PostgreSQL is one of the most powerful and open source object-relational database system. It can efficiently store data in objects therefore relationship between objects persist rather than through common fields making it compatible for both relational(SQL) and non-relational data(JSON).PostgreSQL is ACID compliant, that means it supports transactions and maintains the data integrity as well!
PostgreSQL is well suited for both OLTP and OLAP applications. OLTP(Online transaction processing) is a type of database that deals with transactions, such as data entries and retrievals, basically for the applications that require real-time data access, such as ecom and ATM.OLAP(Online Analytical processing) deals with data mining and business intelligence, OLAP databases are u sed in applications requiring complex queries such as financial analysis.
PostgreSQL basically supports all the datatypes like JSON, XML, arrays and HStore,it can also store text, images, numbers etc in the same database
PostgreSQL supposrts geospatial data as well, we can easily store and query data related to locations!
HStore is a data type that allows to store key-value pairs in PostgreSQL, using this we can successfully store non-traditional data such as user preferences and product information!
It can handle a lot of data and queries, in addition to standard B-tree indexes, it also offers GIN and GiST indexes, which can be used for arrays and HStore.
Cascading Replication feature of PostgreSQL is used for sharding and Materialized view allows for pre-computing joins and aggregations which help to improve query performance.
It also supports asynchronous commits ie. we dont need to wait for other transactions to complete and can commit our transaction without any hassle!
It also supports trigger based event notification ie. we can setup certain alerts so that we can get informed regarding partuclar events.
PostgreSQL supports multiple storage types like:
Tablespaces: we can store data in different physical locations.
Clusters: these are basically group of tables stored together, we can use them for improving performance by clubbing frequently accessed data.
Partitions:These divide data into smaller pieces so using that we can improve performance by only accessing the needed data!
Creating a basic Table in PostgreSQL:
CREATE DATABASE expense_db
WITH OWNER = postgres
ENCODING = 'SQL_ASCII'
TABLESPACE = pg_default
CONNECTION LIMIT = -1;Listing the details of Newly created schema:
\l expense_dbConnect to the database:
\c expense_dbPrinting the table structure:
\d+ expense_dbAdding foreign key constraint and linking column to enforce referential integrity:
ALTER TABLE expense
ADD CONSTRAINT fk_expense_category
FOREIGN KEY (category_id) REFERENCES Category (category_id);Insert data in table:
INSERT INTO expense (expense_date, amount, category_id, description)
VALUES
('2022-11-01', 50.25, 1, 'monthly grocery refill'),
('2022-11-05', 20.75, 2, 'birthday party'),
('2022-11-15', 50, 3, 'gas for car');Create Index
CREATE INDEX idx_expense_amount ON expense (amount);Storing Complex data types:
Array:
CREATE TABLE Person (
id SERIAL PRIMARY KEY,
hobbies TEXT[]
);
INSERT INTO
Person (hobbies)
VALUES
(ARRAY ['reading', 'hiking', 'cooking']);
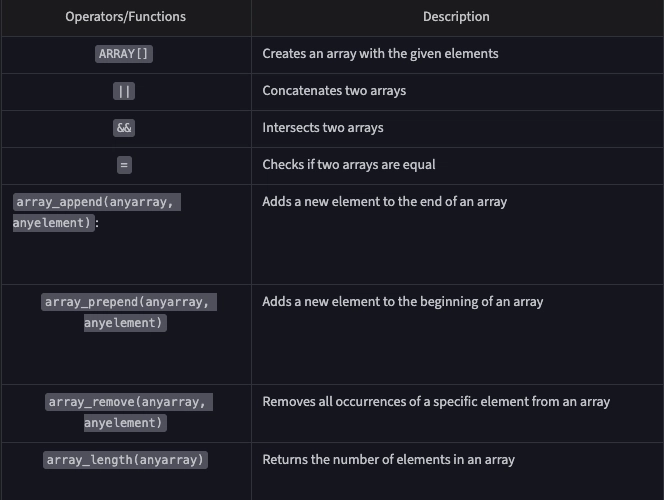
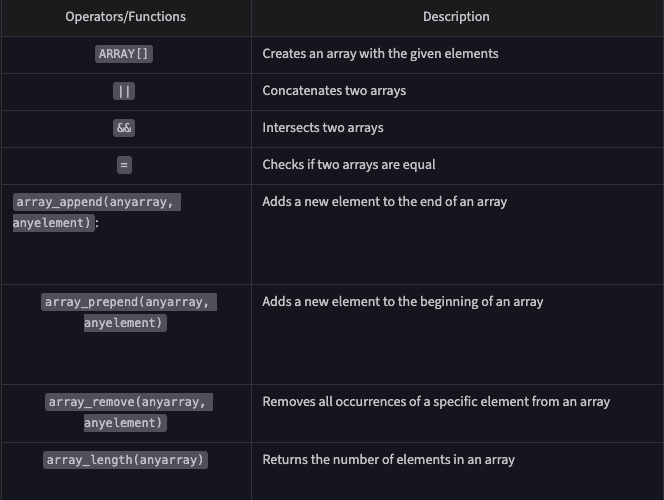
SELECT hobbies[1] FROM Person;Operations for array:
JSON:
CREATE TABLE Person (
id SERIAL PRIMARY KEY,
address JSON
);
INSERT INTO
Person (address)
VALUES
(
'{"street": "123 Main St", "city": "New York", "state": "NY", "zipcode": "A2N9ZJ"}'
);
SELECT address -> 'city' AS "City" FROM Person;
SELECT '\n' AS " "; -- Adding new line
SELECT JSON(address) AS "Address" FROM Person;
SELECT '\n' AS " "; -- Adding new line
SELECT address ->> 'city' AS "City" FROM Person;
SELECT '\n' AS " "; -- Adding new lineOperators:
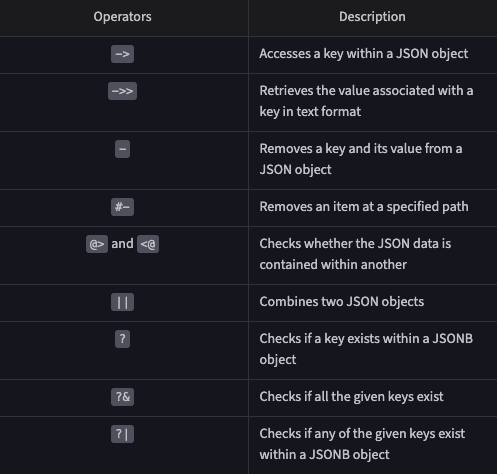
Functions:
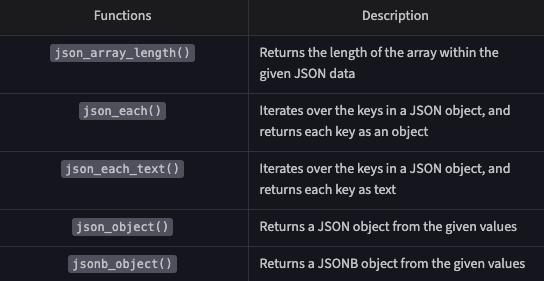
Geometrical data like points, lines, polygons useful for geospatial data:
CREATE TABLE parks (
id SERIAL PRIMARY KEY,
name TEXT,
boundary POLYGON
);
INSERT INTO
parks (name, boundary)
VALUES
(
'Central Park',
'((-73.9677, 40.7936), (-73.9668, 40.7911), (-73.9612, 40.7923),
(-73.9606, 40.7941), (-73.9645, 40.7954), (-73.9677, 40.7936))'
);
SELECT * FROM parks;Network Addresses:
PostgreSQL supports data types like INET and CIDR (storing and manipulating network addresses)
MACADDR(to store media access control addresses which is a sequence of six hexadecimal numbers, this datatype is used by network tools like ping and traceroute)
BIT(bits or bit strings)
CREATE TABLE Users (
user_id SERIAL PRIMARY KEY,
user_name VARCHAR(255),
user_ip_address INET,
user_mac_address MACADDR,
user_location VARCHAR(255),
user_status BIT
);
INSERT INTO
Users (
user_name,
user_ip_address,
user_mac_address,
user_location,
user_status
)
VALUES
(
'John Doe',
'192.168.0.1',
'00:11:22:33:44:55',
'California',
B'1'
),
(
'Jane Smith',
'10.0.0.1',
'01:02:03:04:05:06',
'New York',
B'0'
);
SELECT * FROM users;Views:
Databases are often divided into multiple tables, with each table containing a subset of the data. This allows for better organization and easier maintenance but can complicate querying the data. A database view allows us to create a virtual table based on one or more existing tables. The base tables used to create the database view are hidden from the end user. This simplifies querying the data because only the view needs to be queried. Views can also be used for performance optimization, because the query to create the view only needs to be executed once, and the resulting data can be accessed multiple times.
