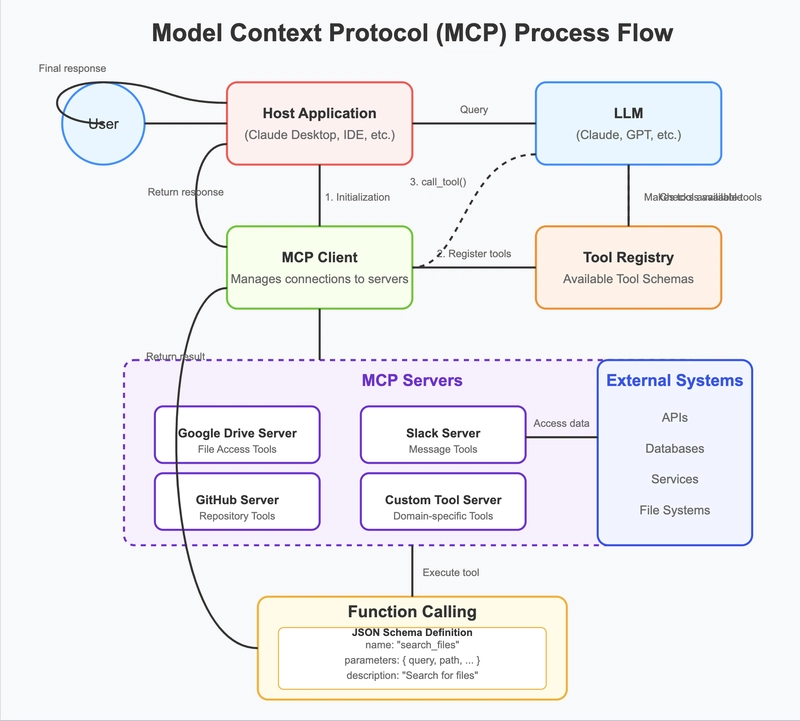
前回の投稿では、モデルコンテキストプロトコル(MCP)を使用して、LLMクライアントがAWSアカウント内のAmazon Interactive Video Service(Amazon IVS)リソースに直接アクセスできるツールを公開するカスタムサーバーを構築しました。このサーバーは、CloudWatch 経由で Amazon IVS リソースのヘルスデータとメトリクスデータを取得する機能も備えています。これにより、環境に関する詳細な情報を取得し、カスタムクエリを実行できるようになり、Amazon IVS リソース管理の体験を大幅に改良されています。
リソースに関する情報を持つ MCP サーバーは素晴らしいものですが、Amazon IVS というサービスに関するドキュメントやコンテキスト知識を与えることで、このサーバーをさらに強力にすることができます。この記事では、その知識と他の便利な機能を追加するために、MCP サーバーにいくつかの追加ツールを加えていきます。ご心配なく、MCP クライアントの構築も後ほど行います。今のところは、クライアントが素晴らしい Amazon IVS プロトタイプとデモを構築するのに必要なすべてのツールを持てるように、このサーバーを強化していきましょう。
MCP サーバーに RAG サポートを追加する
MCP の人気の高まりが Retrieval Augmented Generation(RAG)の終焉を意味するのではとと考える人もいます。しかし、これは真実からはほど遠いものです。MCP と同様に、RAG は LLM が通常アクセスできないドメイン固有データを提供する貴重なツールです。IVS MCP サーバーに RAG 機能を追加するため、Amazon Bedrock でナレッジベースを作成し、Amazon IVS ドキュメントを登録していきます。
