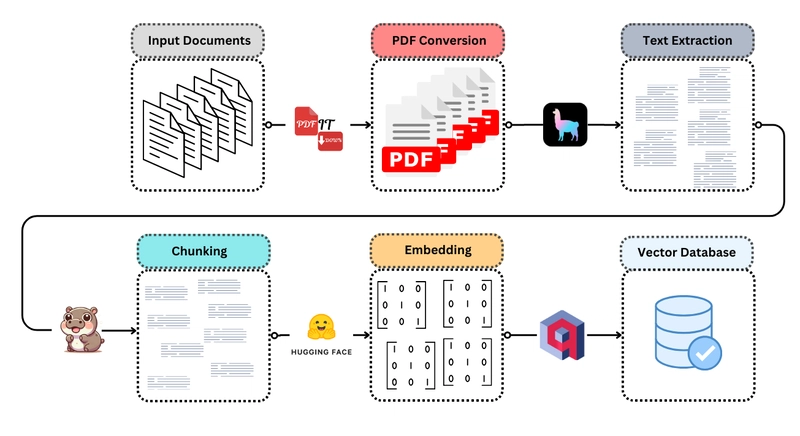
One of my areas of focus, recently, has been the development of a universal and zero-effort way of converting text-based documents (and even images) into PDF files, so that they could fit into my RAG pipelines, that are optimized for that format. In the end, after almost 30 "This is the last git commit", I came up with PdfItDown, a python package capable of transforming the most commonly used file formats into PDF, and it can do so with single or multiple files (and even entire folders!).
After that, tho, I wasn't satisfied: converting files to PDF is ok, but they're unplugged from the main ingest-into-DB pipeline, which might be still a lot of effort to design and optimize. Then it came the idea: why don't I create a standardized, simple and yet powerful, fully-automated procedure to go from a non-PDF file to vector data loaded into a database?
The tools were already there:
- PdfItDown can handle file transformation
- LlamaIndex has the readers to turn PDFs into text files
- Chonkie offers a versatile and mighty chunking toolbox
- Sentence Transformers are a widely use embeddings library that could provide text encoders
- Qdrant is an easy-to-set-up, highly performing and scalable vector database, that offers numerous functionalities (among which hybrid search and metadata filtering).
What's even better? All these tools are open source!🎉
So it was just a matter of combining them - and that's how ingest-anything came to life:
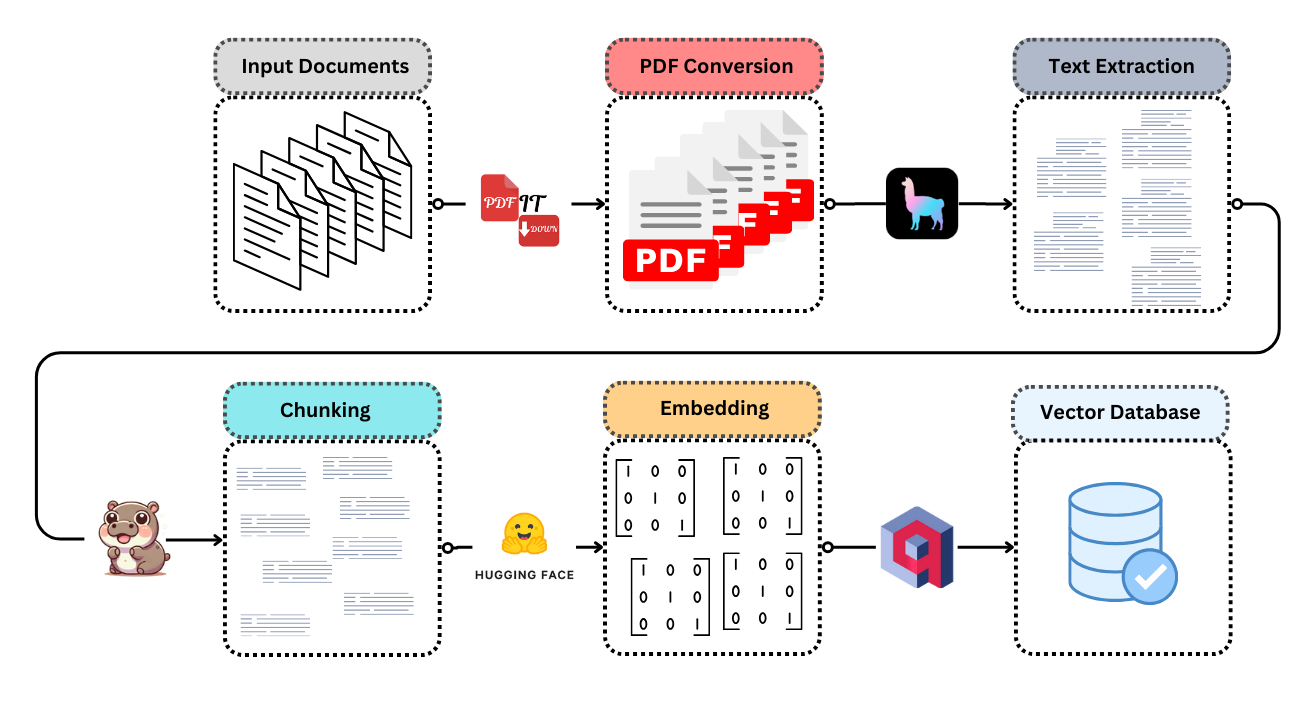
Simple, elegant and all-in-one!
Let's see how we can use it to ingest files:
- We install it:
pip install ingest-anything
# or, if you prefer a faster installation
uv pip install ingest-anything- We set up a local Qdrant instance with Docker:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant:latest- We initialize the ingestor:
from ingest_anything.ingestionn import IngestAnything, QdrantClient, AsyncQdrantClient
ingestor = IngestAnything(qdrant_client = QdrantClient("http://localhost:6333"), async_qdrant_client = AsyncQdrantClient("http://localhost:6333"), collection_name = "flowers", hybrid_search=True)- We ingest our files...:
ingestor.ingest(chunker="late", files_or_dir=['tests/data/test.docx', 'tests/data/test0.png', 'tests/data/test1.csv', 'tests/data/test2.json', 'tests/data/test3.md', 'tests/data/test4.xml', 'tests/data/test5.zip'], embedding_model="sentence-transformers/all-MiniLM-L6-v2")- Or an entire directory!
# with a directory
ingestor.ingest(chunker="token", files_or_dir="tests/data", tokenizer="gpt2", embedding_model="sentence-transformers/all-MiniLM-L6-v2")And we're done! In three lines of code we've ingested all non-PDF files (in a list or in a directory) into a Qdrant collection, which we can now query for RAG purposes!
As you can see, you can act on several levels, customizing the embedding model, the chunking method (check out Chonkie docs for this), the tokenizer (when necessary), a lot of chunking parameters (that you can optionally set or leave as default), and you can also turn on and off the hybrid search, (optionally) choosing the sparse model to use among the ones available through FastEmbed.
So what are you waiting? Grab your PC and try this out: I can guarantee that speedrunning effortlessly through documents ingestion in a vector DB is highly satisfying (and addictive)!


