
This is a Plain English Papers summary of a research paper called LiveVQA: AI Challenges Answering Visual Questions with Real-Time Knowledge. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
LiveVQA: Building a Benchmark for Live Visual Knowledge
Introduction
LiveVQA introduces a new benchmark dataset that tests AI systems on their ability to answer questions requiring the latest visual knowledge from the internet. Unlike text-based knowledge problems which have seen significant advances through search-integrated language models, visual knowledge questions remain challenging for current AI systems.
The researchers created LiveVQA with three key design principles: strict temporal filtering to prevent dataset contamination, automated ground truth with human verification, and high-quality authentic image-question pairs. The dataset contains 1,233 news articles with 3,602 visual questions across 14 domains, sourced from six major global news platforms.
Each instance in LiveVQA contains a representative image paired with three types of questions: a basic visual understanding question (Level 1) and two multi-hop questions requiring deeper reasoning and contextual knowledge (Levels 2-3).

LiveVQA comprises 14 different News categories, containing 1233 News and 3602 question-answer pairs.
The LiveVQA Dataset
The dataset provides comprehensive coverage across 14 news categories and 6 major global news sources. It features high-quality image-text coherence and authentic information, with each instance carefully designed to test different levels of visual reasoning ability.
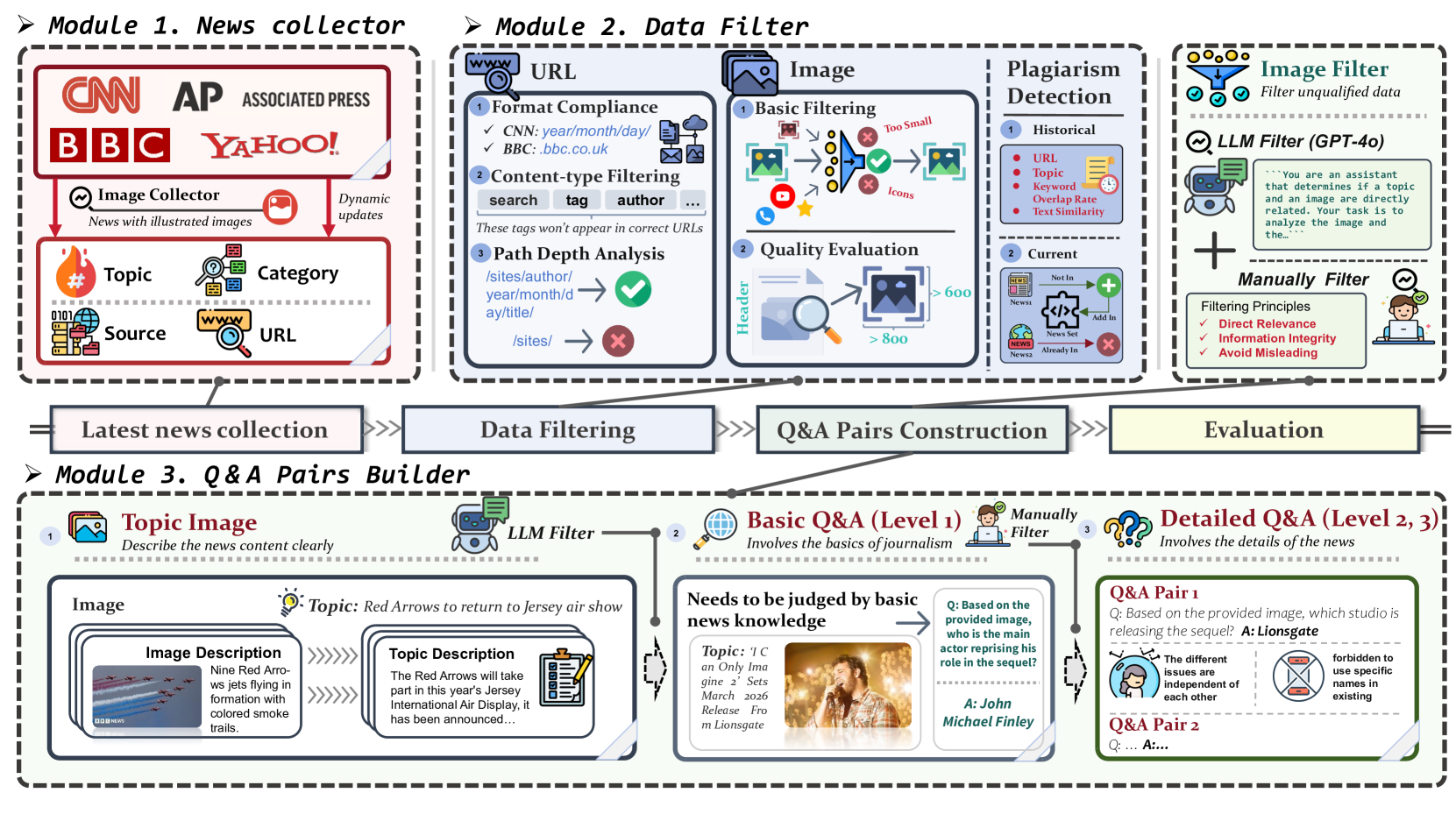
Pipeline of LiveVQA data engine showing the three main modules: news collector, data filter, and Q&A pairs builder.
