LlamaIndex AgentWorkflow, as a brand-new multi-agent orchestration framework, still has some shortcomings. The most significant issue is that after an agent hands off control, the receiving agent fails to continue responding to user requests, causing the workflow to halt.
In today's article, I'll explore several experimental solutions to this problem with you and discuss the root cause behind it: the positional bias issue in LLMs.
I've included all relevant source code at the end of this article. Feel free to read or modify it without needing my permission.
Introduction
My team and I have been experimenting with LlamaIndex AgentWorkflow recently. After some localization adaptations, we hope this framework can eventually run in our production system.
During the adaptation, we encountered many obstacles. I've documented these problem-solving experiences in my article series. You might want to read them first to understand the full context.
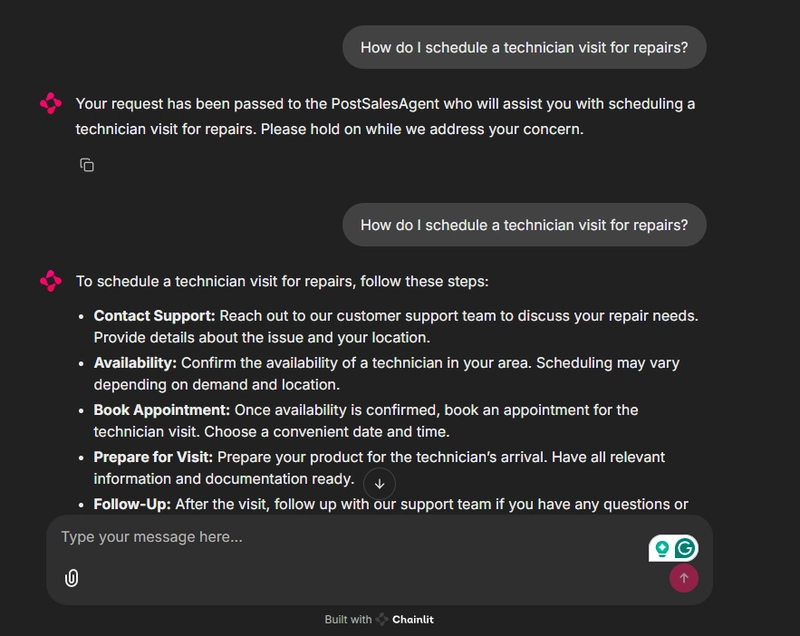
Today, I'll address the issue where after the on-duty agent hands off control to the next agent, the receiving agent fails to continue responding to the user's most recent request.
Here's what happens:
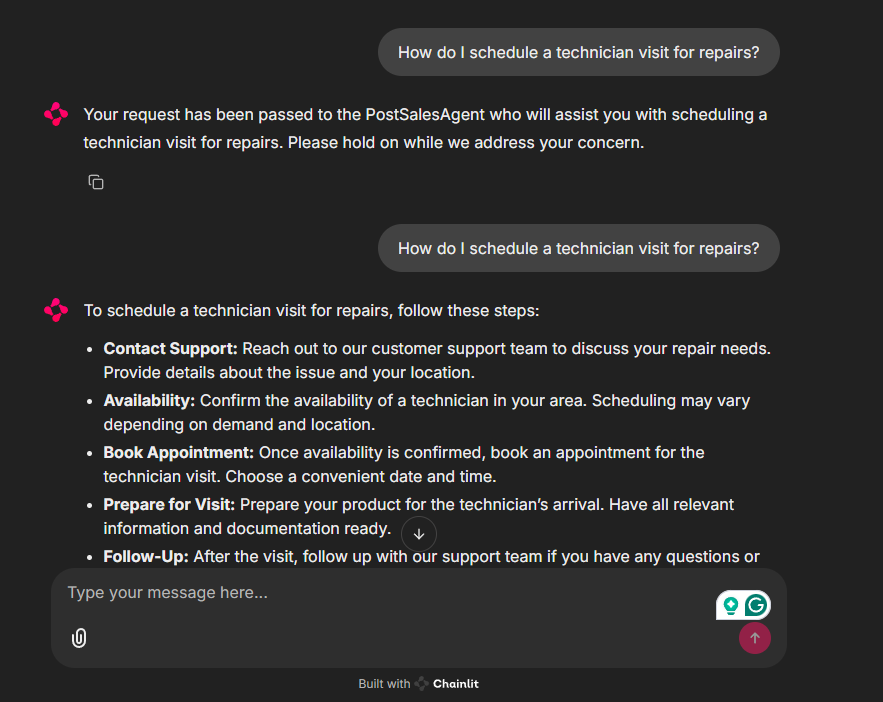
After the handoff, the receiving agent doesn't immediately respond to the user's latest request - the user has to repeat their question.