ナレッジベースの作成
AWS CLI などでもナレッジベースを作成できますが、ここでは、必要なデータストアと IAM ロールを自動で設定してくれるコンソールを使うのが便利です。
まず、Amazon Bedrock コンソールに移動し、「作成」を選択して、「ベクターストアを含むナレッジベース」を選択します。

ナレッジベースに名前を付けて、既存のサービスロールを選択するか、新しいものを作成します。
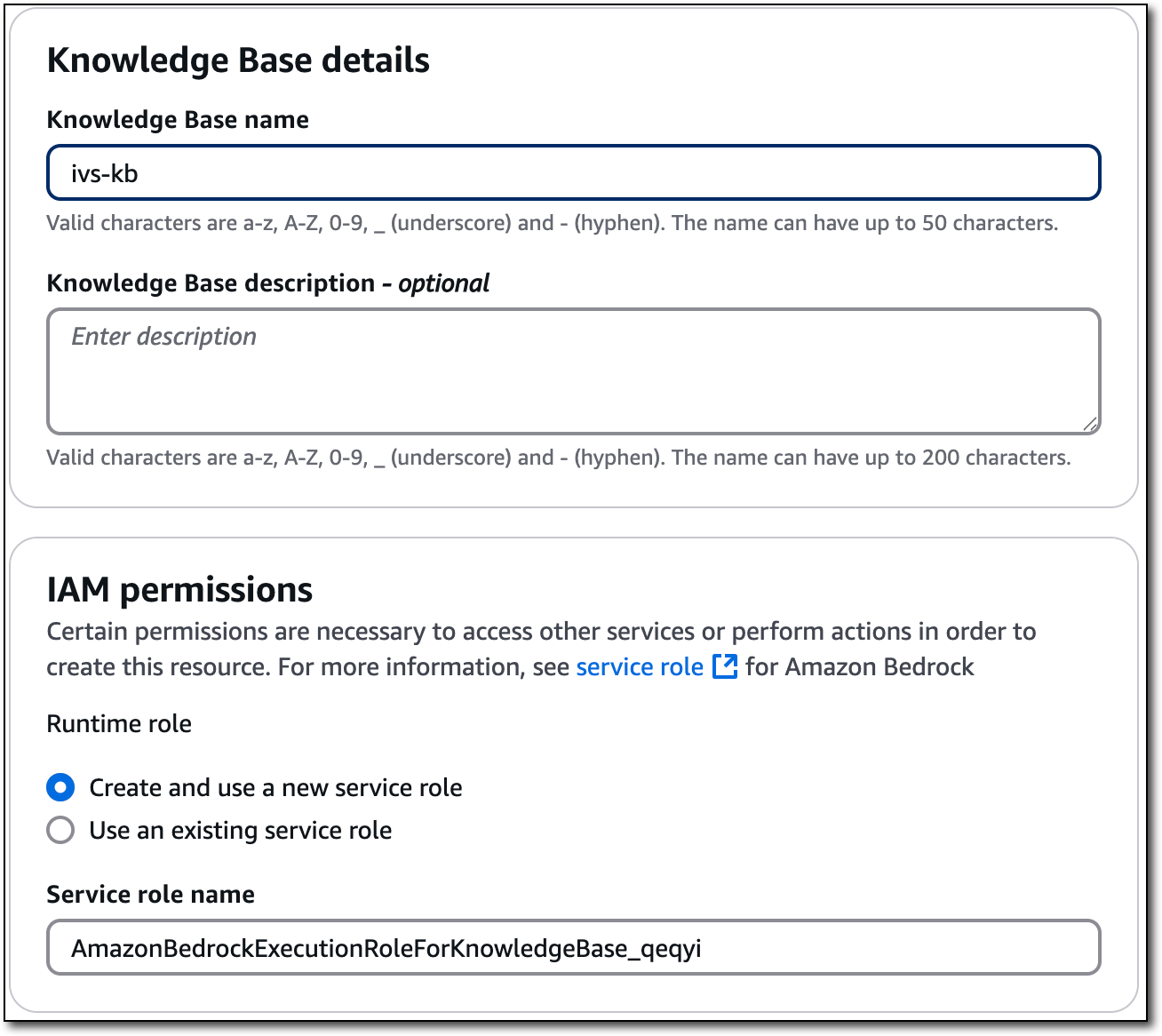
データソースとして「ウェブクローラー 」を選択し、「次へ」を選択します。
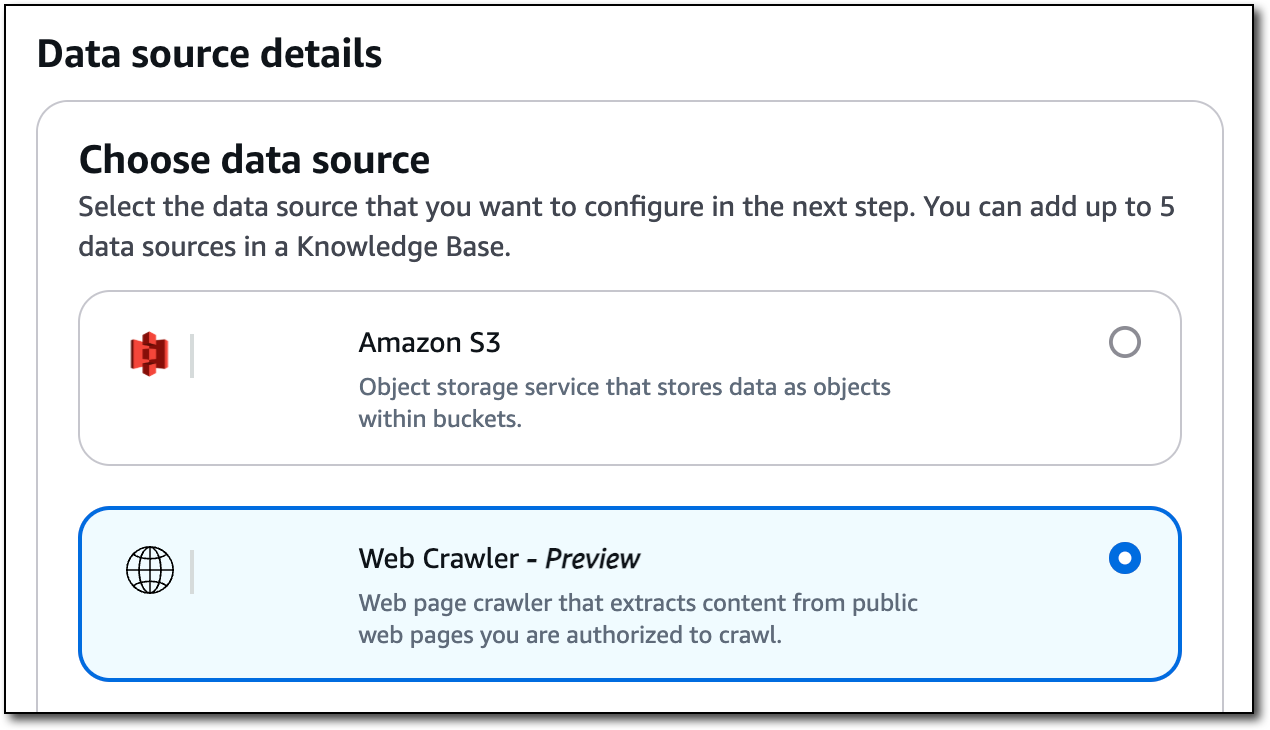
次に、データソースに名前と説明(任意)を付けます。
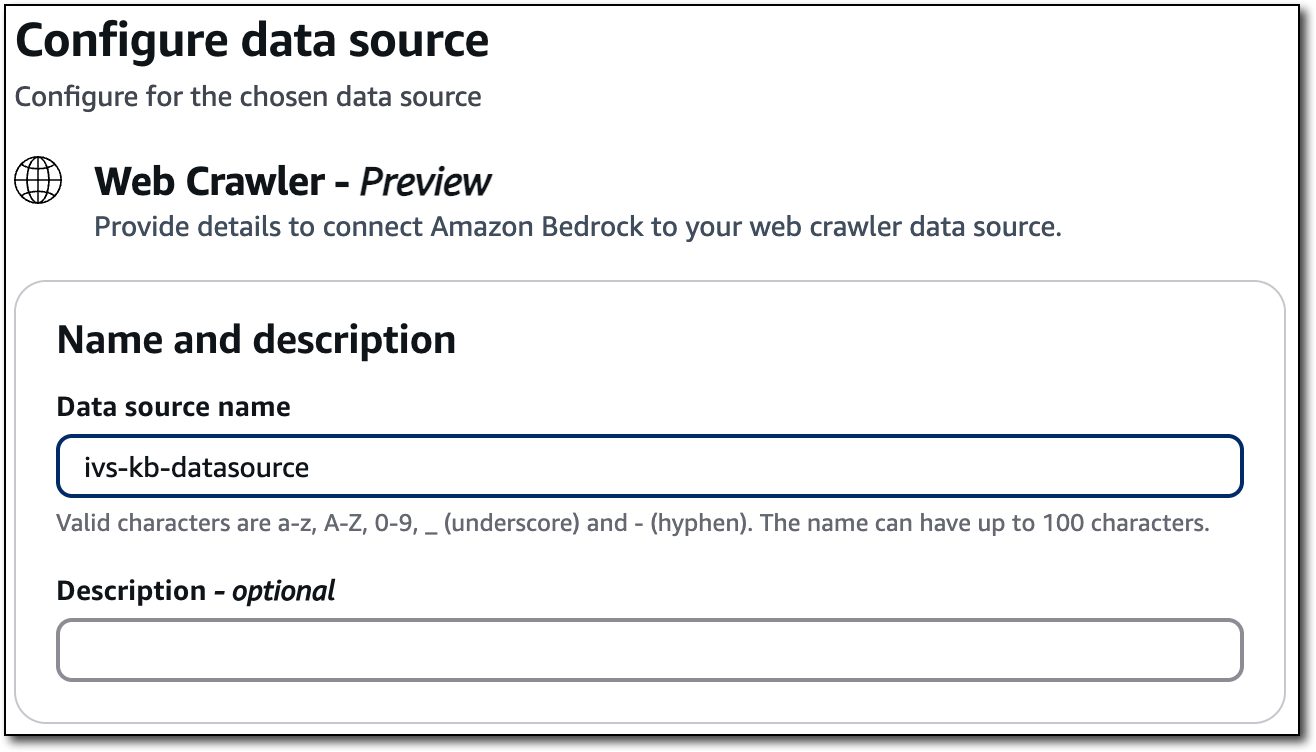
これで、データソースにデータを入力するために使用される、クロールするデータソースの URL を最大 9 個定義できます。
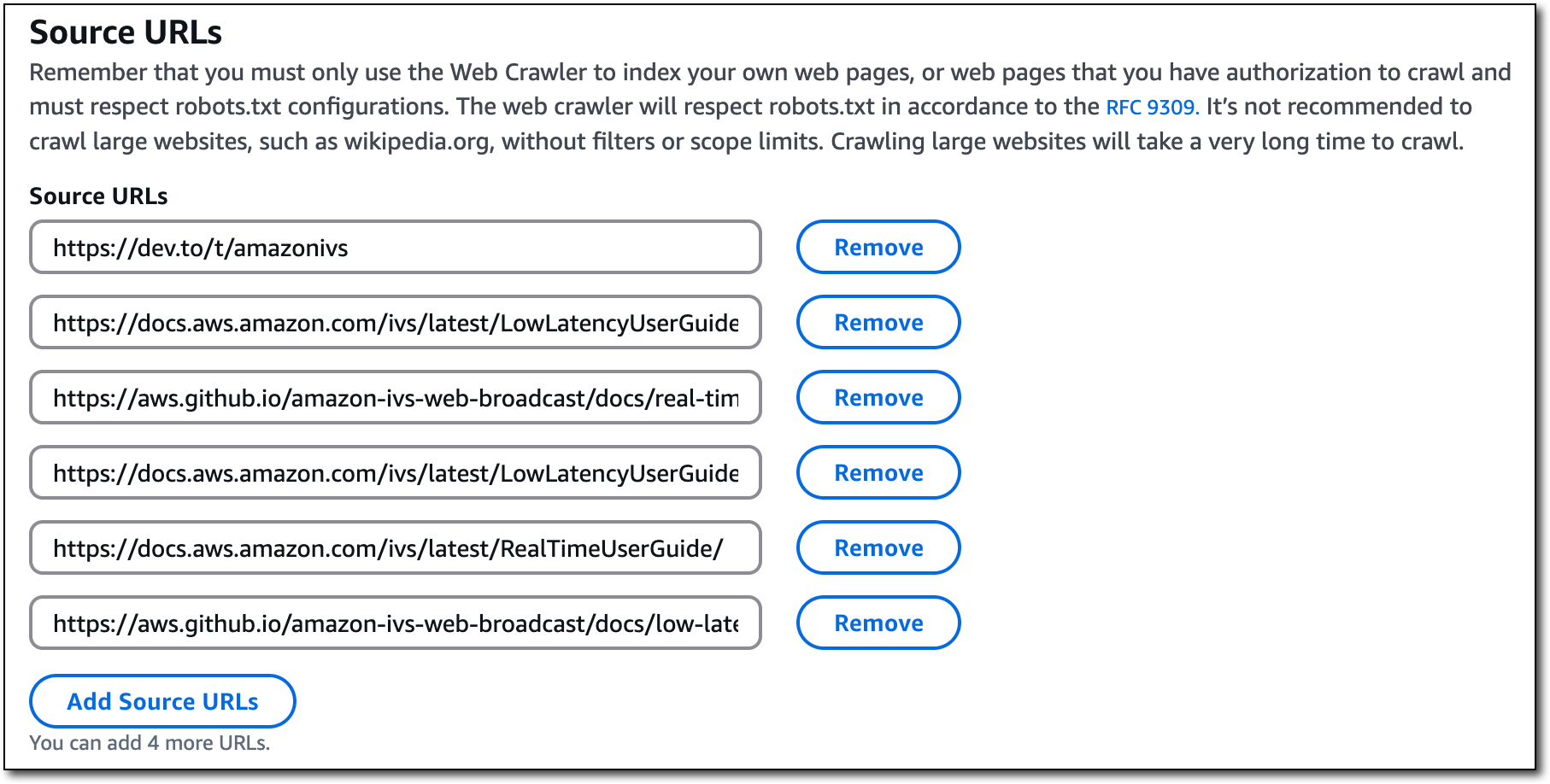
私が使用したURLリストは以下の通りです。Amazon IVS の公式ドキュメントと「amazonivs」タグが付いた dev.to の記事に絞りました。
https://dev.to/t/amazonivs
https://aws.github.io/amazon-ivs-web-broadcast/
https://docs.aws.amazon.com/ivs/latest/LowLatencyUserGuide/
