

Fighting mental fatigue...
Do you ever feel overwhelmed by tech newsletters? As a fullstack developer, you need to stay up to date across multiple areas — frontend, backend, databases, infrastructure, and more.
Personally, I’m subscribed to at least 15 newsletters, and I love them all — spoiler alert: I list most of them at the end of the article. But if I miss a day or two, my “DEV” folder starts overflowing. I often spend hours on the weekend catching up — reading inspiring articles, testing snippets, and discovering new tools. It’s one of the best ways to grow and stay sharp.
But let’s be honest — keeping up with everything is exhausting.
So last weekend, I gave myself a challenge: build a system to manage the overflow using as little code as possible, combining AI and automation. I’m no expert— I had only heard of embeddings and we use some at work— but I pulled it off. And you can too. 🙂
What Are We Building?
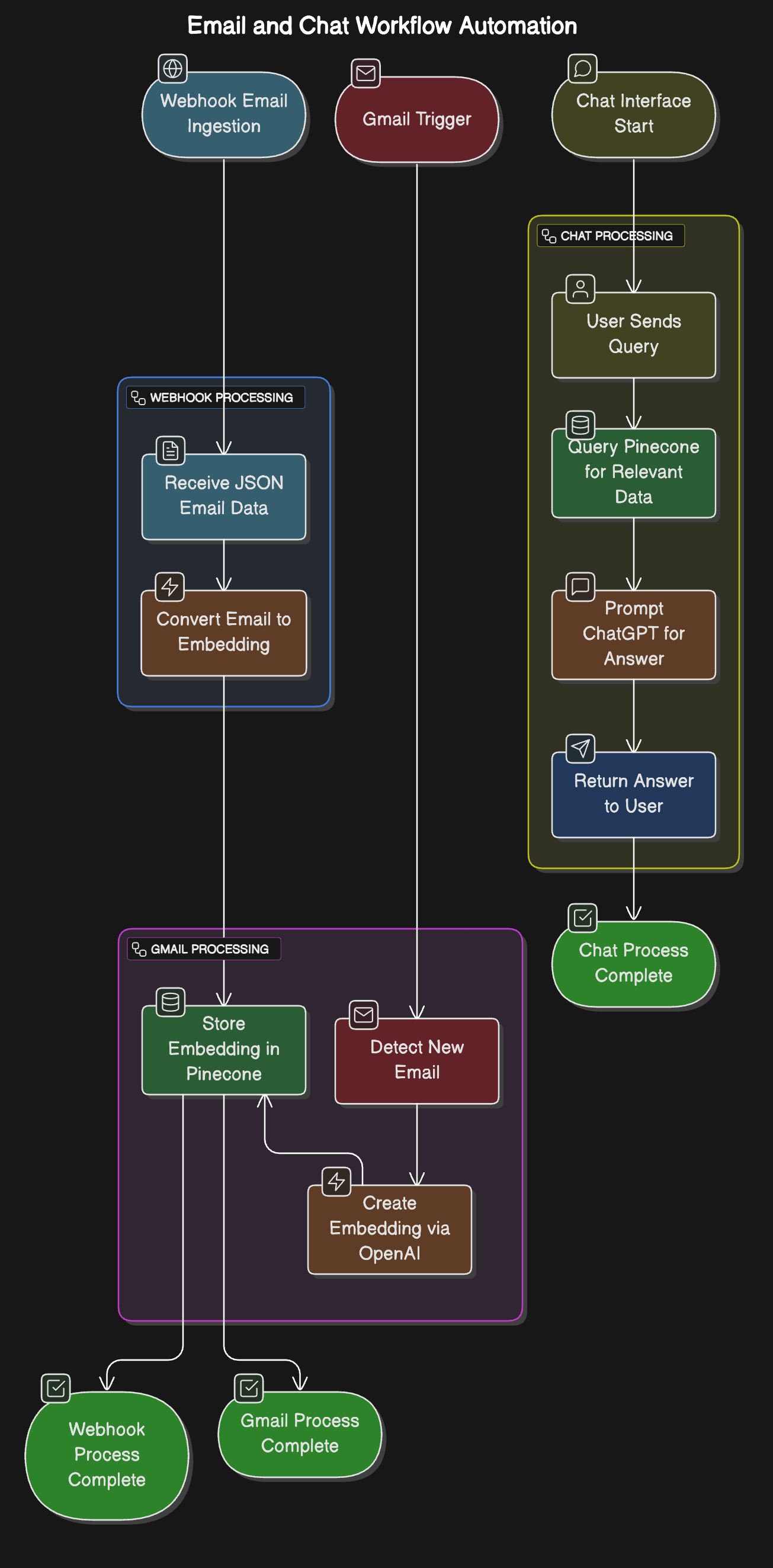
We’ll build a system that pulls content from your favorite tech newsletters, stores it in a vector database, and lets you query them conversationally — all in (almost) no-code using n8n, Pinecone, a bit of JavaScript, and of course OpenAI - but you can use an other AI provider of course.
We’ll need three workflows but one of them is optional:
- Gmail Trigger: It is going to poll our gmail account and if there are new emails, it will get their full details, including html, create the embeddings and store them in the vectorized database.
- Chat Interface: This will leverage n8n’s chat interface to prompt ChatGPT with results from the vector database in an agentic way.
- (Optional) Webhook for Historical Ingestion: This workflow processes older newsletters in bulk and required some code. I'll treat it last.
Services we’ll use:
- Gmail
- OpenAI API
- Pinecone (free tier)
- n8n (free trial)
I’ll assume that, like me, you’re using Gmail, and that you can set up forwarding rules.Also, you’ll need Node.js installed to run a small script if you go for the optional step.
Oh and just before we go, let's just get a quick reminder about a concept we gonna use: what is an embedding ?
An embedding converts text (or images, audio, etc.) into a vector — a list of numbers — that represents its meaning in a way a machine can understand. We store it in a vectorized database.
Example:
- Text:
"How to build an agent?"- Embedding:
[0.12, -0.98, 1.45, ...]
Let's synchronize emails
- Create a Gmail account
I think it's easier not to mix everything as it only takes 3min, I recommend you create a new email adress for this exercise.
