Google's Gemini 2.0 Flash is making waves with its groundbreaking native image generation. This "workhorse" AI now crafts and edits visuals directly from text, marking a leap towards true AI multimodality. In this blog post, we will offer a hands-on guide to using Gemini 2.0 Flash for image generation in AI Studio and via the API, showcasing its transformative potential through compelling use cases.
Getting Started: How to Use it?
Eager to start playing with AI-powered visuals? Gemini 2.0 Flash offers two user-friendly ways to explore its native image generation: Google AI Studio for a visual approach, and the Gemini API for programmatic control.
1. Google AI Studio: A Visual Playground
If you prefer a hands-on, visual environment, Google AI Studio is the ideal launchpad. It's an intuitive platform for experimenting with the experimental Gemini 2.0 Flash, often labeled as gemini-2.0-flash-exp-image-generation, alias that points to gemini-2.0-flash-exp.
Here's your quick start guide to AI Studio:
- Step 1. Model Selection: Within AI Studio, pinpoint and choose the
Gemini 2.0 Flash (Image Generation) Experimentalmodel. - Step 2. Output Configuration: Set the output format to "Images + text". This simple but essential step instructs the model to include images alongside any text responses.
-
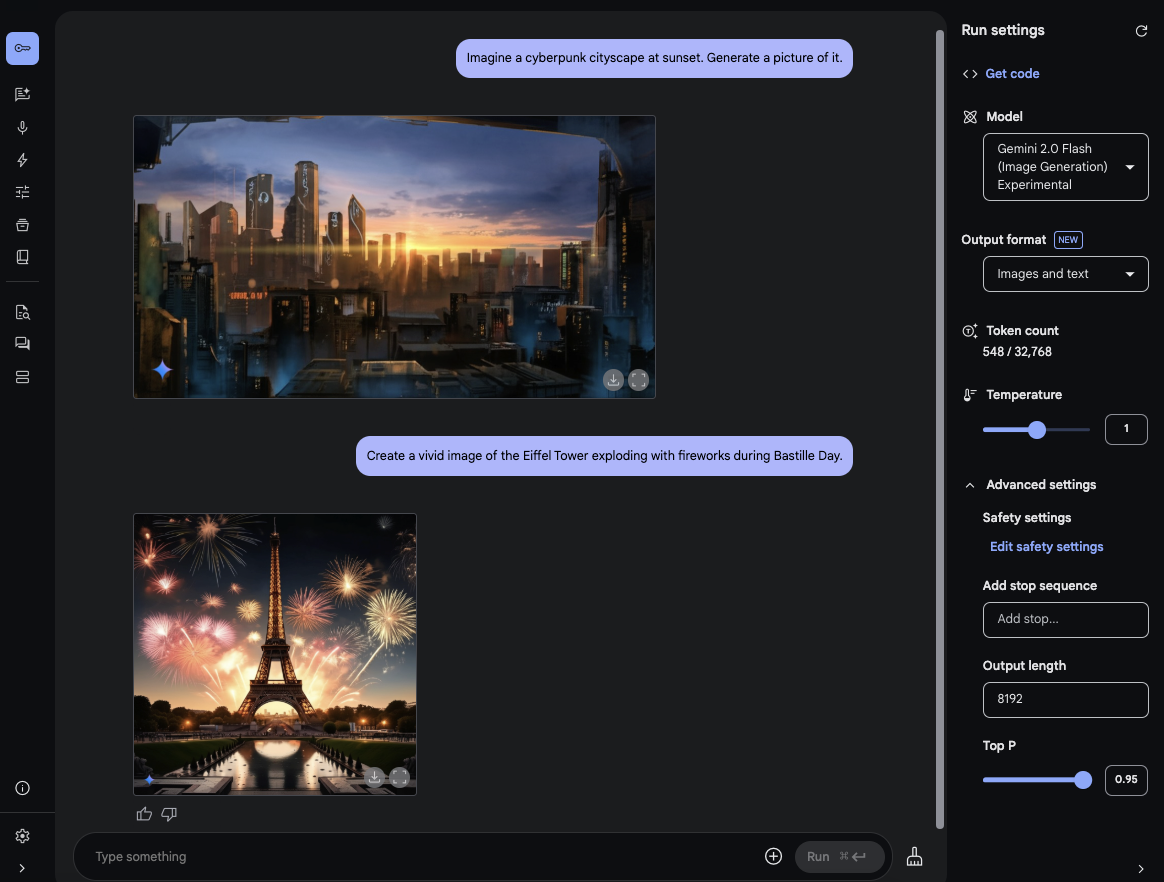
Step 3. Jump into Text-to-Image Prompts: Time to get creative! Try starting with prompts like these:
Imagine a cyberpunk cityscape at sunset. Generate a picture of it.Create a vivid image of the Eiffel Tower exploding with fireworks during Bastille Day.
