🧠 Overview
The Image Generator is a web-based application that allows users to generate custom images using text or voice prompts. It utilizes AWS services such as Amazon Bedrock's Nova Canvas model for image generation and AWS Transcribe for converting voice input into text. The application has a React + HTML/CSS frontend, a FastAPI backend hosted on an EC2 instance, and uses Amazon S3 for image storage.
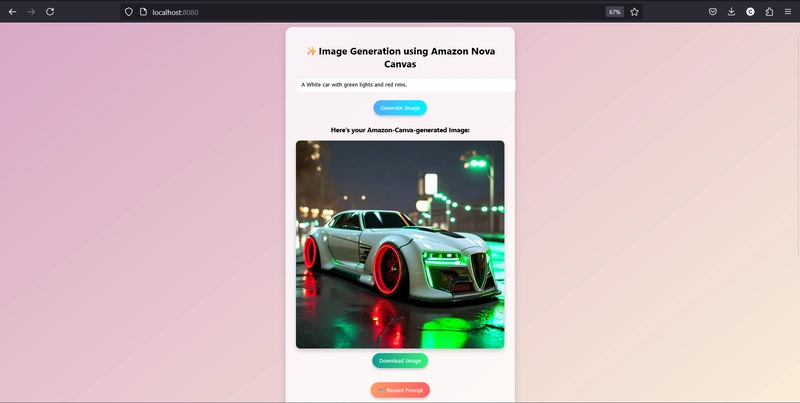
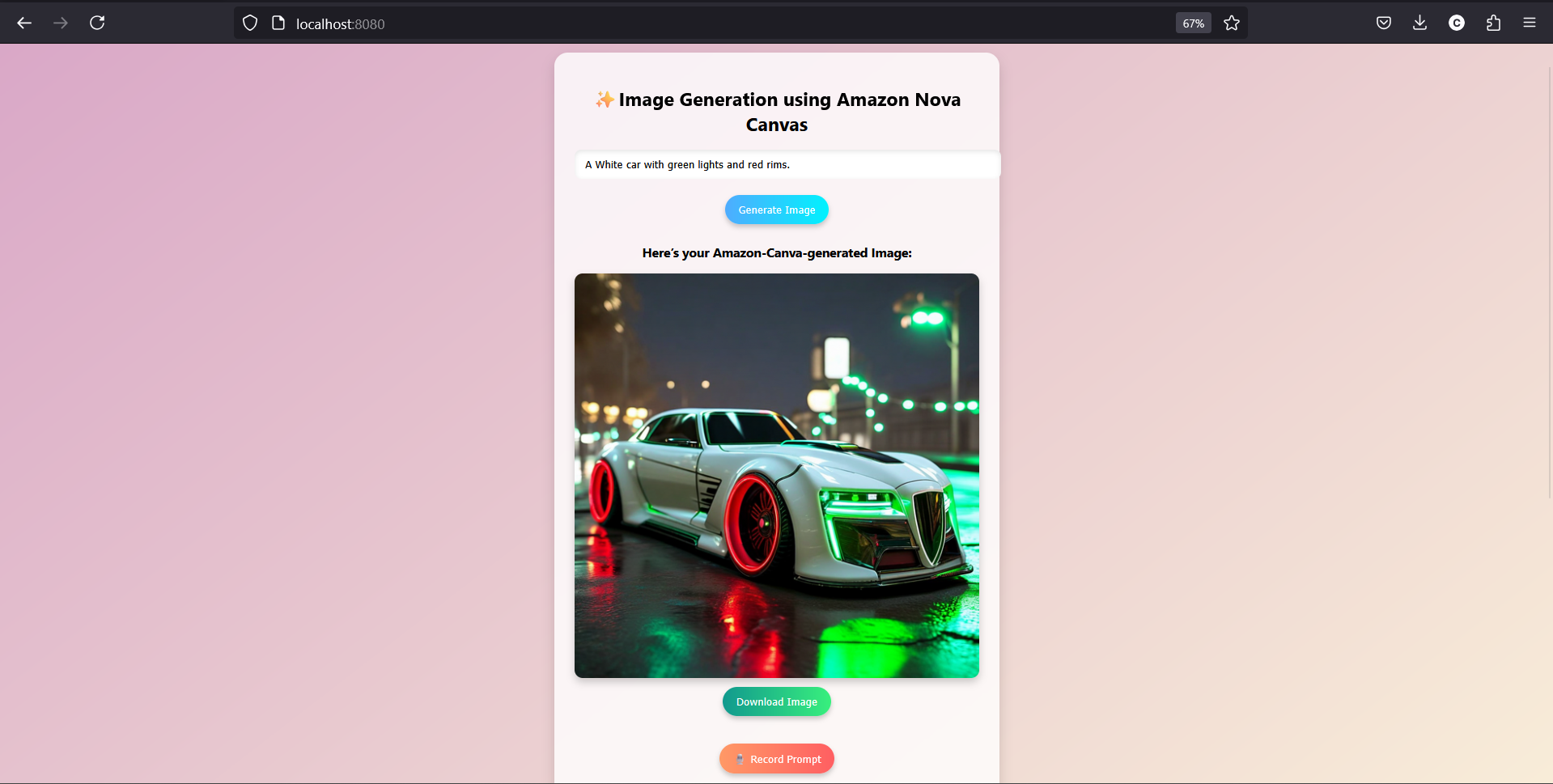
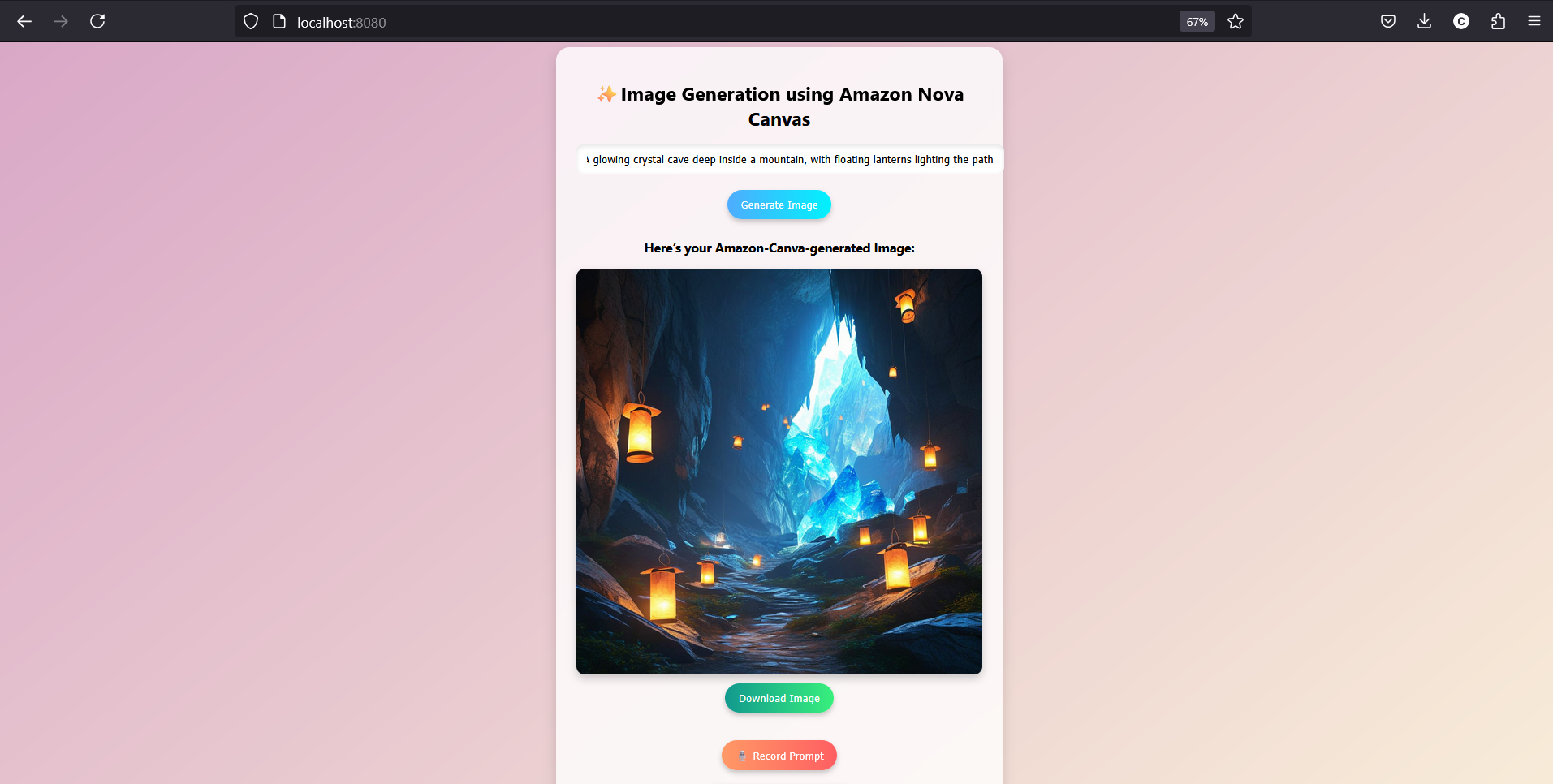
🎥 Image Showcase
Check out these cool images the web-based application generated using Amazon Nova Canvas:
🎥 Demo Video
Want to see it in action?
👉 Watch the full working demo of the Image Generator
✨ Amazon Nova Canvas Model - Why and How I Used It
The Amazon Nova Canvas model was chosen for its:
- ✨ Photorealistic image generation capabilities.
- ⏱ Low-latency inference through Amazon Bedrock.
- 🧠 Structured prompt compatibility, allowing controlled and formatted input.
- 🔌 Seamless API integration with Bedrock, reducing the need for infrastructure management.
How I Used It (Technical Execution)
I have used the model via the Bedrock API by sending a structured message payload. Here’s how:
- I have structured the input like a conversation, as expected by Nova Canvas.
- The following is the core FastAPI code (main.py) that handles prompt input, connects to Amazon Bedrock, and returns the generated image:
from fastapi import FastAPI, Form, UploadFile, File
from fastapi.responses import StreamingResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
from io import BytesIO
import boto3
import base64
import json
import os
import time
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# Clients
s3_client = boto3.client("s3")
transcribe_client = boto3.client("transcribe")
bedrock_client = boto3.client("bedrock-runtime", region_name="us-east-1")
# S3 bucket
BUCKET_NAME = "bedrock-video-generation-us-east-1-6jywv6"
@app.post("/generate")
async def generate_wallpaper(prompt: str = Form(...)):
body = {
"messages": [
{
"role": "user",
"content": [{"text": prompt}]
}
]
}
try:
response = bedrock_client.invoke_model(
modelId="amazon.nova-canvas-v1:0",
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
response_body = json.loads(response["body"].read())
base64_image = response_body["output"]["message"]["content"][0]["image"]["source"]["bytes"]
# Save and return image
output_path = "output_wallpaper.png"
with open(output_path, "wb") as f:
f.write(base64.b64decode(base64_image))
return StreamingResponse(open(output_path, "rb"), media_type="image/png")
except Exception as e:
return JSONResponse(status_code=500, content={"error": str(e)})
@app.post("/transcribe")
async def transcribe_audio(file: UploadFile = File(...)):
# Step 1: Upload to S3
job_name = f"transcription-job-{int(time.time())}"
s3_key = f"uploads/{job_name}.wav"
s3_client.upload_fileobj(file.file, BUCKET_NAME, s3_key)
s3_uri = f"s3://{BUCKET_NAME}/{s3_key}"
# Step 2: Start transcription job
transcribe_client.start_transcription_job(
TranscriptionJobName=job_name,
Media={"MediaFileUri": s3_uri},
MediaFormat="wav",
LanguageCode="en-US",
OutputBucketName=BUCKET_NAME
)
# Step 3: Poll until the job finishes
while True:
status = transcribe_client.get_transcription_job(TranscriptionJobName=job_name)
job_status = status["TranscriptionJob"]["TranscriptionJobStatus"]
if job_status in ["COMPLETED", "FAILED"]:
break
time.sleep(2)
if job_status == "FAILED":
return JSONResponse(status_code=500, content={"error": "Transcription failed"})
# Step 4: Get transcript from S3
transcript_uri = status["TranscriptionJob"]["Transcript"]["TranscriptFileUri"]
transcript_json = boto3.client("s3").get_object(
Bucket=BUCKET_NAME,
Key=f"{job_name}.json"
)
transcript_data = json.loads(transcript_json["Body"].read())
transcript_text = transcript_data["results"]["transcripts"][0]["transcript"]
return {"prompt": transcript_text}- This payload is sent via the FastAPI backend to the Bedrock API using the model ID
amazon.nova-canvas-v1:0. - The response contains an image blob which is returned to the frontend and rendered for the user.