The distribution of news instances shows meaningful patterns across categories and sources:
| Category | Overall | By News Source (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Count | % | VRTY | BBC | CNN | APNWS | FORB | YHO | |
| Sports | 305 | 24.8 | 1.0 | 48.8 | 20.3 | 7.5 | 15.5 | 0.0 |
| Other | 219 | 17.8 | 1.0 | 17.3 | 25.3 | 28.4 | 13.6 | 30.0 |
| Movies | 102 | 8.3 | 36.7 | 0.7 | 1.7 | 6.0 | 5.8 | 0.0 |
| TV | 89 | 7.2 | 31.0 | 1.8 | 2.1 | 2.5 | 4.9 | 5.0 |
| Science | 80 | 6.5 | 0.0 | 5.5 | 7.1 | 16.9 | 0.0 | 20.0 |
| Economy | 72 | 5.8 | 0.0 | 4.4 | 7.9 | 8.0 | 14.6 | 10.0 |
| Health | 67 | 5.4 | 1.0 | 6.6 | 3.3 | 12.4 | 1.0 | 5.0 |
| Media | 58 | 4.7 | 7.6 | 3.1 | 7.5 | 3.5 | 1.9 | 5.0 |
| Music | 47 | 3.8 | 11.9 | 2.0 | 0.8 | 3.0 | 4.9 | 0.0 |
| G.Business | 45 | 3.7 | 1.9 | 1.8 | 7.5 | 2.5 | 6.8 | 15.0 |
| Tech | 45 | 3.7 | 2.4 | 2.6 | 4.2 | 3.0 | 10.7 | 5.0 |
| Opinion | 45 | 3.7 | 1.0 | 2.4 | 8.3 | 2.5 | 5.8 | 5.0 |
| Art/Design | 43 | 3.5 | 0.0 | 2.4 | 4.2 | 4.0 | 13.6 | 0.0 |
| Theater | 15 | 1.2 | 4.8 | 0.9 | 0.0 | 0.0 | 1.0 | 0.0 |
| Total | 1,232 | 100 | 210 | 457 | 241 | 201 | 103 | 20 |
| Source % | 100 | 17.1 | 37.1 | 19.6 | 16.3 | 8.4 | 1.6 |
Table 1. The distribution of 1,232 news instances across 14 categories and 6 major sources, containing 3,602 VQA.
Dataset Construction
The LiveVQA dataset construction involved three main steps:
Data Collection: The researchers selected six global news platforms (CNN, BBC, Yahoo, Forbes, AP News, and Variety) for comprehensive geographic coverage and content diversity. The collection process included URL normalization to filter out advertisements and indexes, structured content extraction using site-specific CSS selectors, and image filtering to prioritize content-relevant images.
Raw Data Filtering: To ensure dataset quality, a multi-level filtering mechanism was implemented, covering URL validation, image screening, and duplicate removal. This involved website-specific filters, quality prioritization for images, and hierarchical deduplication techniques.
Question-Answer Generation: GPT-4o was employed to generate QA pairs from raw news documents. Each sample comprises an image reflecting the news topic, a basic question about image content, and two multi-hop detailed questions requiring cross-modality reasoning. The basic questions focus on substantive elements like people, objects, or locations, while avoiding queries solely reliant on visual properties like color. The multi-hop questions require deeper contextual reasoning and must be answerable only through the news text.
This careful construction process ensures high-quality visual question answering data that can properly test models' capabilities with latest visual knowledge.
Data Statistics
The final dataset contains 1,232 news items spanning 14 categories and 6 global news platforms, amounting to 3,602 QA pairs. The dataset shows distinct domain specificity - sports news is the most prevalent category, with a significant portion sourced from BBC. News sources also exhibit clear domain preferences: Variety primarily covers film and music, Forbes focuses on business, and AP News emphasizes science and health.
This diverse coverage makes the dataset ideal for comprehensive evaluation of visual question answering capabilities across different domains.
Experiments and Analysis
Experiment Setups
The researchers conducted zero-shot testing on 15 state-of-the-art multimodal large language models (MLLMs), including Gemini 2.0 Flash, Qwen2.5-VL series (3B to 72B), Gemma-3 series (4B to 27B), QVQ-72B-Preview, QVQ-Max, GPT-4o-mini, and GPT-4o.