Why should I care?
In this article, we'll examine this unique phenomenon and attempt to solve it from multiple perspectives, including developer recommendations and our own experience.
During this process, we'll intentionally review AgentWorkflow's excellent source code, having a cross-temporal conversation with its authors through code to better understand Agentic AI design principles.
We'll also touch upon LLM position bias for the first time, understanding how position bias in chat history affects LLM responses.
These insights aren't limited to LlamaIndex - they'll help us handle similar situations when working with other multi-agent orchestration frameworks.
Let's go.
The Developer-Recommended Solution
First, let's see what the developers say
Before we begin, if you need background on LlamaIndex AgentWorkflow, feel free to read my previous article:
Diving into LlamaIndex AgentWorkflow: A Nearly Perfect Multi-Agent Orchestration Solution
In short, LlamaIndex AgentWorkflow builds upon the excellent LlamaIndex Workflow framework, encapsulating agent function calling, handoff, and other cutting-edge Agentic AI developments. It lets you focus solely on your agent's business logic.
In my previous article, I first mentioned the issue where agents fail to continue processing user requests after handoff.
Others have noticed this too. In this thread, someone referenced my article's solution when asking the developers about it. I'm glad I could help:
I was building a multi-agent workflow, where each agent has multiple tools. I started the...
Developer Logan M proposed including the original user request in the handoff method's output to ensure the receiving agent continues processing.
Unfortunately, as of this writing, LlamaIndex's release version hasn't incorporated this solution yet.
So today's article starts with the developer's response - we'll try rewriting the handoff method implementation ourselves to include the original user request in the handoff output.
First attempt
Since this solution modifies the handoff method implementation, we don't need to rewrite FunctionAgent code. Instead, we'll modify AgentWorkflow's implementation.
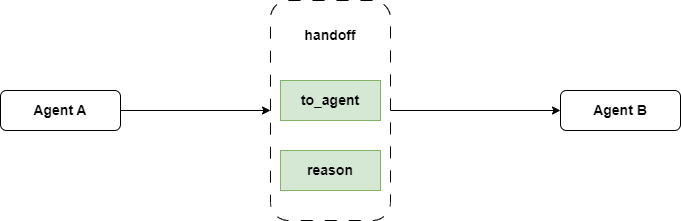
The handoff method is core to AgentWorkflow's handoff capability. It identifies which agent the LLM wants to hand off to and sets it in the context's next_agent. During workflow execution, this method merges with the agent's tools and gets called via function calling when the LLM needs to hand off.
This is how AgentWorkflow implements multi-agent handoff.
In the original code, after handoff sets the next_agent, it returns a prompt as the tool call result to the receiving agent. The prompt looks like this:
DEFAULT_HANDOFF_OUTPUT_PROMPT = """
Agent {to_agent} is now handling the request due to the following reason: {reason}.
Please continue with the current request.
"""This prompt includes {to_agent} and {reason} fields. But since the prompt goes to the receiving agent, {to_agent} isn't very useful. Unless {reason} contains the original user request, the receiving agent can't get relevant information from this prompt. That's why the developer suggested including the user request in the prompt output.