This allowed users to see their ideas transformed into visuals almost instantly.
- On the frontend, I have built a React application where users can type or speak their prompts. Here's App.js file that shows how we send the prompt to the backend and render the generated image:
import React, { useState } from 'react';
import axios from 'axios';
import { ReactMediaRecorder } from "react-media-recorder";
function App() {
const [prompt, setPrompt] = useState("");
const [image, setImage] = useState(null);
const [loading, setLoading] = useState(false);
// Function to handle wallpaper generation
const handleGenerate = async (textPrompt) => {
if (!textPrompt) {
alert("Please provide a prompt.");
return;
}
setLoading(true);
const formData = new FormData();
formData.append("prompt", textPrompt);
try {
const response = await axios.post("http://98.81.151.118:8000/generate", formData, {
responseType: 'blob'
});
const imageUrl = URL.createObjectURL(response.data);
console.log("✅ Image generated:", imageUrl);
setImage(imageUrl);
} catch (error) {
console.error("❌ Error generating wallpaper:", error);
alert("Error generating image.");
} finally {
setLoading(false);
}
};
// Handle audio file upload and transcription
const handleGenerate = async (textPrompt) => {
setLoading(true);
const formData = new FormData();
formData.append("prompt", textPrompt); // Append the prompt as form data
try {
// Send form data instead of JSON
const response = await axios.post("http://98.81.151.118:8000/generate", formData, {
responseType: 'blob', // Ensure the response is a blob (image)
});
// Create an object URL from the blob response and set it to the state
setImage(URL.createObjectURL(response.data));
} catch (error) {
console.error("❌ Error generating wallpaper:", error);
alert("Error generating image");
} finally {
setLoading(false);
}
};
return (
style={{ padding: "2rem", textAlign: "center" }}>
1>🎨 AI Wallpaper Generator1>
{/* Text input for manual prompt */}
type="text"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
placeholder="Describe your wallpaper..."