The evaluation also tested models with search engine capabilities, enabling built-in search functionalities and MM-Search with Gemini-2.0-Flash, GPT-4o-mini, and GPT-4o. For evaluation, GPT-4o-mini was instructed as an impartial judge to provide binary (yes/no) correctness assessments.
Experiment Results
The evaluation revealed several important findings:
| Model | Avg. | L1 | L2 | L3 | Per. | Loc. | Tim. | Eve. | Org. | Obj. | Rea. | Oth |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w.o. Search | ||||||||||||
| Gemma-3-4b-it | 14.65 | 38.42 | 3.10 | 2.46 | 19.20 | 11.96 | 2.82 | 14.51 | 26.75 | 28.37 | 2.89 | 10.26 |
| Gemma-3-12b-it | 17.10 | 44.19 | 3.47 | 3.71 | 23.96 | 15.78 | 5.08 | 15.95 | 29.40 | 29.58 | 2.69 | 12.25 |
| Gemma-3-27b-it | 20.43 | 48.50 | 7.93 | 4.92 | 29.19 | 17.77 | 2.82 | 20.50 | 34.46 | 35.21 | 5.17 | 15.23 |
| Qwen2.5-VL-3B | 15.63 | 39.98 | 4.58 | 2.38 | 25.65 | 13.29 | 3.11 | 12.98 | 28.67 | 27.89 | 2.89 | 5.30 |
| Qwen2.5-VL-7B | 18.74 | 41.28 | 7.44 | 3.63 | 29.43 | 17.61 | 3.07 | 16.89 | 30.23 | 33.82 | 2.87 | 10.67 |
| Qwen2.5-VL-32B | 18.96 | 47.93 | 5.12 | 3.88 | 27.19 | 17.61 | 2.82 | 17.54 | 33.49 | 35.21 | 4.75 | 8.61 |
| Qwen2.5-VL-72B | 21.07 | 55.93 | 5.94 | 1.35 | 32.87 | 20.60 | 4.52 | 19.59 | 35.66 | 32.96 | 3.51 | 12.25 |
| GPT-4o | 16.38 | 41.02 | 4.54 | 3.62 | 2.61 | 21.43 | 5.08 | 18.68 | 28.67 | 41.97 | 6.20 | 15.23 |
| GPT-4o-mini | 17.30 | 43.71 | 4.95 | 3.19 | 5.84 | 21.93 | 3.67 | 20.05 | 32.53 | 41.13 | 6.20 | 13.58 |
| Gemini-2.0-Flash | 24.93 | 58.81 | 8.75 | 5.86 | 43.01 | 20.93 | 4.24 | 19.36 | 35.66 | 43.10 | 6.61 | 19.54 |
| QVQ-72B-Preview | 19.94 | 39.90 | 11.62 | 7.41 | 21.81 | 19.44 | 2.25 | 19.95 | 34.46 | 36.52 | 10.33 | 13.58 |
| QVQ-Max | 17.80 | 38.10 | 9.50 | 4.91 | 24.88 | 17.94 | 3.67 | 15.95 | 33.01 | 26.76 | 4.34 | 11.59 |
| w. Search | ||||||||||||
| GPT-4o | 13.38 | 28.43 | 5.78 | 5.34 | 2.46 | 13.79 | 3.39 | 18.45 | 22.17 | 34.93 | 6.61 | 13.91 |
| GPT-4o-mini | 22.27 | 32.58 | 19.49 | 14.22 | 12.14 | 21.26 | 11.58 | 26.42 | 34.22 | 42.25 | 15.50 | 23.51 |
| Gemini-2.0-Flash | 29.46 | 59.63 | 16.43 | 11.03 | 44.85 | 25.91 | 11.58 | 24.60 | 44.10 | 45.63 | 9.92 | 23.51 |
| w. MM Search [12] | ||||||||||||
| GPT-4o | 20.20 | 34.88 | 15.57 | 9.32 | 8.18 | 20.75 | 16.98 | 25.97 | 34.48 | 52.38 | 8.33 | 10.64 |
| GPT-4o-mini | 21.80 | 41.28 | 14.97 | 8.07 | 24.55 | 24.53 | 7.55 | 16.88 | 31.03 | 47.62 | 10.00 | 17.02 |
| Gemini-2.0-flash | 29.00 | 49.42 | 22.75 | 13.66 | 44.55 | 26.42 | 20.75 | 20.78 | 29.31 | 42.86 | 11.67 | 27.66 |
Table 2. Overall performance on LiveVQA. See Table 5 for performance on another categorizing taxonomy for live visual knowledge.
Key findings include:
Larger models perform better: Within model families like Gemma or Qwen, increasing model size leads to consistently better accuracy across all question difficulty levels. For example, Gemma-3-4b-it achieves only 2.46% on L3-level questions, while Gemma-3-27b-it reaches 4.92%.