- Forward your newsletters
I already had a rule that filtered all tech newsletters into a “DEV” folder. I just added a forward rule to send them to the new address.
- Connect Gmail to n8n
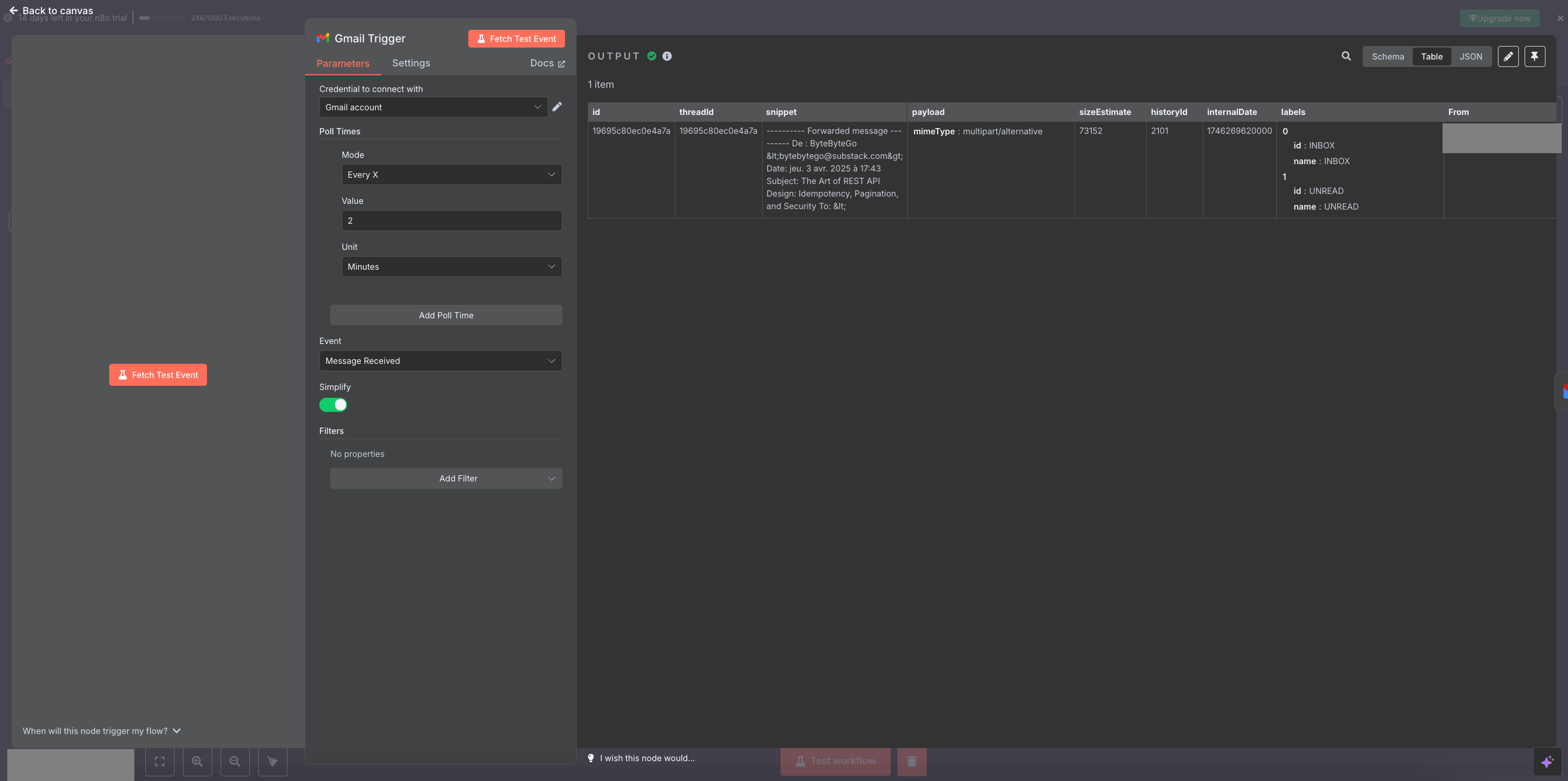
Ok let's dive in, you need a free trial n8n subscription and create a new workflow from scratch. You select the "on app event" trigger, choose Gmail and "Message received". From there you can create a credential using Oauth and connect to your newly created account. For testing, you can send yourself an email.
One of the feature I liked the most on n8n, just like my previous experience with Integromat, is the possiblity to listen for an input (for example a webhook or an event) and analyze the input received. Immensely useful, given the fact that you can pin it for the next step also.
