Welcome back! In my last post, we explored the three pillars of data systems: reliability, scalability, and maintainability.
You can visit the last chapter from here :
Chapter 1: Foundations of data systems
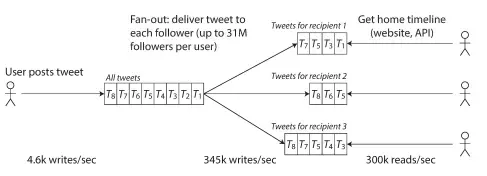
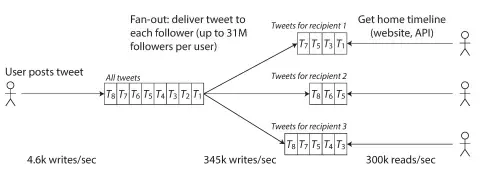
Today, we'll zoom in on one of the trickiest challenges modern social networks face—fan-out—using Twitter as our case study.
"When Cristiano Ronaldo tweets, it needs to reach 100 million in seconds"
What Is Fan-Out?
Fan-out is the process of delivering one message (a tweet) to all of a user's followers.
- If you have 50 followers, fan-out is easy
- If you have 100 million followers, you need special magic
There are two main approaches:
- Fan-Out on Write
- Fan-Out on Read
Approach 1: Fan-Out on Write
(Ideal for "regular" users)
- User posts a tweet
- The tweet is stored in a durable Tweet Store
- A background job pushes that tweet into each follower's Timeline Cache
Read path
- When a follower opens Twitter, their timeline is already pre-filled
- The app just fetches cached tweets—instant display
Why it works
- Fast reads for followers
- Simple ranking and pagination
The Scaling Challenge
Let's break down why this fails for celebrities:
# For 31M followers with 90s delivery SLA
31,000,000 followers / 90 seconds = 344,444 writes/sec
# If 1% of followers check immediately
31,000,000 × 1% = 310,000 reads/secAnd there are more than 4.6k writes/sec system-wide. Now imagine if Ronaldo just dropped a 'hello' on X
Trade-offs
- Write amplification: N writes per tweet (where N = number of followers)
- Doesn't scale to celebrity levels
Approach 2: Fan-Out on Read
(Necessary for mega-stars like Ronaldo)
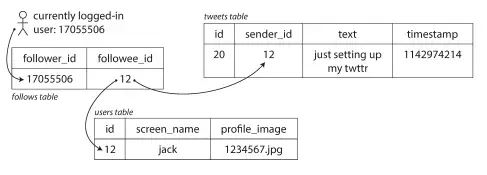
- Celebrity posts a tweet
- Store the tweet once in the tweets table
- When each follower loads their timeline:
- Fetch their personal cache (small fan-out of regular users)
- Dynamically merge the celebrity's tweet on the fly
SELECT t.id,
u.screen_name,
t.text,
t.timestamp
FROM follows f
JOIN tweets t
ON t.sender_id = f.followee_id
JOIN users u
ON u.id = t.sender_id
WHERE f.follower_id = :current_user
ORDER BY t.timestamp DESC
LIMIT 50;Why it's needed
- 1 write per tweet—constant cost
- Handles millions of followers without crashing
Trade-offs
- Slower reads (joins and lookups)
- Harder to cache consistently
Twitter's Hybrid Solution
Twitter combines both strategies:
- Regular users → Fan-Out on Write
- Celebrities → Fan-Out on Read
The Nuanced Reality
Even celebrity tweets use strategic writes for critical followers:
-
First 1M Followers
- Immediate fan-out-on-write to timeline caches
- Targets super-fans most likely to engage immediately
-
Remaining Followers
- True fan-out-on-read via dynamic query merging
- Served through geographically distributed edge caches
# Why this hybrid works
100M followers =
1M (1%) active immediately + 99M (99%) eventual consistencyCore components under the hood:
- Tweet Store: Manhattan (Twitter’s distributed database)
- Timeline Cache: Redis with active replication
- Stream Processing: Heron for batched background jobs
- Rate Limiters: Raven for traffic shaping
Key Lessons for Your Own Systems
1. Segment Users by Follower Count
Why:
- <10k followers: Full fan-out-on-write is safe and fast
- 10k-1M followers: Hybrid approach with write batching
- >1M followers: Primarily fan-out-on-read with edge caching
2. Precompute vs Compute-on-Demand
Balance:
- Precompute: Timeline caches, trending lists, follower graphs
- Compute live: Celebrity tweets, search results, archived content
Rule of Thumb:
"Cache what 80% of users will see immediately. Compute what 20% might request later."
3. 99th-Percentile Latency Focus
Why It Matters:
- Average latency hides worst-case scenarios
- 1% slow requests = 3.6M unhappy users/hour (at 100k RPS)
Prioritization:
- Ensure 95% requests complete in <100ms
- Optimize until 99% <200ms
- Let 1% (edge cases) degrade gracefully
4. Hot/Warm/Cold Data:
- Hot: In-memory cache (last 3h tweets)
- Warm: SSD storage (3h-7d tweets)
- Cold: HDD/tape (archival)
"There are no solutions, only trade-offs. The art is balancing write costs vs read complexity."
What's Next?
In the next post, I'll dive into data modeling and query languages—because fast fan-out needs a solid home for your data.
Got fan-out horror stories? Or clever caching tricks? Share them in the comments below! 🚀