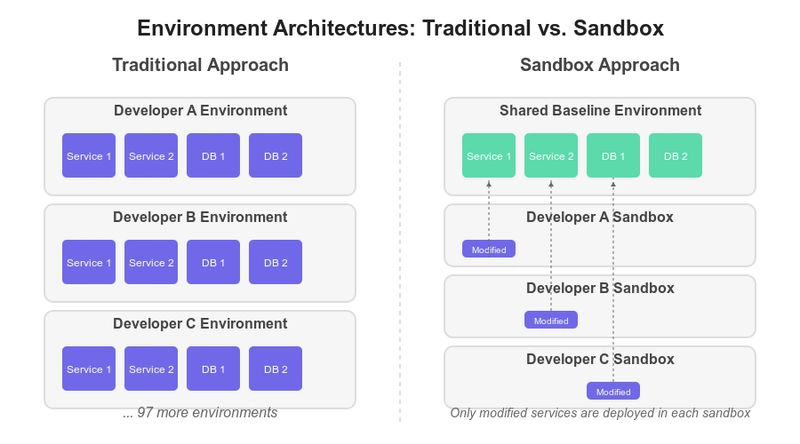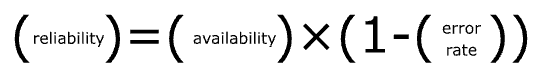
Microservices is an architectural style that breaks down an application into small, independent services that communicate with each other using well-defined APIs. These services are designed to be loosely coupled, meaning they can be developed, deployed, and scaled independently. In essence, a microservices architecture is about building applications as a collection of small, independent services that work together to achieve a larger goal.
Microservices Reliability Playbook
- Introduction to Risk
- Introduction to Microservices Reliability
- Microservices Patterns
- Read Patterns
- Write Patterns
- Multi-Service Patterns
- Call Patterns
Download the full Playbook at a free PDF
The first question being asked about micro services is how large should they be? A single function? A single file? A persistent entity and its APIs? A logical Module?
The simplest answer is that a microservice is as large as the team managing it. One team can own multiple micro services, but one micro service can be owned by only one team.
To understand this statement, one just reviews the risk of change above. If a microservice gets contributions from two or more teams, in order to release the microservice both teams have to synchronize on changes to the microservices and have all changes in a state of done. There is an added risk that one team deploys (for example, due to a hot fix) while another team change is not done, and by deploying introducing a bug.
But is that the only rule for microservices size? Actually no, there is another rule that will cause a team to have multiple microservices - managing blast radius, or the SLO (service level objectives) of the system.
Service Level Objectives
Before diving into Reliability of microservices, let's review how we define service level objectives for a software component. SLO is composed of 4 definitions
- Availability - the ability of a system to give a response, including an error response. A client calling a system and receiving a timeout (from the system, or the client decides to stop waiting), for that client the system is not available.
- Latency - the time it takes to get a response, including an error response. Do note that latency turns into an availability problem once the client or some intermediate communication element decides to stop waiting.
- Error rate - when the system gives an error that is not the fault of the client. We are talking about HTTP 500s type of errors. To be clear - HTTP 400s errors, such as a client accessing unauthorized API and getting an error should not be counted as part of this error rate - this error rate captures the inability of a system to fulfill a valid request
- Correctness - the ability of a system to give a correct response. For example, we expect the add API to return 2 for 1+1. If it returns any other number, the response is not correct. Normally, when a system is not able to return a correct response, we say it has a bug.
All the above should be measured on a per request basis, not on a time basis. The reason is that software systems do not have the same load at all times, and using time basis gives more weight to the low load periods. Take that to the extreme - a system that is up and running idle 24x7, yet gets 10 calls in one minute and fails all of them, is it 99% available (according to time basis) or 0% available (according to request basis)?
For this discussion, we define reliability as SLO availability * (1 - error rate) and measure it with the x-nines measure, or percent of operations that succeed. Five-nines means that 99.999% of the operations succeed.
As stated in the previous section, we define reliability as
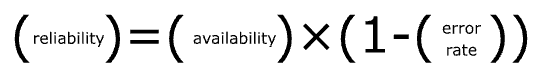
Reliability is not a global attribute of the system - instead, it is an attribute of each independent API of the system. A system with 50 APIs has 50 reliability scores, one for each API.
Side note - the above statement depends on how we define an API. If we have an API “do anything”, which performs multiple different actions based on different inputs, it is not very beneficial to measure its reliability as one API. In such a case, we can measure reliability per API and key API inputs which determine which action to perform. Consider an API such as run task, which gets a task id as an input - as different tasks can be quite different, it makes sense to compute reliability per task and not just per the API.
To measure reliability, one has to monitor each API for availability (when it is called and does not answer in a reasonable time) and error rate (when it answers with uncalled for error).
For example, an API with 10,000 calls during a day, of which
- 40 calls have failed to reach the API
- 100 calls have reached the API and timed out
- 200 calls returned a 5XX error
The API reliability is then 1 - 340/10000 = 1 - 0.034 = 9.964%.