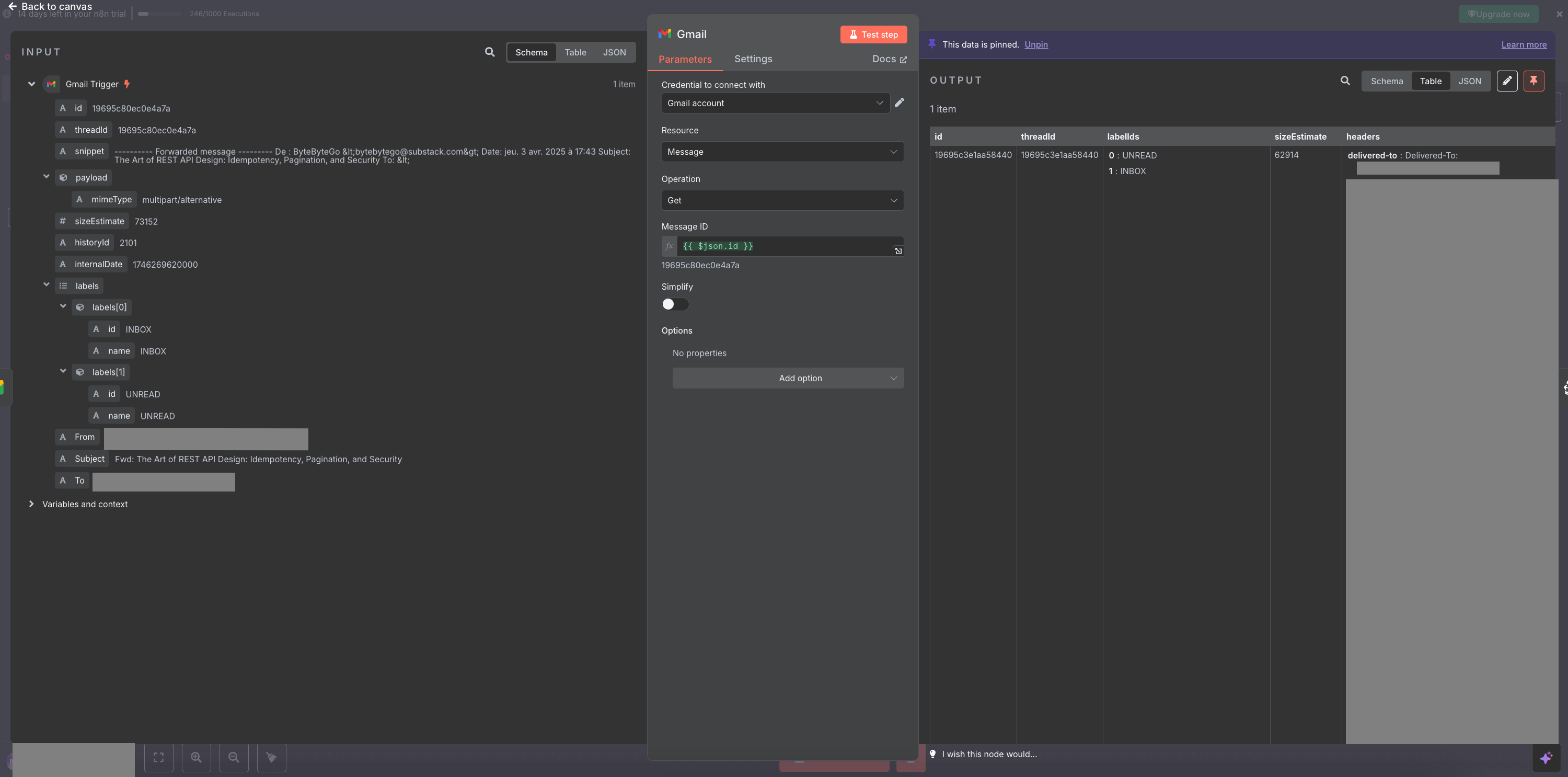
- Get the full email content
The trigger doesn’t give you the full HTML body. You need to add a Get Message node (still using the Gmail integration) and uncheck “Simplify” to get the raw HTML.
- Handling multiple emails?
I remember having to create loop and handle array in my previous no-code experience with Make Integromat. But with n8n it's much more simpler. Thanks to their "multiple items" processing model, n8n automatically handles arrays of items by processing each one through the entire workflow. It's like every node is accepting an array - even if there is only a single element inside. This is brillant!
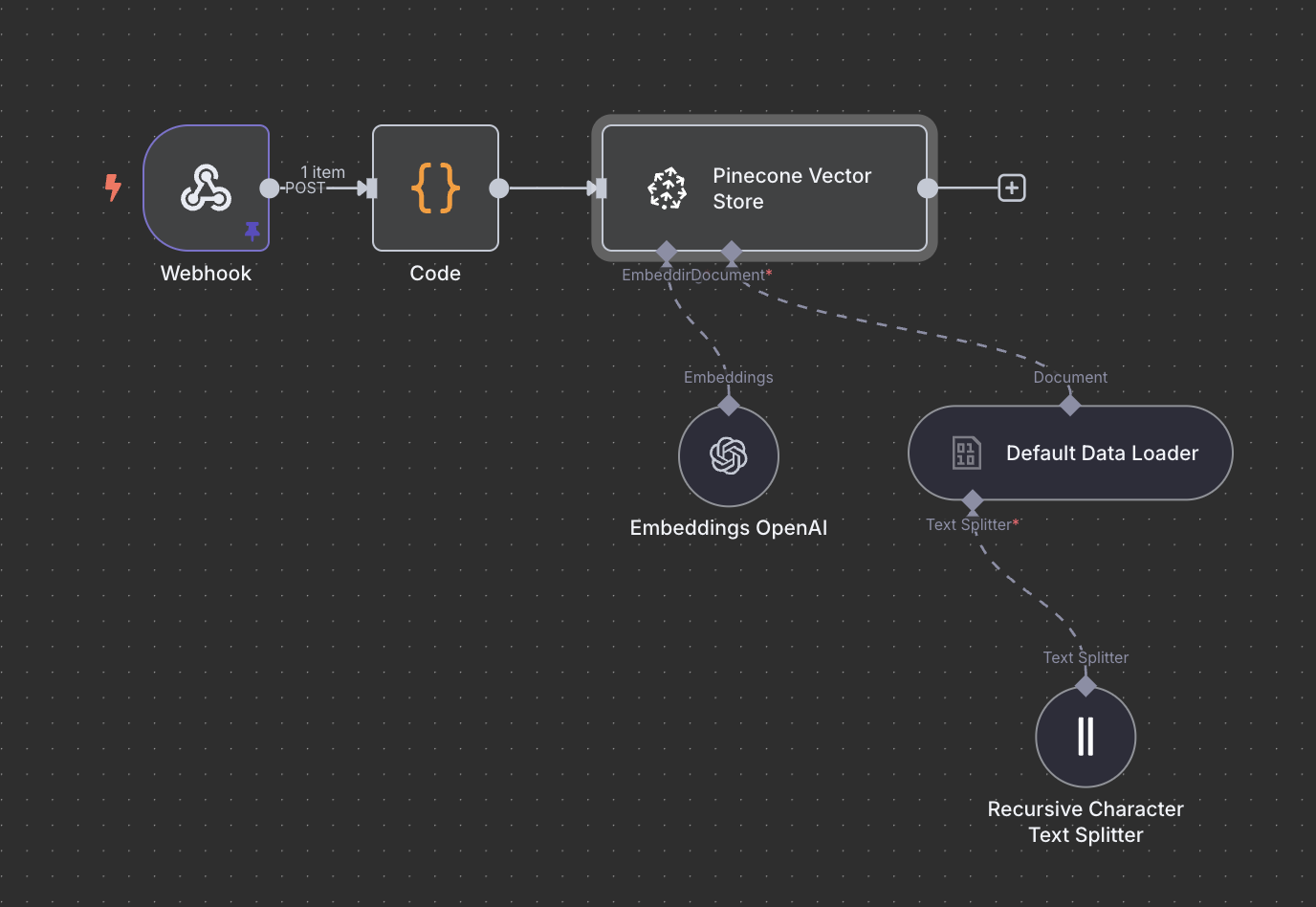
Convert to Embeddings & Store in Pinecone
Now, we need to convert our html piece of code into a more LLM-friendly data format and this is why we need to convert it to an embedding. Embeddings come in different formats, depending on the model we use.