Strong visual reasoning helps with complex questions: Models with stronger reasoning capabilities, such as QvQ-72B-Preview, outperform their base models on multi-hop questions, highlighting the importance of visual reasoning abilities in live knowledge tasks.
| Model | Avg. | L1 | L2 | L3 |
|---|---|---|---|---|
| Qwen2.5-VL-72B | 21.07 | 55.93 | 5.94 | 1.35 |
| Short | 21.52 | 40.78 | 12.05 | 8.96 |
| Midium | 19.94 | 39.90 | 11.62 | 7.41 |
| Long | 21.71 | 41.75 | 12.47 | 10.09 |
Table 3. Performance comparison between Qwen2.5-VL-72B [35] and QvQ-72B-Preview [24] with different thinking pattern via prompt engineering.
Search engines significantly improve performance: Integrating MM-Search with Gemini-2.0-Flash boosts its average accuracy to 29.00%, with substantial gains on harder questions (22.75% on L2 and 13.66% on L3), demonstrating that retrieval-based evidence is particularly helpful for questions beyond models' internal knowledge.
Entity-centric vs. abstract knowledge: Models perform better on concrete entity recognition tasks (Person, Organization, Object) but struggle with abstract knowledge like Time and Reason, indicating limitations in causal reasoning and temporal understanding.
Domain-specific performance patterns: Models achieve higher performance in domains with rich visual and textual cues but perform poorly in ambiguous or subjective domains like Opinion.
The research also explored whether providing image captions could improve performance on more complex questions:
| Provided Info. | Avg. | L1 | L2 | L3 |
|---|---|---|---|---|
| Image | 17.30 | 43.71 | 4.95 | 3.19 |
| Image Caption | 14.83 | 34.77 | 5.28 | 3.62 |
Table 4. Performance of GPT-4o-mini on LiveVQA using image and image description as input. We find that model perform better in L2 and L3 problems when provided image caption.
This demonstrates that for more complex reasoning tasks (L2 and L3), having the image caption helps models perform better, despite lower performance on basic visual understanding questions (L1).
These findings highlight the importance of multimodal inference capabilities in solving visual question answering tasks that require up-to-date knowledge.
Error Analysis
To understand the limitations of current models, the researchers conducted a comprehensive analysis of failure cases, categorizing errors into several types:
- Recognition Error: Failure to correctly identify visual elements like people, objects, locations, or text
- Reasoning Error: Inability to perform deeper reasoning, including inference, causality, or temporal understanding
- Ambiguous Answer: Responses too generic or indirect to address the question accurately
- Privacy Restriction: Refusal to answer due to privacy or safety constraints, despite the question being valid
- Judge Error: Correct answers mistakenly marked as incorrect during evaluation
- Others: Errors not covered by the above categories, including system failures
These error categories provide valuable insights into the specific challenges that models face when dealing with visual question answering tasks requiring latest knowledge.
Related Works
The LiveVQA research builds on three key areas of previous work:
Live Knowledge Seeking: Recent advances in LLMs as search engines have shown significant progress, especially when integrated with retrieval-augmented generation (RAG) techniques. While tools like Search GPT have effectively combined RAG with online search for textual queries, multimodal search engines are still evolving to provide richer experiences integrating text, images, and other information types.
Live Visual Knowledge: Visual knowledge encompasses both factual information from external sources and commonsense understanding about objects and their interactions. Recent developments are expanding from static data to "live" visual content, addressing challenges in understanding current news, emerging events, and temporally relevant information.
News QA: News Question Answering has evolved from purely text-based approaches to NewsVQA, which integrates textual and visual information. This field faces unique challenges in multimodal fusion, temporal information processing, and scene text understanding.
Conclusion
LiveVQA provides a comprehensive benchmark for evaluating multimodal large language models on live visual knowledge tasks. The extensive experiments across 15 models reveal that while larger models generally perform better, significant challenges remain in addressing complex multi-hop visual questions that require up-to-date knowledge.
The research demonstrates that equipping models with online search tools or GUI-based image search leads to substantial performance improvements, particularly for challenging questions requiring contextual understanding and reasoning.
Despite these advances, even the best models achieve only modest accuracy (29.46% for Gemini-2.0-Flash with search), highlighting that live visual knowledge seeking remains an open challenge requiring further research.
Limitations
The researchers acknowledge several limitations of their study:
The dataset primarily structures latest information into visual question answering formats, while additional synthetic data approaches like image captioning or Chain-of-Thought reasoning could further enhance models' capabilities.
The research predominantly sources content from mainstream news websites like CNN and BBC, potentially leading to imbalance and incomplete representation of current internet content. Incorporating data from social media platforms could provide a more diverse dataset.
More robust visual search tools need to be developed to enhance model performance on latest visual knowledge queries.
These limitations point to promising directions for future research in this rapidly evolving field.
