Using Docling enrichment features!
Introduction
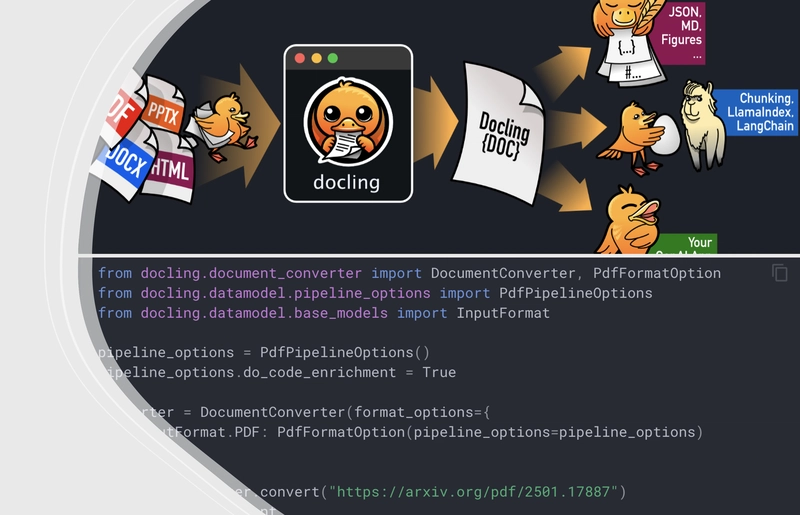
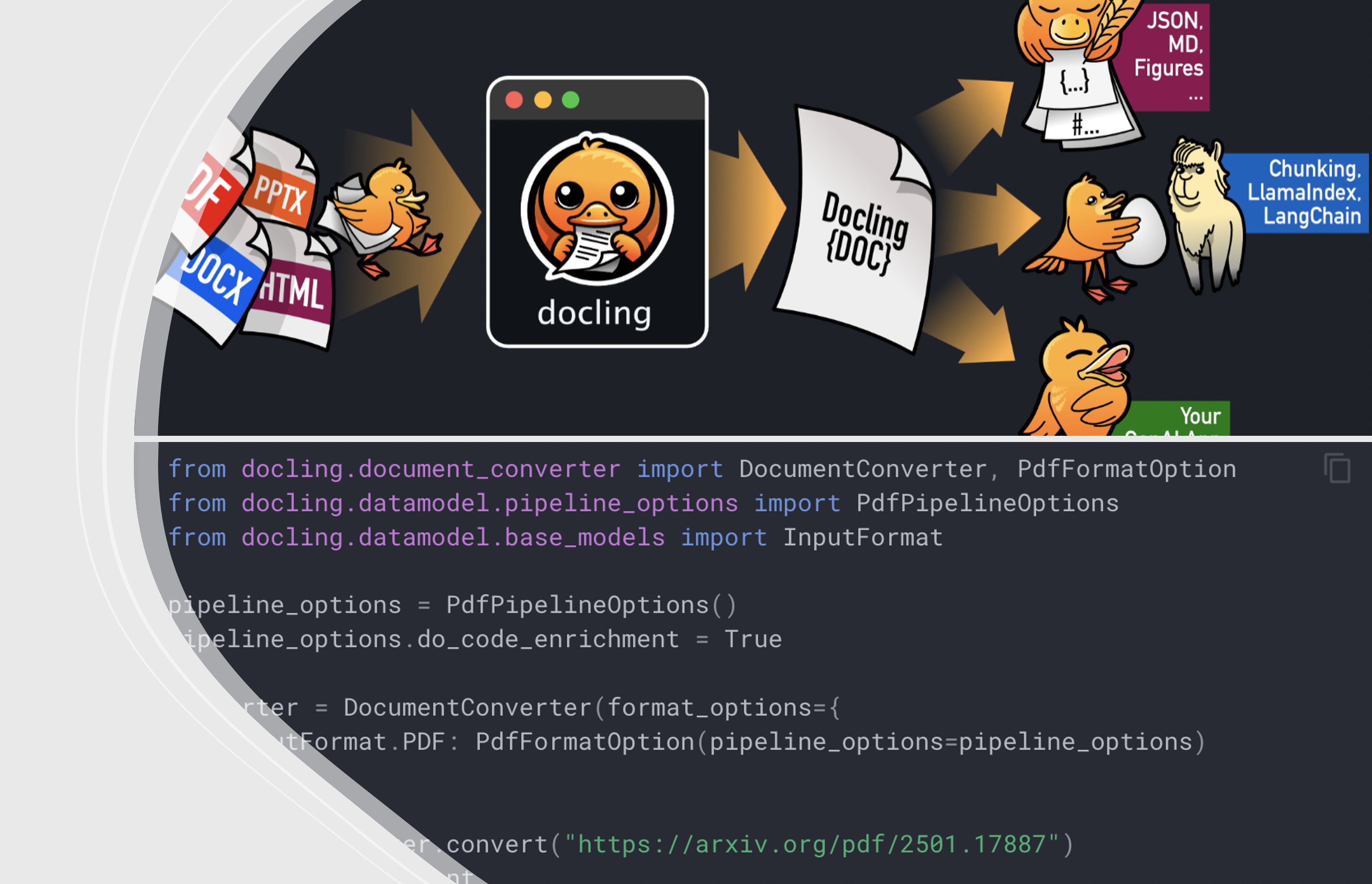
Docling simplifies document processing, parsing diverse formats — including advanced PDF understanding — and providing seamless integrations with the gen AI ecosystem. In short, Docling prepares any types of documents for AI 🦾!
