🤖 Ever Wondered How ChatGPT or Gemini Works?
We all have used AI tools like ChatGPT or Gemini, but have you ever wondered how these tools are able to generate such accurate responses to our queries? 🤔
In this blog, we’ll get an overview of how AI models generate responses — and along the way, we’ll learn some jargon 🧠 that you often see floating around the internet 🌐.
🧩 AI Jargon You’ll Learn in This Blog
Let’s walk through the working of an AI model while exploring these terms:
- 🔤 LLM
- 🧠 GPT (Generative Pre-trained Transformer)
- ⚙️ Transformer
- 🧱 Tokens
- 📥 Encoder / Encoding
- 📍 Positional Encoding
- 📤 Decoder / Decoding
- 🧮 Vectors
- 🔗 Embedding
- 🧠 Semantic Meaning
- 👁️ Self Attention
- 🎯 SoftMax
- 🧠 Multi-Head Attention
- 🌡️ Temperature
- 📅 Knowledge Cutoff
- ✂️ Tokenization
- 📚 Vocab Size
🤔 What is AI?
- AI is basically an algorithm trained on data. After training, it generates output based on learned weights in response to a user query.
⚙️ Transformer
- An AI model is a mathematical structure that has learned patterns from data.
- A Transformer is a type of deep learning architecture that’s especially good at understanding sequences like text or audio.
