This article was originally published on IBM Developer by Kelly Abuelsaad
Artificial intelligence (AI) agents are generative AI (gen AI) systems or programs capable of autonomously designing and executing task workflows using available tools. Can you build agentic workflows without needing extremely large, costly large language models (LLMs)? The answer is yes.
In this tutorial, we will demonstrate how to build a multi agent RAG system locally.
Agentic RAG overview
Retrieval-Augmented Generation (RAG) is an effective way of providing an LLM with additional datasets from various data sources without the need for expensive fine-tuning. Similarly, agentic RAG leverages an AI agent’s ability to plan and execute subtasks along with the retrieval of relevant information to supplement an LLM's knowledge base. This allows for the optimization and greater scalability of RAG applications.
The future of agentic RAG is multi agent RAG, where several specialized agents collaborate to achieve optimal latency and efficiency. We will demonstrate this using a small, efficient model like Granite 3.2 and combine it with a modular agent architecture. We will use multiple specialized "mini agents" that collaborate to achieve tasks through adaptive planning and tool calling. Like humans, a team of agents, or a multi agent system, often outperforms the heroic efforts of an individual, especially when they have clearly defined roles and effective communication.
For the orchestration of this collaboration, we can use AutoGen (AG2) as the core framework to manage workflows and decision-making, alongside other tools like Ollama for local LLM serving and Open WebUI for interaction. Notably, every one of these components is open source. Together, these tools enable you to build an AI system that is both powerful and privacy-conscious—all without leaving your laptop.
Multi agent architecture: When collaboration beats competition
Our Granite Retrieval Agent relies on a modular architecture in which each agent has a specialized role. Much like humans, agents perform best when they have targeted instructions and just enough context to make an informed decision. Too much extraneous information, such as an unfiltered chat history, can create a “needle in the haystack” problem, where it becomes increasingly difficult to decipher signal from noise.
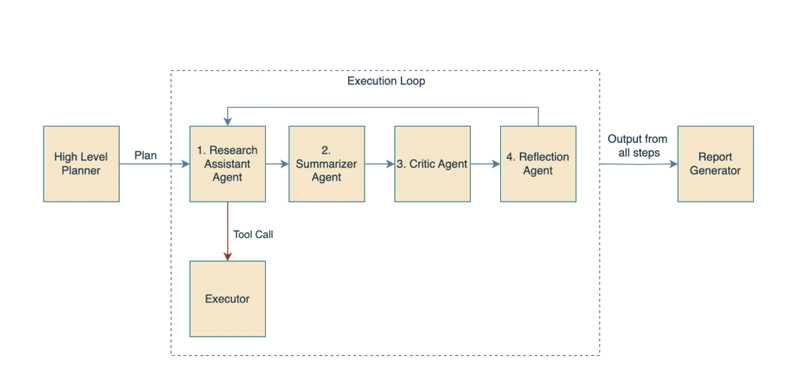
In this agentic AI architecture, the agents work together sequentially to achieve the goal. Here is how the generative AI system is organized:

Planner Agent: Creates the initial high-level plan, once, in the beginning of the workflow. For example, if a user asks, “What are comparable open source projects to the ones my team is using?” then the agent will put together a step-by-step plan that may look something like this: “1. Search team documents for open source technologies. 2. Search the web for similar open source projects to the ones found in step 1.” If any of these steps fail or provide insufficient results, the steps can be later adapted by the Reflection Agent.
Research Assistant: The Research Assistant is the workhorse of the system. It takes in and executes instructions such as, “Search team documents for open source technologies.” For step 1 of the plan, it uses the initial instruction from the Planner Agent. For subsequent steps, it also receives curated context from the outcomes of previous steps.
For example, if tasked with “Search the web for similar open source projects,” it will also receive the output from the previous document search step. Depending on the instruction, the Research Assistant can use tools like web search or document search, or both, to fulfill its task.
Summarizer Agent: The Summarizer Agent condenses the Research Assistant’s findings into a concise, relevant response. For example, if the Research Assistant finds detailed meeting notes stating, “We discussed the release of Tool X that uses Tool Y underneath,” then the Summarizer Agent extracts only the relevant snippets such as, "Tool Y is being used," and reformulates it to directly answer the original instruction. This may seem like a small detail, but it can help give higher quality results and keep the model on task, especially as one step builds upon the output of another step.
Critic Agent: The Critic Agent is responsible for deciding whether the output of the previous step satisfactorily fulfilled the instruction it was given. It receives two pieces of information: the single step instruction that was just executed and the output of that instruction from Summarizer Agent. Having a Critic Agent weigh in on the conversation brings clarity around whether the goal was achieved, which is needed for the planning of the next step.