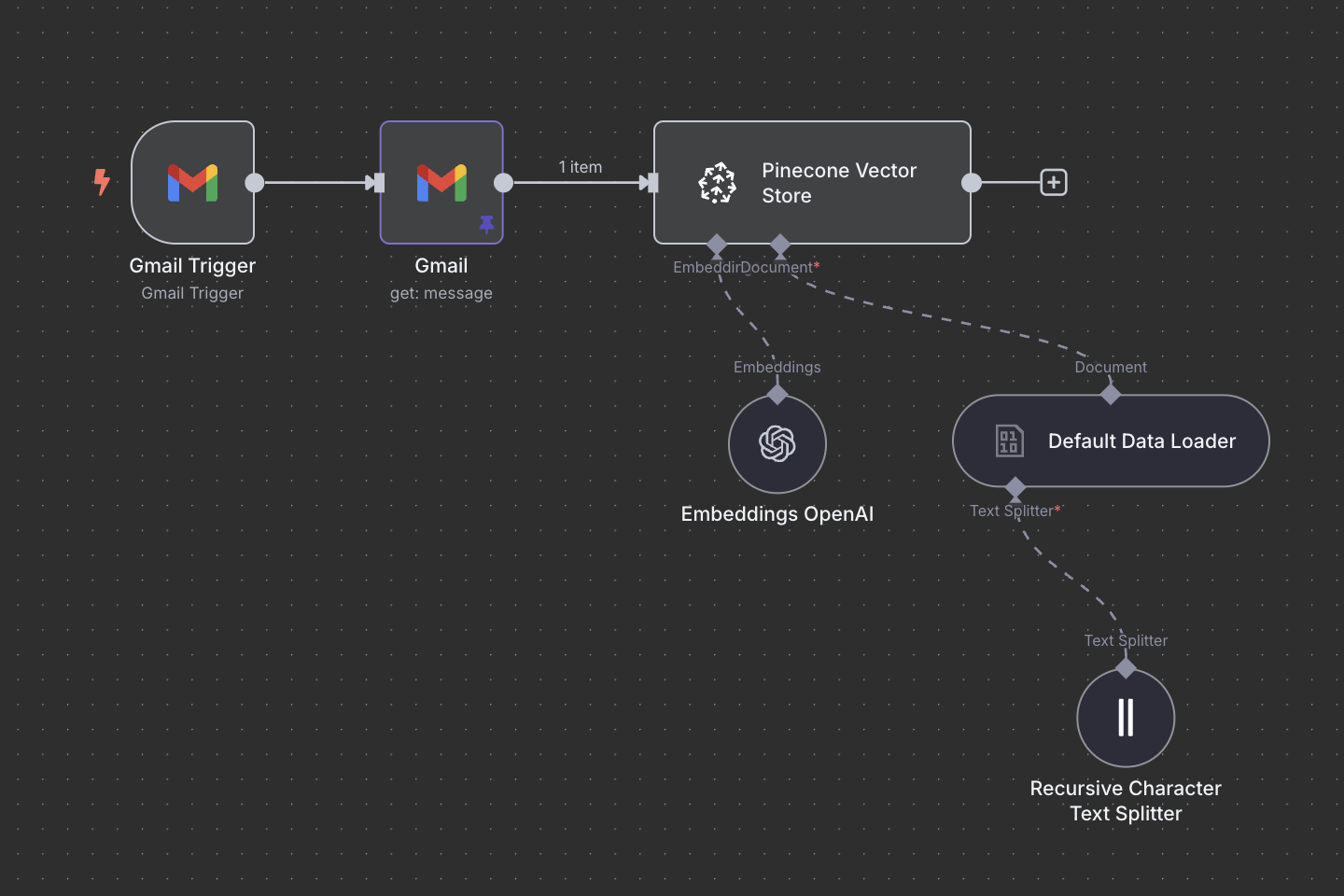
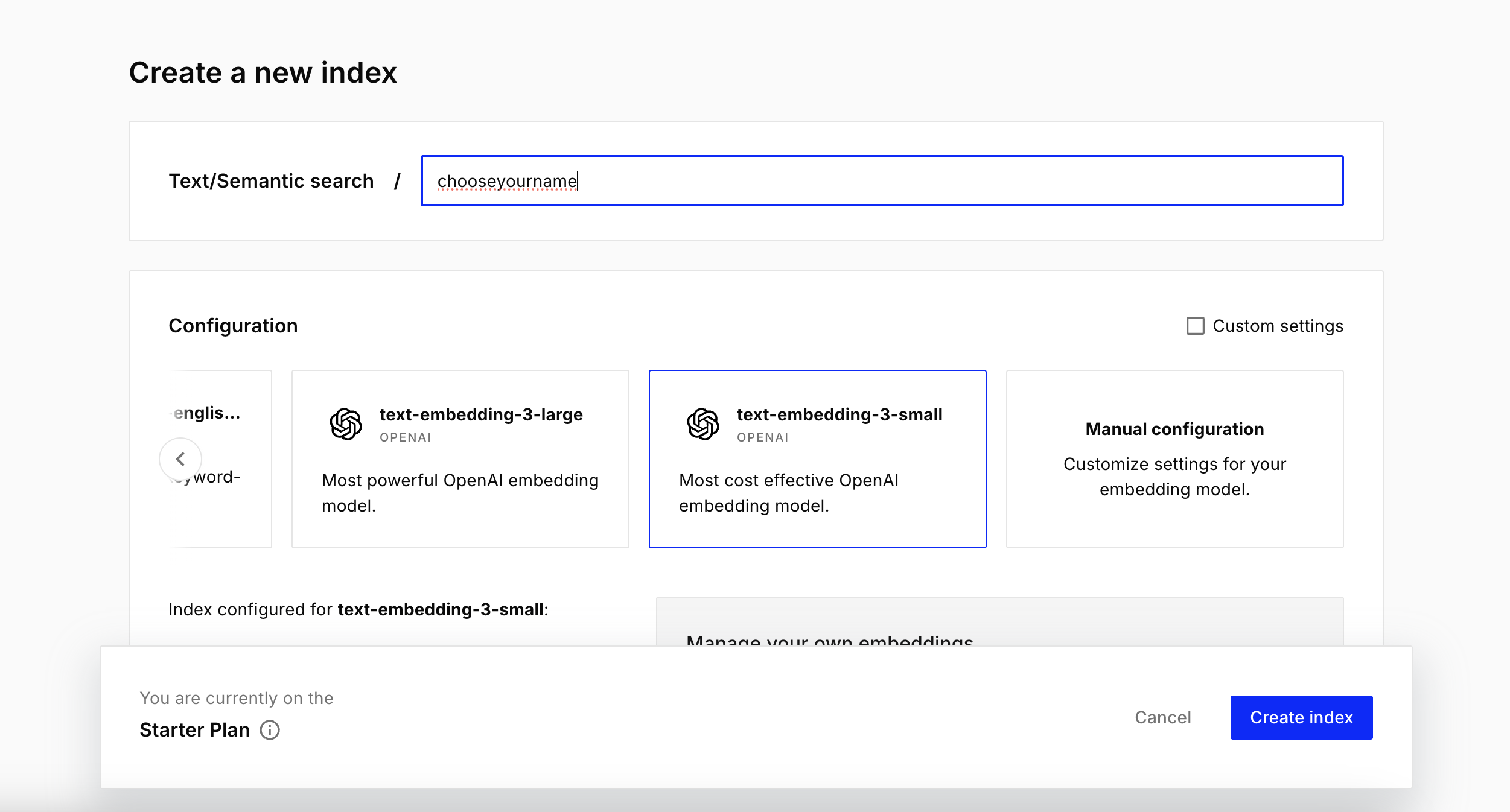
- Create a Pinecone index
We’ll use the OpenAI text-embedding-3-small model (1536 dimensions), which is more than enough for newsletter HTML.
Thanks to Pinecone serverless architecture, creating the index is very straightforward, I didn't touch to any of settings. The only thing we're going to need is its id, which we set up in the first input fields.