These initial prompts will give you a feel for the visual requests Gemini 2.0 Flash can handle and inspire more complex creations.
Interactive Image Evolution in AI Studio:
AI Studio truly shines with its conversational image editing. You can refine and evolve images through simple, natural language dialogues, much like chatting with a visual collaborator. Picture this interactive flow:
You:
Generate a picture of a classic blue muscle car from the 1960s.
AI (Shows you a blue muscle car image)
You:Make it a convertible with the top down.
AI (Updates the image, now a convertible muscle car)
You:Change the color to a vibrant, sunny yellow.
AI (Again, updates the image, now a yellow convertible muscle car)

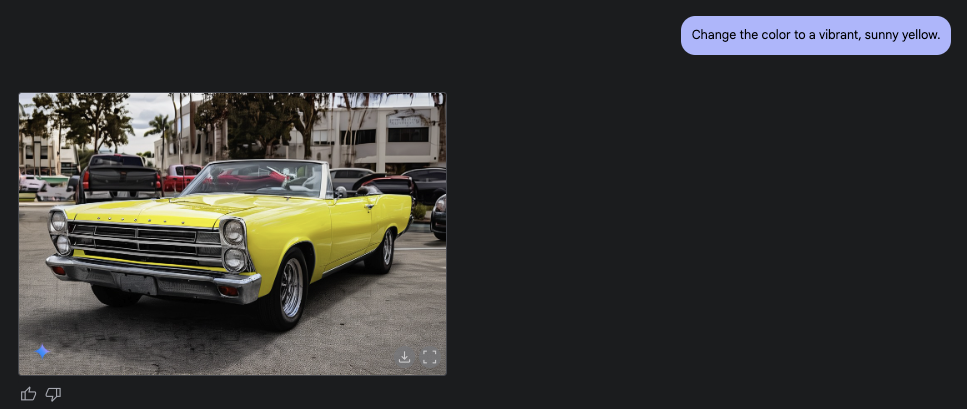
This back-and-forth, where the model remembers your previous instructions and the image's history, makes image refinement remarkably intuitive and efficient. It's like having a visual assistant that understands your creative vision as it evolves.
2. Gemini API: Programmatic Image Power
For developers looking to weave image generation directly into applications or automated workflows, the Gemini API offers a powerful and flexible programmatic route. Leveraging the google-genai Python library, integrating this capability is surprisingly straightforward.
Basic Text-to-Image Generation with Python:
First, ensure you have the necessary library installed in your Python environment:
!pip install -U -q "google-genai>=1.5.0"Now, let's examine a Python code snippet to generate an image programmatically:
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client() # Assumes API key is configured, e.g., via environment variable
contents = "Generate a photorealistic image of a vibrant parrot perched on a tropical flower."
response = client.models.generate_content(
model="models/gemini-2.0-flash-exp",
contents=contents,
config=types.GenerateContentConfig(response_modalities=['Text', 'Image'])
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image_data = part.inline_data.data
image = Image.open(BytesIO(image_data))
image.save("parrot.png") # Or image.show() to display directlyCode Breakdown:
-
client = genai.Client(): Initializes the Gemini client. This assumes your API key is already set up, for instance, as an environment variable namedGOOGLE_API_KEY. -
model="models/gemini-2.0-flash-exp": Specifies the experimental Gemini 2.0 Flash model for image generation using the correct model ID format for the API. -
contents = "...": Your text prompt describing the desired image. -
config=types.GenerateContentConfig(response_modalities=['Text', 'Image']): This is key!response_modalities=['Text', 'Image']tells the API to expect both text and image outputs in the response. -
Image Handling: The code iterates through the response parts. If a part contains
inline_data(image data), it opens the image using PIL and saves it as "parrot.png". You could alternatively useimage.show()to display the image directly instead of saving it.