- It was introduced by Google in 2017 in a paper called: 📄 Attention is All You Need
🤖 GPT
- GPT stands for Generative Pre-trained Transformer.
- It’s a pre-trained transformer that generates the next token based on the data it has seen.
- 🏋️ Training GPT is expensive and time-consuming, so it’s not retrained frequently.
- Thus, GPT has a knowledge cutoff — it doesn’t know anything that happened after its last training.
🔍 Fun Fact: ChatGPT combines GPT with an agent system in the background.
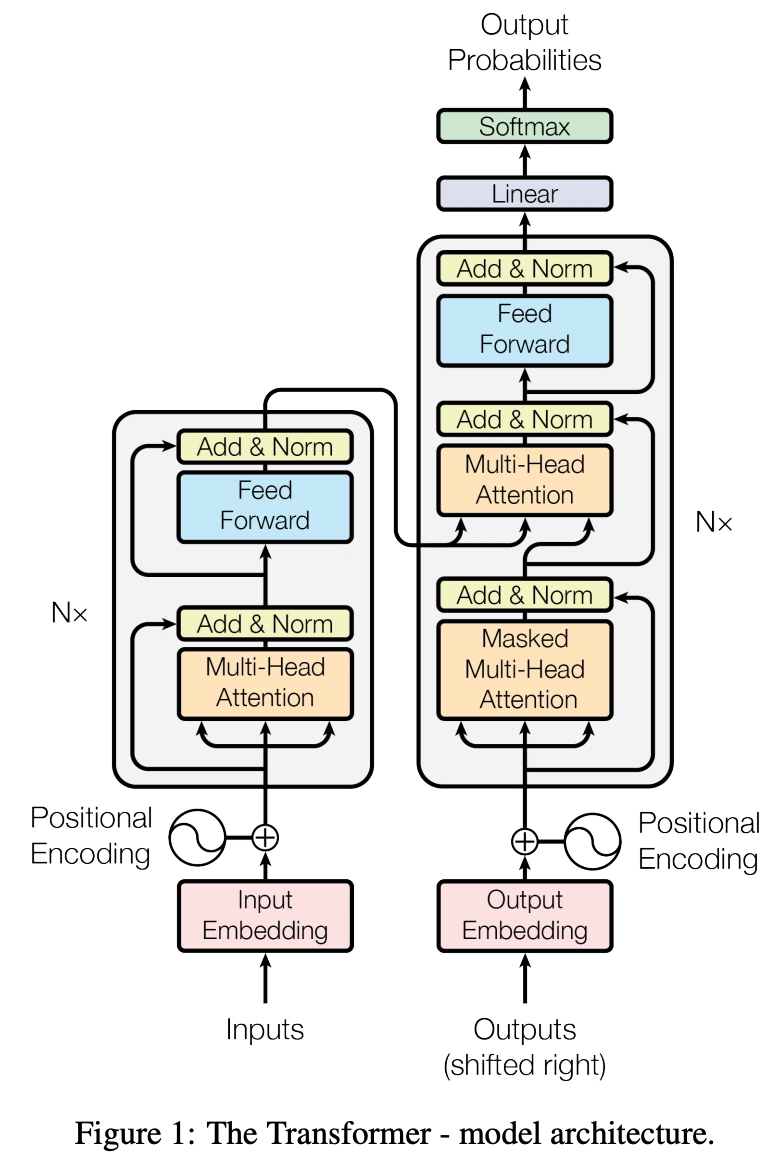
🧱 Transformer Model Architecture
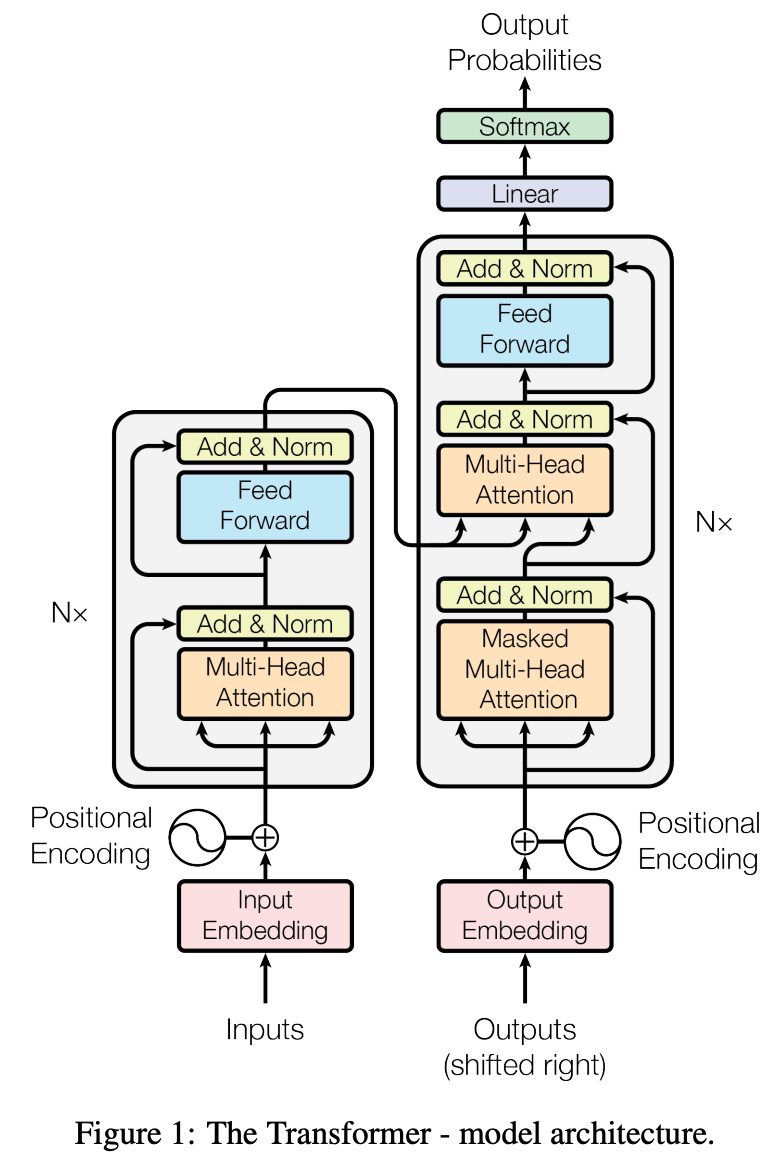
At first glance, this architecture might seem scary 😨, but it becomes simple when explained properly. Let’s break it down:
🧾 Input Query & Tokenization
- Input: The query provided by the user.
- AI models like LLMs don’t understand human languages directly — they understand numbers.
- So, we convert the input into numbers — this process is called Tokenization.
- A token is a word or piece of a word.
- The token ID is the numeric representation.
