เริ่มแรก Decision Tree และ Random Forest นั้นคือะไร?
Decision Tree คือ Machine Learning แบบ Supervised Learning ที่ใช้สำหรับ Classification และ Regression โดยใช้โครงสร้างแบบต้นไม้ โดยใช้ Information Gain และ Entropy ในการแยกข้อมูล ซึ่งมีโครงสร้างแบบราก-กิ่ง-ใบ
หลักการทำงาน
- แต่ละ "node" ในต้นไม้จะใช้คุณลักษณะ (feature) หนึ่งในการแบ่งข้อมูล
- ใช้หลักการ Entropy และ Information Gain ในการเลือกว่าจะใช้ feature ไหนในการ แบ่งข้อมูลเพื่อให้ได้กลุ่มที่บริสุทธิ์ที่สุด (pure group)
- Terminal node (leaf) แสดงผลลัพธ์ที่คาดการณ์ได้ *ตัวอย่าง * ถ้ามีข้อมูลผู้โดยสารและต้องการทำนายว่าเขาจะรอดหรือไม่จาก เรือเซวอล ระบบจะเลือก feature ที่ดีที่สุด เช่น sex, age, class ในการแยกกลุ่ม
Random Forest คือ Ensemble Learning ที่รวม หลายๆ Decision Tree เข้าด้วยกัน เพื่อเพิ่มความแม่นยำและลด overfitting ใช้วิธี bootstrap และ random selection ของ feature โดยตัดสินใจโดยการ vote หรือ average จากหลายต้นไม้
หลักการทำงาน
- สร้างหลายต้นไม้โดยใช้การ Bootstrap Sampling
- ที่แต่ละ node จะ เลือก feature มาแบบสุ่ม เพื่อหาการแบ่งที่ดีที่สุด
- ใช้วิธี Voting สำหรับ classification และ Averaging สำหรับ regression
แล้วความแตกต่างระหว่าง Decision Tree กับ Random Forest เป็นอย่างไร?
1.วิธีการสร้าง
Decision Tree - สร้างต้นไม้เดียวแบบลำดับชั้น
Random Forest - สร้างหลายต้นไม้ด้วยการสุ่มข้อมูลและ feature
2.ความแม่นยำ
Decision Tree - ความแม่นยำน้อยกว่า มีโอกาส overfitting
Random Forest - มีความแม่นยำกว่า มีความเสถียรกว่า
3.ความซับซ้อน
Decision Tree - เข้าใจง่ายกว่า
Random Forest - ซับซ้อนกว่า (เพราะ Decision Tree นั้นมีเพียงต้นไม้เดียว แต่ Random Forest จะสร้างหลายๆ ต้นไม้ (อาจจะ 100, 500, หรือ 1000 ต้นก็ได้) นั่นจึงทำให้กระบวนการภายใน ซับซ้อนขึ้นกว่าแค่ต้นไม้เดียว)
4.เวลาในการ train model
Decision Tree - เร็วกว่า
Random Forest - ช้ากว่า เนื่องจากมีหลายต้นไม้
การทำงานของ code ของ Decision Tree และ Random Forest นั้นเป็นอย่างไร รันแล้วจะมีผลลัพธ์อย่างไร
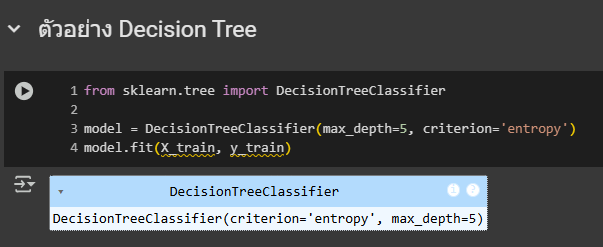
1.การใช้ Decision Tree **
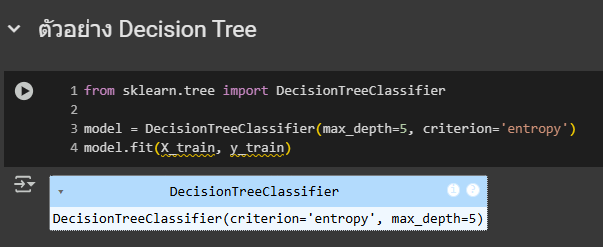
**อธิบายโค้ด
- DecisionTreeClassifier คือ ตัวที่เอาไว้สร้างโมเดลต้นไม้