Let's modify this method first.
We'll create an enhanced_agent_workflow.py file and write the modified HANDOFF_OUTPUT_PROMPT:
ENHANCED_HANDOFF_OUTPUT_PROMPT = """
Agent {to_agent} is now handling the request.
Check the previous chat history and continue responding to the user's request: {user_request}.
"""Compared to the original, I added a requirement for the LLM to review chat history and included the user's most recent request.
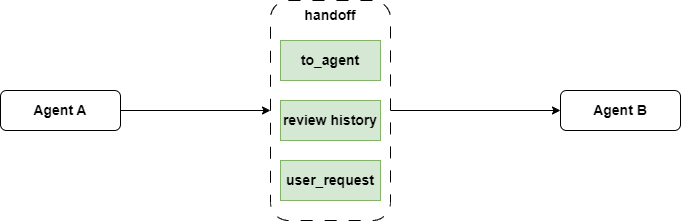
Next, I rewrote the handoff method to return the new prompt:
async def handoff(ctx: Context, to_agent: str, user_request: str):
"""Handoff control of that chat to the given agent."""
agents: list[str] = await ctx.get('agents')
current_agent_name: str = await ctx.get("current_agent_name")
if to_agent not in agents:
valid_agents = ", ".join([x for x in agents if x != current_agent_name])
return f"Agent {to_agent} not found. Please select a valid agent to hand off to. Valid agents: {valid_agents}"
await ctx.set("next_agent", to_agent)
handoff_output_prompt = PromptTemplate(ENHANCED_HANDOFF_OUTPUT_PROMPT)
return handoff_output_prompt.format(to_agent=to_agent, user_request=user_request)The rewrite is simple - I just changed the reason parameter to user_request and returned the new prompt. The LLM will handle everything else.
Since we modified handoff's source code, we also need to modify AgentWorkflow's code that calls this method.
The _get_handoff_tool method in AgentWorkflow calls handoff, so we'll implement an EnhancedAgentWorkflow subclass of AgentWorkflow and override _get_handoff_tool:
class EnhancedAgentWorkflow(AgentWorkflow):
def _get_handoff_tool(
self, current_agent: BaseWorkflowAgent
) -> Optional[AsyncBaseTool]:
"""Creates a handoff tool for the given agent."""
agent_info = {cfg.name: cfg.description for cfg in self.agents.values()}
configs_to_remove = []
for name in agent_info:
if name == current_agent.name:
configs_to_remove.append(name)
elif (
current_agent.can_handoff_to is not None
and name not in current_agent.can_handoff_to
):
configs_to_remove.append(name)
for name in configs_to_remove:
agent_info.pop(name)
if not agent_info:
return None
handoff_prompt = PromptTemplate(ENHANCED_HANDOFF_PROMPT)
fn_tool_prompt = handoff_prompt.format(agent_info=str(agent_info))
return FunctionTool.from_defaults(
async_fn=handoff, description=fn_tool_prompt, return_direct=True
)Our modifications are complete. Now let's write test code in example_2.py to verify our changes. (example_1.py contains the original AgentWorkflow test.)
I'll base the code on this user's scenario to recreate the situation.
We'll create two agents: search_agent and research_agent. search_agent searches the web and records notes, then hands off to research_agent, who writes a research report based on the notes.
search_agent:
search_agent = FunctionAgent(
name="SearchAgent",
description="You are a helpful search assistant.",
system_prompt="""
You're a helpful search assistant.
First, you'll look up notes online related to the given topic and recorde these notes on the topic.
Once the notes are recorded, you should hand over control to the ResearchAgent.
""",
tools=[search_web, record_notes],
llm=llm,
can_handoff_to=["ResearchAgent"]
)research_agent:
research_agent = FunctionAgent(
name="ResearchAgent",
description="You are a helpful research assistant.",
system_prompt="""
You're a helpful search assistant.
First, you'll look up notes online related to the given topic and recorde these notes on the topic.
