can often speed up an older computer.\\n\\nWhen you turn off your computer, everything in RAM is cleared - just like clearing off your desk at the end of the day. That's why RAM is called \\\"volatile\\\" memory.\\n\\nHope that helps explain it in a simple way! Let me know if you have any other tech questions - I'm always happy to chat about this stuff.\"}"
}Notice how the response matches our system prompt. The assistant changed how the response was structured to match our system prompt.
Converse Stream API
In the previous code, we used the Converse API's synchronous version. It works well, but a better approach if you don’t necessarily need a synchronous flow is to use the API's stream version.
The ConverseStream, as well as the InvokeModelWithResponseStream, are implementations that return a stream instead of the whole result. This allows your application to have the data as soon as it is generated, unlocking many possibilities, like using the full potential of WebSockets, which is impossible with the standard API.
Let’s then update our callBedrock method in the handler.go file:
func (h *Handler) callBedrock(prompt string, ctx *context.Context) (*types.Message, error) {
input := &bedrockruntime.ConverseStreamInput{
ModelId: aws.String(h.modelID),
Messages: []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
},
System: []types.SystemContentBlock{
&types.SystemContentBlockMemberText{
Value: `You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.`,
},
},
}
response, err := h.bedrockClient.ConverseStream(*ctx, input)
if err != nil {
log.Printf("Failed to invoke model with error %s", err.Error())
return nil, err
}
outputMessage := response.GetStream().Events()
result := h.handleOutput(outputMessage)
return result, nil
}Notice that our return changed from string to *types.Message. This is because we can receive multiple content blocks in a stream response. So we create this new struct to help us get a better result. In the models.go, let’s add this new struct and update the return from our lambda:
type Response struct {
Messages []string `json:"messages"`
}Now we need to implement the handleOutput method:
func (h *Handler) handleOutput(outputMessage <-chan types.ConverseStreamOutput) *types.Message{
var result string
var msg types.Message
for event := range outputMessage {
switch e := event.(type) {
case *types.ConverseStreamOutputMemberMessageStart:
log.Print("Message start")
msg.Role = e.Value.Role
case *types.ConverseStreamOutputMemberContentBlockStart:
log.Print("Content block start")
result = ""
case *types.ConverseStreamOutputMemberContentBlockDelta:
log.Print("Content block delta")
textResponse := e.Value.Delta.(*types.ContentBlockDeltaMemberText)
result = result + textResponse.Value
case *types.ConverseStreamOutputMemberContentBlockStop:
log.Print("Content block stop")
msg.Content = append(msg.Content, &types.ContentBlockMemberText{
Value: result,
})
case *types.ConverseStreamOutputMemberMetadata:
log.Printf("Metadata %+v", e.Value)
case *types.ConverseStreamOutputMemberMessageStop:
log.Printf("Message stop. Reason: %s", e.Value.StopReason)
case *types.UnknownUnionMember:
log.Printf("unknown tag: %s", e.Tag)
default:
log.Printf("Received unexpected event type: %T", e)
}
}
return &msg
}Notice here that we receive the channel from the stream and loop through it to get the stream events as soon as they are available.
And then update the HandleRequest method to work with the new returns from callBedrock :
func (h *Handler) HandleRequest(ctx context.Context, event events.APIGatewayWebsocketProxyRequest) (*events.APIGatewayProxyResponse, error) {
log.Printf("Received event %+v", event)
var request Request
err := json.Unmarshal([]byte(event.Body), &request)
if err != nil {
log.Fatal("Could not unmarshal request body")
}
if request.Prompt == "" {
return &events.APIGatewayProxyResponse{
StatusCode: 404,
Body: "",
}, nil
}
log.Printf("Got user prompt message %s", request.Prompt)
if err != nil {
log.Fatal("Could not marshal model request body")
}
response, err := h.callBedrock(request.Prompt, &ctx, event.RequestContext.ConnectionID)
if err != nil {
log.Fatal("Failed to call bedrock")
}
var messages []string
for _, content := range response.Content {
if textContent, ok := content.(*types.ContentBlockMemberText); ok {
messages = append(messages, textContent.Value)
}
}
responseBody, _ := json.Marshal(Response{
Messages: messages,
})
apiResponse := &events.APIGatewayProxyResponse{
StatusCode: 200,
Body: string(responseBody),
}
return apiResponse, nil
}Once you deploy, you can test it in the Lambda Console. Notice that you’ll get a similar behaviour, but if you go to CloudWatch, you’ll see multiple times the log Content block delta , indicating that the message was built when the LLM returns the content, which was ready.
Adding Tools
Tools enhance the LLM's ability to provide more information for a prompt.
They can increase the response accuracy to a given context, and the LLM can then decide whether to use the tool to provide a better response.
In Bedrock, tools are only supported in the Converse API. Please also check the documentation to see if the model you are using supports it.
To provide a tool to Bedrock, you need to give the tool schema, which is a JSON with:
Name — The tool’s name (it is the value Bedrock returns and you can use to link it back to the tool you want to use)
Description — A detailed description of what the tool does. To increase accuracy, please be thorough with the tool’s capabilities and provide examples.
Properties — A list of properties with their names and descriptions. Also, be detailed with the descriptions.
Required — A list of the properties required to run this tool.
Here is an example JSON Schema:
{
"toolSpec": {
"name": "getWeather",
"description": "Get the current weather for a city or location. It returns the weather simplified with the city in the response. Examples: 'It is sunny in Berlin', 'It is raining in New York.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city or location to get the weather for. Example locations are Berlin, New York, Paris."
}
},
"required": ["location"]
}
}
}
}Let’s implement a simple tool to get the weather for a location. It will just return a static It is sunny in with the location.
Under app, create a folder tools and then a file tools.go. Here we’ll define a simple GetWeather and the tool schema:
package tools
func GetWeather(location string) string {
return "It is sunny in " + location
}
const (
ToolGetWeather = "GetWeather"
)
func GetWeatherToolSchema() map[string]interface{} {
return map[string]interface{}{
"type": "object",
"properties": map[string]interface{}{
"location": map[string]interface{}{
"type": "string",
"description": "The city or location to get the weather for. Example locations are Berlin, New York, Paris",
},
},
"required": []string{"location"},
}
}The tool schema is how we inform the LLM about how our tool works, its parameters, and their meanings.
Now we update the system prompt to let the LLM know it can get weather if the user asks. And then we also need to add the ToolConfig let the LLM know that it has access to a tool if it needs.
input := &bedrockruntime.ConverseStreamInput{
ModelId: aws.String(h.modelID),
Messages: []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
},
System: []types.SystemContentBlock{
&types.SystemContentBlockMemberText{
Value: `You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.
You are also allowed to get the current weather.`,
},
},
ToolConfig: &types.ToolConfiguration{
Tools: []types.Tool{
&types.ToolMemberToolSpec{
Value: types.ToolSpecification{
InputSchema: &types.ToolInputSchemaMemberJson{
Value: document.NewLazyDocument(tools.GetWeatherToolSchema()),
},
Name: aws.String(tools.ToolGetWeather),
Description: aws.String("Get the current weather for a city or location. It returns the weather simplified with the city in the response. Examples: 'It is sunny in Berlin', 'It is raining in New York"),
},
},
},
},
}The description is a very important property because it gives the LLM context for how it should use the tool correctly. Try to be as detailed as possible.