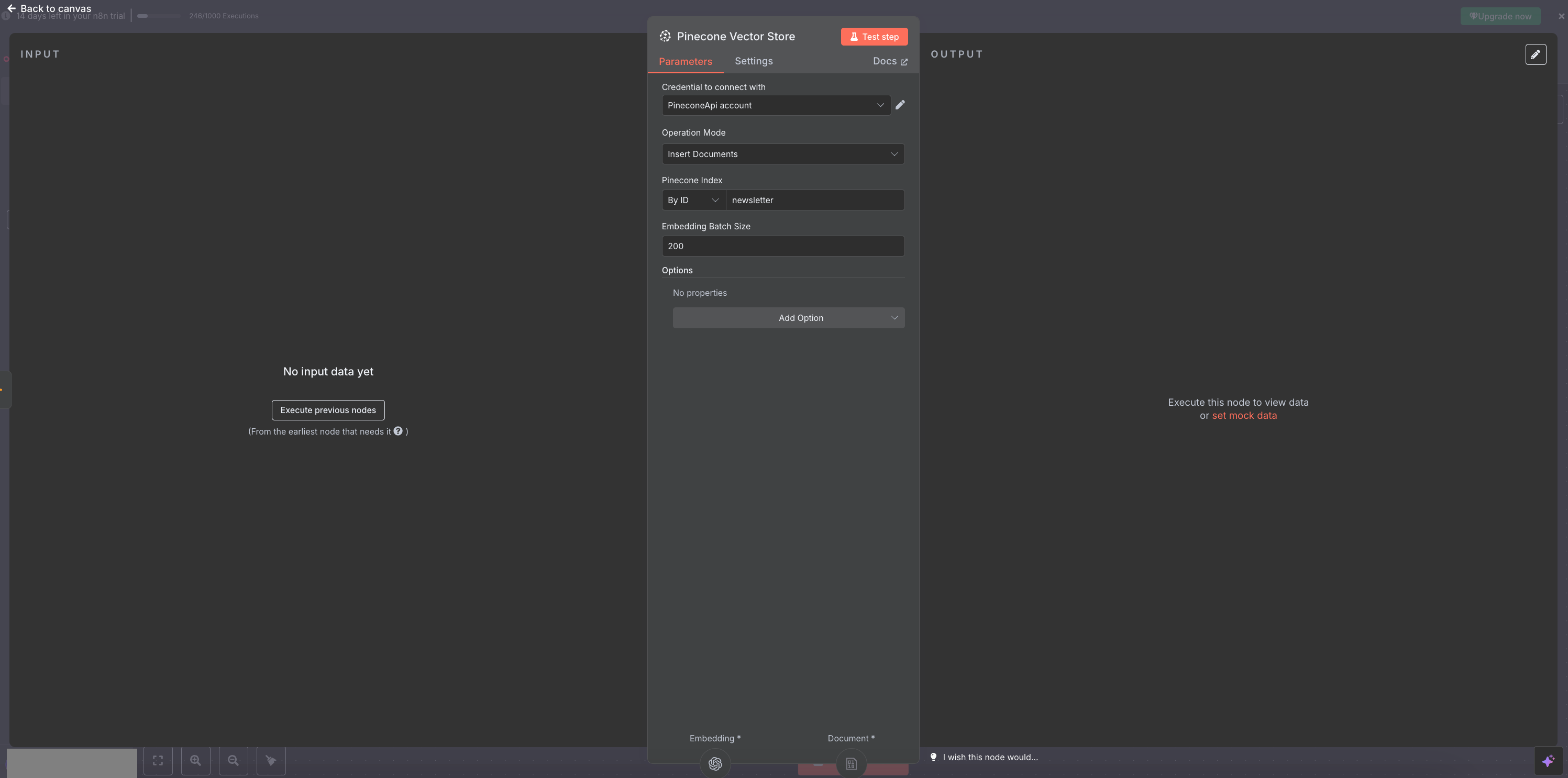
- Set up the Pinecone node with embeddings
Create the node, enter your index ID and link it to the OpenAI embeddings node. This is very easily done with n8n, when a module needs another module, it just appears below, you click it and can navigate in a sub-menu to set everything up. Here you just have to click first on Embedding, choose the same model and enter your OpenApi API key.