Once the notes are recorded, you should hand over control to the ResearchAgent.
""",
llm=llm
)search_agent is a multi-tool agent that uses search_web and record_notes methods:
search_web:
async def search_web(ctx: Context, query: str) -> str:
"""
This tool searches the internet and returns the search results.
:param query: user's original request
:return: Then return the search results.
"""
tavily_client = AsyncTavilyClient()
search_result = await tavily_client.search(str(query))
return str(search_result)record_notes:
async def record_notes(ctx: Context, notes: str, notes_title: str) -> str:
"""
Useful for recording notes on a given topic. Your input should be notes with a title to save the notes under.
"""
return f"{notes_title} : {notes}"Finally, we'll use EnhancedAgentWorkflow to create a workflow and test our modifications:
workflow = EnhancedAgentWorkflow(
agents=[search_agent, research_agent],
root_agent=search_agent.name
)
async def main():
handler = workflow.run(user_msg="What is LLamaIndex AgentWorkflow, and what problems does it solve?")
async for event in handler.stream_events():
if isinstance(event, AgentOutput):
print("=" * 70)
print(f"🤖 {event.current_agent_name}")
if event.response.content:
console.print(Markdown(event.response.content or ""))
else:
console.print(event.tool_calls)
if __name__ == "__main__":
asyncio.run(main())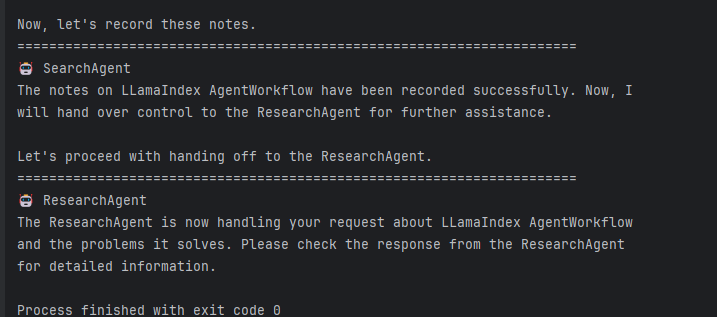
After research_agent takes over, it recognizes the user request but still doesn't respond. Our attempt failed. 😭
My Proposed Solution
How I view this issue
In my previous article, I speculated about the cause:
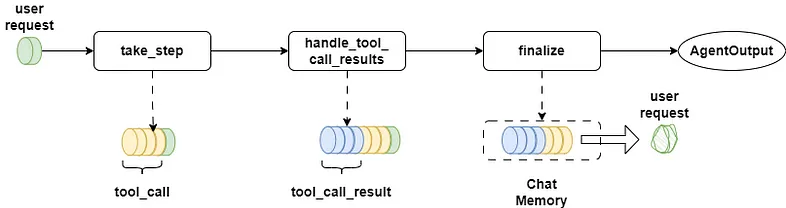
As shown, FunctionAgent stores all chat messages in a MemoryBuffer - essentially a FIFO queue where user requests enter first.
After completing function calling based on user requests, FunctionAgent saves both tool_call and tool_call_result as chat messages in memory.
Each function call generates two messages. Multiple tool calls create even more messages.
This pushes the original user request deeper into the queue - either far from the latest message or, due to MemoryBuffer's After token limit, completely out of the queue.
Consequently, the LLM struggles to perceive the original request from chat history. I'll explain the technical reasons in the position bias section.
When the next agent takes over, it can't immediately respond to the user request.
So I tried a simple fix: After each handoff, I copy the original user request to the queue's end, ensuring the LLM notices it.