The flow of how the LLM uses the tool is:
The prompt is sent to Bedrock with the tool
Bedrock processes the prompt and identifies that it needs to use the tool
Stops the current block content
Starts a new content block with the Tool Use ID and the Tool Name in the
startproperty. For Golang, the block start is of typeContentBlockStartMemberToolUse.Identifies the tool inputs and passes them down as a string in the Content Block Delta in the property
input. In Golang, the delta block is of typeContentBlockDeltaMemberToolUse. In streaming mode, it passes chunks of the input.Stops the content block
Stops the message with a stop reason
tool_useThe application gets input from Bedrock's resulting message and uses the tool with the input provided by Bedrock.
The application gets the tool's result and then builds a new tool result message with the Tool Use ID and the tool result as content.
If the tool fails, the application also passes the status propertyerrorThe application appends the tool result message to the previous array of messages (the prompt message + the result messages from Bedrock's first conversation)
The application sends this new message array to Bedrock
Bedrock processes the tool result
Below you can find a simple diagram of the flow
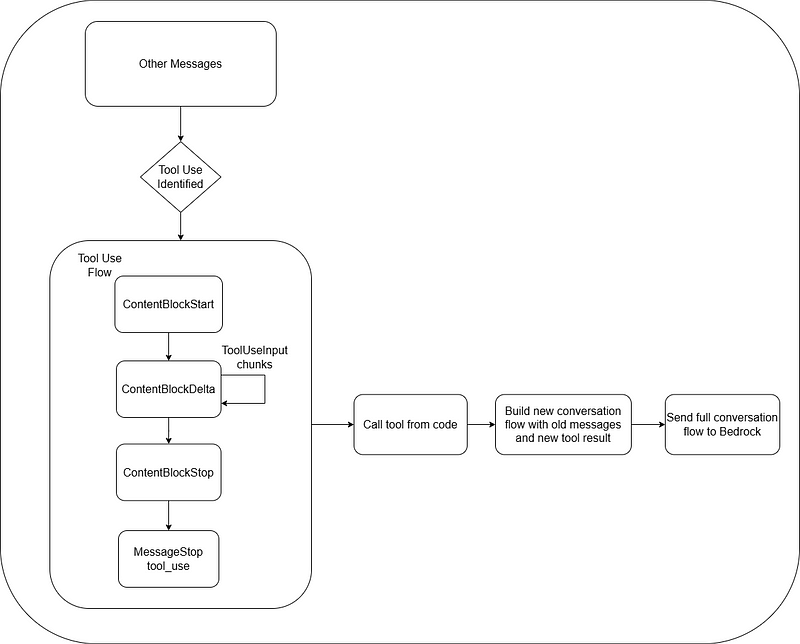
With the flow in mind, we can update the handleOutput method to enable it to identify the tool use context and build the message:
func (h *Handler) handleOutput(outputMessage <-chan types.ConverseStreamOutput, connectionID string, ctx *context.Context) (*types.Message, types.StopReason) {
var result string
var toolInput string
var stopReason types.StopReason
var msg types.Message
var toolUse types.ToolUseBlock
for event := range outputMessage {
switch e := event.(type) {
case *types.ConverseStreamOutputMemberMessageStart:
msg.Role = e.Value.Role
case *types.ConverseStreamOutputMemberContentBlockStart:
switch blockStart := e.Value.Start.(type) {
case *types.ContentBlockStartMemberToolUse:
toolUse.Name = blockStart.Value.Name
toolUse.ToolUseId = blockStart.Value.ToolUseId
}
case *types.ConverseStreamOutputMemberContentBlockDelta:
switch delta := e.Value.Delta.(type) {
case *types.ContentBlockDeltaMemberText:
result = result + delta.Value
case *types.ContentBlockDeltaMemberToolUse:
if delta.Value.Input != nil {
toolInput = toolInput + *delta.Value.Input
}
}
case *types.ConverseStreamOutputMemberContentBlockStop:
if toolInput != "" {
var toolInputMap map[string]string
if err := json.Unmarshal([]byte(toolInput), &toolInputMap); err == nil {
toolUse.Input = document.NewLazyDocument(toolInputMap)
msg.Content = append(msg.Content, &types.ContentBlockMemberToolUse{
Value: toolUse,
})
}
toolUse = types.ToolUseBlock{}
toolInput = ""
} else {
msg.Content = append(msg.Content, &types.ContentBlockMemberText{
Value: result,
})
result = ""
}
case *types.ConverseStreamOutputMemberMetadata:
log.Printf("Metadata %+v", e.Value)
case *types.ConverseStreamOutputMemberMessageStop:
stopReason = e.Value.StopReason
case *types.UnknownUnionMember:
log.Printf("unknown tag: %s", e.Tag)
default:
log.Printf("Received unexpected event type: %T", e)
}
}
return &msg, stopReason
}Now we can extract the code that builds the ConverseStreamInput, calls Bedrock, and handles the output into a streamMessages method so we can easily handle the tool calls:
func (h *Handler) streamMessages(ctx *context.Context, messages *[]types.Message, connectionID string) (*types.Message, error) {
input := &bedrockruntime.ConverseStreamInput{
ModelId: aws.String(h.modelID),
Messages: *messages,
System: []types.SystemContentBlock{
&types.SystemContentBlockMemberText{
Value: `You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.
You are also allowed to get the current weather.`,
},
},
ToolConfig: &types.ToolConfiguration{
Tools: []types.Tool{
&types.ToolMemberToolSpec{
Value: types.ToolSpecification{
InputSchema: &types.ToolInputSchemaMemberJson{
Value: document.NewLazyDocument(tools.GetWeatherToolSchema()),
},
Name: aws.String(tools.ToolGetWeather),
Description: aws.String("Get the current weather for a city or location. It returns the weather simplified with the city in the response. Examples: 'It is sunny in Berlin', 'It is raining in Curitiba"),
},
},
},
},
}
response, err := h.bedrockClient.ConverseStream(*ctx, input)
if err != nil {
log.Printf("Failed to invoke model with error %s", err.Error())
return nil, err
}
outputMessage := response.GetStream().Events()
result, stopReason := h.handleOutput(outputMessage, connectionID, ctx)
if stopReason == types.StopReasonToolUse {
*messages = append(*messages, *result)
for _, content := range result.Content {
switch block := content.(type) {
case *types.ContentBlockMemberToolUse:
if *block.Value.Name == tools.ToolGetWeather {
var params map[string]string
_ = block.Value.Input.UnmarshalSmithyDocument(¶ms)
weatherResult := tools.GetWeather(params["location"])
*messages = append(*messages, types.Message{
Role: types.ConversationRoleUser,
Content: []types.ContentBlock{
&types.ContentBlockMemberToolResult{
Value: types.ToolResultBlock{
ToolUseId: block.Value.ToolUseId,
Content: []types.ToolResultContentBlock{
&types.ToolResultContentBlockMemberText{
Value: weatherResult,
},
},
Status: types.ToolResultStatusSuccess,
},
},
},
})
}
}
}
result, err = h.StreamMessages(ctx, messages, connectionID)
}
return result, nil
}And then, update the callBedrock method:
func (h *Handler) callBedrock(prompt string, ctx *context.Context, connectionID string) (*types.Message, error) {
messages := []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
}
msg, err := h.streamMessages(ctx, &messages, connectionID)
if err != nil {
return nil, err
}
return msg, nil
}With this, you can test with a prompt that requires weather fetching, like How is the weather in New York?, and Bedrock should return the weather for you now. You can also add logging in the tool to see the flow in CloudWatch.
Cross-Region Inference
Cross-Region Inference is a method that increases the foundation model’s throughput by spreading and routing your requests to different regions during peak bursts.
