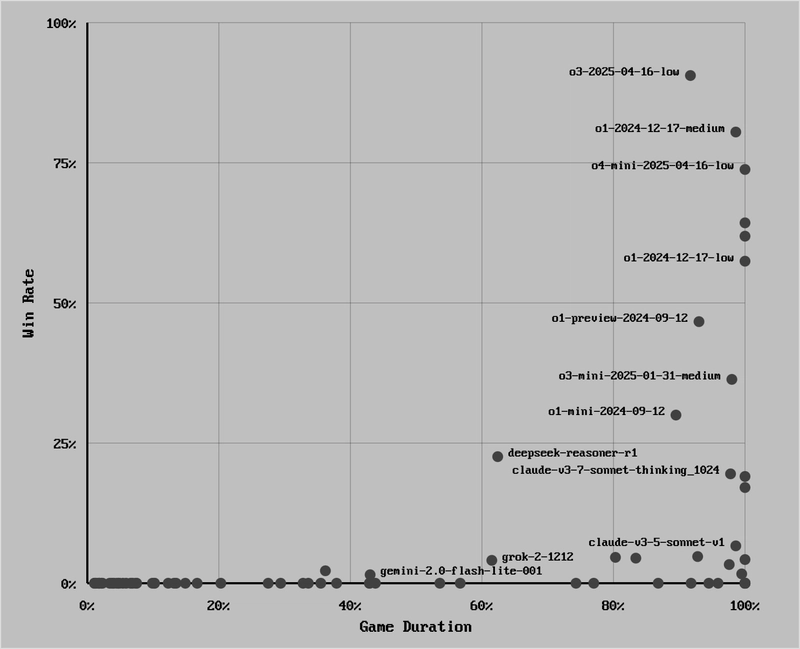
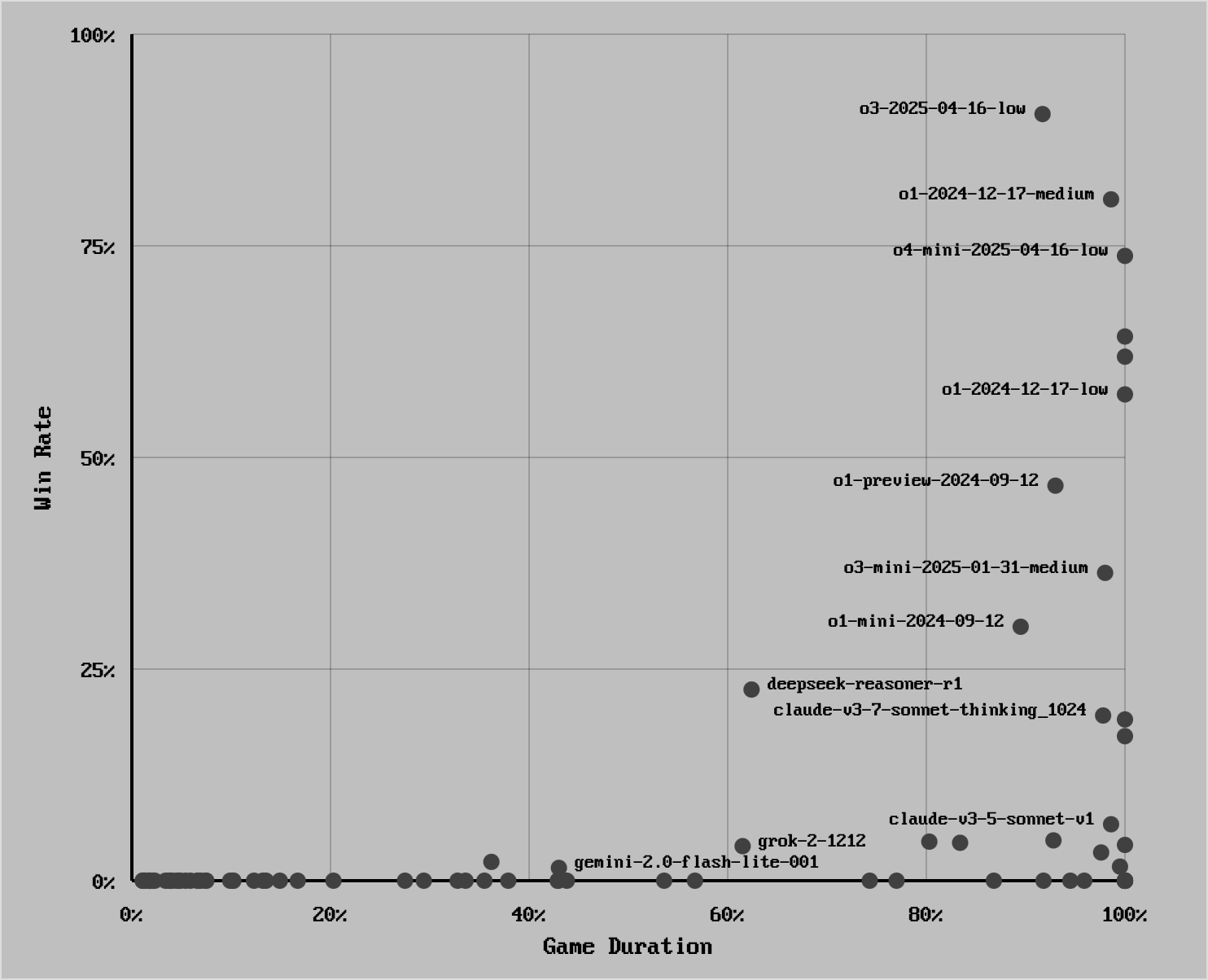
This will be a quick post. I've ran the recent OpenAI models through LLM Chess eval:
- o4-mini and o3 demonstrate solid chess performance and instruction following
- GPT 4.1 didn't qualify due to multiple model errors
- 4.1 Mini is a good increment over 4o Mini, 4.1 Nano didn't impress
Below is a matrix view of models' performance with Y-axis showing chess proficiency and X-axis instruction following:
P.S> The "Notes" section of the leaderboard web site dives deeper into model's performance.