Before running this code:
-
Set up your API key: Ensure you have a Google AI Studio API key and have configured it. One common method is to set the
GOOGLE_API_KEYenvironment variable. Refer to the Gemini API documentation for detailed instructions on API key setup and authentication.
Gemini 2.0 Flash in Action: Real-World Use Cases
Gemini 2.0 Flash's native image generation isn't just a tech demo; it's a versatile toolkit with game-changing potential across numerous fields. Let's explore some compelling applications:
1. Cantonese Visual Storytelling: Bridging Languages with Images
Gemini 2.0 Flash transcends language barriers, generating image sequences to accompany stories, even in languages like Cantonese. This showcases its ability to connect text and visuals across different linguistic contexts, opening doors for culturally relevant content.
Creating a Cantonese Children's Story:
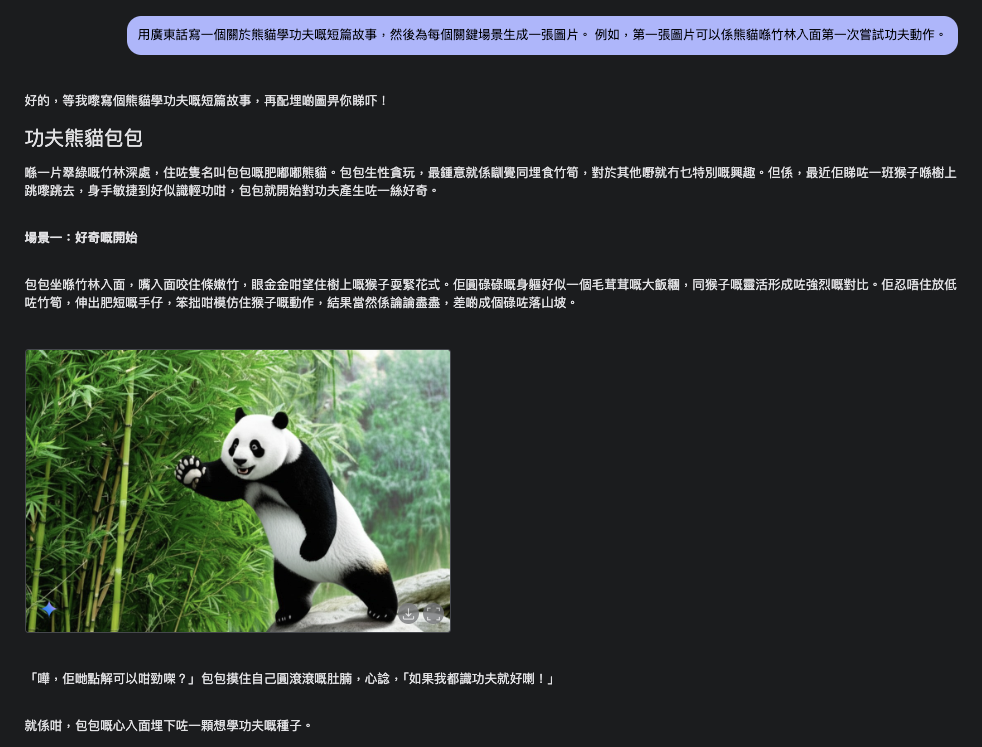
Imagine crafting a children's story in Cantonese about a playful panda learning Kung Fu. You could provide a Cantonese narrative and instruct Gemini 2.0 Flash to generate a series of images, one for each key scene. The model is designed to maintain consistency in characters, settings, and overall mood throughout the visual narrative.