The model needs to support it to be able to use it. You can find which models support it here.
Note that some models can only be accessed through cross-region inference, meaning that you cannot use the Model ID from the model catalog. Instead, use the model’s inference profile ID from the Cross-Region Inference console. An example is Claude 3.7 Sonnet, which can only be used through this method.
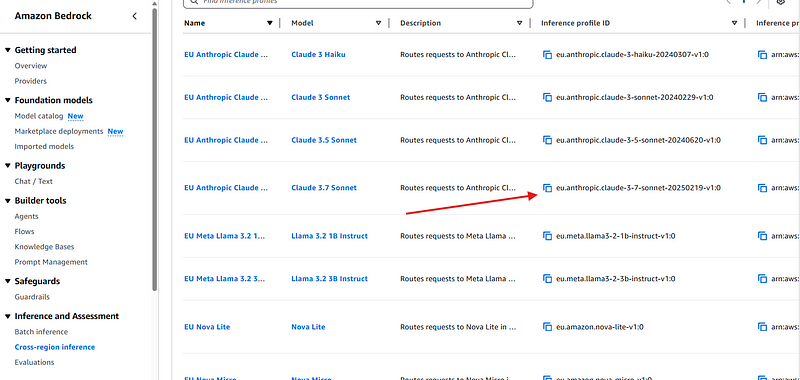
To use it, you can pass the Inference Profile ID, which is usually in the template {region}.{modelID} , for example eu.anthropic.claude-3–7-sonnet-20250219-v1:0. Also, you need to give bedrock:InvokeModel to the Inference Profile ARN and the ARN for all the regions this inference profile uses. For instance, Claude 3.7 Sonnet spams through Europe (Frankfurt), eu-north-1, Europe (Ireland), and Europe (Paris). So you need to permit like:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1743700361915",
"Action": [
"bedrock:InvokeModel"
],
"Effect": "Allow",
"Resource": [
"arn:aws:bedrock:eu-central-1:011223344556:inference-profile/eu.anthropic.claude-3-7-sonnet-20250219-v1:0",
"arn:aws:bedrock:eu-central-1::foundation-model/anthropic.claude-3-7-sonnet-20250219-v1:0",
"arn:aws:bedrock:eu-north-1::foundation-model/anthropic.claude-3-7-sonnet-20250219-v1:0",
"arn:aws:bedrock:eu-west-1::foundation-model/anthropic.claude-3-7-sonnet-20250219-v1:0",
"arn:aws:bedrock:eu-west-3::foundation-model/anthropic.claude-3-7-sonnet-20250219-v1:0"
]
}
]
}Or you can give it access to all regions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1743700361915",
"Action": [
"bedrock:InvokeModel"
],
"Effect": "Allow",
"Resource": [
"arn:aws:bedrock:eu-central-1:011223344556:inference-profile/eu.anthropic.claude-3-7-sonnet-20250219-v1:0",
"arn:aws:bedrock:*::foundation-model/anthropic.claude-3-7-sonnet-20250219-v1:0"
]
}
]
}You can find out about the supported models here. They are the ones marked with a *.
Integrating with a WebSocket API
Let’s integrate our app with API Gateway WebSockets.
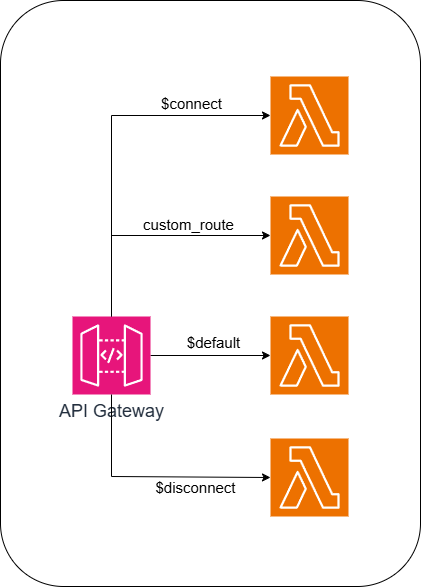
API Gateway WebSockets have four types of routes:
$connect — When a new client connects to the websocket
$disconnect — When a client disconnects from the websockets
$default — When no routes match or we have no routes defined
custom_route — Custom routes that are defined in the API Gateway. Example: user, product,…
For this example, we don’t necessarily need the $connect and $disconnect routes. A use case for these routes would be if you needed to save the ConnectionID to the database to send a message to it through the websocket from another service. But, if the user sends the message through the WebSocket directly, as we’ll do, then API Gateway automatically sends the ConnectionID in the request context.
Let’s create a new API Gateway WebSockets with the $default route. In the iac folder, create a new file api_websocket.tf :
resource "aws_apigatewayv2_api" "api" {
name = "bedrock"
protocol_type = "WEBSOCKET"
route_selection_expression = "$request.body.action"
}
resource "aws_apigatewayv2_stage" "stage" {
api_id = aws_apigatewayv2_api.api.id
name = "live"
auto_deploy = true
}
resource "aws_apigatewayv2_route" "default" {
api_id = aws_apigatewayv2_api.api.id
route_key = "$default"
target = "integrations/${aws_apigatewayv2_integration.default.id}"
}
resource "aws_apigatewayv2_integration" "default" {
api_id = aws_apigatewayv2_api.api.id
integration_type = "AWS_PROXY"
connection_type = "INTERNET"
content_handling_strategy = "CONVERT_TO_TEXT"
description = "Default Websocket route"
integration_method = "POST"
integration_uri = aws_lambda_function.bedrock.invoke_arn
passthrough_behavior = "WHEN_NO_MATCH"
}
resource "aws_lambda_permission" "bedrock" {
statement_id = "AllowDefaultExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.bedrock.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.api.execution_arn}/*/${aws_apigatewayv2_route.default.route_key}"
}To send messages to the WebSocket from the Lambda function, we need to let it know where to send the messages. For that, we just need to add the API Gateway https invoke URL to our Lambda. In the lambda.tf file, let’s add it as an environment variable:
resource "aws_lambda_function" "bedrock" {
function_name = "bedrock"
runtime = "provided.al2023"
handler = "bootstrap"
architectures = ["arm64"]
filename = data.archive_file.file.output_path
source_code_hash = data.archive_file.file.output_base64sha256
role = aws_iam_role.role.arn
timeout = 30
environment {
variables = {
MODEL_ID = "${data.aws_bedrock_foundation_model.model.model_id}"
API_GATEWAY_ENDPOINT = "${replace(aws_apigatewayv2_stage.stage.invoke_url, "wss", "https")}"
}
}
}Note that we are replacing wss for https . That is because the invoke_url is the WebSocket address to the active stage.
The lambda role now needs permission to access the /POST/@connections/{connectionId} endpoint in API Gateway. Let’s add this permission to the policies.tf file, in the aws_iam_policydocument polices resource, add the following statement:
statement {
effect = "Allow"
actions = [
"execute-api:ManageConnections"
]
resources = [
"${aws_apigatewayv2_stage.stage.execution_arn}/POST/@connections/{connectionId}"
]
}Great! The API Gateway WebSocket is ready. We now need to update our Lambda code to send messages to the connected client.
In the app folder, run the following command to get the ApiGatewayManagementAPI package:
go get "github.com/aws/aws-sdk-go-v2/service/apigatewaymanagementapi"In the models.go , let’s add a new model for our message to the WebSocket and some helpful constants:
type WebSocketMessage struct {
Event string `json:"event"`
Data string `json:"data"`
}
const (
BedrockEventContent string = "content"
BedrockEventMessageStart string = "message_start"
BedrockEventMessageStop string = "message_stop"
BedrockEventContentStart string = "content_start"
BedrockEventContentStop string = "content_stop"
BedrockEventMetadata string = "metadata"
)These constants help the client understand when a new message starts and ends so it can react accordingly.