CREATE VIEW OrderHistory AS
SELECT
Customer.name,
Customer_order.order_date
FROM
Customer INNER JOIN Customer_order
ON Customer.order_id = Customer_order.id;
\d+ OrderHistoryHaving a materialized view can be beneficial in cases where the underlying tables and data used in the view can change frequently because the materialized view will only need to be refreshed periodically rather than after every change to the base tables. It can also be helpful in cases where the view involves complex queries, because having the results pre-computed and stored can improve performance. However, it’s important to keep in mind that materialized views don’t update automatically and must be refreshed manually. They also can’t be used for the modification of data. Therefore, it’s important to carefully consider if a materialized view is the best solution for a particular query before implementing it.
CREATE MATERIALIZED VIEW AS
SELECT
FROM
...WITH NO DATA;
Enter fullscreen mode
Exit fullscreen mode
Recursive View:
Recursive views allow for querying data that references itself, such as hierarchical relationships.The syntax for creating recursive views in PostgreSQL is given below.
CREATE RECURSIVE VIEW AS (
UNION ALL
)
Enter fullscreen mode
Exit fullscreen mode
Stored procedures
Stored procedures are reusable blocks of SQL code that can be called and executed whenever needed. They allow for faster execution of repetitive tasks and increased security by defining strict parameters for input and output. The syntax for creating stored procedures is given below:
CREATE PROCEDURE update_employee(employee_id int, job_title text)
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE Employee
SET title = $2
WHERE id = $1;
END; $$;
Enter fullscreen mode
Exit fullscreen mode
Calling the stored procedure:
CALL update_employee(1, 'Marketing Manager');
Enter fullscreen mode
Exit fullscreen mode
Functions:
Functions are similar to stored procedures because they’re reusable blocks of code. However, they are also different because they always return a value. They can also be used with stored procedures as subroutines within the larger procedure.
CREATE FUNCTION get_cheap_product_count(low MONEY, high MONEY)
RETURNS VARCHAR(50)
LANGUAGE plpgsql
AS
$$
DECLARE
product_count integer;
BEGIN
SELECT count(id) INTO product_count
FROM
Product
WHERE
price between low and high;
RETURN product_count;
END; $$;
SELECT * FROM get_cheap_product_count(100::MONEY, 500::MONEY);
Enter fullscreen mode
Exit fullscreen mode
Trigger Creation Syntax:
CREATE OR REPLACE FUNCTION update_creation_date() RETURNS TRIGGER
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE Product SET creation_date = current_timestamp WHERE id = NEW.id;
RETURN NEW;
END;$$;
CREATE TRIGGER product_insert_trg
AFTER INSERT ON Product
FOR EACH ROW EXECUTE PROCEDURE update_creation_date();
INSERT INTO
Product (name, price)
VALUES
('iPhone', 799.99),
('S7 Edge', 849.99),
('Mate 9', 599.99),
('Moto Z', 599.99),
('Lumia', 499.99);
SELECT * FROM Product;
Enter fullscreen mode
Exit fullscreen mode
Commands to control transactions:
The BEGIN command is used to start a new transaction in PostgreSQL.
The COMMIT command is used to commit the transaction and make all the changes permanent.
When we start a transaction, we can optionally create a savepoint within it. This allows us to roll back the changes made by the transaction up to that point in case something goes wrong, without having to undo all of the changes made since the beginning of the transaction.
We can use the ROLLBACK command to undo all of the changes made within a transaction.