- Libraries like tiktoken (used by OpenAI) perform tokenization.
🔤 Vocabulary Size = Total number of unique tokens in the tokenizer's dictionary.
🧰 Tokenizer
- A tokenizer is separate from the model.
- It has a fixed vocabulary: a mapping of words (tokens) to numbers (token IDs).
- The model doesn’t “know” words — it only understands token IDs.
- During inference:
- If a new word appears, the tokenizer:
- Breaks it into known sub-tokens, or
- Uses an unknown token placeholder.
- So, vocab size = number of unique tokens the model can recognize.
👉 Tokenizer visualizer: tiktokenizer.vercel.app
🧪 Tokenizer Code Example
from tiktoken._educational import *
import tiktoken
encoder = tiktoken.get_encoding("o200k_base")
print("encoder", encoder)
print("vocab size", encoder.n_vocab)
tokens = encoder.encode('Hello World, How are you?')
print("tokens", tokens)
decoded_text = encoder.decode(tokens)
print("decoded_text", decoded_text)
print(tiktoken.encoding_for_model('text-embedding-3-small'))
encoder_for_model = tiktoken.encoding_for_model("gpt-4o")
print("encoder_for_model", encoder_for_model)
# Train a BPE tokeniser on a small amount of text
enc = train_simple_encoding()
print("enc", enc)
# Visualise how the GPT-4 encoder encodes text
another_encoder = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
print(another_encoder.encode("hello world aaaaaaaaaaaa"))🧠 Embeddings (Vector & Positional)
🧮 Vector Embedding
- A vector embedding is the numerical representation of tokens that captures semantic meaning.
- Semantic meaning = meaning of the word in a specific context.
- "Reserve Bank" vs "Bank of a river" — same word, different meanings.
✨ Imagine "cat" as a point in space:
[0.2, 1.3, -0.5, ...]
- These embeddings can be stored in vector databases like:
- 🔍 Pinecone
- 🌌 Chroma DB
- 🧭 Qdrant
🧭 Visualize embeddings here: TensorFlow Projector
🧠 Semantic Example
- King ➡️ Queen implies Man ➡️ ?
- If "Queen" is 3 units down and "Man" is 4 units left of "King" in vector space — then the model can estimate the missing word using vector math ✨.
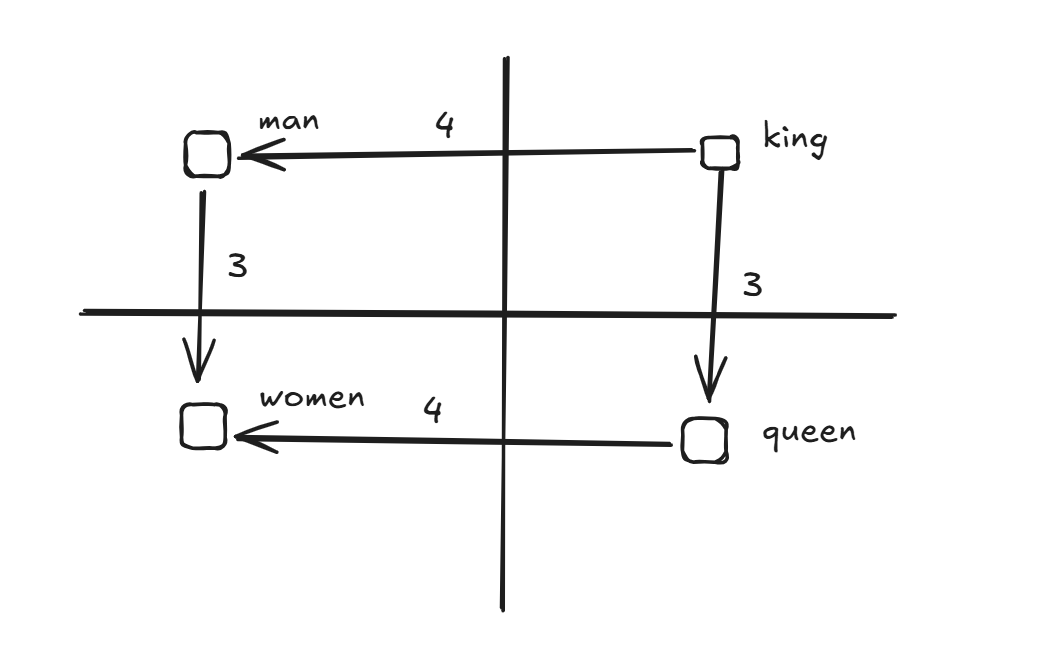
📍 Positional Embedding
- Tokens alone don’t carry position info.
