To harness the power of data for decision-making, businesses rely on data management architectures like data warehouses and data lakes. While both serve as data repositories, they cater to different use cases, offering unique advantages and challenges. In this evolving landscape, Presto has emerged as a powerful query engine that bridges the gap between data warehouses and data lakes, enabling fast, distributed SQL queries across disparate data sources.
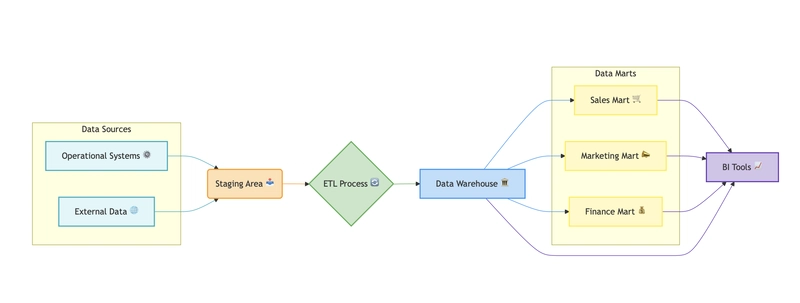
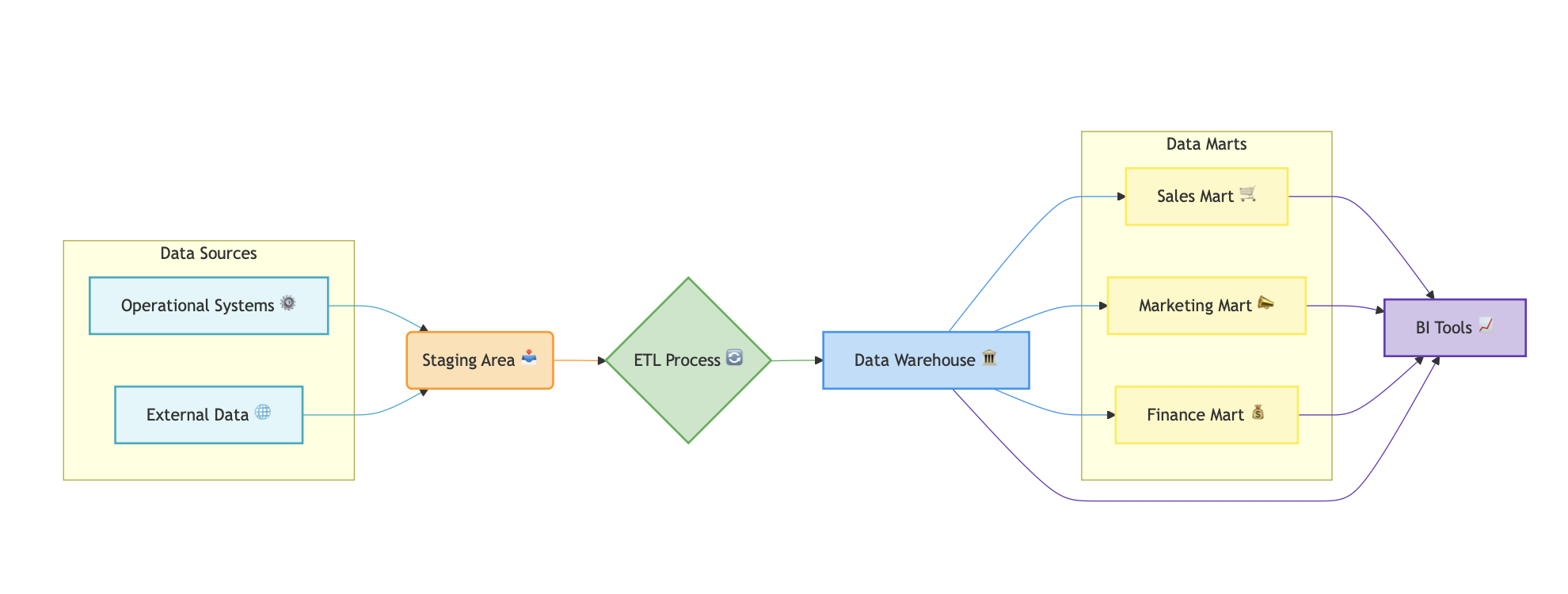
What is a Data Warehouse? (🏛️ -> 🛢️+🛢️+🛢️)
A data warehouse is a structured repository designed for analytical processing and reporting. It integrates data from multiple sources, transforms it into a consistent format, and stores it in a structured manner using predefined schemas. Data warehouses are optimized for fast query performance and are widely used for business intelligence (BI), reporting, and analytics.
Key Characteristics of Data Warehouses:
- Structured Data Storage: Data is cleaned, processed, and stored in structured formats, making it easy to query.
- Schema-on-Write: Data must conform to a predefined schema before being stored.
- Optimized for Analytical Queries: Supports complex SQL queries and aggregations for reporting.
- Historical Data Analysis: Designed to store and analyze historical data trends over time.
- Examples: Amazon Redshift, Google BigQuery, Snowflake, etc.
- Supported Data Types: Structured data such as relational databases and transactional data.
What is a Data Lake? (🏛️ -> 🔊+🎬+🗂️+📊+📈)
A data lake is a centralized repository that stores vast amounts of raw, structured, semi-structured, and unstructured data. Unlike data warehouses, data lakes do not enforce a predefined schema, allowing organizations to store data in its native format and process it when needed.
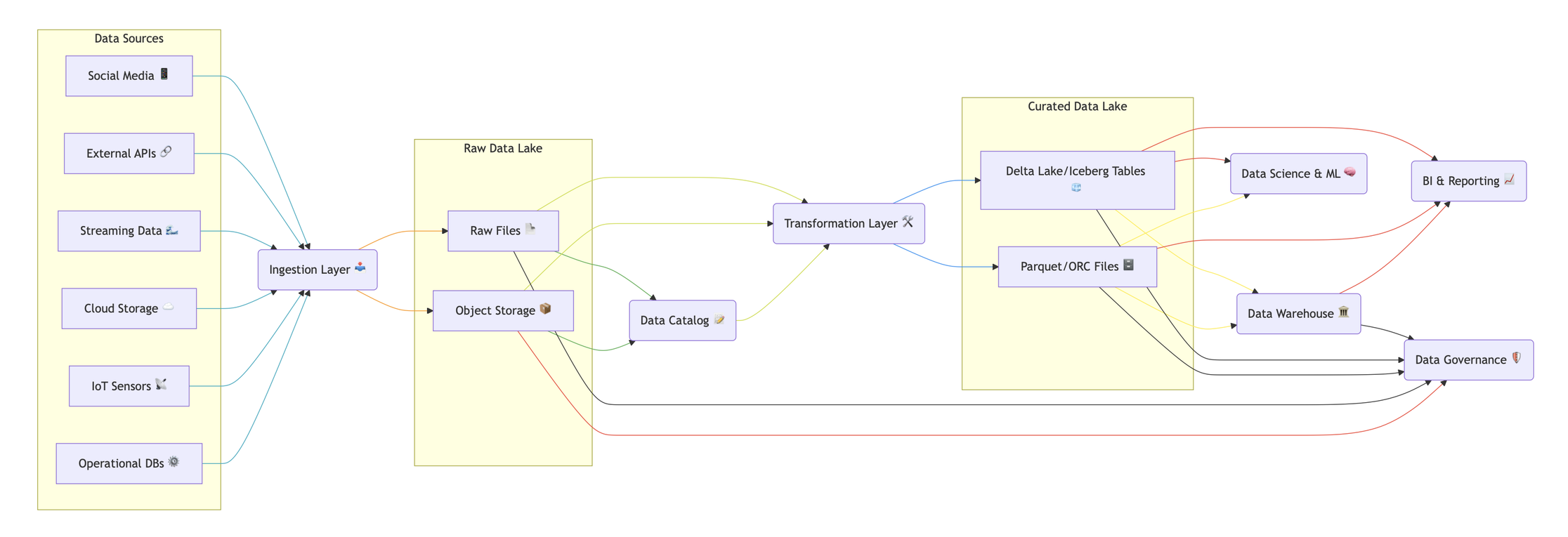
- Data Sources 📚: Where your data comes from (databases, files, etc.).
- Ingestion 📥: Bringing data into the lake.
- Raw Data Lake 🏞️: Stores data in its original form.
- Transformation 🛠️: Cleaning and preparing data.
- Curated Data Lake 📊: Organized data ready for analysis.
- Analysis & ML 📈🧠: Using the data for insights and predictions.
- Data Catalog 📝: Keeps track of your data.
- Governance 🛡️: Ensures data quality and security.
Key Characteristics of Data Lakes:
- Schema-on-Read: Data is stored in raw form and structured at the time of analysis.
- Supports Diverse Data Types: Can store structured, semi-structured, and unstructured data such as logs, multimedia files, and sensor data.
- Highly Scalable and Cost-Effective: Built on cloud-based storage systems that allow massive scalability.
- Flexible Analytics: Supports machine learning (ML), big data analytics, and real-time processing.
- Examples: Amazon S3 (with AWS Lake Formation), Azure Data Lake, Google Cloud Storage, Apache Hadoop.
- Supported Data Types: Structured (relational databases), semi-structured (JSON, XML, CSV), and unstructured (images, videos, IoT sensor data, social media feeds, logs).
Note: Presto has the ability (💪) to query data from both warehouses and lakes without data movement or duplication.Follow Presto at Official Website, Linkedin, Youtube, and Slack channel to join the community.