BEGIN;
INSERT INTO Account
VALUES ('100-0000-0001', 'Timothy Wright', 1000);
SAVEPOINT trans_point1;
\echo '>> Updating the row'
SELECT '\n' AS " "; -- Adding new line
UPDATE Account SET balance = balance + 100::money;
SELECT * FROM Account;
SELECT '\n' AS " "; -- Adding new line
SAVEPOINT trans_point2;
\echo '>> Deleting the row'
SELECT '\n' AS " "; -- Adding new line
DELETE FROM Account WHERE account_number='100-0000-0001';
SELECT * FROM Account;
SELECT '\n' AS " "; -- Adding new line
\echo '>> Rolling back to trans_point2'
SELECT '\n' AS " "; -- Adding new line
ROLLBACK TO SAVEPOINT trans_point2;
SELECT * FROM Account;
SELECT '\n' AS " "; -- Adding new line
\echo '>> Rolling back to trans_point1'
SELECT '\n' AS " "; -- Adding new line
ROLLBACK TO SAVEPOINT trans_point1;
SELECT * FROM Account;
SELECT '\n' AS " "; -- Adding new line
Enter fullscreen mode
Exit fullscreen mode
Transaction isolation level
The transaction isolation level determines how much information is shared between different transactions.A dirty read is a transaction that allows reading data that has been modified but not committed yet. This can lead to inconsistencies in data, so it’s not recommended for use in production environments.In a nonrepeatable read, a transaction can read the same data multiple times but see different values each time. This can also lead to problems in the database, so it’s best to avoid this type of transaction if possible.A phantom read occurs when data is read twice and different rows have been read in between. This can cause unexpected results, so it’s best to avoid this mode of transaction.As per SQL standards, there are four different transaction isolation levels, as given below:READ UNCOMMITTED: This allows dirty reads. It can lead to data inconsistencies, so it’s usually not recommended. However, PostgreSQL ensures there are no dirty reads in a transaction, even in this mode. Having a more restrictive isolation mode is allowed as per SQL standards.READ COMMITTED: This prohibits reading data that has been modified but not yet committed. It provides a higher level of consistency for our data. This is also the default level of consistency in a PostgreSQL database.REPEATABLE READ: This allows reading data that has been modified but not yet committed. It guarantees that we see the same results if we run the same query multiple times. In PostgreSQL, this mode doesn’t allow phantom reads.SERIALIZABLE: This guarantees that we’ll see the same results if we run the same query multiple times, preventing other transactions from modifying our data. It’s the most restrictive of all the isolation levels.Locks:
Locks are a special type of mechanism that can control access to data between multiple processes. In PostgreSQL, locks can be applied at the table, row, or page level. When we acquire a lock on a resource within a single transaction, it will remain in place until the transaction is committed or rolled back. This ensures that only one process can modify the data at a time.PostgreSQL uses the concept of shared and exclusive locks. There’s no UNLOCK statement in PostgreSQL, but we can release the lock by committing or rolling back our transaction. Once a transaction ends, all the locks obtained in the transaction are released automatically.Deadlock:
A deadlock is a situation where two or more processes are locked in an endless loop, unable to proceed until one of the processes terminates. This typically occurs when there’s a cyclical dependency between two or more processes that both need to access the same data. To avoid deadlocks, it’s important to understand the underlying causes and take steps to prevent them from occurring.Some of the strategies for preventing deadlocks are as follows:Using transactions to lock data in smaller chunksEnsuring that processes don't hold locks for too longUsing dedicated deadlock detection tools to identify and resolve deadlocks as they occurBut ultimately, the best way to prevent deadlocks is to be aware of their potential causes and take steps to mitigate the associated risks.PostgreSQL Architecture
The client connects to the server and sends a request for a connection.
The server authenticates the client and establishes a connection.
The client sends a request for a transaction.
The server determines whether or not to allow the transaction, and if so, starts a new process to execute it.
The client sends SQL commands to the server.
The server executes the commands and returns the results to the client.
When the client has finished sending commands, it commits or rolls back the transaction.
Process Architecture:
Postmaster: This is a process that runs on the server and manages the data flow between the client and the database. It accepts client requests, assigns them to processes, and manages the communication between them and the database.
Postgres: This is the main process that manages data in the database. It receives and executes client queries and retrieves and updates data based on them.
Checkpointer: This process monitors the postgres process to ensure it works correctly. If a problem is detected, it will trigger a failover and cause another server process to take over.
Write-ahead logging (WAL): PostgreSQL uses the WAL system to manage the process of writing dirty buffers to disk. This ensures that data is always written consistently, even if the database crashes unexpectedly.
Dirty buffer: This stores modified or new data that hasn’t yet been written to the disk. It allows the database to continue operating even if the disk is full or unavailable. When the buffer is full, the oldest data is written to the disk by the background writer process.
