I recently had to populate a DynamoDB table with over 740,000 items as part of a migration project. I tried three different approaches to see what would give me the best mix of speed, cost, and operational sanity. I’m sharing what I learned here in case you’re facing the same question: “What’s the best way to load a large amount of data into DynamoDB?”
Spoiler: Step Functions with batched Lambda invocations is the winner — but the path to that conclusion was full of interesting surprises.
Before You Go Too Far...
If your data is stored in S3 as a CSV or JSON file, and you're looking for a simple, no-code solution to load it directly into DynamoDB, AWS offers an out-of-the-box option. You can use the DynamoDB Data Import feature from the S3 console to create a table and populate it from your S3 bucket with minimal effort.
This feature is ideal if you don't need custom pipelines or complex data transformations. You simply upload your data, configure the table, and let DynamoDB handle the rest.
For more details on this feature, check out the official documentation: DynamoDB S3 Data Import.
If that fits your use case, this post might be more than you need — feel free to stop here.
The Setup
I needed to insert 740,000 items into DynamoDB from a CSV file as part of a migration. Each item was under 1KB, which meant write capacity usage stayed predictable and efficient. I tested:
- An AWS Glue Job using Apache Spark.
- A Step Function with distributed map writing items directly via
PutItem. - A Step Function batching 1,000 items per state, passed to a Lambda using
BatchWriteItem.
Here’s what I found.
Benchmark Results
| Method | Time to Load 740K Items | Cost | Notes |
|---|---|---|---|
| Glue Job | ~12 minutes | ~$2.1 | Good for large files & data transformation |
| Step Function + Direct DynamoDB | ~120 minutes | ~$18.5 | Every item is a state transition — ouch |
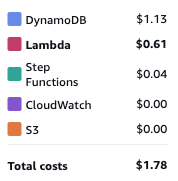
| Step Function + Lambda Batches | ~5 minutes | ~$1.78 | Fastest and cheapest with high configurability |
Option 1: Glue Job
Glue is great when you’re dealing with S3-based batch inputs or doing big ETL-style transformations. I used 10 Data Processing Units (DPUs), and the job finished in about 12 minutes.
Summary:
- ⏩ Fast & Scalable
- ⚙️ Great for data transformation
- 💰 Charged for minimum run time of 1-minute
- 🤓 Some Apache Spark knowledge required
It’s a solid option for large datasets, especially if you already have some experience with Glue. Note that for smaller datasets, you'll still be charged for at least 1-minute processing time, even if the job finishes in under a minute.
Option 2: Step Function with Direct DynamoDB Writes
This was by far the simplest implementation — just feed the items into a distributed map and call PutItem on each one. You can also easily configure the concurrency of this step, but be careful about your DynamoDB table's write capacity, or you could get throttled.
Unfortunately, there’s no simple way to batch the items up and use BatchWriteItem directly. Serverless Land has created a workflow to do it, which you can find here.
I tested a similar approach, but it was slower for large datasets due to more state transitions. I imagine for a small enough dataset, this could be a great solution.
However, with the large dataset in my case, it was painfully slow and surprisingly expensive. Even just loading the CSV file from S3 took a long time, plus I hit issues with the state payload input/output being too large.
Summary:
- 🕓 Took more than 2 hours to write the data
- 💸 Cost almost $20 because each item is a Step Function state transition ($0.025 per 1,000 transitions adds up quickly)
Simple? Yes. Scalable? Not really.
Option 3: Step Function with Lambda Batches
Here’s where things got good. I batched the input into chunks of 1,000 items using Step Functions' distributed map, then handed each batch off to a Lambda. That Lambda used BatchWriteItem in a loop to write in chunks of 25 (the max per batch write). I ran the Lambda task with a concurrency of 20, but you can adjust this based on your table's write capacity units.
With this setup:
- 🚀 Completed in ~5 minutes
- 💵 Cost only $1.78 total
- 🔁 Batch size of 1,000 kept SFN transitions and Lambda invocations low
- 🛠 Full control over retries, unprocessed items, and logging
The Lambda had 2GB of memory and finished each batch in ~100ms. Total compute cost was therefore very small.
The Final Take
If you’re bulk-loading a DynamoDB table:
- Use Step Functions + Lambda + batch writes if you want the best combo of speed, cost, and control.
- Use Glue if your data is already in S3 or you need transformations.
- Avoid direct DynamoDB tasks in Step Functions unless your item count is small.
The sweet spot seems to be letting Step Functions handle parallelism and letting Lambda do the writing in batches.
This setup scaled cleanly to over 740K items with no issues and minimal cost.
Considerations
DynamoDB Write Capacity Considerations
In terms of DynamoDB write capacity, I ended up using on-demand mode and just made sure I retried enough times when being throttled — and I was throttled. If you want, you can set the table to have appropriate provisioned write capacity. Here's a rough way to calculate the units:
Required WCUs = (Items per second) × (Item size in KB, rounded up)For example, in my case, I am running 20 Lambdas concurrently, each writing batches of 25 items. Each batch write takes around 100ms. This means:
Items per second = 250 items per second × 20 concurrency = 5000 items per secondSo, applying the formula:
Required WCUs = 5000 (items per second) × 1 (item size in KB)Therefore, a write capacity of 5000 WCUs would have been ideal to avoid throttling.
In my case, i.e. with on-demand I was throttled quite a bit at first but as the capacity scaled up things settled:
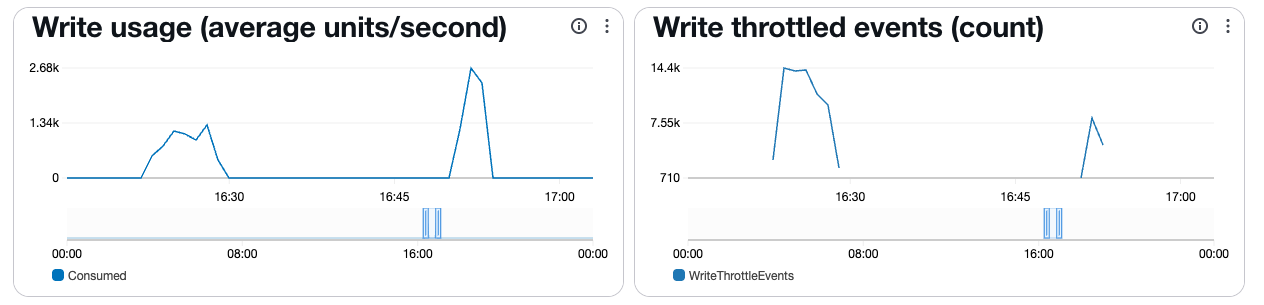
Noting here that I ran this in 2 batches of ~300k
TL;DR
- Don’t underestimate the per-transition cost of Step Functions.
- DynamoDB is a beast.
- Batch everything.
- Lambda + Step Functions = powerful combo when tuned right.
Hope this helps you avoid a few hours of experimenting. 🙂
Stay tuned for a follow-up post which will include all the code I used achieve this!