style={{ width: "300px", marginRight: "1rem" }}
/>
onClick={() => handleGenerate(prompt)}>Generate
/> />
{/* Audio recorder button */}
audio
render={({ startRecording, stopRecording }) => (
onMouseDown={startRecording}
onMouseUp={stopRecording}
>
🎙️ Hold to Speak
)}
onStop={handleAudioUpload}
/>
{loading && ✨ Generating wallpaper...}
{/* Image display */}
{image && (
src={image}
alt="Generated Wallpaper"
style={{ marginTop: "2rem", maxWidth: "90%", borderRadius: "12px" }}
/>
)}
);
}
export default App;In addition to the React frontend, I have also built a lightweight index.html version using plain HTML, JavaScript, and the MediaRecorder API. This ensures the app remains functional in environments where React isn’t available or during testing:
html>
lang="en">
charset="UTF-8" />
✨Image Generation using Amazon Nova Canvas
body {
margin: 0;
padding: 0;
font-family: 'Segoe UI', sans-serif;
background: linear-gradient(to bottom right, #d9a7c7, #fffcdc);
display: flex;
flex-direction: column;
align-items: center;
padding-top: 40px;
transition: background-color 0.3s, color 0.3s;
}
.container {
background: rgba(255, 255, 255, 0.8);
backdrop-filter: blur(10px);
border-radius: 20px;
padding: 30px;
max-width: 600px;
width: 90%;
box-shadow: 0 8px 20px rgba(0, 0, 0, 0.15);
text-align: center;
}
h1 {
margin-bottom: 20px;
font-size: 28px;
}
input[type="text"] {
padding: 12px 16px;
font-size: 16px;
width: 100%;
border: none;
border-radius: 10px;
margin-bottom: 15px;
box-shadow: inset 0 2px 6px rgba(0,0,0,0.1);
}
button {
padding: 12px 20px;
font-size: 16px;
border: none;
border-radius: 30px;
margin: 10px 5px;
cursor: pointer;
transition: background 0.3s, transform 0.2s;
box-shadow: 0 4px 8px rgba(0,0,0,0.2);
}
button:hover:not(:disabled) {
transform: translateY(-2px);
}
button:disabled {
background-color: #ccc;
cursor: not-allowed;
}
#generateBtn {
background: linear-gradient(to right, #4facfe, #00f2fe);
color: white;
}
#recordBtn {
background: linear-gradient(to right, #ff9966, #ff5e62);
color: white;
}
#stopBtn {
background: linear-gradient(to right, #f2709c, #ff9472);
color: white;
display: none;
}
#downloadLink button {
background: linear-gradient(to right, #11998e, #38ef7d);
color: white;
}
.loading-spinner {
border: 4px solid #f3f3f3;
border-top: 4px solid #4fa3f7;
border-radius: 50%;
width: 30px;
height: 30px;
animation: spin 2s linear infinite;
margin: 10px auto;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
.mic-animation {
font-size: 40px;
animation: bounce 1s infinite;
}
@keyframes bounce {
0%, 100% { transform: translateY(0); }
50% { transform: translateY(-10px); }
}
#audioStatus {
font-size: 16px;
color: #2e7d32;
margin-top: 10px;
display: none;
}
img {
max-width: 100%;
border-radius: 12px;
box-shadow: 0 6px 12px rgba(0,0,0,0.2);
}
#output {
display: none;
}
.gallery {
margin-top: 40px;
display: flex;
flex-wrap: wrap;
gap: 16px;
justify-content: center;
}
.gallery-item {
width: 180px;
background: white;
border-radius: 12px;
overflow: hidden;
box-shadow: 0 4px 8px rgba(0,0,0,0.15);
cursor: pointer;
text-align: center;
position: relative;
}
.gallery-item img {
width: 100%;
height: auto;
}
.gallery-item p {
margin: 10px;
font-size: 14px;
padding: 0 8px;
}
.delete-btn {
position: absolute;
top: 10px;
right: 10px;
background-color: red;
color: white;
border: none;
border-radius: 50%;
padding: 5px;
cursor: pointer;
font-size: 12px;
}
.gallery-item:hover .delete-btn {
display: block;
}
#gallerySearch {
width: 90%;
padding: 12px;
font-size: 16px;
border-radius: 8px;
margin-bottom: 20px;
}
body.dark-mode {
background-color: #333;
color: #fff;
}
body.dark-mode .container {
background: rgba(40, 40, 40, 0.8);
}
body.dark-mode .gallery-item {
background: #444;
}
body.dark-mode .gallery-item p {
color: #eee;
}
class="container">
1>✨Image Generation using Amazon Nova Canvas1>
type="text" id="prompt" placeholder="Describe your image idea..." />
id="generateBtn" onclick="generate()">Generate Image
id="loading" class="loading-spinner" style="display:none;">
id="output">
3>Here’s your Amazon-Canva-generated Image:3>
id="wallpaper" src="" alt="Generated wallpaper" />
id="downloadLink" download="image.png">
Download Image
/>
id="recordBtn" onclick="startRecording()">🎙️ Record Prompt
id="stopBtn" onclick="stopRecording()" disabled>Stop
id="audioStatus"> class="mic-animation">🎤 Recording...