Now, in the handler.go file, let’s first update the Handler struct to add the API Gateway Management Client:
type Handler struct {
bedrockClient *bedrockruntime.Client
modelID string
apiGatewayManagementClient *apigatewaymanagementapi.Client
}Let’s update the NewHandler function to get the API_GATEWAY_ENDPOINT environment variable and initialize an instance of apigatewaymanagementapi.Client :
func NewHandler(config aws.Config) *Handler {
modelID := os.Getenv("MODEL_ID")
apiGatewayEndpoint := os.Getenv("API_GATEWAY_ENDPOINT")
return &Handler{
bedrockClient: bedrockruntime.NewFromConfig(config),
modelID: modelID,
apiGatewayManagementClient: apigatewaymanagementapi.NewFromConfig(config, func(o *apigatewaymanagementapi.Options) {
o.BaseEndpoint = &apiGatewayEndpoint
}),
}
}Let’s now create a new function to send messages to the WebSocket:
func (h *Handler) SendWebSocketMessageToConnection(ctx *context.Context, textResponse string, event string, connectionID string) {
data, _ := json.Marshal(WebSocketMessage{Event: event, Data: textResponse})
websocketInput := &apigatewaymanagementapi.PostToConnectionInput{
ConnectionId: aws.String(connectionID),
Data: []byte(data),
}
response, err := h.apiGatewayManagementClient.PostToConnection(*ctx, websocketInput)
if err != nil {
log.Printf("ERROR %+v", err)
}
}We now need to use it in the handleOutput method:
func (h *Handler) handleOutput(outputMessage <-chan types.ConverseStreamOutput, connectionID string, ctx *context.Context) (*types.Message, types.StopReason) {
var result string
var toolInput string
var stopReason types.StopReason
var msg types.Message
var toolUse types.ToolUseBlock
for event := range outputMessage {
switch e := event.(type) {
case *types.ConverseStreamOutputMemberMessageStart:
h.SendWebSocketMessageToConnection(ctx, "", BedrockEventMessageStart, connectionID)