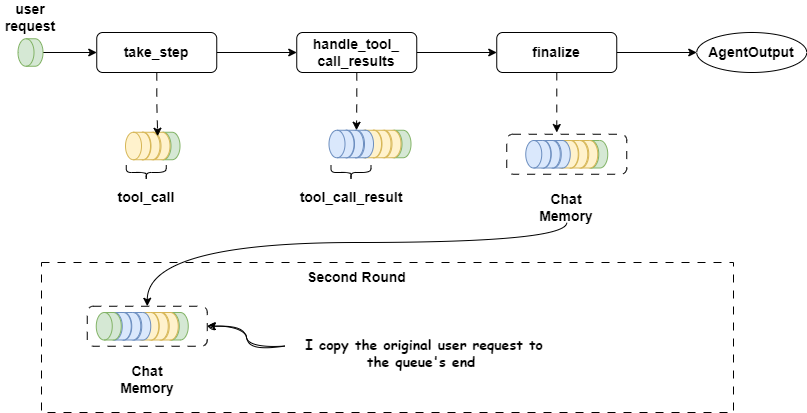
Second attempt
This attempt's code is in reordered_function_agent.py.
The implementation is simple: I subclass FunctionAgent as ReorderedFunctionAgent and override take_step.
class ReorderedFunctionAgent(FunctionAgent):
@override
async def take_step(
self,
ctx: Context,
llm_input: List[ChatMessage],
tools: Sequence[AsyncBaseTool],
memory: BaseMemory,
) -> AgentOutput:
last_msg = llm_input[-1] and llm_input[-1].content
state = await ctx.get("state", None)
if "handoff_result" in last_msg:
for message in llm_input[::-1]:
if message.role == MessageRole.USER:
last_user_msg = message
llm_input.append(last_user_msg)
break
return await super().take_step(ctx, llm_input, tools, memory)When I detect the last message in llm_input is a handoff tool_call_result, I traverse backward to find the user's last request and append it to the queue's end.
To identify handoff tool_call_result messages, I manually pass a handoff_output_prompt during AgentWorkflow initialization, adding a "handoff_result:" string as a marker. The test code is in example_3.py:
workflow = AgentWorkflow(
agents=[search_agent, research_agent],
root_agent=search_agent.name,
handoff_output_prompt=(
"handoff_result: Due to {reason}, the user's request has been passed to {to_agent}."
"Please review the conversation history immediately and continue responding to the user's request."
),
)Let's run the test:
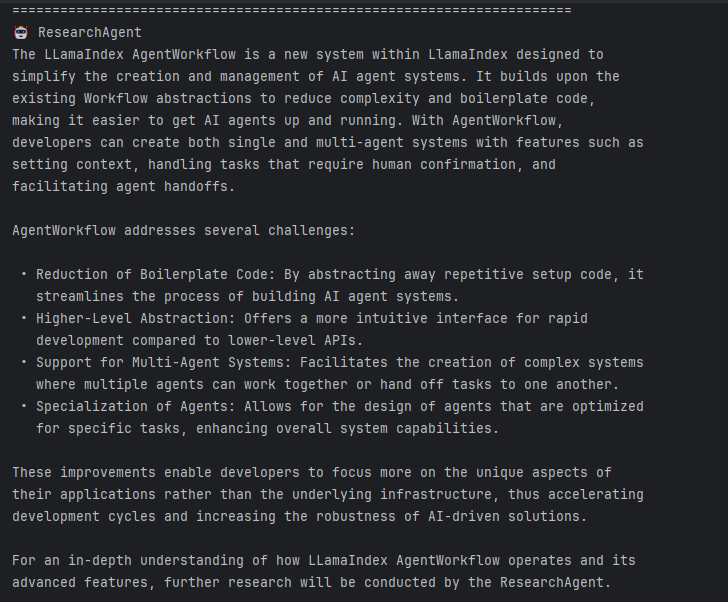
This time, research_agent successfully detects and responds to the user request after taking over. But the result isn't perfect - it doesn't realize the web search and note-taking already happened. It thinks research isn't complete, so the output is just a summary of partial notes rather than a final research report.
I believe this happens because after appending the user request to ChatMemory's end, previous tool_call information gets pushed to the front, causing the LLM to lose critical information.
Next, we'll examine the theoretical basis of this problem and propose an ultimate solution.
