Introduction
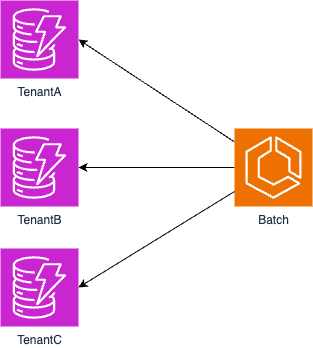
Recently, I had the opportunity to implement batch processing using Go in a multi-tenant application.
The architecture was structured as follows: Each tenant had its own database table, and batch processing needed to be performed for each tenant individually.
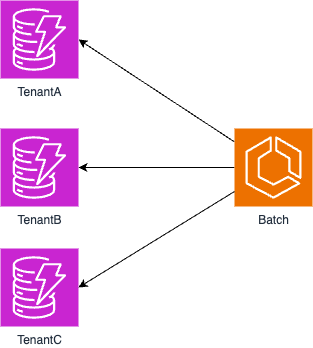
Processing sequentially would result in increasingly longer processing times as the number of tenants grew.
Since such IO-bound operations typically benefit from multi-threaded processing, I decided to implement this using Go's concurrency features. This post documents my implementation as a reference.
I've included sample code, but please note that this is meant for illustration purposes only. When applying these patterns to your own projects, make sure to customize them according to your specific use case.
Explaining Concurrent Processing
For applications that require processing large amounts of data or handling numerous I/O operations, concurrent processing is essential.
In multi-tenant systems especially, processing time increases linearly with the number of tenants when done sequentially. By implementing concurrent processing and handling each tenant's data simultaneously, you can significantly reduce overall processing time.
Go provides built-in support for lightweight threads (goroutines) and channels at the language level, allowing you to express complex concurrent operations with concise code.
In this article, I'll introduce an implementation of the worker pool pattern using these features.
Key Components
Go's concurrent processing relies on several key components:
- goroutines
- channels
- sync.WaitGroup
Goroutines and Channels
Go's concurrency model is primarily built on two fundamental elements: goroutines and channels.
Goroutines are Go's lightweight threads, which you can execute in parallel by specifying a function with the "go" statement:
func f(v string) {
fmt.Println(v)
}
func main() {
go f("Hello") // Hello
}When a program runs, a special goroutine called the main goroutine is automatically created and serves as the entry point. The main goroutine can launch other goroutines that run concurrently.
Channels are structures that allow goroutines to communicate with each other. Using channels makes data transfer and synchronization between goroutines straightforward.
Here's an example:
func main() {
ch := make(chan string) // create a channel
go func() {
ch <- "Hello, World!" // send data to the channel
}()
msg := <-ch
fmt.Println(msg) // Hello, World!
}channel<- sends data to the channel. In the code above, "Hello, World!" is sent to the channel.
<-channel receives data from the channel. The code stores the received data in msg, which will contain "Hello, World!".
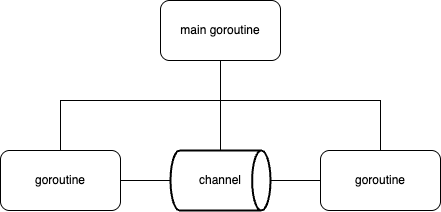
WaitGroup
Goroutines run independently of the main goroutine. When the main goroutine terminates, all other goroutines are forcibly terminated as well.
Therefore, we need to ensure all goroutines complete their execution before the main goroutine ends. In Go, we use sync.WaitGroup to make the main goroutine wait until all workers have completed, preventing premature termination.
WaitGroup has three main methods:
- Add(int): Increases the counter
- Done(): Decreases the counter by 1 (internally calls Add(-1))
- Wait(): Blocks until the counter reaches 0
By combining these simple operations, we can efficiently wait for multiple goroutines to complete.
Here's a sample implementation:
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // Decrease the WaitGroup counter when the work is complete
fmt.Printf("Worker %d starting\n", id)
// Do something
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1) // Increase the counter before launching a worker
go worker(i, &wg)
}
// Wait for all workers to complete
wg.Wait()
fmt.Println("All workers completed")
}The processing flow is as follows:
- Initialize the WaitGroup with
var wg sync.WaitGroup - Increase the counter with
wg.Add(1)before launching a worker - Launch the worker with
go worker(i, &wg) - Decrease the counter with
defer wg.Done()when the worker completes - Wait for all workers to complete with
wg.Wait()
This ensures the main goroutine waits until all workers have finished their tasks.
When using WaitGroup, there are two key best practices to follow to avoid race conditions and unexpected behavior:
Always call Add() before starting a goroutine
If you call Add() inside the goroutine, it might introduce a race condition where Wait() could execute before Add(), leading to incorrect synchronization.
- Good example:
wg.Add(1)
go func() {
defer wg.Done()
// do something
}()- Bad example:
go func() {
wg.Add(1) // This is risky!
defer wg.Done()
// do something
}()Always pass WaitGroup as a pointer
Passing WaitGroup by value creates a copy, and calling Done() on the copy will not affect the original WaitGroup, which causes the main thread to hang indefinitely.
- Good example:
func worker(wg *sync.WaitGroup) {
defer wg.Done()
// do something
}- Bad example:
func worker(wg sync.WaitGroup) {
defer wg.Done() // Since wg is copied from original, this won't decrement the original WaitGroup
// do something
}What is the Worker Pool Pattern?