msg.Role = e.Value.Role
case *types.ConverseStreamOutputMemberContentBlockStart:
switch blockStart := e.Value.Start.(type) {
case *types.ContentBlockStartMemberToolUse:
toolUse.Name = blockStart.Value.Name
toolUse.ToolUseId = blockStart.Value.ToolUseId
default:
h.SendWebSocketMessageToConnection(ctx, "", BedrockEventContentStart, connectionID)
}
case *types.ConverseStreamOutputMemberContentBlockDelta:
switch delta := e.Value.Delta.(type) {
case *types.ContentBlockDeltaMemberText:
h.SendWebSocketMessageToConnection(ctx, delta.Value, BedrockEventContent, connectionID)
result = result + delta.Value
case *types.ContentBlockDeltaMemberToolUse:
if delta.Value.Input != nil {
toolInput = toolInput + *delta.Value.Input
}
}
case *types.ConverseStreamOutputMemberContentBlockStop:
if toolInput != "" {
var toolInputMap map[string]string
if err := json.Unmarshal([]byte(toolInput), &toolInputMap); err == nil {
toolUse.Input = document.NewLazyDocument(toolInputMap)
msg.Content = append(msg.Content, &types.ContentBlockMemberToolUse{
Value: toolUse,
})
}
toolUse = types.ToolUseBlock{}
toolInput = ""
} else {
h.SendWebSocketMessageToConnection(ctx, "", BedrockEventContentStop, connectionID)
msg.Content = append(msg.Content, &types.ContentBlockMemberText{
Value: result,
})
result = ""
}
case *types.ConverseStreamOutputMemberMetadata:
h.SendWebSocketMessageToConnection(ctx, fmt.Sprintf("%+v", e.Value), BedrockEventMetadata, connectionID)
case *types.ConverseStreamOutputMemberMessageStop:
stopReason = e.Value.StopReason
h.SendWebSocketMessageToConnection(ctx, string(e.Value.StopReason), BedrockEventMessageStop, connectionID)
case *types.UnknownUnionMember:
log.Printf("unknown tag: %s", e.Tag)
default:
log.Printf("Received unexpected event type: %T", e)
}
}
return &msg, stopReason