Theoretical Cause: Position Bias of LLMs
This issue of messages at the queue's front being ignored relates to a rarely discussed topic: position bias.
Since this isn't an academic discussion, I won't cite many research papers or delve deep into theory. If interested, search for "position bias of large language model."
I'll explain this phenomenon in simple terms:
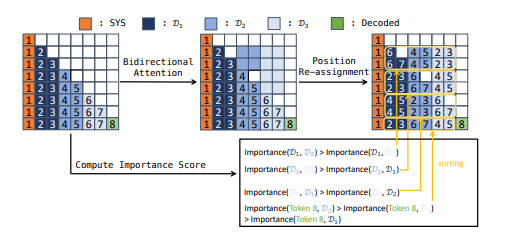
Our text instructions to LLMs typically include two segments: system_prompt an average and chat history - collectively called the LLM's context.
LLMs have an attention weight decay mechanism. As context expands, attention weights for earlier information naturally decay.
When knowledge sits at chat history's front, its influence diminishes rapidly with new dialogue turns. Experiments show that in an 8k token context window, tokens in the first 10% positions see an average over 60% influence weight drop. (Large Language Model Agent: A Survey on Methodology, Applications and Challenges - Junyu Luo et al., 2025)
System prompts are designed as global control signals, with information there having higher confidence (about 3- 5x weight difference).
Imagine entering a restaurant. You first notice the menu cover (system prompt) featuring special dishes and chef introductions, then seasonal items (latest chat history), and finally regular dishes. Delicacies hidden in regular dishes often get overlooked.

Understanding the cause leads us to the ultimate solution.
My Final Attempt
What I plan to do
Next, I'll walk you through my final attempt. First, here's what our project output looks like after implementing it:
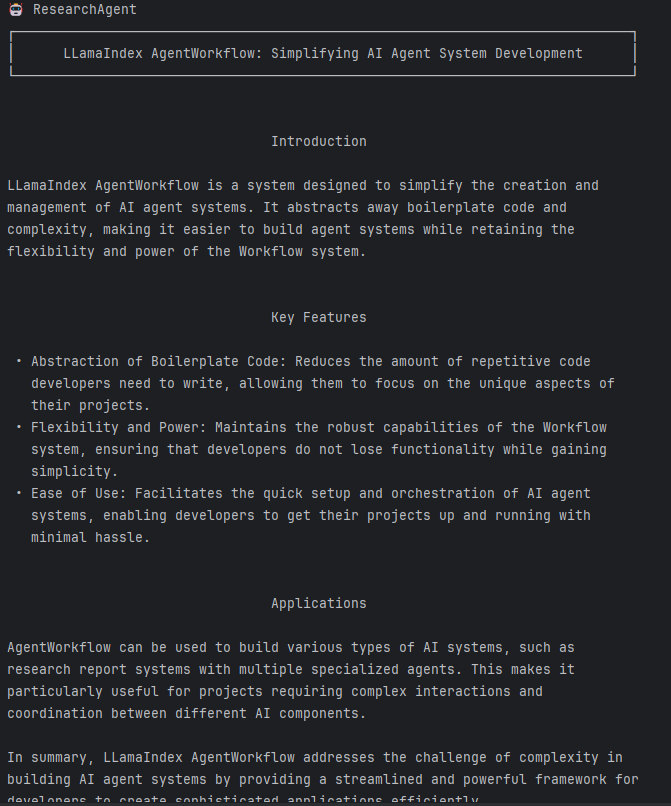
After taking over, ResearchAgent not only continues processing the user request but fully perceives the search notes, ultimately producing a perfect research report.
My solution approach:
I'll discard tool_call and tool_call_result information, no longer appending them to chat history. Chat history will only keep user requests (role: user) and LLM outputs (role: assistant).
Where should we put external information from tool_call?
Here we'll use another AgentWorkflow feature: the original framework lets you initialize a state in Context for storing predefined system states with persistence support.
