
Language detection หรือ ตรวจจับภาษา เมื่อเราต้องการรู้ว่า ภาษาที่เราเจอเนี่ย มันคือภาษาอะไรกันแน่น้า? เช่น เราอาจจะมีความสับสนระหว่าง คันจิภาษาญี่ปุ่น และ อักษรภาษาจีน??😵💫 language detection ก็สามารถช่วยเราแยกได้นั่นเองค่ะ
ซึ่งวันนี้เราจะมาลองใช้ Learning Machine ตรวจจับภาษา โดยใช้ Python และ เพิ่มฟีเจอร์การแปลภาษา ด้วยกันนะคะ
สิ่งที่เราขาดไม่ได้เลยคือ ข้อมูล(Data) ค่ะ ยิ่งมีข้อมูลเยอะ โมเดลก็จะแม่นยำขึ้นมากๆค่ะ
ชุดข้อมูลที่เราจะลองเอามาทำกันวันนี้มาจาก Kaggle ค่ะ ในนี้จะมีข้อมูลภาษา 22 ภาษายอดนิยม แต่ละภาษาจะมีจำนวน 1,000 ประโยคค่ะ ซึ่งข้อมูลนี้เหมาะมากๆที่จะฝึกโมเดลค่ะ
Data from Kaggle
1.เริ่มต้นด้วยการ นำเข้าLibraryที่จำเป็นใน python และ โหลดชุดข้อมูลของเรากัน
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
data = pd.read_csv("https://raw.githubusercontent.com/amankharwal/Website-data/master/dataset.csv")
print(data.head())
2.เรามาดูกันว่า ในชุดข้อมูลนี้มีค่าเป็น Null อยู่หรือป่าว?🤔
data.isnull().sum()
3.ลองเช็คดูหน่อยว่า ตอนนี้ชุดข้อมูลนี้มีภาษาอะไรบ้างง
data["language"].value_counts()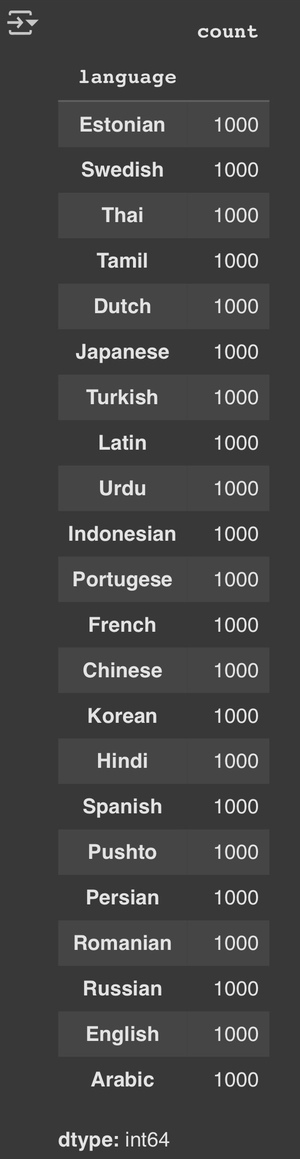
ชุดข้อมูลนี้มีความ balance มาก และ ไม่มีค่าที่หายไปเลย พร้อมใช้งานสำหรับการฝึกแล้ว!
4.Language Detection Model
ตอนนี้เราจะแยกข้อมูลออกเป็น training set และ test set ค่ะ
x = np.array(data["Text"])
y = np.array(data["language"])
cv = CountVectorizer()
X = cv.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.33,random_state=42)เพราะว่าเราต้องการ จำแนกหลายคลาส(Multiclass Classification) โดยจะใช้ Multinomial Naïve Bayes ช่วยแก้ไขปัญหาที่ความถี่ของคำในแต่ละภาษา/คลาส เยอะๆ เพื่อคำนวณความน่าจะเป็นว่า ข้อความใหม่ๆ ที่เข้ามา มีแนวโน้มจะอยู่ในภาษาใด
model = MultinomialNB()
model.fit(X_train,y_train)
model.score(X_test,y_test)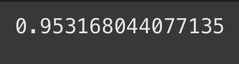
5.ตอนนี้เราใช้ model นี้ เพื่อ detect ภาษา ได้แล้วค่ะ ให้ผู้ใช้กรอกข้อความได้เลยย!
user = input("Enter a Text: ")
data = cv.transform([user]).toarray()
output = model.predict(data)
print(output)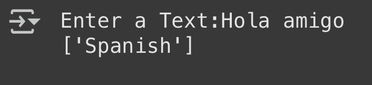
จากผลลัพธ์นะคะ เห็นได้ชัดว่า Model นี้ ทำงานได้ แต่ว่ามันสามารถตรวจจับได้เฉพาะประโยค/คำหรือภาษาที่มีอยู่ในชุดข้อมูลเท่านั้น
เพิ่ม Translation
ลองมาทำให้มัน เพิ่มการแปลของข้อความที่ผู้ใช้ป้อนเข้ามา ก็น่าจะดีนะ🫠 (สามารถทำต่อจาก detect ได้เลยน้า)
ตัวอย่างนี้จะใช้ library ของ Google Translate API เพราะใช้ง่ายและฟรีด้วยค่ะ 😋
1.ติดตั้ง library ก่อนนะ
pip install googletrans==4.0.0-rc12.เพิ่ม LANGUAGES เป็น library ที่จะช่วยให้เราเขียน key ของภาษาได้ง่ายขึ้น เช่น { 'en': 'english', 'th': 'thai', ... } เอาไว้ใช้ดูเฉยๆ ว่า จะแปลเป็นภาษาไหนค่ะ
from googletrans import LANGUAGESprint("🔤 Languages available for translation:") #ภาษาที่สามารถแปลได้มีอะไรบ้าง
for code, name in LANGUAGES.items():
print(f"{code} = {name.capitalize()}")รับ input จากผู้ใช้ว่าอยากแปลเป็นภาษาอะไร
lang_code = input("\nEnter target language code (e.g., en, th, fr): ").strip()
3.สร้าง object จาก class Translator
translator = Translator()4.สั่งให้แปลข้อความ user ที่เขากรอกมาตอน detect ก่อนหน้านี้ค่ะ
ผลลัพธ์จะถูกเก็บไว้ในตัวแปร translated ซึ่งเป็น object ที่มีข้อมูลของ
translated.text = ข้อความที่แปลแล้ว
translate.src = ภาษาต้นฉบับที่ระบบตรวจจับได้
นั่นเองง!!
translated = translator.translate(user, dest=lang_code)5.แสดงผลลัพธ์ข้อความที่ถูกแปลแล้วออกมา
print(f"Translated to [{lang_code}]:", translated.text)
สรุปผล
สำหรับบทความนี้ เราสามารถสร้างโมเดลตรวจจับภาษาได้ด้วย Machine Learning โดยใช้ Python และข้อมูลที่เหมาะสมค่ะ และเมื่อนำไปทำงานร่วมกับ Google Translate API ก็สามารถแปลข้อความเป็นภาษาต่าง ๆ ได้อย่างง่ายดายเลยค่ะ การทดลองนี้เหมาะสำหรับผู้เริ่มต้นที่อยากฝึกทำ และต่อยอดสู่แอปพลิเคชันจริงได้ในอนาคตคค่ะ
ref : (https://thecleverprogrammer.com/2021/10/30/language-detection-with-machine-learning/)
colab