Reflection Agent: The reflection agent is our executive decision maker. It decides what step to take next, whether that is encroaching onto the next planned step, pivoting course to make up for mishaps or giving the thumbs up that the goal has been completed. Much like a real-life CEO, it performs its best decision making when it has a clear goal in mind and is presented with concise findings on the progress that has or has not been made to reach that goal. The output of the Reflection Agent is either the next step to take or the instructions to terminate if the goal has been reached. We present the Reflection Agent with the following items:
The goal.
The original plan.
The last step executed.
The output of the Summarizer and Critic Agents from the last step.
A concise sequence of previously executed instructions (just the instructions, not their output).
Presenting these items in a structured format makes it clear to our decision maker what has been done so that it can decide what needs to happen next.
- Report Generator: Once the goal is achieved, the Report Generator synthesizes all findings into a cohesive output that directly answers the original query. While each step in the process generates targeted outputs, the Report Generator ties everything together into a final report.
Leveraging open source tools
For beginners, it can be difficult to build an agentic AI application from scratch. Hence, we will use a set of open source tools.
The following architecture diagram illustrates how the Granite Retrieval Agent integrates multiple tools for agentic RAG.
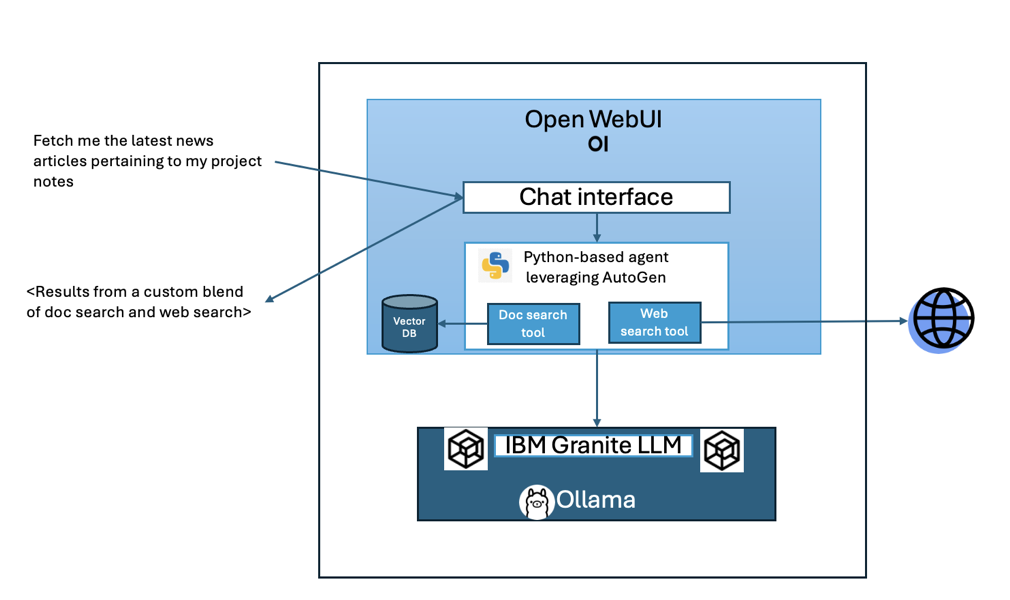
Open WebUI: The user interacts with the system through an intuitive chat interface hosted in Open WebUI. This interface acts as the primary point for submitting queries (such as “Fetch me the latest news articles pertaining to my project notes”) and viewing the outputs.
Python-based agent (AG2 Framework):** At the core of the system is a Python-based agent built using AutoGen (AG2). This agent coordinates the workflow by breaking down tasks and dynamically calling tools to execute steps.
The agent has access to two primary tools:
Document search tool: Fetches relevant information from a vector database containing uploaded project notes or documents stored as embeddings. This vector search leverages the built-in documental retrieval APIs inside of Open WebUI, rather than setting up an entirely separate data store.
Web search tool: Performs web-based searches to gather external knowledge and real-time information. In this case, we are using SearXNG as our metasearch engine.
Ollama: The IBM Granite 3.2 LLM serves as the language model powering the system. It is hosted locally using Ollama, ensuring fast inference, cost efficiency and data privacy.
Other common open source, agent frameworks not covered in this tutorial include LangChain, LangGraph, and crewAI.
Steps
Detailed setup instructions are contained in the README of the agentic RAG project. The entire project can be viewed on the IBM Granite Community GitHub[https://github.com/ibm-granite-community/granite-retrieval-agent].
The following steps provide a quick setup for the Granite Retrieval agent.
Continue reading on IBM Developer