But in the original framework, state information accompanies each user request. This limits state usage scenarios - it mostly stores static content like login information.
So I'll modify this. I'll place useful information from tool_call in state information, no longer including it in user requests. Instead, I'll put state information in system_prompt.
Remember I mentioned system_prompt information has about 3-5x higher confidence weight? If we want the LLM to notice important information, system_prompt is ideal.
This aligns with my project experience. In a previous project using vanna.ai, we initially placed few-shot prompting examples in chat history, resulting in low accuracy.
After moving few-shot examples to system_prompt, LLM generation accuracy improved dramatically. Try it yourself.
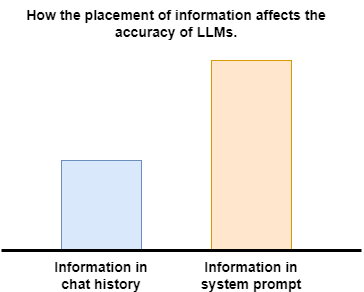
Back to today's article - I'll make similar adjustments to AgentWorkflow: keeping only user-LLM chat messages in chat history, while placing all external information from tool_call into agent system_prompt via state.
How? Let's proceed to implementation.
Code implementation
To implement this solution, I need to modify both AgentWorkflow and FunctionAgent classes.
In AgentWorkflow, I'll remove the inclusion of state information in user requests. We'll create contextual_agent_workflow.py with a ContextualAgentWorkflow subclass of AgentWorkflow.
In ContextualAgentWorkflow, we override init_run to simply place user requests in ChatMemory without state information:
class ContextualAgentWorkflow(AgentWorkflow):
@step
async def init_run(self, ctx: Context, ev: StartEvent) -> AgentInput:
"""Sets up the workflow and validates inputs"""
await self._init_context(ctx, ev)
user_msg: Optional[Union[str, ChatMessage]] = ev.get("user_msg")
chat_history: Optional[List[ChatMessage]] = ev.get("chat_history", [])
memory: BaseMemory = await ctx.get("memory")
current_agent_name: str = await ctx.get("current_agent_name")
if isinstance(user_msg, str):
user_msg = ChatMessage(role="user", content=user_msg)
if user_msg:
await memory.aput(user_msg)
await ctx.set("user_msg_str", user_msg.content)
elif chat_history:
last_msg = chat_history[-1].content or ""
memory.set(chat_history)
await ctx.set("user_msg_str", last_msg)
else:
raise ValueError("Must provide either user_msg or chat_history")
input_messages = memory.get()
return AgentInput(input=input_messages, current_agent_name=current_agent_name)After modifying AgentWorkflow, we'll adjust FunctionAgent. Create contextual_function_agent.py with a ContextualFunctionAgent subclass of FunctionAgent.
In contextual_function_agent.py, we'll add a new STATE_STR_PROMPT string containing state information that will ultimately append to system_prompt:
STATE_STR_PROMPT = """
Current state:
{state_str}
"""We'll also keep an option to modify the default STATE_STR_PROMPT in ContextualFunctionAgent:
class ContextualFunctionAgent(FunctionAgent):
"""The Function Agent contains a system_prompt with state strings."""
state_str_prompt: Optional[str] = Field(
default=STATE_STR_PROMPT,
description="Adding state information to the system_prompt."
)Next, we'll override FunctionAgent methods. FunctionAgent implements take_step, handle_tool_call_results, and finalize. I'll override take_step and handle_tool_call_results.
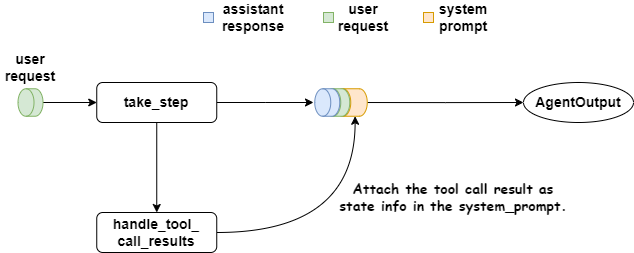
In take_step, I removed statements saving tool_call information to Context, built STATE_STR_PROMPT, appended it to system_prompt, then normally called the parent class's take_step to get LLM results.
class ContextualFunctionAgent(FunctionAgent):
"""The Function Agent contains a system_prompt with state strings."""