Example Cantonese Prompt (for a story about a Panda learning Kung Fu):
用廣東話寫一個關於熊貓學功夫嘅短篇故事,然後為每個關鍵場景生成一張圖片。 例如,第一張圖片可以係熊貓喺竹林入面第一次嘗試功夫動作。
(Translation: Write a short story in Cantonese about a panda learning Kung Fu, and then generate an image for each key scene. For example, the first image could be a panda in a bamboo forest trying Kung Fu moves for the first time.)
While explicit confirmation for Cantonese image generation is still emerging, Gemini's robust multilingual capabilities, including Chinese, strongly suggest this is already possible or will be soon. This unlocks exciting opportunities for Cantonese-speaking communities to create culturally relevant educational materials, engaging children's stories, and targeted marketing campaigns that resonate deeply.




2. From 2D Image to 3D Model: Generating Objects for Meshy AI and Beyond
Synthetic data generation takes an exciting turn when we combine Gemini 2.0 Flash with tools like Meshy AI. Instead of just creating static 2D images of 3D objects, we can use Gemini 2.0 Flash to generate the input for 2D-to-3D conversion services, opening up a streamlined pathway to create 3D models.
The Power of Synergy: Gemini 2.0 Flash + 2D-to-3D AI
This approach leverages the strengths of both technologies:
- Gemini 2.0 Flash: excels at generating diverse and customizable 2D images of objects from text prompts, allowing for control over style, viewpoint, and lighting.
- Meshy AI (or similar services): specializes in reconstructing 3D models from single or multiple 2D images.
By using Gemini 2.0 Flash to create the 2D image, we gain a powerful and flexible way to generate the precise visual input needed for 3D model creation in tools like Meshy AI.