Predicting Reliability
Reliability of a distributed system can be predicted based on only two measures of the system itself, which factor in the risks of Load and Latency and the risk of Change. Those two measures enable architects, developers and managers to predict the reliability of a system, or the impact of a change to the system on the system reliability.
The risks of security incidents and malfunctions depend on external elements and cannot be predicted from examining the distributed system itself.
The two measures are
- Number of Network hops: The number of network calls between services, up to data persistence.
- Number of Artifacts: The number of releasable software artifacts involved.
Reliability can be predicted using the two above measures by

Given we can assume the single network call reliability is five-nines or 0.99999%, and that Change Reliability per artifact is also five-nines, or 0.99999%, the model formula simplifies to

Or simplified to
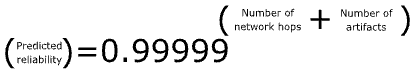
Example of Predicted Reliability
Let’s consider a toy model of a commerce cart, that includes multiple services -
- A cart service, owning the line items and cart totals calculation
- A product catalog
- A tax service, which calculates the tax depending on the items in the cart
- A shipment service, which calculates the tax depending on the items in the cart
- A coupon service, which validates coupons added to the cart and assess their value and applicability to the cart items
In addition, our micro services system has non functionals for access control and quota.
We also assume each micro service has a database, and each call to a micro service includes one query to the database.
Our system looks kind of like the following:
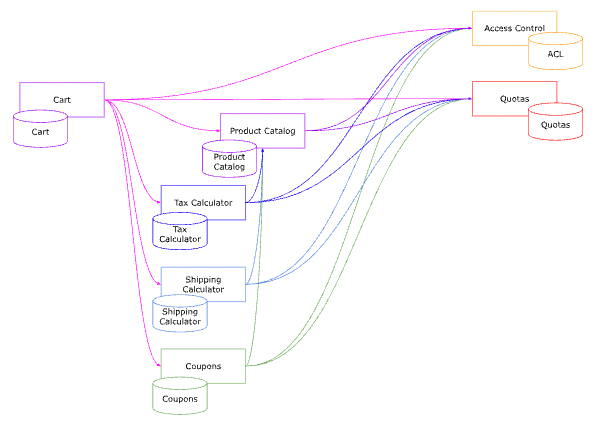
And now, let's examine the transaction to load the cart data for display, including the line items and total price.
The number of artifacts involved is 7 (with micro services we count the database as part of the micro service deployment unit).
The number of network calls is 35
- 1 Cart to Cart DB
- 6 Cart to other micro services + 6 each micro services to their DB
- 8, from 4 micro services to 2 micro services (from Product Catalog, Tax calculator, shipping calculator & coupons to Access Control & Quotas) + 8 for ACL and Quotas DB Access
- 3 additional calls to product catalog from Tax calculator, Shipping Calculator and coupons + 3 calls to product catalog DB.
Using our formula, the predicted reliability of the system is 0.99999^(35+7) = 0.9995 or 99.95%
Monitoring Microservices
Ok, we have defined how to predict the reliability of a system only using the number of network calls and artifacts. But what is the best way to monitor and create alerts on the system such that we know if we have a problem and can react fast?
Our first intuition is to set an alert every minute (or so) at an error rate of 1-5%.
But does it help? Does it guarantee we keep the SLO we aim for, be it 3-9s (99.9%), 4-9s (99.99%) or above? At the same time, does it cause too much unnecessary noise? How do we balance alerting?
Recommended Alerts Strategy
We note there are different kinds of risks which have different error patterns. Risk of change tends to cause short periods of high error rate, which we want to detect early. Risk of load and latency tends to create a constant error rate that can slightly increase or decrease depending on many factors. We want to factor both and still detect risk of change errors fast without false positives.
- We remind that reliability is defined per API, and as such to be measured per API individually, based on the number of calls to the API.
- We want to implement, per API, a measure of
- Number of calls
- Number of errors
- Latency p50, p95, p99, p999 (percentails 50, 95, 99, 99.9)
- We need to define what the latency limit is. Any API call latency above this threshold is considered also an error.
- This threshold has to be below the timeout limit, which is considered an error by default.
- or semantic threshold at which the API returns a regular response while logging the latency as an error.
- For most API, this threshold can be at around x10 of the mean latency, or x2-x3 of the p90 latency.
- We want a fast alert at a lower threshold, set as
- One minute interval for high traffic APIs
- Moving average over 5 minutes, computed every minute for lower traffic APIs
- With error rate limit of about 5-10%
- We want a slow alert at a higher threshold, set as
- One day interval, or
- One week moving average, computed daily
- At almost the SLO target limit (for 4-9s, we set error rate at ~0.001%)
Explanation
- The latency threshold is intended to detect momentary load and latency risk effects - if an API latency becomes considerably larger but does not reach the timeout threshold.
- The fast alert is intended to detect risk of change effects - if some changes cause the service to fail, we want fast feedback.
- The slow alert is intended to detect load and latency risk effects - gradual degradation over time, or a buildup of errors over time. By setting a threshold that is close to the required SLO we can both detect early and have time to react and fix.
Next: Microservices Reliability Playbook, Part 3 - Microservices Patterns