}We need to then update the streamMessages method to receive and pass the connectionID :
func (h *Handler) StreamMessages(ctx *context.Context, messages *[]types.Message, connectionID string) (*types.Message, error) {
input := &bedrockruntime.ConverseStreamInput{
ModelId: aws.String(h.modelID),
Messages: *messages,
System: []types.SystemContentBlock{
&types.SystemContentBlockMemberText{
Value: `You are a technology expert named Tony.
You answer technology related questions in a friendly and casual tone.
You break down complex topics into easy-to-understand explanations.
It's ok to not know the answer, but try your best to point to where the user might find more information about the topic.
You are also allowed to get the current weather.`,
},
},
ToolConfig: &types.ToolConfiguration{
Tools: []types.Tool{
&types.ToolMemberToolSpec{
Value: types.ToolSpecification{
InputSchema: &types.ToolInputSchemaMemberJson{
Value: document.NewLazyDocument(tools.GetWeatherToolSchema()),
},
Name: aws.String(tools.ToolGetWeather),
Description: aws.String("Get the current weather for a city or location. It returns the weather simplified with the city in the response. Examples: 'It is sunny in Berlin', 'It is raining in Curitiba"),
},
},
},
},
}
response, err := h.bedrockClient.ConverseStream(*ctx, input)
if err != nil {
log.Printf("Failed to invoke model with error %s", err.Error())
return nil, err
}
outputMessage := response.GetStream().Events()
result, stopReason := h.handleOutput(outputMessage, connectionID, ctx)
if stopReason == types.StopReasonToolUse {
*messages = append(*messages, *result)
for _, content := range result.Content {
switch block := content.(type) {
case *types.ContentBlockMemberToolUse:
if *block.Value.Name == tools.ToolGetWeather {
var params map[string]string