https://docs.aws.amazon.com/ivs/latest/RealTimeUserGuide/「同期スコープ」セクション内の設定はユースケースに合わせた設定すべきですが、「除外パターン」に特に注意してください。状況によって結果は異なるかもしれませんが、私のナレッジベースでは PDF と RSS フィードを除外すること良い結果が得られました。具体的には、除外パターンは(.*.pdf|.*.rss)に設定しました。私のテストでは、除外しないでクロールすると、ドキュメント本体ではなくPDFの「目次」ページから結果が返されることが多く、後でクライアントが混乱する結果となりました。
「コンテンツのチャンクと解析」も、ユースケースに合わせて設定しましょう。私の場合はデフォルトのオプションで問題なく動作しました。
次のステップでは、「埋め込みモデル」を選択します。これは、クロールしたデータをベクターデータに変換するために使用されるモデルです。私の環境では Titan Embeddings G1 - Text v1.2 というモデルがうまく機能しました。
最後に、埋め込みの保存、更新、管理に使用するベクターデータベースを選択または作成します。私は Amazon OpenSearch Serverless を選び、新規作成することにしました。
「次へ」を選択し、設定を確認して「ナレッジベースを作成」を選択します。必要なロールとデータベースが作成されていきます。準備が整ったら、データソースを「同期」することができるようになります。これには約 15 分かかります。データソースの同期が完了したら、ナレッジベースを MCP サーバーに統合する準備が完了です。
ナレッジベース検索ツールの作成
RAG ナレッジベースを作成、同期したら、クエリに基づいてデータを取得する MCP サーバーツールの作成に取り掛かりましょう。このツールには Amazon Bedrock Agent Runtime を使用するため、モジュールをインストールしてクライアントを作成します。
