
Machine Learning คือ เทคโนโลยีที่ช่วยให้คอมพิวเตอร์สามารถเรียนรู้จากข้อมูลและทำการตัดสินใจได้ด้วยตนเอง หนึ่งในวิธีที่ได้รับความนิยมในการวิเคราะห์ข้อมูลคือการใช้โมเดลต้นไม้ เช่น Decision Tree และ Random Forest บทความนี้จะพาไปทำความเข้าใจหลักการทำงานของทั้งสองเทคนิค พร้อมแสดงตัวอย่างโค้ด Python และการประยุกต์ใช้งานจริง
ในโลกของข้อมูลขนาดใหญ่และการตัดสินใจอย่างรวดเร็ว Machine Learning ได้เข้ามามีบทบาทสำคัญ โดยเฉพาะในด้านการทำนาย เช่น พฤติกรรม การแบ่งประเภท และการวิเคราะห์แนวโน้มของข้อมูล
บทความนี้นำเสนอเทคนิคพื้นฐาน 2 แบบ คือ
Decision Tree
Random Forest
ทั้งสองเทคนิคจัดอยู่ในกลุ่ม Supervised Learning ซึ่งหมายถึงโมเดลที่เรียนรู้จากข้อมูลที่มี
"คำตอบ" อยู่แล้ว (เช่น ข้อมูลลูกค้าที่ซื้อ/ไม่ซื้อ, ผู้ป่วยที่เป็น/ไม่เป็นโรค ฯลฯ)
หลักการของ Decision Tree และ Random Forest
Decision Tree : เป็นโมเดลที่ใช้โครงสร้างแบบต้นไม้ในการตัดสินใจ โดยแบ่งข้อมูลออกเป็นส่วนย่อย ๆ ตามเงื่อนไขต่าง ๆ ที่ลดความไม่แน่นอนให้มากที่สุด สามารถใช้งานได้ทั้ง Classification และ Regression
การเลือกแยกข้อมูลจะใช้เกณฑ์อย่าง Gini Impurity หรือ Entropy เพื่อหาค่าที่ดีที่สุดในการแบ่งข้อมูล
Random Forest : เป็นการรวมโมเดล Decision Tree หลาย ๆ ต้นเข้าด้วยกัน (Ensemble Learning) แล้วใช้การโหวตจากหลายต้นไม้เพื่อลดความเอนเอียง (Bias) และความแปรปรวน (Variance)
จะมีการสุ่มเลือก feature และ subset ของข้อมูล (Bootstrapping) เพื่อฝึกแต่ละต้นไม้ ทำให้ผลลัพธ์โดยรวมมีความเสถียรกว่า
จุดเด่นของ Decision Tree:
เข้าใจง่าย มองภาพการตัดสินใจเป็นขั้น ๆ ได้
ทำงานได้ทั้งข้อมูลจำแนกประเภท (Classification) และตัวเลข (Regression)
จุดเด่นของ Random Forest:
รวมหลาย Decision Tree เข้าด้วยกัน ทำให้ลดการ Overfitting
มีความแม่นยำสูง ใช้งานได้ในระบบจริง
ตัวอย่างการใช้งานจริง
การแพทย์: ใช้ Random Forest เพื่อวิเคราะห์ความเสี่ยงโรคเรื้อรัง เช่น เบาหวาน หรือหัวใจ
การเงิน: ใช้ Decision Tree สำหรับวิเคราะห์เครดิต หรืออนุมัติวงเงินกู้
อีคอมเมิร์ซ: ใช้ Random Forest เพื่อสร้างระบบแนะนำสินค้า หรือวิเคราะห์โอกาสในการซื้อซ้ำ
เกษตรกรรม: ใช้ Decision Tree เพื่อพยากรณ์ผลผลิตจากสภาพแวดล้อมและดิน
การเปรียบเทียบ Decision Tree และ Random Forest

การเรียกใช้ไลบรารี ที่จำเป็นจาก scikit-learn
load_iris() โหลดชุดข้อมูลดอกไม้ Iris
DecisionTreeClassifier และ RandomForestClassifier ใช้สร้างโมเดล
train_test_split() แบ่งข้อมูล
accuracy_score() ใช้วัดความแม่นยำของโมเดล

แบ่งข้อมูลออกเป็น 70% สำหรับฝึก และ 30% สำหรับทดสอบ
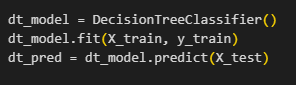
สร้าง Decision Tree และ ทำนาย