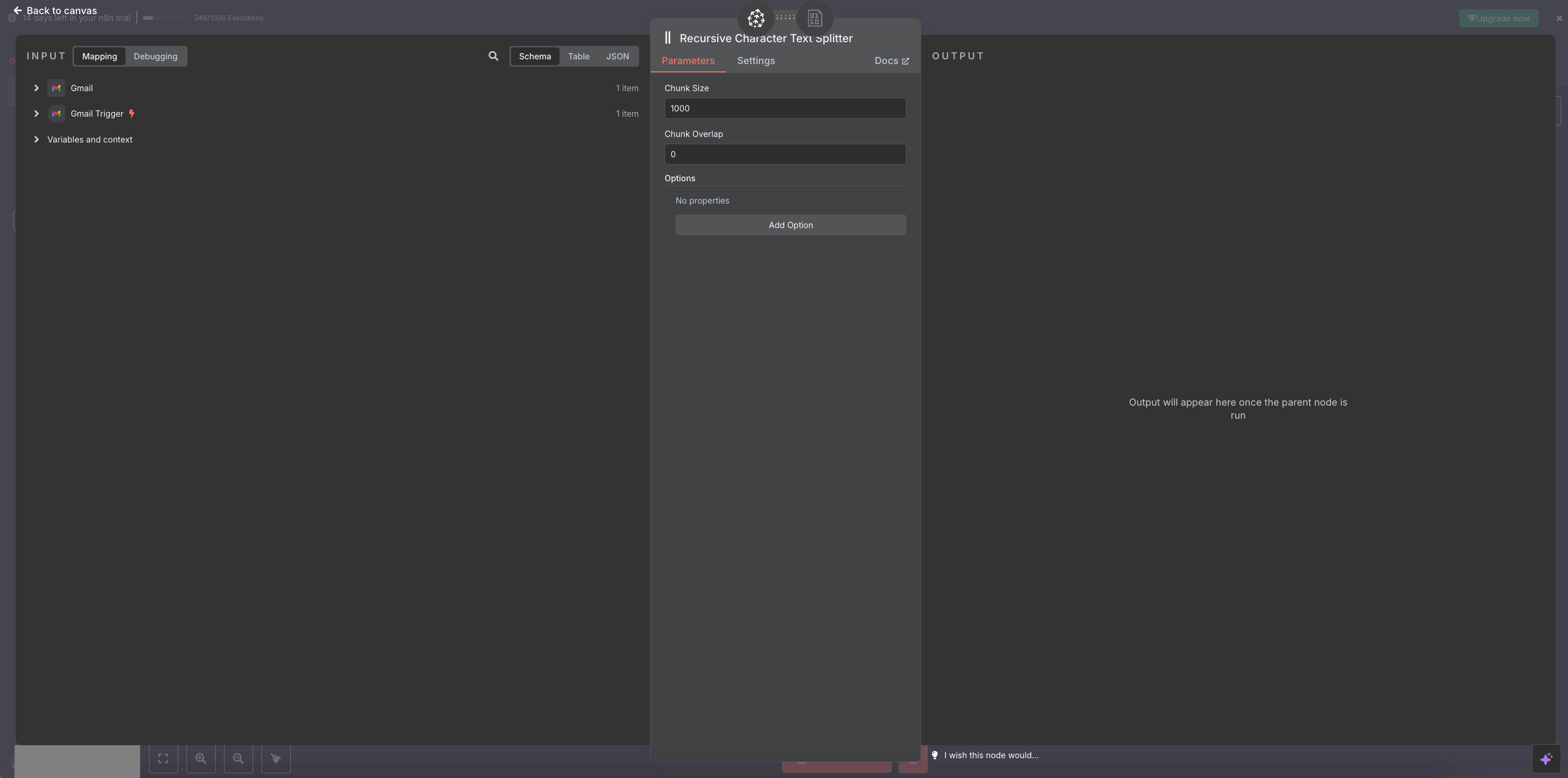
- Set up the Pinecone node with document
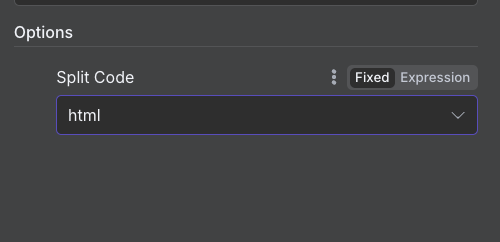
We set up a Default data loader to access the html field but we need to set what is called a separator. We choosed a basic setting as it was mentioned it will cover most use case: the recursive character text splitter. Why? In n8n, you're loading html content and need to break it into smart chunks for further processing. The separator defines how you split it. I'm sure there is era for improvement here as I choose the default and set options for split code to html.
You've just created your first AI pipeline!