Background writer: This process periodically writes changes to the disk, which helps prevent database corruption if there’s a power failure or other system problem.
WAL writer: This process writes data to the write-ahead logs (WALs), which helps ensure the consistency of the database by writing changes to the disk before they’re applied to the database. This helps to prevent database corruption in the event of a system failure. They allow the database to recover from a crash without losing any data, which helps minimize downtime. In addition, WALs also help to improve performance by reducing the amount of I/O that’s necessary.
Archiver: This process helps to manage backups.
Autovacuum: This process regularly examines tables for dead space and other inconsistencies.
The pg_ctl utility manages the database cluster and is used to start, stop, and manage the PostgreSQL server. The pg_hba.conf file, which controls client authentication and access to the server, is also stored in the database cluster.Vaccuming
Database vacuuming is the process of removing old or stale records from a database.
When we delete data from our database, it’s not actually removed immediately, but rather marked as “deleted.” The database still uses this memory, and this can slow down our database performance. Vacuuming removes these marked, deleted rows from our database, freeing up memory space and improving the overall performance. It helps minimize wasted storage space by reclaiming and recycling the unused blocks in the memory.
VACUUM | ;
Enter fullscreen mode
Exit fullscreen mode
VACUUM FULL;
Enter fullscreen mode
Exit fullscreen mode
Reindexing
We should also consider reindexing the PostgreSQL database regularly. This process involves rebuilding our indexes to optimize their performance and remove obsolete data from the system.PostgreSQL uses B-trees by default, but other types of indexes are also available for PostgreSQL. As we keep updating and inserting more and more data into our table, the B-tree tends to stay imbalanced and get fragmented, meaning that it’s no longer optimized for fast access and retrieval. Reindexing will rebuild the index and ensure that it stays properly balanced, optimizing the performance of our database over time.Audit logs
Audit logs are a record of all the activities or events that occur in a system or application. These logs provide a way to track changes and activities within the system, including user actions, system events, and security-related events.Auditing Capabilities
Granular logging: PostgreSQL supports the logging of SQL statements, user logins, and specific events to a variety of output formats, including files, syslog, and the Windows event log.
Database event triggers: PostgreSQL's event trigger feature allows users to define triggers that execute when specific events occur in the database, such as table creations, modifications, or deletions.
Fine-grained access control: PostgreSQL provides several mechanisms for controlling access to audit logs, including file system permissions and database roles.
pgAudit extension: pgAudit is an open-source extension for PostgreSQL that provides more advanced auditing capabilities, such as auditing of data modifications, row-level auditing, and filtering of audit logs by specific fields.
Session tracking: PostgreSQL allows tracking of user sessions, including usernames, IP addresses, and session durations.
Log file rotation and retention policies: PostgreSQL allows administrators to configure the retention period and maximum file size of log files and other log file rotation policies.
Integration with third-party log management and SIEM systems: PostgreSQL supports integration with third-party log management and security information and event management (SIEM) systems, such as Splunk and Logstash, allowing administrators to manage and analyze log data centrally.
Data Encryption- one way hashing
CREATE TABLE Users (
username VARCHAR(20) NOT NULL PRIMARY KEY,
password VARCHAR(50)
);
INSERT INTO Users VALUES ('developer', md5('p@ssw0rd'));
SELECT * FROM Users;
Enter fullscreen mode
Exit fullscreen mode
Replication:
Database replication is the process of copying data from one database to another. This can be useful in scenarios where we want to have multiple copies of a database to ensure high availability and reliability. In case one database fails, another can take over to serve the application.Methods of database replications
PostgreSQL supports several types of database replication, including:
Streaming replication: This is the standard method of replication in PostgreSQL, and it involves continuously sending WAL records from the primary to the replica. The replica then applies the WAL records to keep its data in sync with the primary.
Logical replication: This method involves replicating individual changes to the data, such as inserts, updates, and deletes, instead of replicating the entire database. Logical replication can be useful for replicating specific data between databases or for creating reporting replicas.
File-based replication: This method involves copying the entire database files from the primary to the replica. It can be useful for disaster recovery or for creating read-only replicas for reporting purposes.
Synchronous replication: This type of replication involves having the primary wait for the replicas to confirm that they have received and applied the changes before committing the transaction. Synchronous replication can provide a higher level of data consistency, but can also impact performance due to the wait time for the replicas to confirm receipt.