The Workflow: Image to 3D Model in a Few Steps
- Step 1. Generate a 2D Image with Gemini 2.0 Flash: Use a text prompt to describe the 3D object and desired viewpoint. Focus on creating a clear, well-defined image from a single perspective that will be easily interpreted by a 2D-to-3D tool.
Example Prompts for 2D Image Generation (for 3D conversion):
-
"Render a photorealistic image of a classic red sports car from a standard side view with plain background."
(Focus on a clear side view for easier 3D reconstruction)

Step 2. Download the Generated Image: Save the image generated by Gemini 2.0 Flash to your computer.
Step 3. Upload to Meshy AI (or a similar 2D-to-3D service): Visit the Meshy AI website (or your chosen 2D-to-3D conversion platform) and upload the 2D image you just generated.
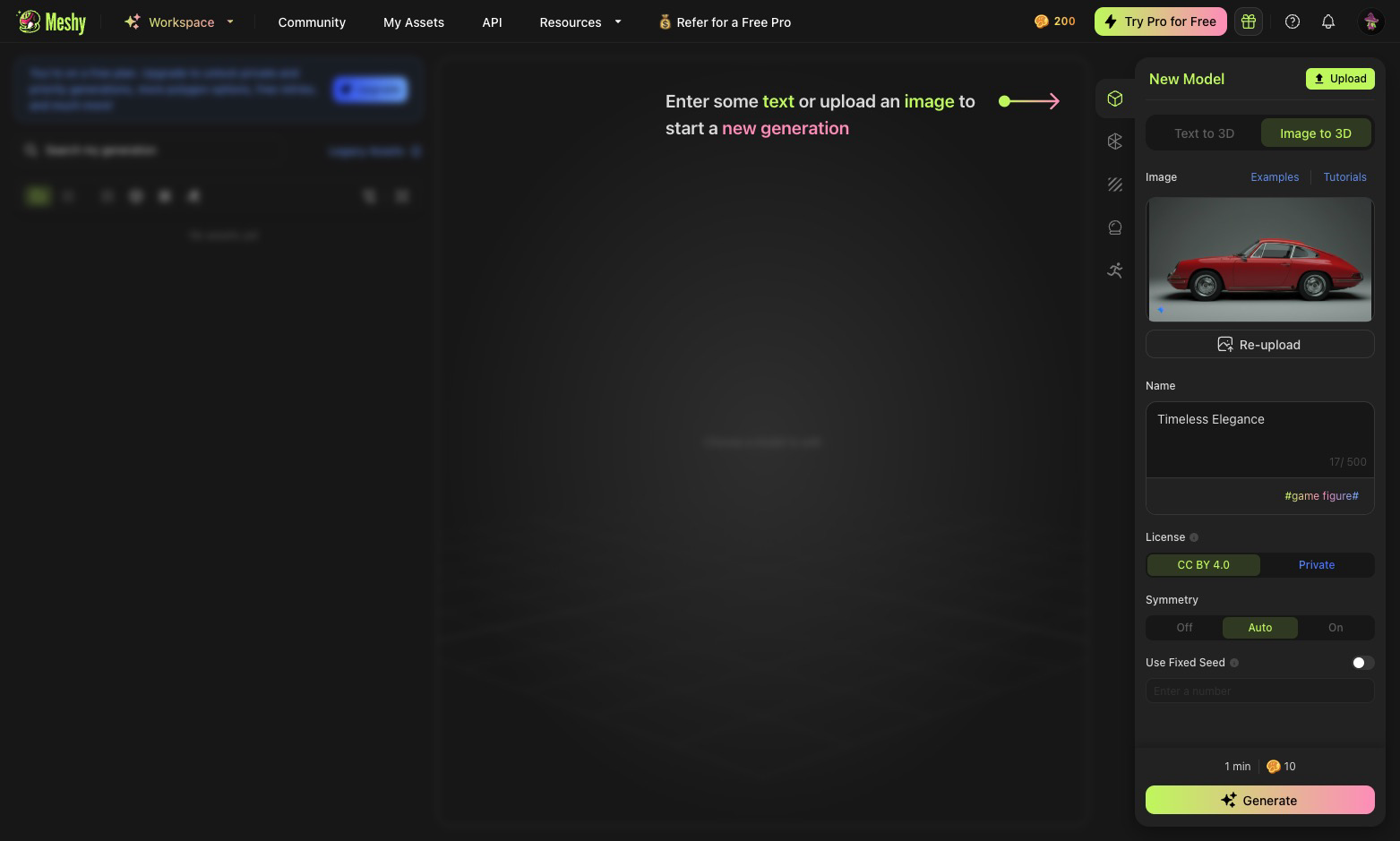
- Step 4. Generate the 3D Model: Follow the instructions on the Meshy AI platform to initiate the 2D-to-3D conversion process. Meshy AI will analyze the 2D image and reconstruct a 3D model based on its interpretation of the visual information.
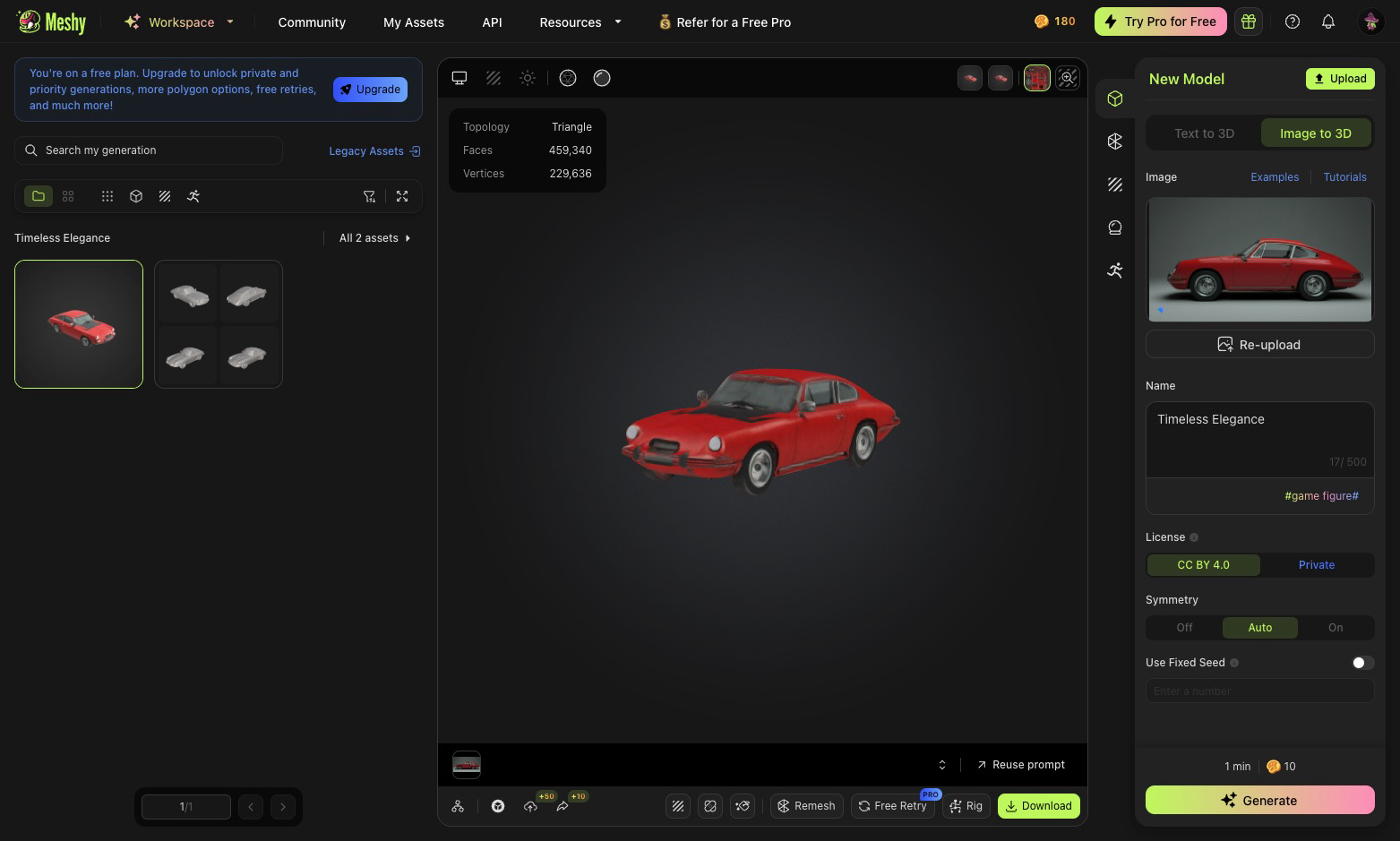
- Step 5. Download and Use the 3D Model: Once Meshy AI has processed the image, you can typically download the generated 3D model in a common 3D file format (like .obj or .glb) and use it in your 3D projects, game development, virtual environments, or other applications.
3. OCR Training Data: Enhancing Text Recognition with Synthetic Handwriting