/>
onclick="toggleDarkMode()">🌙 / 🌞 Toggle Dark Mode
class="container">
2>🖼️ Gallery2>
type="text" id="gallerySearch" placeholder="Search in gallery..." oninput="searchGallery()" />
class="gallery" id="gallery">
onclick="exportImages()">Export All Images
id="imageModal" style="display:none;">
style="position:fixed; top:0; left:0; width:100%; height:100%; background: rgba(0, 0, 0, 0.7);">
style="color:white; font-size: 40px; position: absolute; top: 10px; right: 10px; cursor: pointer;" onclick="closeModal()">✖
id="modalImage" style="width:100%; max-height: 90%; object-fit: contain; margin-top: 50px;" />
<span class="w"> src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.10.1/jszip.min.js">
let mediaRecorder, audioChunks = [], history = [];
async function startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
document.getElementById("recordBtn").disabled = true;
document.getElementById("recordBtn").style.display = "none";
document.getElementById("stopBtn").disabled = false;
document.getElementById("stopBtn").style.display = "inline-block";
document.getElementById("audioStatus").style.display = "block";
mediaRecorder = new MediaRecorder(stream);
mediaRecorder.ondataavailable = e => audioChunks.push(e.data);
mediaRecorder.onstop = async () => {
const audioBlob = new Blob(audioChunks, { type: 'audio/wav' });
audioChunks = [];
document.getElementById("audioStatus").style.display = "none";
await transcribeAudio(audioBlob);
};
mediaRecorder.start();
} catch (err) {
console.error("Mic error:", err);
alert("Microphone access denied.");
}
}
function stopRecording() {
if (mediaRecorder && mediaRecorder.state === "recording") {
mediaRecorder.stop();
document.getElementById("recordBtn").disabled = false;
document.getElementById("recordBtn").style.display = "inline-block";
document.getElementById("stopBtn").disabled = true;
document.getElementById("stopBtn").style.display = "none";
}
}
async function transcribeAudio(audioBlob) {
const formData = new FormData();
formData.append("file", audioBlob, "audio.wav");
try {
const res = await fetch("http://98.81.151.118:8000/transcribe", {
method: "POST",
body: formData
});
const data = await res.json();
document.getElementById("prompt").value = data.prompt;
await generate();
} catch (err) {
alert("Transcription failed.");
}
}
async function generate() {
const prompt = document.getElementById("prompt").value.trim();
if (!prompt) return alert("Enter a prompt first!");
document.getElementById("loading").style.display = "block";
document.getElementById("generateBtn").disabled = true;
try {
const res = await fetch("http://98.81.151.118:8000/generate", {
method: "POST",
headers: { "Content-Type": "application/x-www-form-urlencoded" },
body: new URLSearchParams({ prompt })
});
if (!res.ok) throw new Error("Failed to generate image");
const blob = await res.blob();
const imageUrl = URL.createObjectURL(blob);
document.getElementById("wallpaper").src = imageUrl;
document.getElementById("downloadLink").href = imageUrl;
document.getElementById("output").style.display = "block";
addToHistory(prompt, imageUrl);
} catch (err) {
alert("Error: " + err.message);
}
document.getElementById("loading").style.display = "none";
document.getElementById("generateBtn").disabled = false;
}
function addToHistory(prompt, imageUrl) {
history.unshift({ prompt, imageUrl });
localStorage.setItem("wallpaperHistory", JSON.stringify(history));
renderGallery();
}
function renderGallery() {
const gallery = document.getElementById("gallery");
gallery.innerHTML = "";
history.forEach((item, index) => {
const div = document.createElement("div");
div.className = "gallery-item";
div.innerHTML = `
src="${item.imageUrl}" onclick="viewImage('${item.imageUrl}')" />
Image ${index + 1}
${item.prompt}
class="delete-btn" onclick="deleteFromHistory(${index})">❌
`;
gallery.appendChild(div);
});
}
function viewImage(url) {