npm install @aws-sdk/client-bedrock-agent-runtimeimport {
BedrockAgentRuntimeClient,
RetrieveCommand
} from "@aws-sdk/client-bedrock-agent-runtime";
const bedrockAgentRuntimeClient =
new BedrockAgentRuntimeClient(config);次に、サーバーツールを追加します。
server.tool(
"ivs-knowledgebase-retrieve",
"Retrieve information from the Amazon IVS Bedrock Knowledgebase for queries specific to the latest Amazon IVS documentation or service information.",
{
query: z.string().describe('The query to search the knowledgebase for'),
},
async ({ query }) => {
const input = {
knowledgeBaseId,
retrievalQuery: {
text: query,
},
vectorSearchConfiguration: {
numberOfResults: 5,
overrideSearchType: 'HYBRID',
}
};
const command = new RetrieveCommand(input);
const response = await bedrockAgentRuntimeClient.send(command);
return {
content: [{ type: "text", text: JSON.stringify(response) }]
};
}
);これで完了です。ツールを公開したことで、クライアントが Amazon IVS に関するドキュメンテーションを参照する必要があると判断した際に、いつでもナレッジベースに問い合わせができるようになりました。
MCP サーバーへのさまざまなツールの追加
MCP サーバーの魅力の一つは、様々なユーティリティやツールを提供できる点です。ドメイン固有の知識だけでなく、LLM が通常苦手とする処理(数学や日付処理など)を支援するツールを提供できます。例えば、作成した MCP サーバーを使うクライアントに特定の IVS チャンネルがいつ作成されたかを尋ねると、そのチャンネルが未来に作成されたなどと驚くべき回答をするかもしれません。これはモデルが現在の日時を直接把握していないためです。現在の日時を返すツールを作れば、クライアントがこの情報を適切に扱えるようになります。
server.tool(
"get-current-date-time",
"Gets the current date and time",
{},
async () => {
return {
content: [{ type: "text", text: JSON.stringify(new Date().toISOString()) }]
};
}
);シンプルながら美しい!😍
もう一つ、同様にシンプルかつ強力な便利ツールを追加しましょう。Amazon IVS ドキュメンテーションを使った、多くの役立つ情報を含む優れたナレッジベースを構築しましたが、、LLM が特定のプロンプトに応答するためにさらなる情報を必要とする可能性があります。そこで、インターネットから特定の URL の内容を取得するための単純なツールを追加しましょう。
