In today's data-driven world, organizations need a robust and scalable data architecture to handle large volumes of data. Apache offers a suite of free and open-source tools that can help build a comprehensive data architecture. In this article, we'll explore how to build a scalable data architecture using Apache tools, highlighting the benefits of using free and open-source software.
Technology
Here's a brief overview of the technologies used in this architecture:
1. Apache NiFi: A data integration tool that ingests data from various sources and writes it to destinations like HDFS and Kafka. NiFi provides a scalable and flexible way to manage data flows.
2. Apache Kafka: A distributed streaming platform that handles high-throughput and provides low-latency, fault-tolerant, and scalable data processing. Kafka is ideal for real-time data processing and event-driven architectures.
3. Apache Flink: A unified analytics and event-driven processing engine that provides real-time processing capabilities. Flink is designed for high-performance and scalability.
4. Apache HDFS: A distributed file system that provides a scalable and reliable way to store large amounts of data. HDFS is designed for big data storage and processing.
5. Apache Spark: A unified analytics engine that provides high-level APIs in Java, Python, and Scala for large-scale data processing. Spark is ideal for batch processing and machine learning.
6. Apache Iceberg: A table format that provides a scalable and efficient way to manage large datasets. Iceberg supports ACID transactions and is designed for big data analytics.
7. Apache Atlas: A data governance and metadata management platform that provides a centralized repository for storing and managing metadata. Atlas enables data governance, data discovery, and data lineage.
8. Apache Airflow: A workflow management platform that schedules and manages workflows. Airflow provides a flexible way to manage dependencies and monitor workflows.
9. Apache Superset: A business intelligence web application that provides data visualization capabilities. Superset supports a variety of data sources and provides an intuitive interface for users.
Architecture
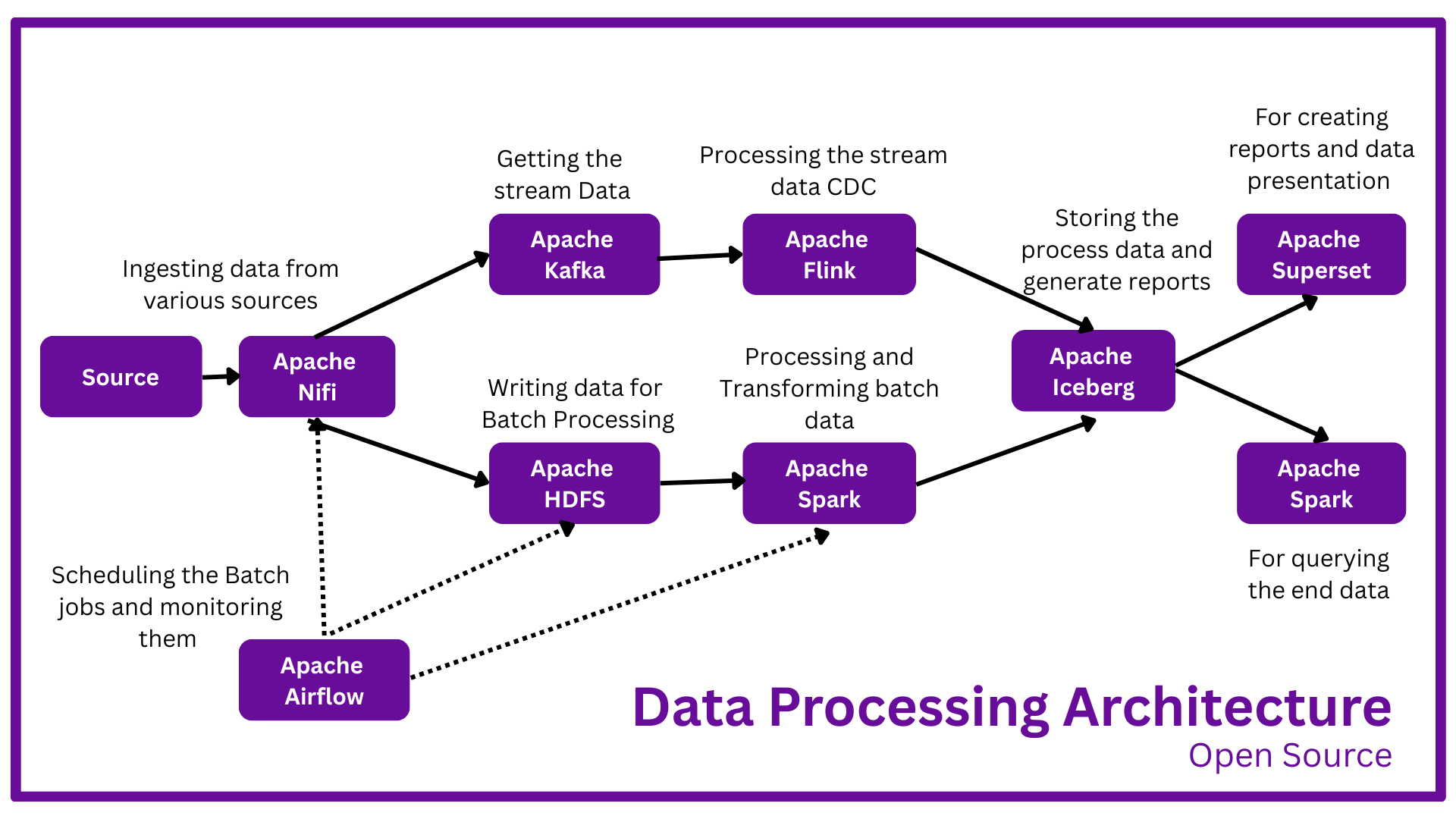
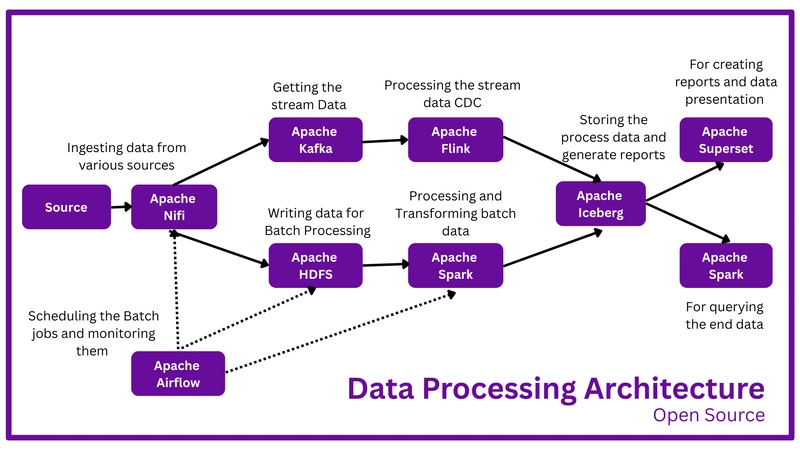
Our data architecture will consist of the following components:
1. Data Ingestion: Apache NiFi will be used to ingest data from various sources, such as logs, APIs, and databases.
2. Real-time Processing: Apache Kafka will stream data to Apache Flink for real-time processing.