Query the Database via Chat
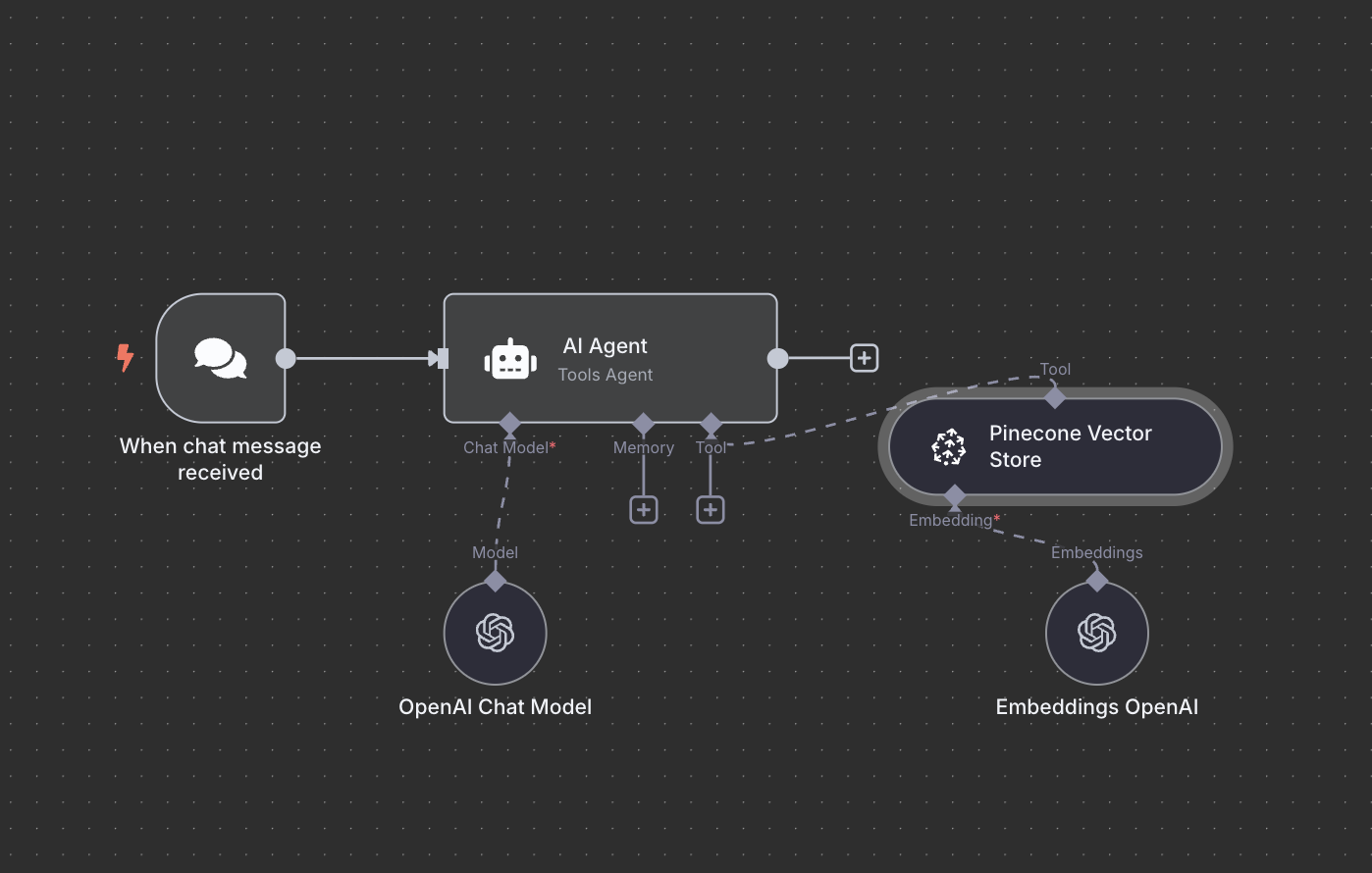
Here I was a bit lost but thanks to n8n great automation examples I just had a look at how someone analyzed a PDF and then chat with the result of it. That was close enough to our use-case. Let's create another workflow.
- Use n8n's Chat Interface
Basically, instead of relying of an app's event, here we choose to have a chat integration. n8n really made a difference here. You can keep your chat private, in the workflow, but also make it public, and even put it behind a login step (username/password or just your n8n credentials). Out-of-the-box!
- Create an AI Agent in n8n
The AI agent will use our tool when needed and attach it to ChatGPT when building prompts. This is simply done again by filling up the modules. That's why our agent needs:
- A connection to ChatGPT (the model)
- Access to the Pinecone vector DB (the tool)
n8n connects these easily via built-in modules. Just fill the needed informations and credentials.
- Craft a good system prompt
A well-written system message boosts the answer quality. Here’s mine:
You are an expert assistant specialized in technologies and web development.
You have access to a curated database of newsletters from top-tier sources, each provided with full HTML source code.
When answering, you must:
- Extract insights directly from the HTML content
- Identify the original sender by examining the HTML metadata
- Clearly cite the newsletter source and reception date
- Always include the original link when available
Your responses should be accurate, concise, and well-structured.
Prioritize verifiable information from the newsletter content itself.Backfill Old Emails (optional)
I wanted to ingest my backlog of newsletters too. The idea was simple : get my data from Google, transform it into JSON, send it via HTTP to a n8n worklow to store it in database. Let's do it!
- Export from Gmail via Google Takeout
Actually, it's quite simple to get your data from Google. There is a service for this called Google Takeout. I choosed the Gmail service, my DEV folder and... kabooom! A few moments later I got a zip with my data.
I tried to open it and found inside a html page with a mbox data folder... I was not familiar with this format but it's used by many email clients to exchange data. But my n8n workflow don't speak MBOX.
- Convert MBOX to JSON
A little research led to me to this repository. Just clone the code and run the command mentioned in the README to get your emails as Json. Easy peasy!
# Instal dependencies
npm i
# Run the script (no need to use node, script uses a shebang)
./mbox-to-json.js --input my_emails.mbox --output my_emails.jsonOk we finally have our JSON. What's the idea? Maybe we can build a little JS script to parse it, and send it via a POST request to another n8n workflow with a webhook that can receive data.
- Send JSON to n8n via Webhook
Basically, I just copied our Gmail trigger workflow and changed the initial step to a webhook. You can chose an authentification method, just buid a token using openssl and put in your header of your choice.
# It's easy to build a simple token using openssl
openssl rand -hex 16- Analyzing answer
Humm... Something is wrong. the body of our request contains an array of data, we need to map them before passing them to our Pinecode node - the same we used before. And here I must say I fell in love for real with n8n : you can write javascript code very easily inside the node. With the help of my good friend Claude, I got the syntax right (it's not that easy at first to understand why you need $input.first()) and then it's just basic JS.