The worker pool pattern is a common design pattern for concurrent processing. In this pattern:
- Create a queue of jobs
- Launch multiple workers (processing units)
- Workers concurrently fetch and process jobs from the queue
- Wait for all processing to complete using WaitGroup
In our implementation, we'll use channels as the queue and goroutines as the workers.
Code Implementation Explanation
Overall Flow
In the sample code, we retrieve a list of tenant IDs and process the data for each tenant concurrently. Here's a brief explanation of the flow:
- Retrieve a list of tenant IDs
- Determine the number of workers based on CPU cores
- Set up a job channel and workers
- Workers fetch tenant IDs from the job channel and process them
- Wait for all processing to complete
Key Components
1. Worker Pool Setup
tenantIDs := []string{"tenant1", "tenant2", "tenant3"} // a list of tenant IDs
numWorkers := 2 // or appropriate value
logger.Infof("Number of workers: %d", numWorkers)
jobs := make(chan string, len(tenantIDs))
var wg sync.WaitGroup
errChan := make(chan error, numWorkers)This code:
- Gets the number of logical CPU cores using
runtime.NumCPU() - Sets up a job channel, WaitGroup, and error channel
- The WaitGroup ensures the main goroutine waits for all goroutines to complete before terminating the process
2. Launching Worker Goroutines
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
logger.Infof("Worker %d started", workerID)
for {
select {
case tid, ok := <-jobs:
if !ok {
logger.Infof("Worker %d: job queue closed, exiting", workerID)
return
}
processData(tid) // function to process tenant data
case <-ctx.Done():
logger.Infof("Worker %d: context done, exiting", workerID)
return
}
}
}(i)
}This code:
- Each worker runs in its own goroutine
- Adds the worker count to the WaitGroup
- Uses a
selectstatement to monitor for job reception and context cancellation - The worker exits when the job channel is closed or the context is canceled
- Otherwise, it calls the processData function to execute tenant-specific processing
- Finally, notifies of worker completion with
wg.Done()
3. Submitting Jobs
for _, tid := range tenantIDs {
select {
case jobs <- tid:
logger.Infof("Tenant ID %s sent to job queue", tid)
case <-ctx.Done():
logger.Warning("Context done, stopping sending jobs")
break
}
}
close(jobs)This code:
- Sends tenant IDs to the job channel
- Stops sending if the context is canceled
- Closes the channel after sending all jobs
4. Waiting for Completion and Error Handling
waitDone := make(chan struct{})
go func() {
wg.Wait()
close(errChan)
close(waitDone)
}()
select {
case <-waitDone:
// error handling logic
case <-ctx.Done():
logger.Warning("Context done, stopping waiting for workers")
}This code:
- Waits for all workers to complete
- Handles potential interruptions from timeouts or signals
Here's the complete code:
func main() {
ctx := context.Background()
tenantIDs := []string{"tenant1", "tenant2", "tenant3"}
numWorkers := 2 // or appropriate value
logger.Infof("Number of workers: %d", numWorkers)
jobs := make(chan string, len(tenantIDs))
var wg sync.WaitGroup
errChan := make(chan error, numWorkers)
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
logger.Infof("Worker %d started", workerID)
for {
select {
case tid, ok := <-jobs:
if !ok {
logger.Infof("Worker %d: job queue closed, exiting", workerID)
return
}
processData(tid) // function to process tenant data
case <-ctx.Done():
logger.Infof("Worker %d: context done, exiting", workerID)
return
}
}
}(i)
}
for _, tid := range tenantIDs {
select {
case jobs <- tid:
logger.Infof("Tenant ID %s sent to job queue", tid)
case <-ctx.Done():
logger.Warning("Context done, stopping sending jobs")
break
}
}
close(jobs)
waitDone := make(chan struct{})
go func() {
wg.Wait()
close(errChan)
close(waitDone)
}()
select {
case <-waitDone:
// error handling logic
for err := range errChan {
if err != nil {
logger.Error(err)
}
}
case <-ctx.Done():
logger.Warning("Context done, stopping waiting for workers")
}
logger.Info("All workers have completed")
}While error handling is omitted for brevity, the normal processing flow is as follows:
- Initialize the channel (jobs)
- Initialize worker goroutines with
go func(workerID int) - Send tenant IDs to the jobs channel with
jobs <- tid - Workers receive tenant IDs from the jobs channel with
tid, ok := <-jobsand execute processing - After all goroutines complete their tasks (signaled by
wg.Done()), check for any errors in errChan and finish the process
Although the worker-related code appears first in the implementation, workers actually wait until data is sent to the channel, and execution begins only when data is available in the channel.
Conclusion
The worker pool pattern is a practical pattern that leverages Go's concurrency features. It can be utilized in many use cases, such as independent processing for each tenant and optimizing I/O-bound workloads.
The code in this article serves as a template; for production use, consider customizing it with the following in mind:
- Retry logic and timeout management for processes
- Error handling strategies (immediate termination vs. continuation)
- Worker pool size adjustment (considering not just CPU but also I/O load)
Go's concurrency features are powerful and flexible, but they show their true value only when properly designed. I hope you'll consider incorporating these patterns into your own projects.