- Two sentences with the same words but different order mean very different things!
- "The cat sat on the mat"
- "The mat sat on the cat"
So, we use positional embeddings to give the model context of order.
🛠️ These modify the original embedding to reflect word position in the sentence.
📥 Embedding Example with OpenAI
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
text = "Eiffel tower is in Paris and is a famous landmark, it is 324 meters tall"
response = client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
print("vector embeddings", response.data[0].embedding)🔄 Self Attention Mechanism
In simple terms: Tokens can talk to each other and update themselves! 🧠💬
- This means when two tokens interact, they can update their vector embeddings based on the sentence and with respect to each other.
- Example:
"river bank"- When these 2 tokens talk to each other, they update their embeddings based on the context.
- So even if the word
"bank"appears in both"river bank"and"icici bank", and both have: - the same token,
- the same original vector embedding,
- and the same positional embedding,
- the final vector embedding will differ because of how they interact with other tokens in the sentence.
- Tokens update their embeddings based on all tokens in the sentence — not just one or two.
- So what does self-attention do?
- It allows tokens to adjust their embeddings based on the other tokens present in the input. 🔁
🧠 Multi-Head Attention — Seeing Things in Many Ways
Think of it like observing the sentence from multiple perspectives at once! 👀🔍
- It helps the model focus on different aspects/perspectives of the tokens simultaneously.
- At its heart, attention is about weighing the importance of different input tokens when focusing on a specific one.
- Multi-head attention runs multiple attention operations in parallel (called “heads”) and combines their results.
- This allows the model to learn various types of relationships between tokens — all at the same time. 💡🧩
🔗 Feed Forward
It’s a neural network that processes each token individually after attention is done. 🛠️
- The interaction cycle between Multi-Head Attention and Feed Forward is repeated many times to get a rich contextual result.
- In GPT (and Transformers in general), after using attention to understand word relationships, the model sends the result through a Feed Forward Neural Network (FFN).
🧠 "Okay, I understand which words matter (thanks to attention)...
Now let me do some math on each word to extract more meaning!" ➗🔍
⚙️ How It Works
- The Feed Forward block is just a small, regular neural network applied to each token individually.
Here's what happens:
- Each token (word embedding) goes into a Linear layer (fully connected).
- Then through a ReLU or GELU activation (for non-linearity).
- Then again through another Linear layer.
- The output replaces the old one and continues through the Transformer stack.
🧱 Formula:
FFN(token) = Linear -> Activation -> Linear🧠 Why Is It Important?
- Attention handles relationships between words.
- Feed Forward handles processing each word by itself, like extracting deeper meanings and features. 🌱
🔁 Simple Analogy
Attention: "Hey 'cat', pay attention to 'mat' and 'sat'!" 🐱🧘🪑
Feed Forward: "Cool. Now let me upgrade 'cat' with better features based on that context." 🚀📈
🔄 Self Attention Mechanism
In simple terms: Tokens can talk to each other and update themselves! 🧠💬
- This means when two tokens interact, they can update their vector embeddings based on the sentence and with respect to each other.
- Example:
"river bank"- When these 2 tokens talk to each other, they update their embeddings based on the context.
- So even if the word
"bank"appears in both"river bank"and"icici bank", and both have: - the same token,
- the same original vector embedding,
- and the same positional embedding,
- the final vector embedding will differ because of how they interact with other tokens in the sentence.
- Tokens update their embeddings based on all tokens in the sentence — not just one or two.
- So what does self-attention do?
- It allows tokens to adjust their embeddings based on the other tokens present in the input. 🔁
🧠 Multi-Head Attention — Seeing Things in Many Ways
Think of it like observing the sentence from multiple perspectives at once! 👀🔍
- It helps the model focus on different aspects/perspectives of the tokens simultaneously.