Optical Character Recognition (OCR) systems rely on vast datasets of text images for effective training. Gemini 2.0 Flash can generate images of handwritten text, providing invaluable synthetic data to improve OCR accuracy and robustness.
Addressing the Challenges of Handwriting Recognition:
Real-world handwriting is incredibly varied. Synthetic handwriting data can:
- Capture Style Diversity: Generate samples encompassing a wide range of handwriting styles, slants, pressure variations, and letter formations.
- Simulate Real-World Imperfections: Introduce realistic noise, smudges, and variations to mimic the imperfections found in real handwritten documents.
- Reduce Bias: Address potential biases in existing datasets by generating samples of underrepresented handwriting styles, leading to more inclusive and accurate OCR systems.
Example Prompts for Handwriting Data Generation:
"Generate an image of the sentence: 'The quick brown fox jumps over the lazy dog.' written in elegant cursive handwriting."

"Generate multiple images of the English word 'Example' written in various messy and hurried handwriting styles."

This capability is particularly critical for developing more accurate and reliable OCR models for processing historical documents, handwritten notes, and multilingual text recognition tasks, where handwriting variability is a significant challenge.
Conclusion: Visual AI is Here
Gemini 2.0 Flash's native image generation is a significant leap, democratizing visual creation through accessible tools like AI Studio and the API. This technology has the power to transform content creation, accessibility, and AI research. Experiment and explore the future of AI visuals with Gemini 2.0 Flash.