Among other features, Docling allows to enrich the conversion pipeline with additional steps which process specific document components, e.g. code blocks, pictures, etc. The extra steps usually require extra models executions which may increase the processing time consistently. For this reason most enrichment models are disabled by default.
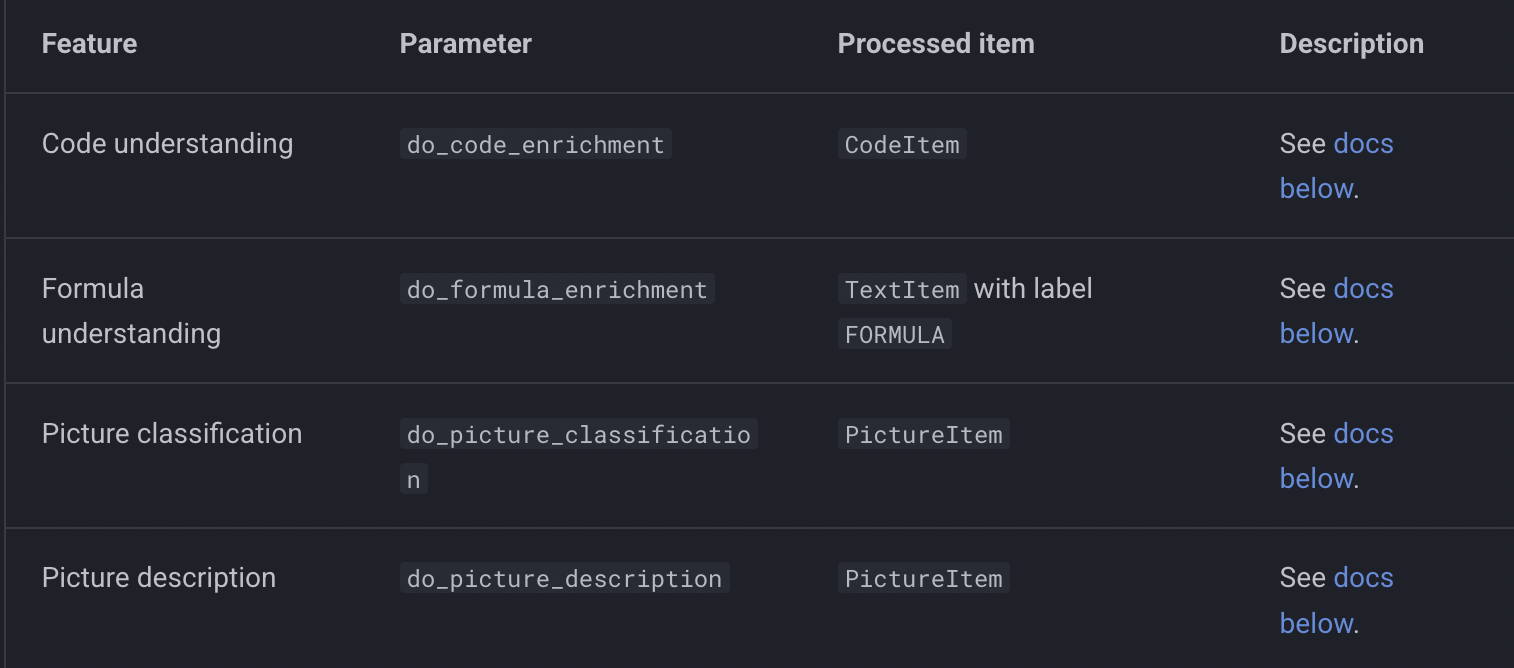
The documentation for the features above are available on Hugging Face. for example;
- ds4sd/DocumentFigureClassifier: https://huggingface.co/ds4sd/DocumentFigureClassifier
- ds4sd/CodeFormula: https://huggingface.co/ds4sd/CodeFormula
Using and implementation
Implementing the enrichment features is quite straightforward and examples are provided.
docling --enrich-code FILEfrom docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.pipeline_options import PdfPipelineOptions
from docling.datamodel.base_models import InputFormat
pipeline_options = PdfPipelineOptions()
pipeline_options.do_code_enrichment = True
converter = DocumentConverter(format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
})
result = converter.convert("https://arxiv.org/pdf/2501.17887")
doc = result.documentBut… for one of my tasks I wanted to discover the “document’s” properties beforehand, because not all documents have all the sections which are described in the documentation!