- At its heart, attention is about weighing the importance of different input tokens when focusing on a specific one.
- Multi-head attention runs multiple attention operations in parallel (called “heads”) and combines their results.
- This allows the model to learn various types of relationships between tokens — all at the same time. 💡🧩
🔗 Feed Forward
It’s a neural network that processes each token individually after attention is done. 🛠️
- The interaction cycle between Multi-Head Attention and Feed Forward is repeated many times to get a rich contextual result.
- In GPT (and Transformers in general), after using attention to understand word relationships, the model sends the result through a Feed Forward Neural Network (FFN).
🧠 "Okay, I understand which words matter (thanks to attention)...
Now let me do some math on each word to extract more meaning!" ➗🔍
⚙️ How It Works
- The Feed Forward block is just a small, regular neural network applied to each token individually.
Here's what happens:
- Each token (word embedding) goes into a Linear layer (fully connected).
- Then through a ReLU or GELU activation (for non-linearity).
- Then again through another Linear layer.
- The output replaces the old one and continues through the Transformer stack.
🧱 Formula:
FFN(token) = Linear -> Activation -> Linear🧠 Why Is It Important?
- Attention handles relationships between words.
- Feed Forward handles processing each word by itself, like extracting deeper meanings and features. 🌱
🔁 Simple Analogy
Attention: "Hey 'cat', pay attention to 'mat' and 'sat'!" 🐱🧘🪑
Feed Forward: "Cool. Now let me upgrade 'cat' with better features based on that context." 🚀📈
🚀 Two Phases of a Model
- 🔧 Training Phase
- 🧠 Inference Phase (using phase)
🔧 Training Phase
Let’s break it down:
- In the training phase, we match input and output.
- We provide the input, the model gives us an output, we compare it with the actual output, calculate the loss, and then backpropagate it (backpropagation = वapas jao 😄).
Example Flow:
-
Input:
my name is piyush -
Actual Output:
my name is piyush I am good -
Model Output:
my name is piyush xsfd@e
Then:
- We calculate the loss between the model’s output and the actual output.
- We send it back through the model to adjust the weights.
- We repeat this until the model starts giving the expected output. 🔁
✅ Goal: Allow the model to update its weights using the training data.
⚙️ This backpropagation and weight update process requires a lot of compute power, hence heavy GPU usage 💻🔥.
🧠 Inference Phase: Using the model
Time to use what we've trained! 😎
- We provide an input to the model:
-
token→vector embedding➕positional embedding→ 🎯multi-head attention
-
⚡ Technically, the model generates multiple possible outputs for a given input.
🧪 Example:
-
Input:
how are you? - Raw Outputs: I, S, U
- The
linearstep calculates probabilities for each token. -
Example Output (with probabilities):
- I (98%) ✅
- S (5%)
- U (0.3%)
The Softmax step picks the one with the highest probability.
🎛️ Temperature Parameter:
- Used by
Softmaxto control randomness.- Higher temperature → more randomness (might pick a less probable token).
- Lower temperature → more deterministic (sticks to highest probability).
🪜 Steps Breakdown
-
STEP 1:
-
Input:
how are you? - Probabilities: I (98%), S (5%), U (0.3%)
- Chosen: I
- ✅ Final Output:
how are you? I
-
Input:
-
STEP 2:
-
Input:
how are you? I - Probabilities: _am (80%), few (5%), good (4%)
- Chosen: _am
- ✅ Final Output:
how are you? I_am
-
Input:
-
STEP 3:
- The process continues iteratively 🔁
(until it reaches the
- The process continues iteratively 🔁
(until it reaches the
📚 Extra Info
- 📜 The Transformer model was introduced by Google in the research paper "Attention is All You Need".
- 🗣️ Originally created for Google Translate, the idea was to understand and translate semantic meaning using NLP.
- 🧠 This means it was built with language understanding in mind.
🔍 GPT (by OpenAI) was based on the transformer —
But instead of translation, it was built for next token prediction 🧩