...
@override
async def take_step(
self,
ctx: Context,
llm_input: List[ChatMessage],
tools: Sequence[AsyncBaseTool],
memory: BaseMemory
) -> AgentOutput:
if '{state_str}' not in self.state_str_prompt:
raise ValueError("{state_str} not found in provided state_str_prompt")
current_state = await ctx.get("state")
state_str_template = PromptTemplate(self.state_str_prompt)
state_prompt = state_str_template.format(
state_str=current_state
)
if llm_input[0].role == "system":
llm_input[0].content = llm_input[0].content + state_prompt
else:
llm_input = [ChatMessage(role="system", content=state_prompt)] + llm_input
output = await super().take_step(
ctx, llm_input, tools, memory
)
await ctx.set(self.scratchpad_key, [])
return outputhandle_tool_call_results doesn't call parent methods. Its key difference is not writing tool_call_result to ChatMemory, but recording it in Context's state. During the next take_step call, the latest state information appends to system_prompt.
class ContextualFunctionAgent(FunctionAgent):
"""The Function Agent contains a system_prompt with state strings."""
...
@override
async def handle_tool_call_results(
self, ctx: Context, results: List[ToolCallResult], memory: BaseMemory
) -> None:
current_state = await ctx.get("state", {})
for tool_call_result in results:
if (
tool_call_result.return_direct
and tool_call_result.tool_name != "handoff"
):
await memory.aput(
ChatMessage(
role="assistant",
content=str(tool_call_result.tool_output.content),
additional_kwargs={"tool_call_id": tool_call_result.tool_call_id}
)
)
break
current_state[tool_call_result.tool_name] = str(tool_call_result.tool_output.content)
await ctx.set("state", current_state)Our modifications to AgentWorkflow and FunctionAgent are complete. Now let's modify the test code.
The modification is simple - just replace original FunctionAgent and AgentWorkflow with ContextualFunctionAgent and ContextualAgentWorkflow.
search_agent = ContextualFunctionAgent(
name="SearchAgent",
description="You are a helpful search assistant.",
...
)
research_agent = ContextualFunctionAgent(
name="ResearchAgent",
description="You are a helpful research assistant.",
...
)
workflow = ContextualAgentWorkflow(
agents=[search_agent, research_agent],
root_agent=search_agent.name
)Running this code gives excellent results:
We've indeed identified and effectively solved the root problem.
Conclusion
LlamaIndex AgentWorkflow is a great multi-agent programming framework, but it still has some flaws: when the on-duty agent hands over control to the next agent, the receiving agent sometimes fails to continue responding to user requests.
In today's article, we first tried the official recommended method and the approach I proposed in my previous article to solve this issue, but the problem couldn't be effectively resolved.
So, I explored a relatively niche topic with you: LLM's position bias. We learned that LLMs assign different parameter weights to information in different positions of the context.
Based on this technical theory, we attempted a temporary modification method and succeeded.
However, the real world is more complex than experiments. Besides position bias, factors like the user's system_prompt and different LLMs' preferences for information positions also contribute to this issue. This requires LlamaIndex to address it at the framework level.
I'm still waiting for LlamaIndex AgentWorkflow to become a truly enterprise-ready, production-grade multi-agent orchestration framework. Until then, I'll pause this magical journey through the Workflow series. But I look forward to meeting LlamaIndex AgentWorkflow again in the near future.
Go LlamaIndex!
Enjoyed this read? Subscribe now to get more cutting-edge data science tips straight to your inbox! Your feedback and questions are welcome — let’s discuss in the comments below!
This article was originally published on Data Leads Future.