So I wrote a simple application which extracts the “doc” object properties which I could use for my usage.
- Preparation 👨🍳
python3.12 -m venv myenv
source myenv/bin/activate
pip install --upgrade pip
pip install docling- The main code 🪬
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.pipeline_options import PdfPipelineOptions
from docling.datamodel.base_models import InputFormat
def main():
"""
This Python app demonstrates converting a PDF from a URL using the docling library
with code enrichment enabled and writes the document properties to a Markdown file.
"""
output_filename = "doc_properties.md"
try:
pipeline_options = PdfPipelineOptions()
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2
pipeline_options.do_picture_classification = True
converter = DocumentConverter(format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)
})
try:
result = converter.convert("https://arxiv.org/pdf/2501.17887")
doc = result.document
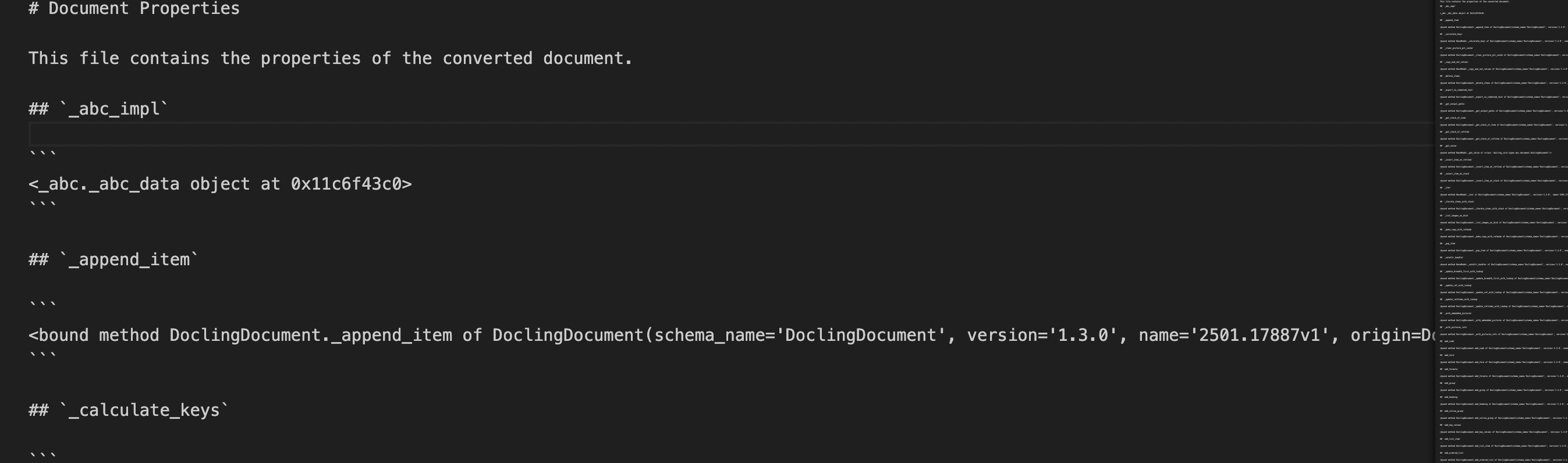
with open(output_filename, "w", encoding="utf-8") as md_file:
md_file.write("# Document Properties\n\n")
md_file.write("This file contains the properties of the converted document.\n\n")
for attr_name in dir(doc):
if not attr_name.startswith("__"):
md_file.write(f"## `{attr_name}`\n\n")
try:
attr_value = getattr(doc, attr_name)
md_file.write(f"```
{% endraw %}
\n{attr_value}\n
{% raw %}
```\n\n")
except Exception as e:
md_file.write(f"*Error accessing property:* `{e}`\n\n")
print(f"\nDocument properties written to '{output_filename}'")
except Exception as conversion_error:
print(f"Error during conversion: {conversion_error}")
except Exception as e:
print(f"An error occurred during setup: {e}")
if __name__ == "__main__":
main()- And the excerpt of the output markdown 📄
Et voilà 🦆
Conclusion
The Docling enrichment features enhance the document conversion process by adding specific processing steps for different document components like code blocks and formulas, enabling advanced parsing and extraction of information such as code language and LaTeX representations, thereby creating a richer and more structured document model.
Links
- Docling: https://github.com/docling-project/docling
- Docling documentation and samples: https://docling-project.github.io/docling/
- Docling Enrichment Features: https://docling-project.github.io/docling/usage/enrichments/