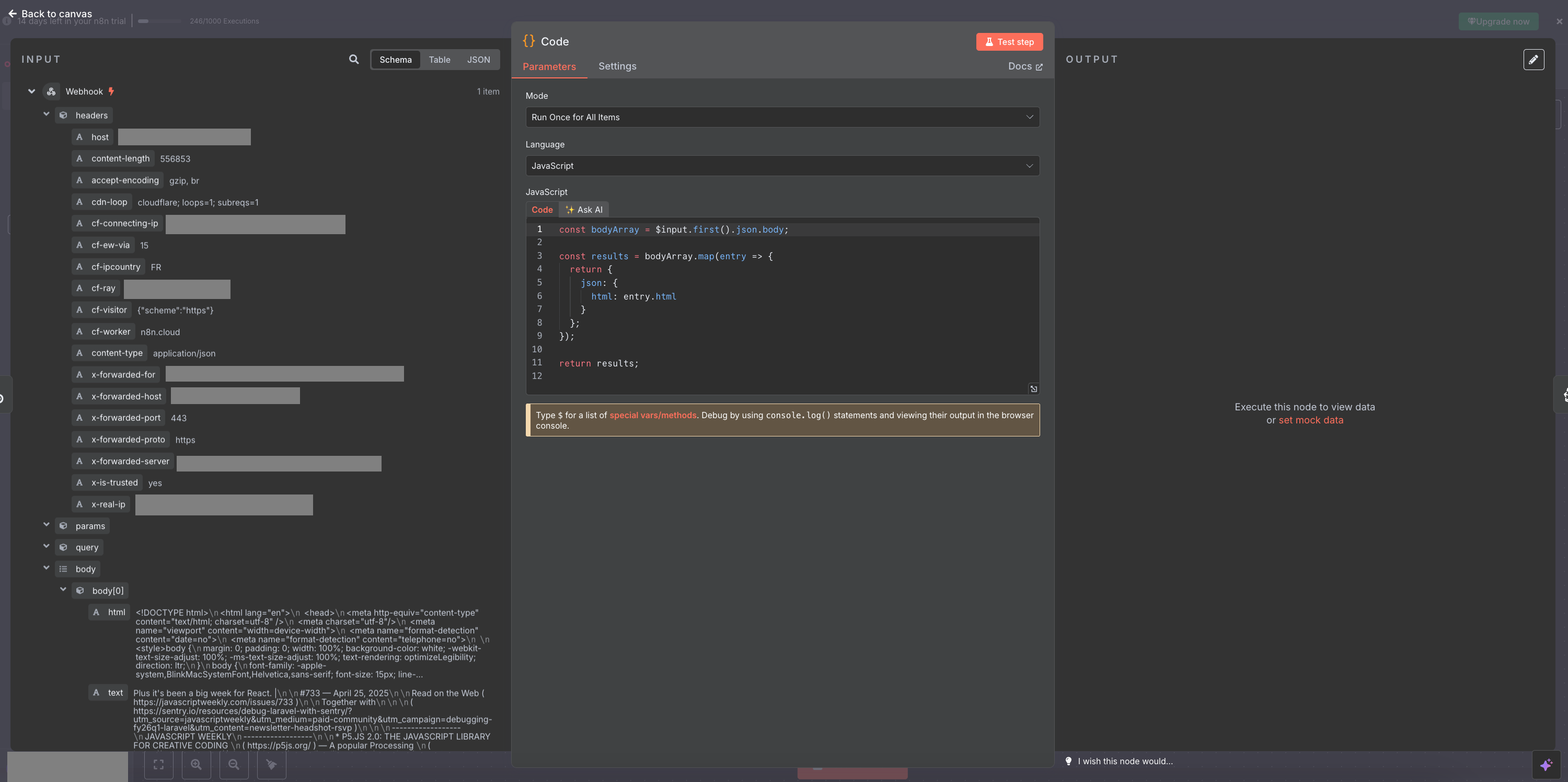
- Here comes the trouble...
But here I encoutered many difficulties that I'll resume here
First, my data was quite big, around 200Mo of JSON, this was way too much of a payload. I need to batch it.
Then, even after batching it in slice of 10 elements, I've realized that the limits of my free instance of n8n : it does not have much memory, some operations are difficult to parallelize and making 10 async calls in JS with 5 workflow running didn't work for me.
What worked was batching it and adding a delay. As creating embeddings and inserting in Pinecode database was a 20-30s job, I used this delay amount in my script to make sure only one workflow was running at a time.
Even with this, some failed so I decided to record which index of the batches was failing to retry later in a specific retry mode in my script. Also, because of the delay, handling 282 batches of 10 elements was quite long so I also decided to store what should be the next batch to start if I had to stop.
After a few hours....all newsletters are indexed. My agent was ready !
Test & Use
Let’s see it in action.
Query: “Do you have any ressources about building components in Vue.js”

→ GPT scans the vector DB and responds with summarized insights, linked to the source newsletter and sender.
If you did the optional part, you saw that n8n's cloud instance has memory and parallelism limits. But it’s manageable...and they even give you advises for this.
Next step for me would probably be to self-host n8n on a VPS to have more RAM and CPU available hat as it'a possibility offered by them and that seems quite well documented. It was my first try with this tool and vectorized database and I must admit this is amazingly powerful. Can't wait to try other scenarios....
I hope this tutorial was helpful! As I said at the start — I’m still learning in both the no-code and AI space, and if I can build this, you definitely can too. I'm coming from a code background so using these tools requires me to adopt a specific logic but after this first step, I must admit I loved the experience.
Also, if I had to code this from scratch, I wouldn’t be writing this article — I'd still be debugging regex filters 😄
Please reach out if you have feedback or ideas on how to improve the flow or integrations.
Bonus: My favorite newsletters
- ByteByteGo
- Node Weekly
- Javascript Weekly
- Tyler from ui.dev
- TLDR / TLDR Web Dev
- Neo Kim
- Frontend Focus
- Smashing Magazine
- Weekly Vue News
- Codepen
- WizardZines / Julia Evans
- Trevor I Lasn
- Quastor
- Modern CSS Newletter
- Sequoia
- Engineering Leadership
- Dev Community Newsletter
- pganalyze
- The New Stack