document.getElementById("modalImage").src = url;
document.getElementById("imageModal").style.display = "block";
}
function closeModal() {
document.getElementById("imageModal").style.display = "none";
}
function deleteFromHistory(index) {
history.splice(index, 1);
localStorage.setItem("wallpaperHistory", JSON.stringify(history));
renderGallery();
}
function searchGallery() {
const query = document.getElementById("gallerySearch").value.toLowerCase();
const filteredHistory = history.filter(item => item.prompt.toLowerCase().includes(query));
renderFilteredGallery(filteredHistory);
}
function renderFilteredGallery(filteredHistory) {
const gallery = document.getElementById("gallery");
gallery.innerHTML = "";
filteredHistory.forEach((item, index) => {
const div = document.createElement("div");
div.className = "gallery-item";
div.innerHTML = `
src="${item.imageUrl}" onclick="viewImage('${item.imageUrl}')" />
Image ${index + 1}
${item.prompt}
class="delete-btn" onclick="deleteFromHistory(${index})">❌
`;
gallery.appendChild(div);
});
}
function exportImages() {
const zip = new JSZip();
history.forEach((item, index) => {
zip.file(`image${index + 1}.png`, fetch(item.imageUrl).then(res => res.blob()));
});
zip.generateAsync({ type: "blob" }).then(content => {
const link = document.createElement("a");
link.href = URL.createObjectURL(content);
link.download = "images.zip";
link.click();
});
}
function toggleDarkMode() {
document.body.classList.toggle("dark-mode");
}
window.onload = () => {
const saved = localStorage.getItem("wallpaperHistory");
if (saved) {
history = JSON.parse(saved);
renderGallery();
}
};
Enter fullscreen mode
Exit fullscreen mode
🏗️ Project Architecture
User → React Frontend
→ FastAPI Backend
→ /transcribe → AWS Transcribe (voice to text)
→ /generate → Amazon Nova Canvas via Bedrock (text to image)
→ (Gallery*) → Session-based temporary history
Enter fullscreen mode
Exit fullscreen mode
🛠️ Technologies Used
Frontend:
ReactJS
MediaRecorder API
Axios
Vanilla JS fallback (index.html)
Backend:
FastAPI (Python)
Hosted on Amazon EC2 (Amazon Linux 2)
AWS Services:
Amazon Bedrock (Nova Canvas) – AI-generated images
AWS Transcribe – Converts voice to text
Amazon S3 – Optional audio storage
🔁 Application Flow
Text Prompt:
User types a description (e.g., "black car with green lights")
Sent to /generate
Image returned and displayed for download
Voice Prompt:
User records voice with MediaRecorder
Audio sent to /transcribe
Transcribed to text via AWS Transcribe
Used as input for /generate
Image generated and displayed
📡 Backend Endpoints
POST /transcribe
Input: Audio file
Process:
Save audio blob
Send to AWS Transcribe
Return transcribed text as { "prompt": "..." }
POST /generate
Input: Prompt string (form-urlencoded)
Process:
Create structured message
Invoke Nova Canvas model
Return image blob
🖥️ Frontend Modes
Text Input: User can type any creative idea and press Generate
Voice Input: Uses MediaRecorder to capture audio
Result: Image is displayed and can be downloaded
Fallback HTML version (index.html) includes:
Input field and generate button
Record button (asks for microphone permission)
Real-time rendering of generated image
🗣️ Voice-to-Image Flow (Deep Dive)
Recording via MediaRecorder
Upload to /transcribe
Transcription via AWS Transcribe
Automatic generation via /generate with transcribed prompt
Rendering on the frontend
Key Design Considerations:
Use of temporary file handling for audio blob
Parsing transcription response and routing to generation
Handling microphone permissions and browser compatibility
✅ Be sure microphone access is allowed in the browser.
🎯 Conclusion
This project demonstrates how voice and text can serve as natural inputs for generating rich visuals using generative AI. By combining Amazon Bedrock, Nova Canvas, and AWS Transcribe, I have built a smooth, scalable app that lets users bring their imagination to life.