_ = block.Value.Input.UnmarshalSmithyDocument(¶ms)
log.Printf("Got inputs %s from tool", params["location"])
weatherResult := tools.GetWeather(params["location"])
*messages = append(*messages, types.Message{
Role: types.ConversationRoleUser,
Content: []types.ContentBlock{
&types.ContentBlockMemberToolResult{
Value: types.ToolResultBlock{
ToolUseId: block.Value.ToolUseId,
Content: []types.ToolResultContentBlock{
&types.ToolResultContentBlockMemberText{
Value: weatherResult,
},
},
Status: types.ToolResultStatusSuccess,
},
},
},
})
}
}
}
result, err = h.StreamMessages(ctx, messages, connectionID)
}
return result, nil
}Update the callBedrock method:
func (h *Handler) callBedrock(prompt string, ctx *context.Context, connectionID string) (*types.Message, error) {
messages := []types.Message{
{
Content: []types.ContentBlock{
&types.ContentBlockMemberText{
Value: prompt,
},
},
Role: types.ConversationRoleUser,
},
}
msg, err := h.streamMessages(ctx, &messages, connectionID)
if err != nil {
return nil, err
}
return msg, nil
}And then the HandleRequest function to extract the ConnectionID from the request context:
func (h *Handler) HandleRequest(ctx context.Context, event events.APIGatewayWebsocketProxyRequest) (*events.APIGatewayProxyResponse, error) {
var request Request
err := json.Unmarshal([]byte(event.Body), &request)
if err != nil {
log.Fatal("Could not unmarshal request body")
}
response, err := h.callBedrock(request.Prompt, &ctx, event.RequestContext.ConnectionID)
if err != nil {
log.Fatal("Failed to call bedrock")
}
var messages []string
for _, content := range response.Content {
if textContent, ok := content.(*types.ContentBlockMemberText); ok {
messages = append(messages, textContent.Value)
}
}
responseBody, _ := json.Marshal(Response{
Messages: messages,
})
apiResponse := &events.APIGatewayProxyResponse{