Asynchronous replication: This type of replication involves the primary sending of changes to the replicas without waiting for confirmation. This can help improve performance, but can also result in data inconsistencies if the replicas are temporarily unavailable.
Trigger-based replication: Trigger-based replication is a method of database replication that uses triggers to replicate data changes from one database to another automatically. It can be useful for replicating data between databases or creating reporting replicas. It can also be used for data migration, where data from an old system is replicated to a new system. Triggers are special functions in a database that are automatically executed when a specified event occurs, such as an insert, update, or delete. The main advantage of trigger-based replication is that it’s easy to set up and can be done without modifying the application code. However, trigger-based replication can also have some disadvantages, such as increased latency and load on the source database and the possibility of circular replication, where changes are continuously replicated between two databases, leading to an infinite loop.
Query optimization
Query optimization in PostgreSQL improves the performance of SQL queries by making them more efficient. Several techniques can be used to optimize queries in PostgreSQL, including indexing, query planning, and execution.Indexing: Indexing is one of the most effective ways to improve the performance of SQL queries. An index allows the database to quickly find the rows that match a query instead of scanning the entire table. Several types of indexes are available in PostgreSQL, including B-tree, Hash, GiST, and GIN, each with different strengths and weaknesses.Query planning: The query planner determines the most efficient execution plan for a query. The planner considers various factors, including the available indexes, statistics about the data, and the cost of various operations, to determine the best plan. We can use the EXPLAIN command to see the execution plan for a query, which can help us identify any bottlenecks or areas for improvement.Execution: Once the query planner has determined the best execution plan, the database engine executes the query. The efficiency of the query execution can be impacted by factors such as the amount of memory available, disk I/O performance, and the amount of concurrent activity on the system. We can use tools like the pg_stat_activity view to monitor the performance of queries and identify any slow-running queries that need to be optimized.SQL techniques: Besides the more technical optimization techniques, it’s important to consider the SQL itself. Simple techniques like using the right data types, avoiding subqueries and complex joins, and using appropriate aggregate functions can make a big difference in the performance of our queries.Check CPU Utilization of Queries:
SELECT
pid,
datname,
usename,
backend_start,
query_start,
(query_start - backend_start) AS duration
FROM
pg_stat_activity
ORDER BY
duration DESC;
Enter fullscreen mode
Exit fullscreen mode
Memory Usage:
The buffers_alloc column from the pg_stat_bgwriter system view represents the total number of buffers allocated in the shared buffer cache to PostgreSQL back-end processes. This value provides insight into current memory usage for caching data.Query Performance Analysis
EXPLAIN (ANALYZE, VERBOSE, COSTS, BUFFERS, TIMING)
SELECT
first_name,
last_name
FROM
Customer
WHERE
state = 'TX';
Enter fullscreen mode
Exit fullscreen mode
Types based on data capture
The types of backups based on what data they capture and how they’re used in the backup and recovery process are as follows:Full backup: A full backup is a complete copy of the database, including all the data and metadata. Full backups are typically the largest and take a long time to complete. However, they’re the most comprehensive form of backup and provide the most straightforward method for restoring data.Incremental backup: An incremental backup includes only the changes made to the database since the last backup. Incremental backups are smaller and take less time to complete than full backups. However, restoring an incremental backup requires the restoration of the full backup and all subsequent incremental backups.Differential backup: A differential backup includes only the changes made to the database since the last full backup. Differential backups are smaller than full backups but larger than incremental backups. Restoring a differential backup requires the restoration of the full backup and the differential backup.Log backup: A log backup captures the transaction logs of the database, which contain information about the changes made to the database since the last log backup. Log backups, typically performed frequently, such as every few minutes or hours, are used for disaster recovery and supporting point-in-time recovery.Snapshot backup: A snapshot backup is a copy of the database at a specific time, created by capturing the state of the database and the storage system. Snapshot backups are typically performed quickly and with minimal impact on the performance of the database and are used for disaster recovery and for supporting point-in-time recovery.
pg_dump -U postgres -F t -f backupfile.tar database_name
pg_dumpall > backup_file.sql
pg_restore -U postgres -F t -C -d newdatabase backupfile.backup
Enter fullscreen mode
Exit fullscreen mode
Useful Commands: