This is a Plain English Papers summary of a research paper called Monocular SLAM Handles Dynamic Scenes with 3D Gaussians & Uncertainty. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Tackling Dynamic Environments: A Key Challenge in SLAM Systems
Simultaneous Localization and Mapping (SLAM) in dynamic environments presents a fundamental challenge in computer vision. Traditional SLAM systems rely on scene rigidity assumptions, making them vulnerable to tracking errors when objects move independently. Although some recent approaches incorporate motion segmentation, semantic information, and depth-based cues to handle dynamic content, they often struggle with varied and unpredictable motion patterns.
To address these limitations, WildGS-SLAM introduces a novel SLAM approach that leverages 3D Gaussian Splatting (3DGS) representation for robust performance in highly dynamic environments using only monocular RGB input. Similar to recent uncertainty-aware methods, this approach takes a purely geometric approach, integrating uncertainty-aware tracking and mapping to effectively remove dynamic distractors without requiring explicit depth or semantic labels.
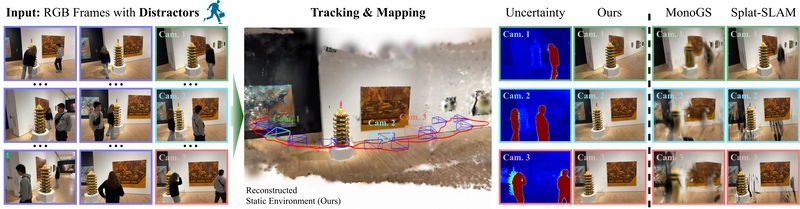
Figure 1: WildGS-SLAM. Given a monocular video sequence captured in the wild with dynamic distractors, this method accurately tracks the camera trajectory and reconstructs a 3D Gaussian map for static elements, effectively removing all dynamic components. This enables high-fidelity rendering even in complex, dynamic scenes.
The key innovation is a shallow multi-layer perceptron (MLP) trained on 3D-aware, pre-trained DINOv2 features to predict per-pixel uncertainty. This MLP trains incrementally as input frames stream into the system, allowing dynamic adaptation to incoming scene data. The uncertainty information enhances tracking through dense bundle adjustment and informs the rendering loss in Gaussian map optimization to refine reconstruction quality.
By optimizing the map and uncertainty MLP independently, WildGS-SLAM ensures maximal performance for each component. The results demonstrate superior performance over existing dynamic SLAM methods across diverse indoor and outdoor scenarios.
Evolution of SLAM Systems: From Static to Dynamic Environments
Traditional Approaches to Visual SLAM
Most traditional visual SLAM methods assume static scenes, which causes substantial tracking drift when dynamic objects disrupt feature matching and photometric consistency. To enhance robustness in dynamic environments, many approaches detect and filter out dynamic regions to focus on reconstructing static scene parts.
Common approaches for detecting dynamic objects include:
- Warping or reprojection techniques
- Off-the-shelf optical flow estimators
- Predefined class priors for object detection or semantic segmentation
- Hybrid strategies combining multiple techniques
Notable systems like ReFusion require RGB-D input and use a TSDF map representation, leveraging depth residuals to filter out dynamic objects. DynaSLAM supports RGB, RGB-D, and stereo inputs, using Mask R-CNN for semantic segmentation with predefined movable object classes, and detects unknown dynamic objects in RGB-D mode via multi-view geometry.
Significantly, no existing traditional SLAM methods support monocular input without relying on prior class information. This limitation stems from the sparse nature of traditional monocular SLAM, which restricts the use of purely geometric cues for identifying dynamic regions. WildGS-SLAM overcomes this by leveraging a 3D Gaussian scene representation to provide dense mapping, enabling support for monocular input without prior semantic information.
Neural Implicit and 3D Gaussian Splatting Approaches
Neural Implicit Representations and 3D Gaussian Splatting (3DGS) have gained substantial interest in SLAM research, offering promising advancements in dense reconstruction and novel view synthesis.
Early SLAM systems like iMAP and NICE-SLAM pioneered neural implicit representations, integrating mapping and camera tracking within a unified framework. Subsequent works advanced these methods through various optimizations and extensions, including efficient representations, monocular settings, and semantic information integration.
The emergence of 3D Gaussian Splatting introduced an efficient and flexible alternative representation for SLAM, adopted in several recent studies. Among these, MonoGS became the first near real-time monocular SLAM system using 3D Gaussian Splatting as its sole scene representation. Another notable advancement is Splat-SLAM, offering high-accuracy mapping with robust global consistency.
While these methods excel in tracking and reconstruction, they typically assume static scene conditions, limiting their robustness in dynamic environments. Some methods have explicitly focused on handling dynamic environments by extracting dynamic object masks before passing them to tracking and mapping components. DGS-SLAM, DynaMon, and RoDyn-SLAM combine segmentation masks with motion masks derived from optical flow. DDN-SLAM employs object detection combined with a Gaussian Mixture Model to distinguish between foreground and background.
However, these approaches rely heavily on prior knowledge of object classes and depend on object detection or semantic segmentation, limiting their generalizability in real-world settings where dynamic objects may be unknown and difficult to segment.
In contrast, WildGS-SLAM takes a purely geometric approach even with monocular input. While similar works like NeRF On-the-go and WildGaussians demonstrate distractor removal in dynamic environments, they primarily target sparse-view settings with known camera poses. WildGS-SLAM extends this framework to tackle the challenging sequential SLAM setting with specific design components for robust tracking and high-fidelity mapping within the 3DGS backend.
WildGS-SLAM System Architecture: Integrating Uncertainty for Robust Performance
Given a sequence of RGB frames captured in a dynamic environment, WildGS-SLAM tracks the camera pose while reconstructing the static part of the scene as a 3D Gaussian map. To mitigate the impact of moving objects in tracking and eliminate them from the 3D reconstruction, the system utilizes DINOv2 features and a shallow MLP to decode them to per-pixel uncertainty.
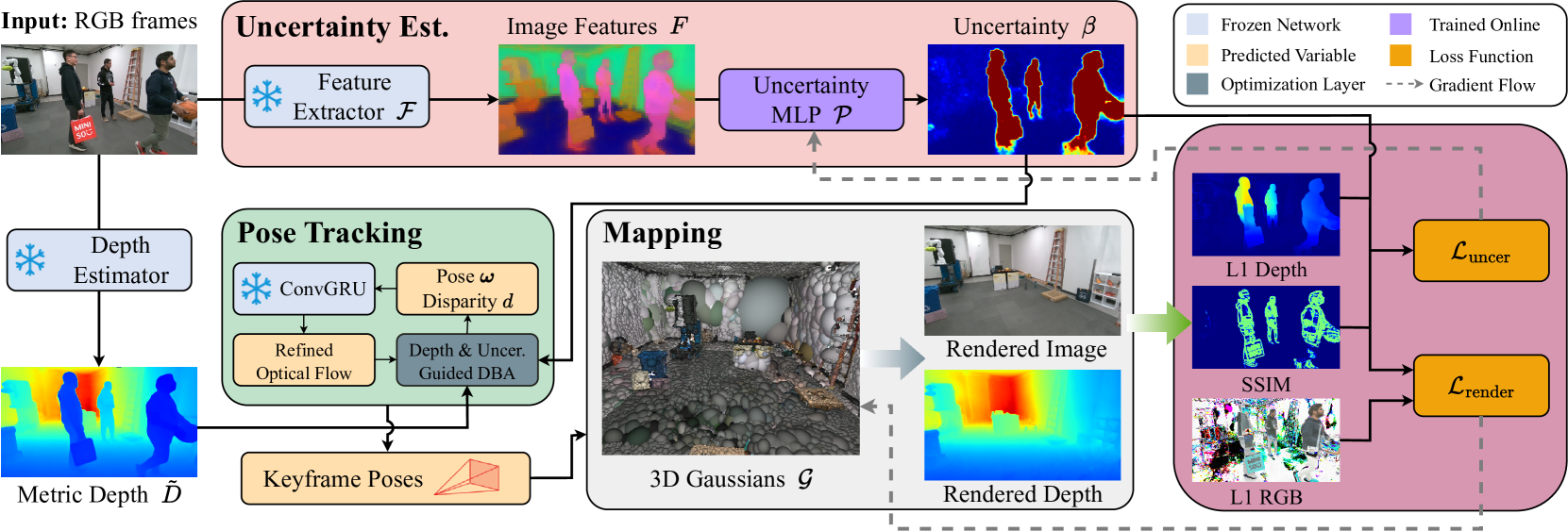
Figure 2: System Overview. WildGS-SLAM takes a sequence of RGB images as input and simultaneously estimates the camera poses while building a 3D Gaussian map of the static scene. The method is more robust to the dynamic environment due to the uncertainty estimation module, where a pretrained DINOv2 model is first used to extract the image features. An uncertainty MLP then utilizes the extracted features to predict per-pixel uncertainty. During the tracking, the predicted uncertainty serves as a weight in the dense bundle adjustment (DBA) layer to mitigate the impact of dynamic distractors. Monocular metric depth facilitates pose estimation. In the mapping module, the predicted uncertainty is incorporated into the rendering loss to update the Gaussian map. Moreover, the uncertainty loss is computed in parallel to train the uncertainty MLP. Note that the uncertainty MLP and Gaussian map are optimized independently, as illustrated by the gradient flow in the gray dashed line. Faces are blurred to ensure anonymity.
Building Blocks: 3D Gaussian Splatting Foundation
WildGS-SLAM utilizes a 3D Gaussian representation to reconstruct the static part of the scanned environment. The scene is represented by a set of anisotropic Gaussians. Each Gaussian contains color, opacity, mean position, and covariance matrix.
For rendering, the system follows the same approach as in the original 3DGS but omits spherical harmonics to speed up optimization. Given a camera-to-world pose and the projection function that maps 3D points onto the image frame, the 3D Gaussians are "splatted" onto the 2D image plane by projecting the mean and covariance matrix.
The rendered color and depth at each pixel are obtained by blending the 3D Gaussians overlapping with this pixel, sorted by their depth relative to the camera plane. This representation enables efficient and high-quality rendering of the static scene elements while allowing the system to identify and exclude dynamic objects.
Seeing the Invisible: Uncertainty Prediction
The main contribution of WildGS-SLAM is eliminating the impact of moving distractors in both mapping and tracking. For each input frame, the system extracts DINOv2 features and utilizes an uncertainty MLP, trained on-the-fly with streamed frames, to predict a per-pixel uncertainty map that mitigates the impact of distractors.
For the uncertainty loss functions, the system adopts a modified SSIM loss and regularization terms, along with an L1 depth loss term comparing rendered depth with metric depth estimated by Metric3D v2. This additional depth signal improves the model's ability to distinguish distractors, enhancing the uncertainty MLP training.
The total uncertainty loss combines these components to effectively train the MLP to identify regions with dynamic content, allowing the system to downweight these regions during tracking and mapping. This approach enables the system to handle dynamic objects without requiring explicit semantic segmentation or prior knowledge about object classes.
Staying on Course: Tracking with Uncertainty Awareness
The tracking component is based on DROID-SLAM with the incorporation of depth and uncertainty into the Dense Bundle Adjustment (DBA) to make the system robust in dynamic environments. The original DROID-SLAM uses a pretrained recurrent optical flow model coupled with a DBA layer to jointly optimize keyframe camera poses and disparities.
WildGS-SLAM integrates the uncertainty map estimated by the MLP into the BA optimization objective to handle moving distractors. Additionally, it utilizes metric depth to stabilize the DBA layer, especially during early tracking stages when the uncertainty MLP may not always provide accurate estimations.
For each newly inserted keyframe, the system first estimates its monocular metric depth and adds it to the DBA objective alongside optical flow. The uncertainty map serves as a weighting mechanism in the optimization, reducing the influence of dynamic objects on the camera pose estimation. This approach enhances the robustness of tracking in the presence of moving distractors.
Building the World: Uncertainty-Aware Mapping
After the tracking module predicts the pose of a newly inserted keyframe, its RGB image, metric depth, and estimated pose are utilized in the mapping module to expand and optimize the 3DGS map. Given a new keyframe, the system expands the Gaussian map to cover newly explored areas, using metric depth as proxy depth.
During mapping optimization, the system maintains a local window of keyframes selected by inter-frame covisibility. At each iteration, the system randomly samples a keyframe, renders the color and depth image, and optimizes the Gaussian map by minimizing the render loss.
Unlike the loss function for static scenes, WildGS-SLAM incorporates the uncertainty map, which serves as a weighting factor for color and depth losses, minimizing the influence of distractors during mapping optimization. Additionally, an isotropic regularization loss constrains 3D Gaussians to prevent excessive elongation in sparsely observed regions.
At each iteration, the system also computes the uncertainty loss given the rendered color and depth image, which is used to train the uncertainty MLP in parallel to the map optimization. Importantly, the system detaches the gradient flow between the uncertainty loss and the Gaussians, as well as between the rendering loss and the uncertainty MLP, ensuring independent optimization of these components.
Proving the Concept: Extensive Evaluation in Dynamic Environments
Experimental Framework and Datasets
WildGS-SLAM was evaluated on the Bonn RGB-D Dynamic Dataset, TUM RGB-D Dataset, and a new Wild-SLAM Dataset. The Wild-SLAM Dataset comprises two subsets: Wild-SLAM MoCap (10 RGB-D sequences recorded with an Intel RealSense D455 camera in a motion capture room providing ground truth trajectories) and Wild-SLAM iPhone (7 non-staged RGB sequences recorded with an iPhone 14 Pro).
The system was compared with 13 baseline methods including classic SLAM methods (DSO, ORB-SLAM2, DROID-SLAM), methods dealing with dynamic environments (Refusion, DynaSLAM), static neural implicit and 3DGS SLAM systems (NICE-SLAM, MonoGS, Splat-SLAM), and concurrent systems designed for dynamic environments (DG-SLAM, RoDyn-SLAM, DDN-SLAM, DynaMoN).
For camera tracking evaluation, the estimated trajectory was aligned to the ground truth using Sim(3) Umeyama alignment, and then evaluated using the Absolute Trajectory Error (ATE RMSE). Additionally, PSNR, SSIM, and LPIPS metrics were employed to evaluate novel view synthesis quality.
Superior Results: Tracking, Mapping, and Rendering Quality
WildGS-SLAM demonstrates remarkable performance across all evaluation benchmarks. On the Wild-SLAM MoCap Dataset, it achieves the lowest average ATE RMSE of 0.46 cm, significantly outperforming all baseline methods, including both RGB-D and monocular approaches.
| Method | ANYmal1 | ANYmal2 | Ball | Crowd | Person | Racket | Stones | Table1 | Table2 | Umbrella | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RGB-D | |||||||||||
| Refusion [palazzolo2019iros] | 4.2 | 5.6 | 5.0 | 91.9 | 5.0 | 10.4 | 39.4 | 99.1 | 101.0 | 10.7 | 37.23 |
| DynaSLAM (N+G) [bescos2018dynaslam] | 1.6 | 0.5 | 0.5 | 1.7 | 0.5 | 0.8 | 2.1 | 1.2 | 34.8 | 34.7 | 7.84 |
| NICE-SLAM [Zhu2022CVPR] | F | 123.6 | 21.1 | F | 150.2 | F | 134.4 | 138.4 | F | 23.8 | - |
| Monocular | |||||||||||
| DSO [Engel2017PAMI] | 12.0 | 2.5 | 1.0 | 88.6 | 9.3 | 3.1 | 41.5 | 50.6 | 85.3 | 26.0 | 32.99 |
| DROID-SLAM [teed2021droid] | 0.6 | 4.7 | 1.2 | 2.3 | 0.6 | 1.5 | 3.4 | 48.0 | 95.6 | 3.8 | 16.17 |
| DynaSLAM (RGB) [bescos2018dynaslam] | 0.6 | 0.5 | 0.5 | 0.5 | 0.4 | 0.6 | 1.7 | 1.8 | 42.1 | 1.2 | 5.19 |
| MonoGS [matsuki2024gaussian] | 8.8 | 51.6 | 7.4 | 70.3 | 55.6 | 67.6 | 39.9 | 24.9 | 118.4 | 35.3 | 47.99 |
| Splat-SLAM [sandstrom2024splat] | 0.4 | 0.4 | 0.3 | 0.7 | 0.8 | 0.6 | 1.9 | 2.5 | 73.6 | 5.9 | 8.71 |
| MonST3R-SW [zhang2024monst3r] | 3.5 | 21.6 | 6.1 | 14.4 | 7.2 | 13.2 | 11.2 | 4.8 | 33.7 | 5.5 | 12.12 |
| MegaSaM [li2024megasam] | 0.6 | 2.7 | 0.6 | 1.0 | 3.2 | 1.6 | 3.2 | 1.0 | 9.4 | 0.6 | 2.40 |
| WildGS-SLAM (Ours) | 0.2 | 0.3 | 0.2 | 0.3 | 0.8 | 0.4 | 0.3 | 0.6 | 1.3 | 0.2 | 0.46 |
Table 1: Tracking Performance on the Wild-SLAM MoCap Dataset (ATE RMSE ↓ [cm]). Best results are highlighted as first, second, and third. All baseline methods were run using their publicly available code. For DynaSLAM (RGB), initialization is time-consuming for certain sequences, and only keyframe poses are generated and evaluated. 'F' denotes tracking failure.

Figure 3: Input View Synthesis Results on the Wild-SLAM MoCap Dataset. Regardless of the distractor type, WildGS-SLAM is able to remove distractors and render realistic images. Faces are blurred to ensure anonymity.
In terms of novel view synthesis quality, WildGS-SLAM consistently outperforms the state-of-the-art Splat-SLAM across all metrics. It achieves higher PSNR (20.59 vs. 17.23), better SSIM (0.783 vs. 0.699), and lower LPIPS (0.209 vs. 0.346), demonstrating its superior ability to produce high-quality renderings.
| ANYmal1 | ANYmal2 | Ball | Crowd | Person | Racket | Stones | Table1 | Table2 | Umbrella | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Monocular | |||||||||||
| Splat-SLAM [sandstrom2024splat] | |||||||||||
| PSNR ↑ | 19.71 | 20.32 | 17.68 | 16.00 | 18.58 | 16.45 | 17.90 | 17.54 | 11.45 | 16.65 | 17.23 |
| SSIM ↑ | 0.786 | 0.800 | 0.702 | 0.693 | 0.754 | 0.699 | 0.711 | 0.717 | 0.458 | 0.667 | 0.699 |
| LPIPS ↓ | 0.313 | 0.278 | 0.294 | 0.356 | 0.298 | 0.301 | 0.291 | 0.312 | 0.650 | 0.362 | 0.346 |
| WildGS-SLAM (Ours) | |||||||||||
| PSNR ↑ | 21.85 | 21.46 | 20.06 | 21.28 | 20.31 | 20.87 | 20.52 | 20.33 | 19.16 | 20.03 | 20.59 |
| SSIM ↑ | 0.807 | 0.832 | 0.754 | 0.802 | 0.801 | 0.785 | 0.768 | 0.788 | 0.728 | 0.766 | 0.783 |
| LPIPS ↓ | 0.211 | 0.230 | 0.191 | 0.176 | 0.189 | 0.186 | 0.185 | 0.209 | 0.303 | 0.210 | 0.209 |
Table 2: Novel View Synthesis Evaluation on the Wild-SLAM MoCap Dataset. Best results are in bold.

Figure 4: Novel View Synthesis Results on the Wild-SLAM MoCap Dataset. PSNR metrics (↑) are included in images.
The system was also evaluated on the Wild-SLAM iPhone Dataset, which presents more challenging unconstrained real-world settings. The qualitative results demonstrate WildGS-SLAM's ability to effectively identify and remove dynamic objects in complex scenes.

Figure 5: Input View Synthesis Results on the Wild-SLAM iPhone Dataset. Only rendering results of monocular methods are shown, as depth images are unavailable in this dataset. Note that the uncertainty map appears blurry because DINOv2 outputs feature maps at 1/14 of the original resolution, and for mapping the system also downsamples to 1/3 of the original resolution to maintain efficiency.
On the Bonn RGB-D Dynamic Dataset, WildGS-SLAM achieves the best average ATE RMSE of 2.31 cm, outperforming all baseline methods including RGB-D approaches. This demonstrates the system's robustness in handling various types of dynamic objects and scenes.
| Method | Balloon | Balloon2 | Crowd | Crowd2 | Person | Person2 | Moving | Moving2 | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| RGB-D | |||||||||
| ReFusion [palazzolo2019iros] | 17.5 | 25.4 | 20.4 | 15.5 | 28.9 | 46.3 | 7.1 | 17.9 | 22.38 |
| ORB-SLAM2 [Mur2017TRO] | 6.5 | 23.0 | 4.9 | 9.8 | 6.9 | 7.9 | 3.2 | 3.9 | 6.36 |
| DynaSLAM (N+G) [bescos2018dynaslam] | 3.0 | 2.9 | 1.6 | 3.1 | 6.1 | 7.8 | 23.2 | 3.9 | 6.45 |
| NICE-SLAM [Zhu2022CVPR] | 24.4 | 20.2 | 19.3 | 35.8 | 24.5 | 53.6 | 17.7 | 8.3 | 22.74 |
| DG-SLAM [xu2024dgslam] | 3.7 | 4.1 | - | - | 4.5 | 6.9 | - | 3.5 | - |
| RoDyn-SLAM [jiang2024rodyn] | 7.9 | 11.5 | - | - | 14.5 | 13.8 | - | 12.3 | - |
| DDN-SLAM (RGB-D) [li2024ddn] | 1.8 | 4.1 | 1.8 | 2.3 | 4.3 | 3.8 | 2.0 | 3.2 | 2.91 |
| Monocular | |||||||||
| DSO [Engel2017PAMI] | 7.3 | 21.8 | 10.1 | 7.6 | 30.6 | 26.5 | 4.7 | 11.2 | 15.0 |
| DROID-SLAM [teed2021droid] | 7.5 | 4.1 | 5.2 | 6.5 | 4.3 | 5.4 | 2.3 | 4.0 | 4.91 |
| MonoGS [matsuki2024gaussian] | 15.3 | 17.3 | 11.3 | 7.3 | 26.4 | 35.2 | 22.2 | 47.2 | 22.8 |
| Splat-SLAM [sandstrom2024splat] | 8.8 | 3.0 | 6.8 | F | 4.9 | 25.8 | 1.7 | 3.0 | - |
| DynaMoN (MS) [schischka2023dynamon] | 6.8 | 3.8 | 6.1 | 5.6 | 2.4 | 3.5 | 1.4 | 2.6 | 4.02 |
| DynaMoN (MS&SS) [schischka2023dynamon] | 2.8 | 2.7 | 3.5 | 2.8 | 14.8 | 2.2 | 1.3 | 2.7 | 4.10 |
| MonST3R-SW [zhang2024monst3r] | 5.4 | 7.2 | 5.4 | 6.9 | 11.9 | 11.1 | 3.3 | 7.4 | 7.3 |
| MegaSaM [li2024megasam] | 3.7 | 2.6 | 1.6 | 7.2 | 4.1 | 4.0 | 1.4 | 3.4 | 3.51 |
| WildGS-SLAM (Ours) | 2.8 | 2.4 | 1.5 | 2.3 | 3.1 | 2.7 | 1.6 | 2.2 | 2.31 |
Table 3: Tracking Performance on Bonn RGB-D Dynamic Dataset (ATE RMSE ↓ [cm]). DDN-SLAM is not open source and does not report its RGB mode results on this dataset. DynaSLAM (RGB) consistently fails to initialize or experiences extended tracking loss across all sequences and therefore cannot be included in the table. 'F' indicates failure.

Figure 6: View Synthesis Results on Bonn RGB-D Dynamic Dataset. Results on the Balloon (first row) and Crowd (second row) sequences. For Balloon, ReFusion fails to remove the person from the TSDF, and DynaSLAM(N+G) struggles with limited static information from multiple views, resulting in partial black masks. In Crowd, DynaSLAM(N+G) cannot detect dynamic regions, defaulting the original image as the inpainted result. In contrast, WildGS-SLAM achieves superior rendering even with motion blur in the input.
The qualitative rendering results further highlight WildGS-SLAM's superior ability to remove dynamic objects and produce high-quality renderings. Unlike other methods that struggle with ghosting artifacts, black holes, or blurry renderings, WildGS-SLAM consistently generates clean and realistic images across all datasets.
Looking Forward: Impact and Future Directions
WildGS-SLAM presents a significant advancement in monocular SLAM for dynamic environments. By leveraging uncertainty-aware geometric mapping, it effectively handles moving objects without requiring explicit semantic segmentation or depth information. This approach enables robust tracking, high-fidelity mapping, and artifact-free rendering in challenging real-world scenarios.
The key innovations include:
- A purely geometric approach to dynamic object removal using only monocular RGB input
- An uncertainty-aware tracking and mapping pipeline that eliminates dynamic distractors without explicit segmentation
- A novel uncertainty prediction mechanism using DINOv2 features and an incrementally trained MLP
- A separation of optimization between the 3D Gaussian map and uncertainty MLP for maximal performance
These advancements have broad implications for applications in augmented reality, robotics, and autonomous navigation, where handling dynamic environments is crucial. The ability to operate with only monocular input makes the system particularly valuable for resource-constrained platforms.
Looking forward, potential improvements could include:
- Further optimization for real-time performance on mobile devices
- Integration with semantic understanding for enhanced scene interpretation
- Extension to multiple moving cameras and collaborative mapping
The introduction of the Wild-SLAM Dataset also contributes to the field by providing a comprehensive benchmark for evaluating SLAM systems in unconstrained, real-world conditions with varied object motions and occlusions.
As WildGS-SLAM demonstrates, uncertainty-aware geometric mapping presents a promising direction for robust SLAM in dynamic environments, potentially inspiring future research in this challenging domain.