สร้าง Random Forest โดยใช้ต้นไม้ 100 ต้น

แสดงผลลัพธ์ความแม่นยำของทั้งสองโมเดล
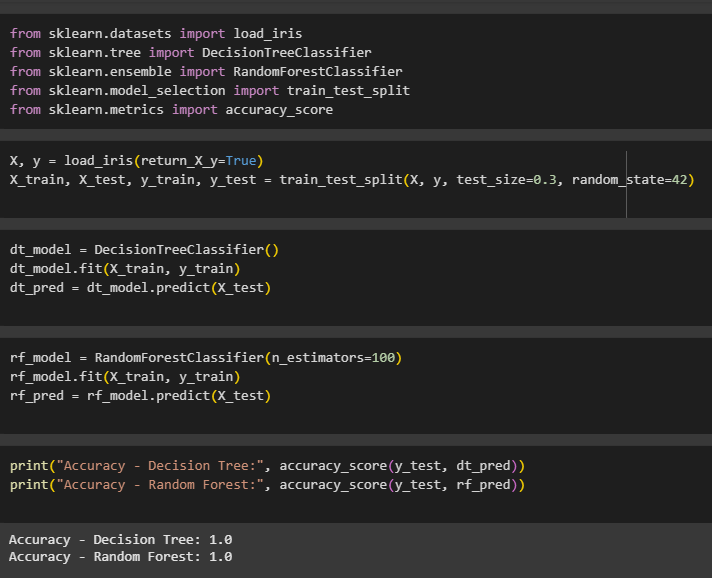
หลังจากทดสอบ ข้อมูล Iris dataset และทำการทดสอบกับชุดข้อมูล X_test พบว่า ทั้งโมเดล Decision Tree และ Random Forest ให้ค่าความแม่นยำ (Accuracy) เท่ากับ 1.0 หรือ 100%
นั่นหมายความว่าโมเดลสามารถทำนายข้อมูลในชุดทดสอบได้ถูกต้องทั้งหมด
ตัวอย่างการประยุกต์ใช้งานจริง
ในตัวอย่างนี้ เราจะจำลองสถานการณ์ของเว็บไซต์ขายสินค้าออนไลน์ที่ต้องการทำนายว่าลูกค้าจะซื้อสินค้าหรือไม่จากพฤติกรรมการใช้งาน โดยใช้ขั้นตอนดังนี้:
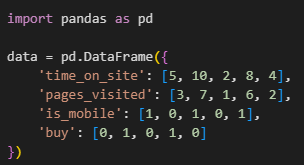
ขั้นตอนที่ 1: เตรียมข้อมูลตัวอย่าง
ขั้นตอนที่ 2: แยกข้อมูลคุณลักษณะ (features) และผลลัพธ์ (target)

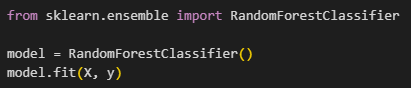
ขั้นตอนที่ 3: สร้างโมเดล Random Forest
ขั้นตอนที่ 4: ทำนายลูกค้าใหม่

ผลลัพธ์คือโมเดลจะทำนายว่าลูกค้าใหม่นั้นมีแนวโน้มจะซื้อหรือไม่ โดยอ้างอิงจากพฤติกรรมของลูกค้าคนก่อนหน้า (ซึ่งในกรณีโค้ดตัวอย่างนี้ผลลัพธ์การทำนาย คือ ไม่ซื้อ)
สรุป
Decision Tree และ Random Forest เป็นเครื่องมือพื้นฐานที่มีประสิทธิภาพในการวิเคราะห์ข้อมูล และเหมาะสำหรับผู้เริ่มต้นศึกษา Machine Learning เนื่องจากเข้าใจง่ายและใช้งานได้หลากหลาย การเรียนรู้และทดลองด้วยโค้ดจริงจะช่วยให้เข้าใจแนวคิดเบื้องหลังของอัลกอริธึมเหล่านี้ได้ลึกซึ้งยิ่งขึ้น
ในงานจริง การเลือกใช้ระหว่าง Decision Tree หรือ Random Forest ขึ้นอยู่กับวัตถุประสงค์ ความซับซ้อนของข้อมูล และความต้องการในการอธิบายผลลัพธ์ต่อผู้ใช้งาน เช่น:
หากต้องการ "โมเดลที่ตีความง่าย" → ใช้ Decision Tree
หากต้องการ "โมเดลที่แม่นยำสูงกว่า แม้ซับซ้อน" → ใช้ Random Forest
ทุกคนสามารถลองสร้าง ลองทดสอบเล่นๆกันได้นะครับ 👏👏
Reference
https://scikit-learn.org/stable/modules/tree.html
https://scikit-learn.org/stable/modules/ensemble.html#random-forests
https://realpython.com/decision-tree-classifier-python/