StatusCode: 200,
Body: string(responseBody),
}
return apiResponse, nil
}After you deploy it, we can test it using wscat tool in the terminal. Open the terminal and run the following command:
npm install -g wscatYou now need the WebSocket URL. You can find it in the API stage’s console:
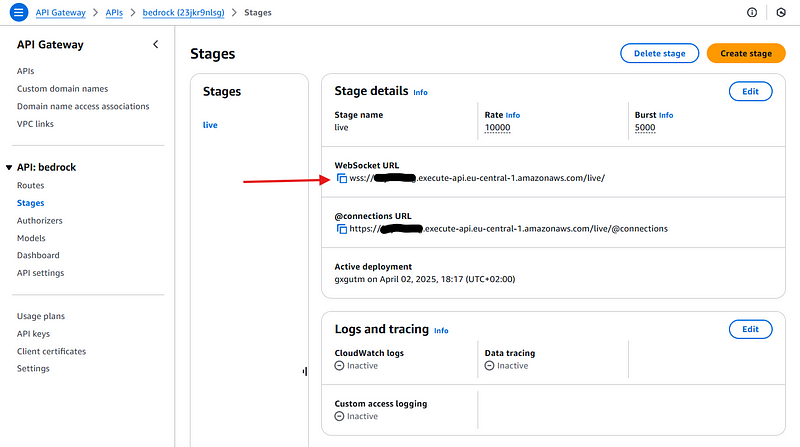
You can copy it and use it in the following terminal command:
wscat -c WEBSOCKET_URLWhere WEBSOCKET_URL is the URL you got from the AWS Console. Once connected, you can send messages, and they should go to our Lambda in the $default route. So, try sending something like:
{ "prompt": "Hey!" }You should see something similar to the example below:
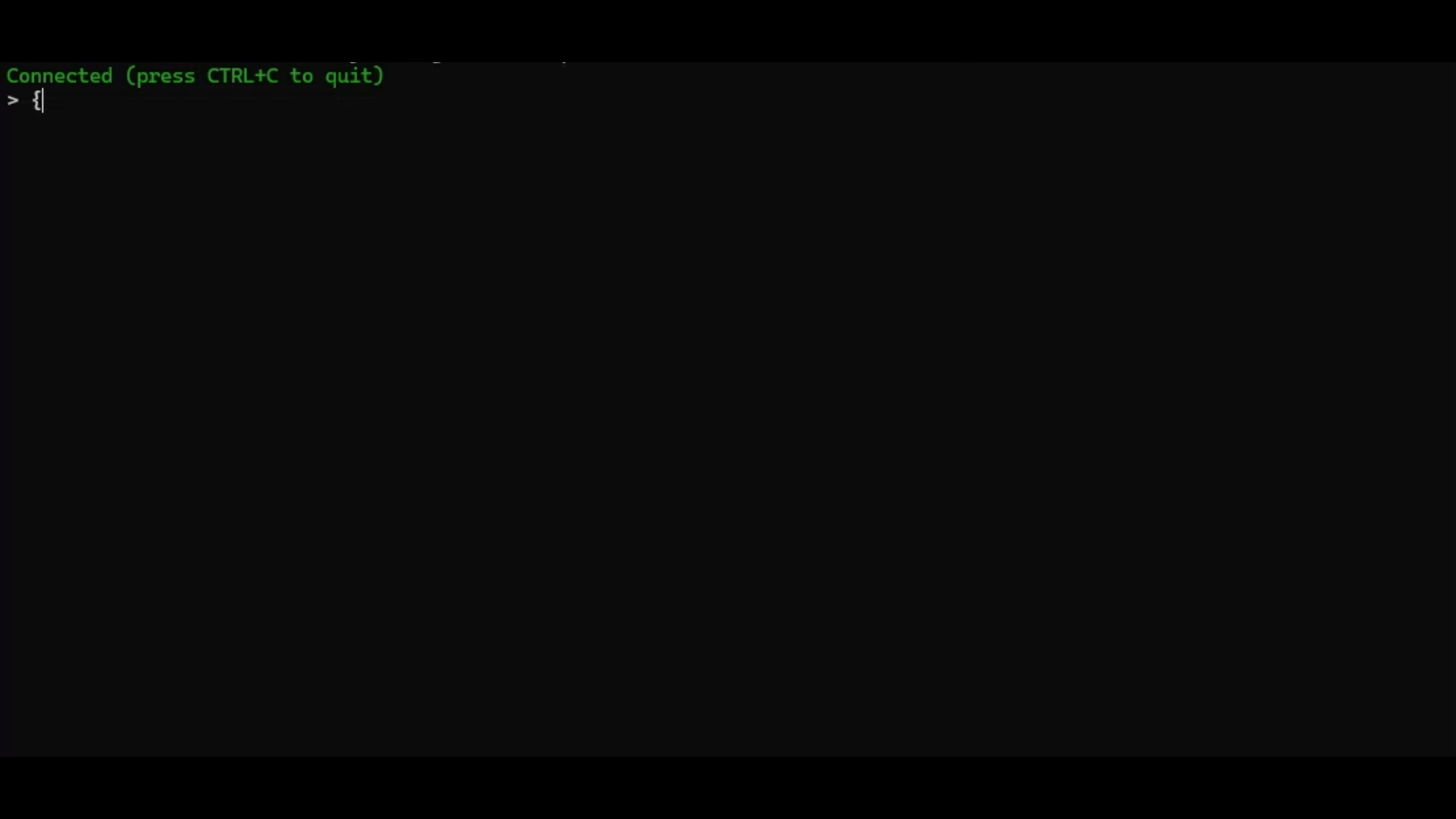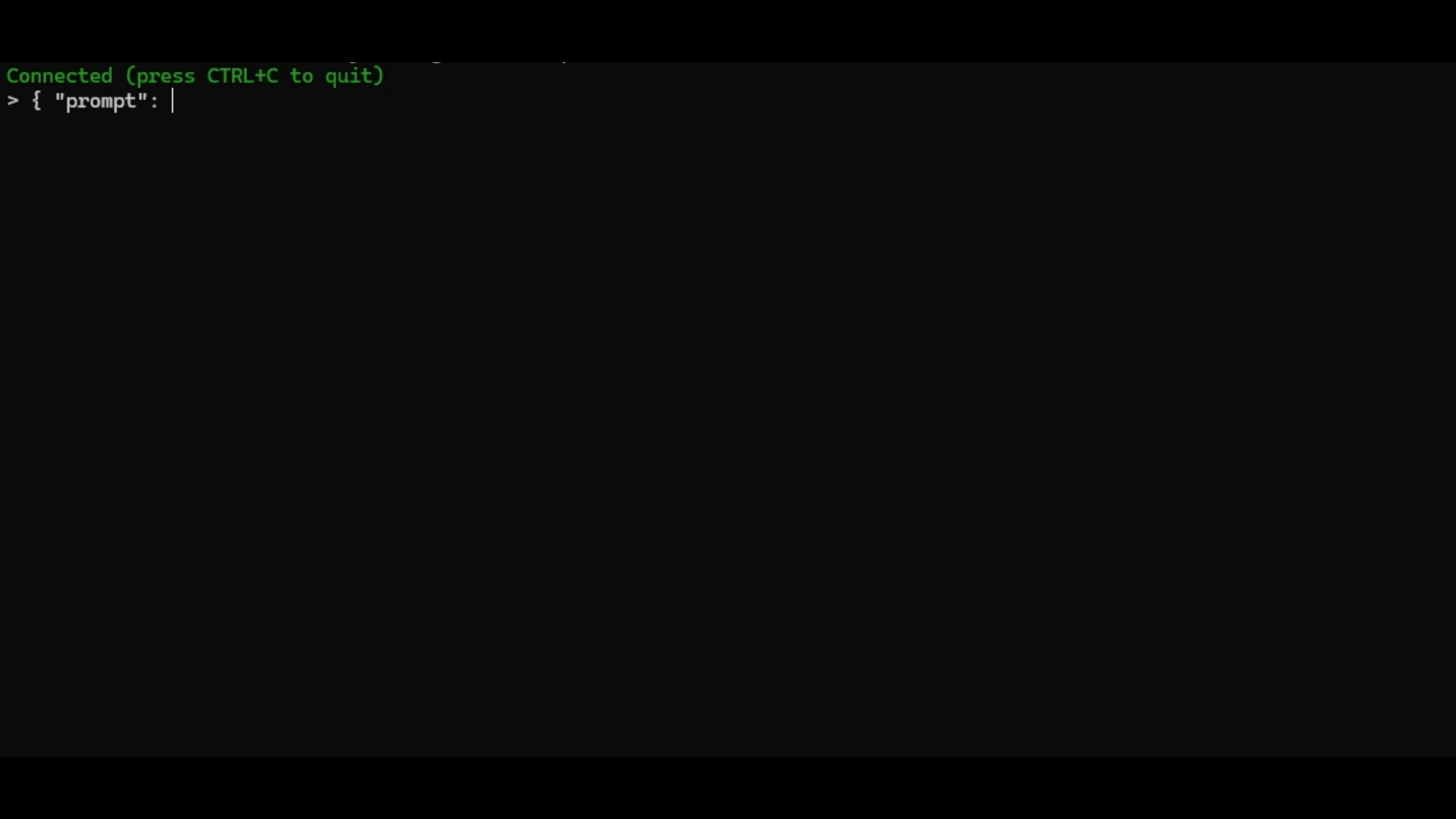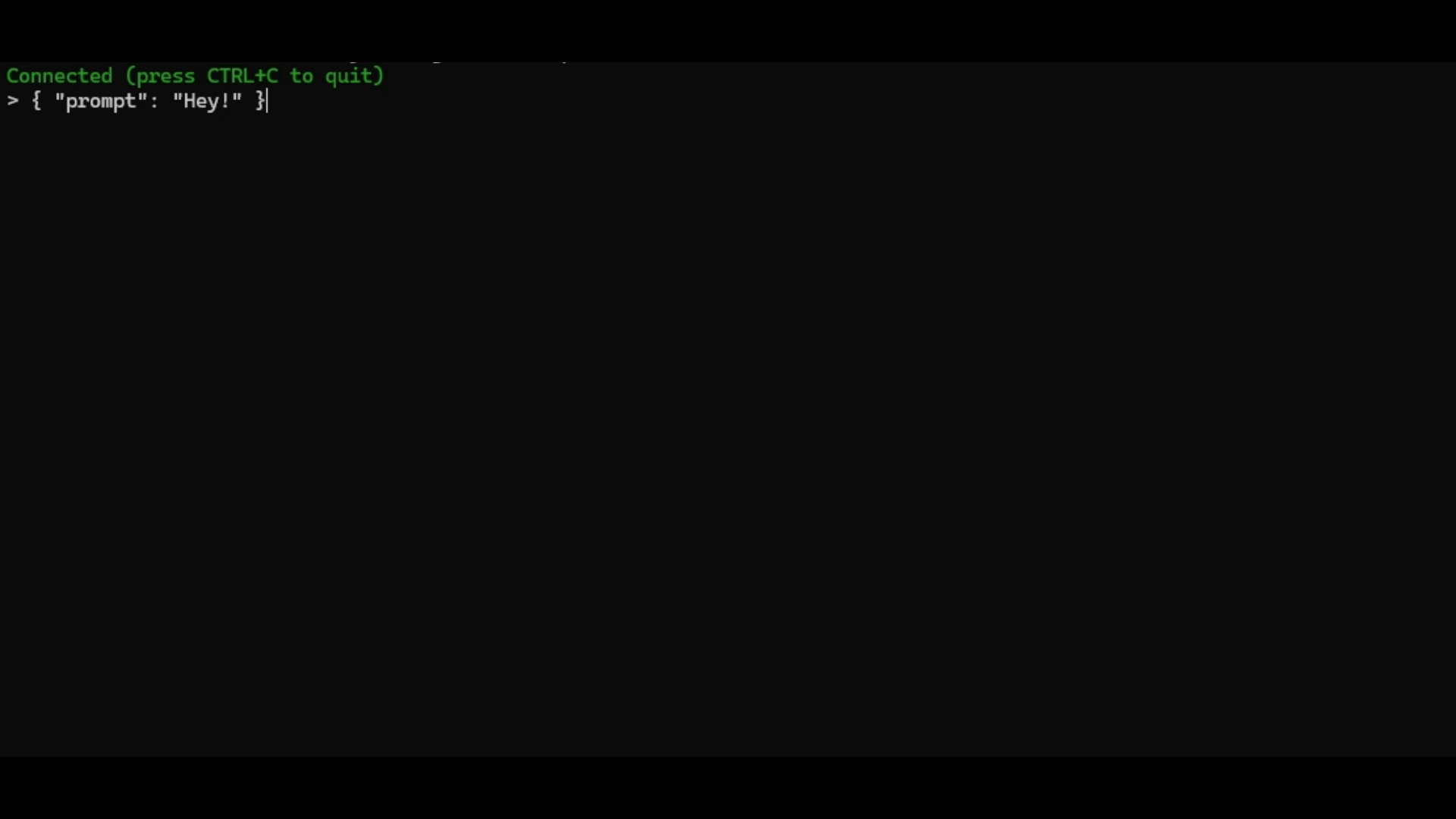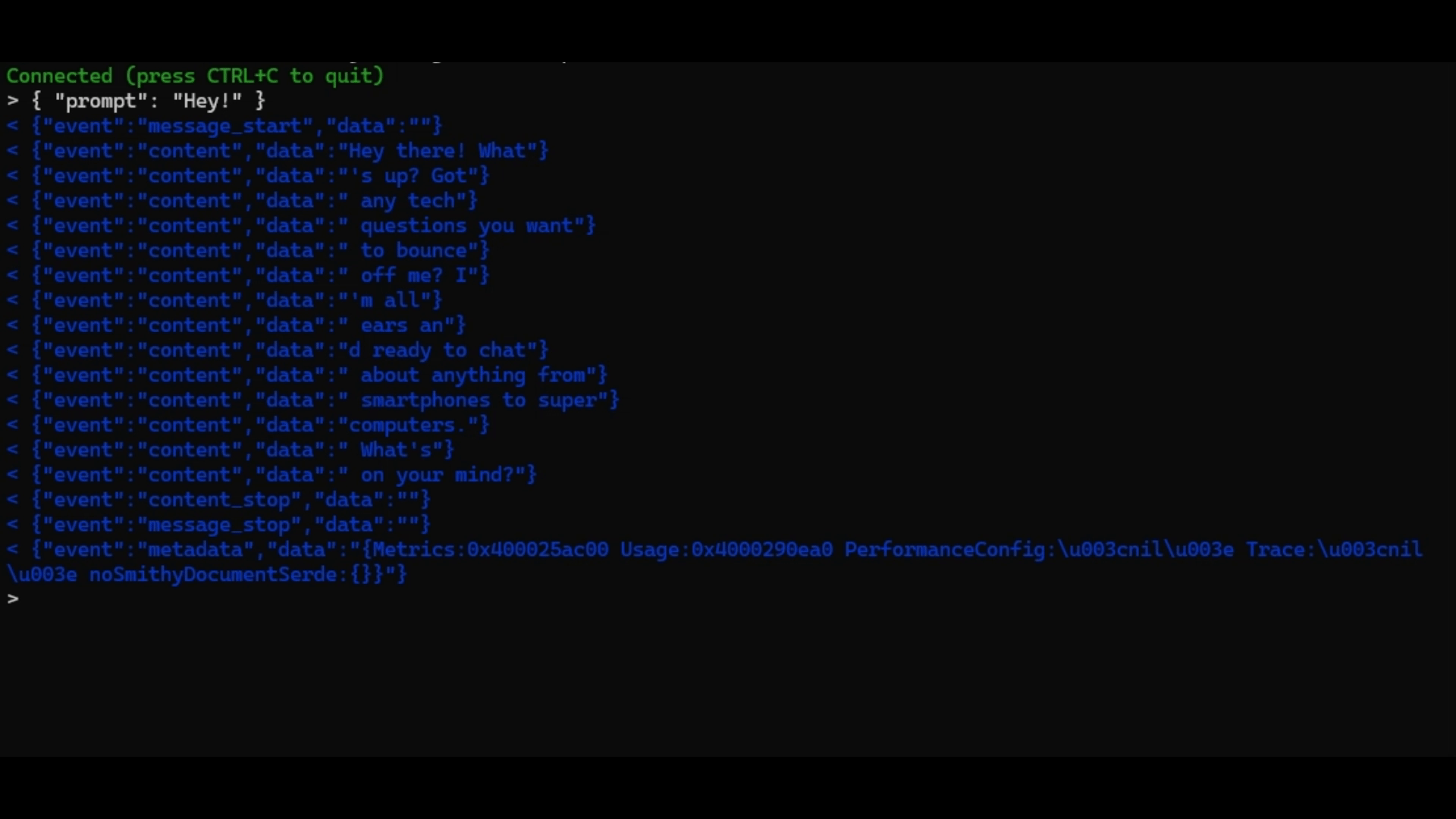
And with the tool:
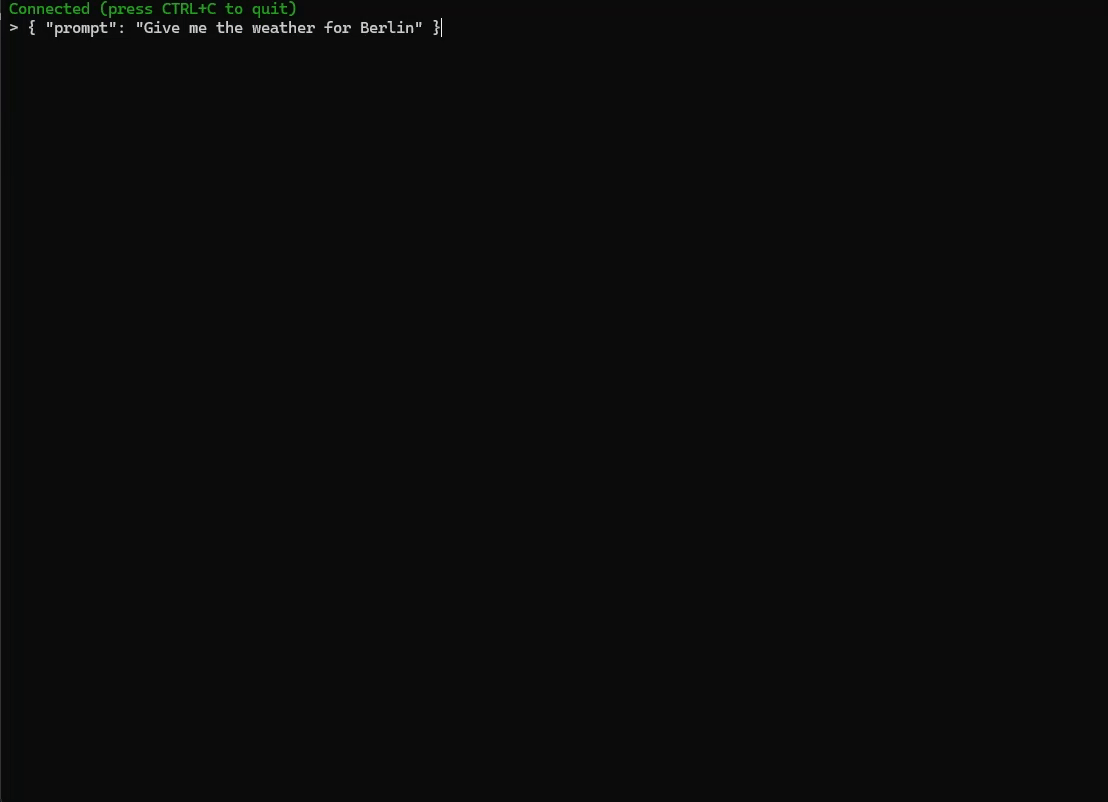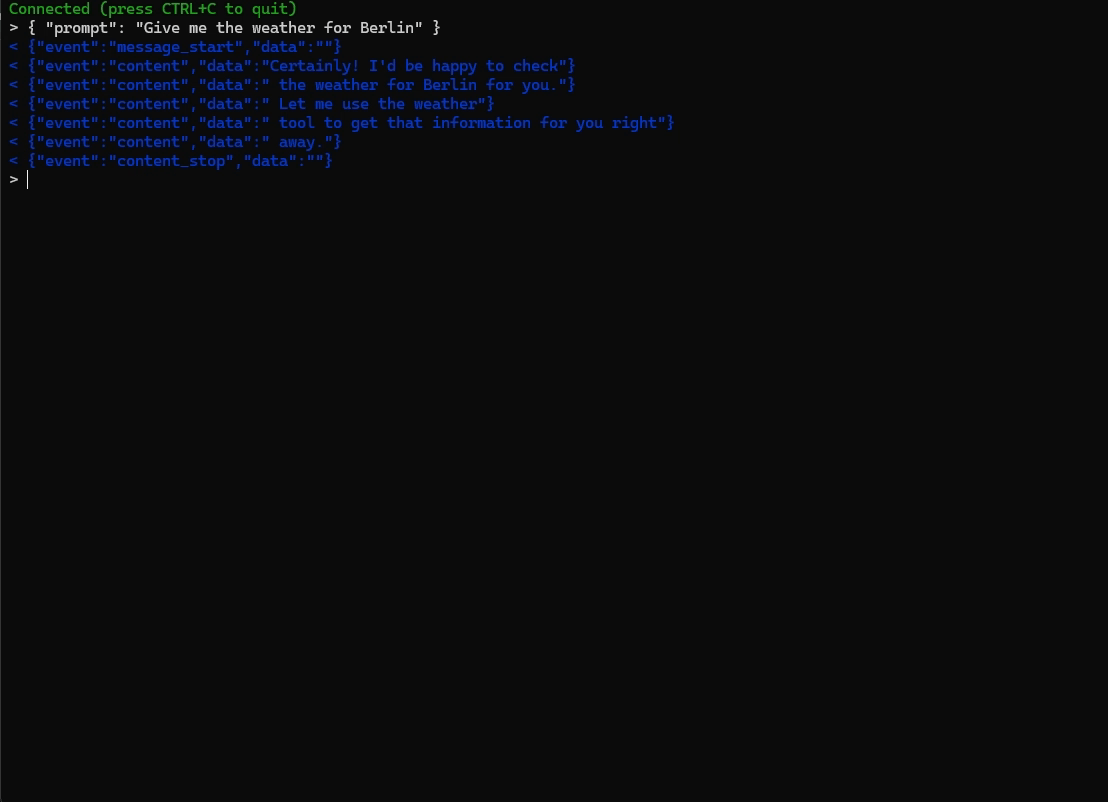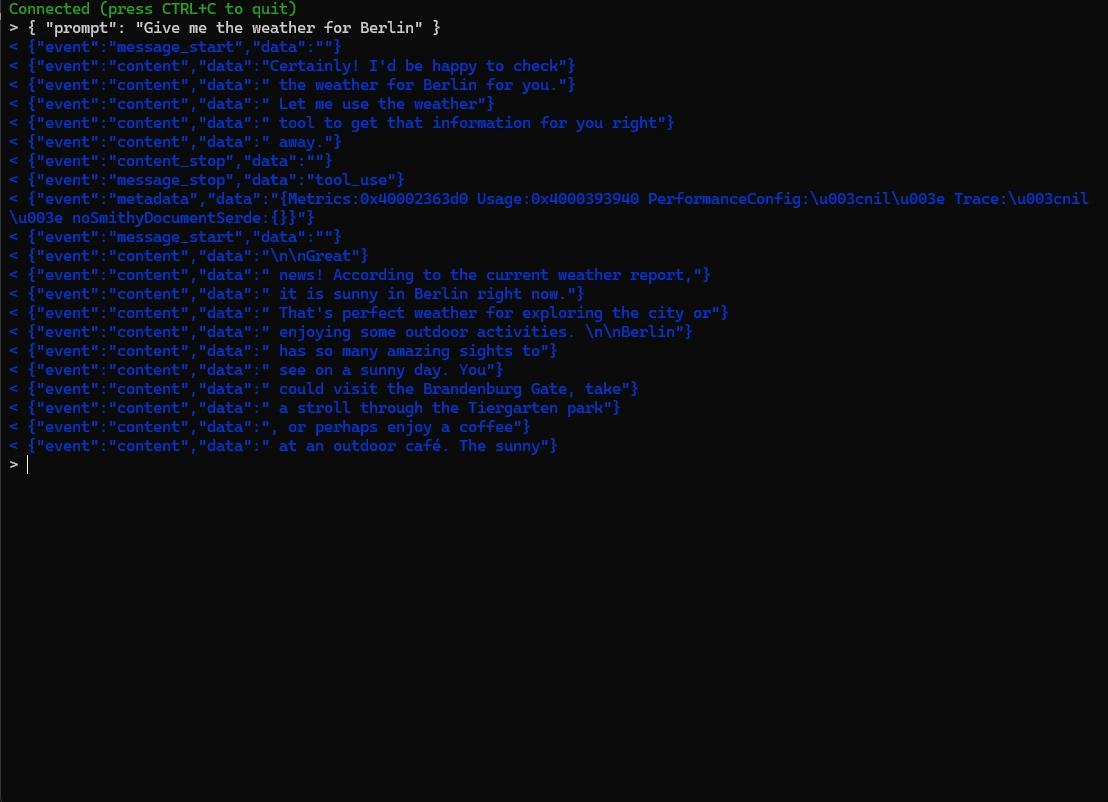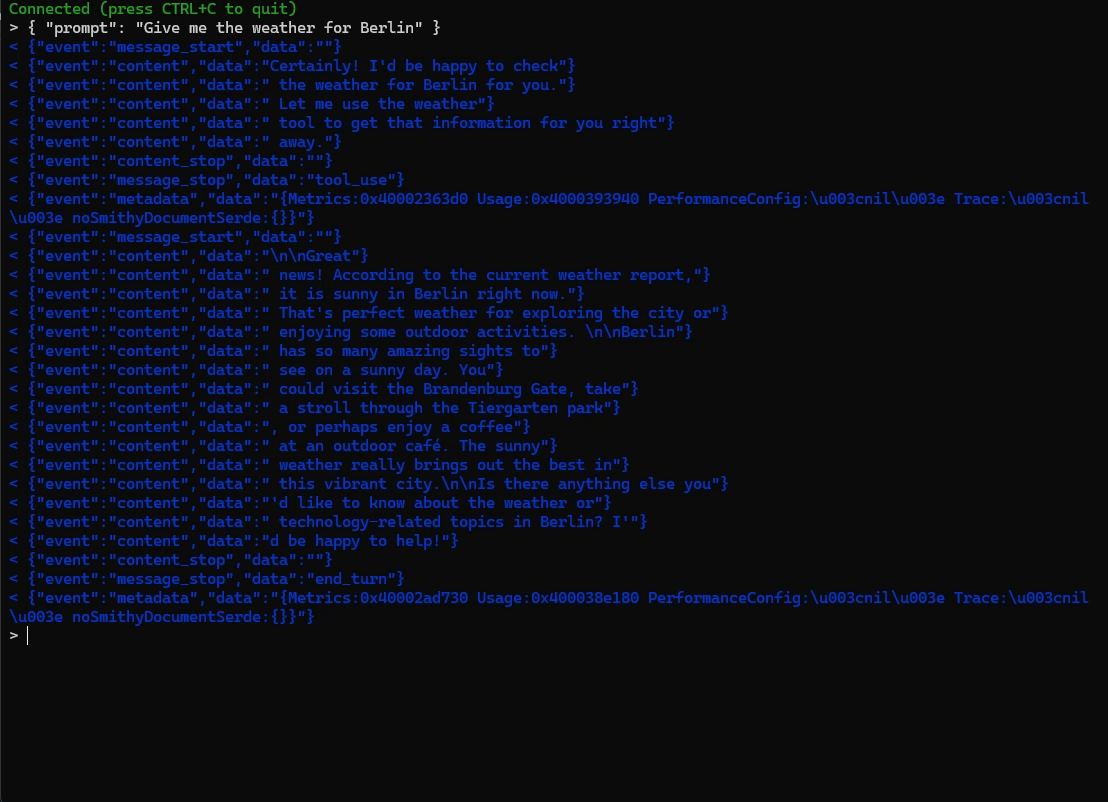
Conclusion
What a journey!
In this article, we learned and worked with the fantastic Bedrock, the AWS LLM service. It facilitates deploying and using the most well-known foundation models and provides serverless solutions for some models.
In addition to the basics and foundations of Bedrock, we also saw how we can easily integrate it with a serverless application using Lambda functions and API Gateway WebSockets.
We also had AI tools, which enriched the LLM’s power to give better and targeted results by providing functions that the model can use for the prompt context.
We wrote all the logic code using Golang, a simple, easy, and fast programming language.
Lastly, we used the power of Terraform to provide and manage our entire infrastructure.
Hope you enjoy it!
Happy coding 💻