3. Batch Processing: Apache Spark will be used for batch processing of large datasets.
4. Data Storage: Apache Iceberg will be used to store processed data in a scalable and efficient table format.
5. Data Governance: Apache Atlas will be used to manage metadata, provide data governance, and enable data discovery and lineage.
6. Data Querying: Apache Spark and Apache Superset will be used to query data stored in Apache Iceberg.
7. Workflow Management: Apache Airflow will be used to schedule and manage workflows.
How it Works
Here's an overview of how the architecture works:
- Data is ingested into Apache NiFi from various sources.
- NiFi writes data to Apache Kafka for real-time processing and Apache HDFS for batch processing.
- Apache Kafka streams data to Apache Flink for real-time processing.
- Flink processes data in real-time and writes processed data to Apache Iceberg.
- Apache Spark reads data from Apache HDFS, applies transformations and aggregations, and writes processed data to Apache Iceberg.
- Apache Atlas manages metadata and provides data governance, data discovery, and data lineage capabilities.
- Apache Spark and Apache Superset query data stored in Apache Iceberg.
- Apache Airflow schedules and manages workflows, ensuring that data is processed and queried efficiently.
Benefits
The benefits of this architecture include:
1. Scalability: The architecture is designed to handle large volumes of data and scale horizontally.
2. Real-time Processing: Apache Kafka and Apache Flink enable real-time processing and analysis of data.
3. Batch Processing: Apache Spark enables batch processing of large datasets.
4. Data Visualization: Apache Superset provides data visualization capabilities, enabling users to gain insights into their data.
5. Free and Open-Source: All the tools used in this architecture are free and open-source, reducing costs and increasing flexibility.
6. Data Governance: Apache Atlas provides data governance, data discovery, and data lineage capabilities.
Apache offers a suite of powerful tools that can be used to build a scalable and efficient data architecture. By leveraging Apache NiFi, Apache Kafka, Apache Flink, Apache Spark, Apache Iceberg, Apache Airflow, and Apache Superset, organizations can build a comprehensive data architecture that supports both real-time and batch processing, as well as data querying and visualization. And the best part? All these tools are free and open-source, making it an attractive solution for organizations looking to reduce costs and increase flexibility.
Soon I will be starting a project on this architecture.