server.tool(
"fetch-url",
"Fetch a URL and return its contents as markdown",
{
url: z.string().describe('The URL to fetch'),
},
async ({ url }) => {
const response = await fetch(url);
const text = await response.text();
// convert to markdown
const md = NodeHtmlMarkdown.translate(text);
return {
content: [{ type: "text", text: md }]
};
}
);このツールを公開することで、クライアントはナレッジベースから取得した情報に基づいて特定のURLを取得できるようになります。ナレッジベースの範囲外のコンテキストを提供するために、このツールを通じて特定のURLを取得するように指示することも可能です。
まとめ
今回の記事では、RAG ナレッジベースを作成し、MCP サーバーからそのナレッジベースに問い合わせる機能を追加しました。さらに、サーバーを充実させるために、便利なツールやユーティリティもいくつか追加しました。「関心の分離」については確かに議論の余地がありますが、これはこのブログシリーズの範囲外かもしれません。例えば、一般的なユーティリティは複数のクライアントで再利用できるように、専用のサーバーに置いた方がよいか、などです。次の記事で解説するように、サーバーと対話するカスタム MCP クライアントを作成すると、クライアントが対話できるサーバーの数には制限はありません。そのため、ここで行ったように機能を統合するメリットは、シンプルさを保つこと以外にあまりありません。