- max_depth=5 คือ จำกัดความลึกของต้นไม้ที่ระดับ 5 (เพื่อป้องกัน overfitting)
- criterion='entropy' คือ การใช้ Entropy (Information Gain) ในการเลือก
- feature ที่ใช้แบ่งข้อมูล
- fit(X_train, y_train) คือ การฝึกโมเดลด้วยข้อมูลเทรน
2.การใช้ Random Forest
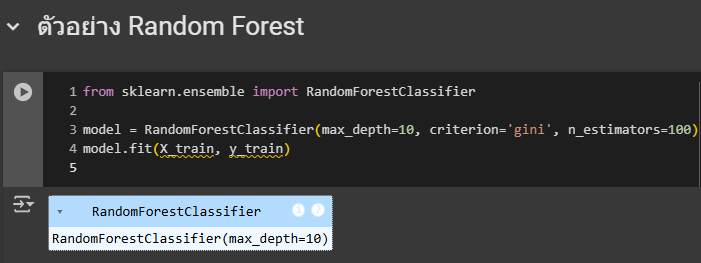
อธิบายโค้ด
- RandomForestClassifier คือ ตัวที่สร้างโมเดล Random Forest
- n_estimators=100 คือ สร้าง 100 ต้นไม้ นั่นจะทำให้โมเดล เรียนรู้จากหลายมุมมอง
- max_depth=10 คือ จำกัดความลึกของแต่ละต้นไม้ไว้ที่ 10
- criterion='gini'คือ ใช้ Gini Impurity แทน Entropy ในการแยกข้อมูล
- fit(X_train, y_train)คือ ฝึกโมเดลด้วยข้อมูลเทรนเช่นกัน
ตัวอย่างโค้ด https://colab.research.google.com/drive/1SePz7Es0w9FRJDbsE3xM0CCnH7NkpdPZ?usp=sharing
ตัวอย่างการรันใช้งาน
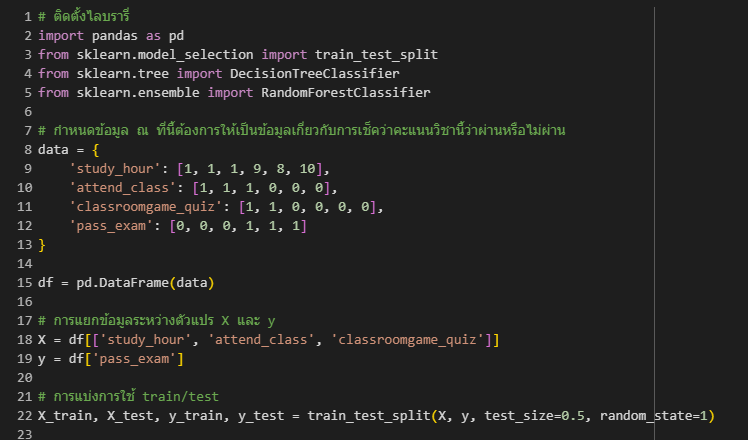
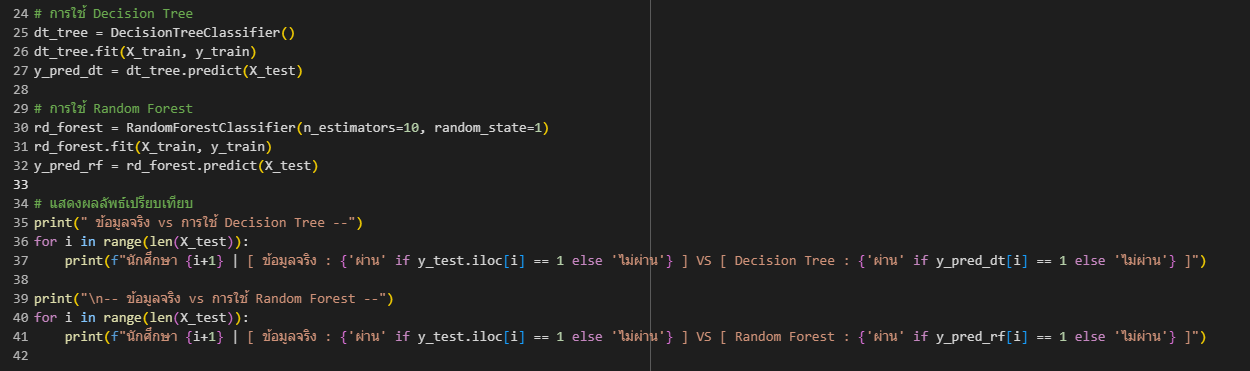
จากตัวอย่างโค้ดจะใช้ตัวอย่างในการเทนโมเดลทั้งคู่ให้ทำนายหรือเดาว่าผลลัพะ์ที่ได้นั้นจะตรงกับข้อมูลจริงหรือไม่ โดยเราได้กำหนด ชั่วโมงที่เรียน (study_hour), เช็คชื่อเข้าเรียน(attend_class), ควิซตอบคำถามท้ายชั่วโมงเรียน (classroomgame_quiz) ในการแยกกลุ่ม และเช็คว่าผ่านหรือไม่ผ่านโดยการใช้ข้อมูล(pass_exam) จากนั้นมีการใช้โมเดลของ Decision Tree และ Random Forestในการเดาหรือทำนายนั่นเอง

จากผลลัพธ์ที่ออกมาแสดงให้เห็นว่าการใช้ Decision Tree นั้นทายถูกจาก2ใน3 มีความแม่นยำน้อยกว่า เนื่องจากอาจมีการเกิด overfitting ในขณะที่ Random Forest นั้นทายถูกหมด เนื่องจากมีความแม่นยำและความเสถียรที่สูงกว่า
ตัวอย่างโค้ด https://colab.research.google.com/drive/1FvHGyjtBI0NshNQs8K14_QoFq3MzyoyQ?usp=sharing
สรุป
ถ้าต้องการโมเดลที่เข้าใจง่าย ควรใช้ Decision Tree เพราะโครงสร้างที่อ่านแล้วจะสามารถเข้าใจได้ง่าย แต่ต้องระวังเรื่อง overfitting เพราะตัวโมเดลจะเรียนรู้จากข้อมูลเยอะเกินไปได้ง่าย ส่วน Random Forest จะซับซ้อนกว่า เพราะใช้ Decision Tree หลายต้นรวมกัน ทำให้แม่นยำกว่าและทนกับข้อมูลแปลกๆ ได้ดี แต่ก็อาจจะใช้เวลาฝึกที่นานกว่าและอธิบายผลลัพธ์ยากขึ้น เลือกใช้ให้เหมาะกับงาน ถ้าเน้นความเข้าใจ ใช้ Decision Tree ถ้าเน้นความแม่น ใช้ Random Forest


