
This is a Plain English Papers summary of a research paper called OctGPT: Autoregressive 3D Shape Generation Rivals Diffusion Models. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Revolutionizing 3D Generation with Octree-Based Autoregressive Models
3D content creation has experienced remarkable growth, primarily driven by diffusion models. While autoregressive models have revolutionized text, image, and multimodal generation, they've lagged behind in 3D shape generation. OctGPT introduces a groundbreaking approach that transforms how autoregressive models generate 3D shapes, achieving quality and efficiency that rivals or even surpasses state-of-the-art diffusion models.

OctGPT generates high-quality 3D shapes in diverse scenarios, including unconditional, category-, text- and image-conditioned generation, as well as large-scale scene synthesis.
The Challenge with 3D Autoregressive Models
Applying autoregressive models to 3D shape generation presents unique challenges:
Unlike text or images, 3D shapes lack natural sequential order, requiring conversion into a one-dimensional sequence suitable for autoregressive prediction.
Previous approaches flatten 3D tokens using rasterization orders based on spatial positions, but this ignores the inherent hierarchical structure and spatial locality of 3D shapes.
3D shapes require numerous tokens to capture complex geometry, making training and inference computationally expensive.
While previous works explored compact mesh-based representations and low-dimensional tokenization schemes, these methods still struggle with expressiveness and fine-grained details.
The OctGPT Approach: Serialized Octree Representation
The key innovation in OctGPT is its novel serialized octree representation. Octrees naturally capture 3D shapes' hierarchical structure while providing a locality-preserving order suitable for autoregressive prediction.

Overview. 3D shapes are encoded as multiscale serialized octrees, where coarse structures are represented by multiscale binary splitting signals derived from the octree hierarchy, and fine-grained details are captured by binarized latent codes from an octree-based VQVAE. These binary tokens, along with teacher-forcing masks, are fed into a transformer for autoregressive training. During inference, the transformer progressively predicts the token sequence to reconstruct the octree and latent codes, generating 3D shapes from coarse to fine. The sequence is decoded by the VQVAE to produce the final 3D shape.
The approach converts input shapes into octrees by recursively splitting nodes to a specified depth or resolution. The node-splitting status (0/1 binary signal) is concatenated across each octree depth from coarse to fine, forming a one-dimensional sequence. While the octree structure captures coarse geometry, it's supplemented with additional binary tokens at the finest octree nodes, generated by a vector quantized variational autoencoder (VQVAE).
Unlike previous autoregressive models that directly predict 3D coordinates, OctGPT decomposes generation into simpler binary classification tasks. This chain-of-thought approach significantly improves convergence speed and generation quality.
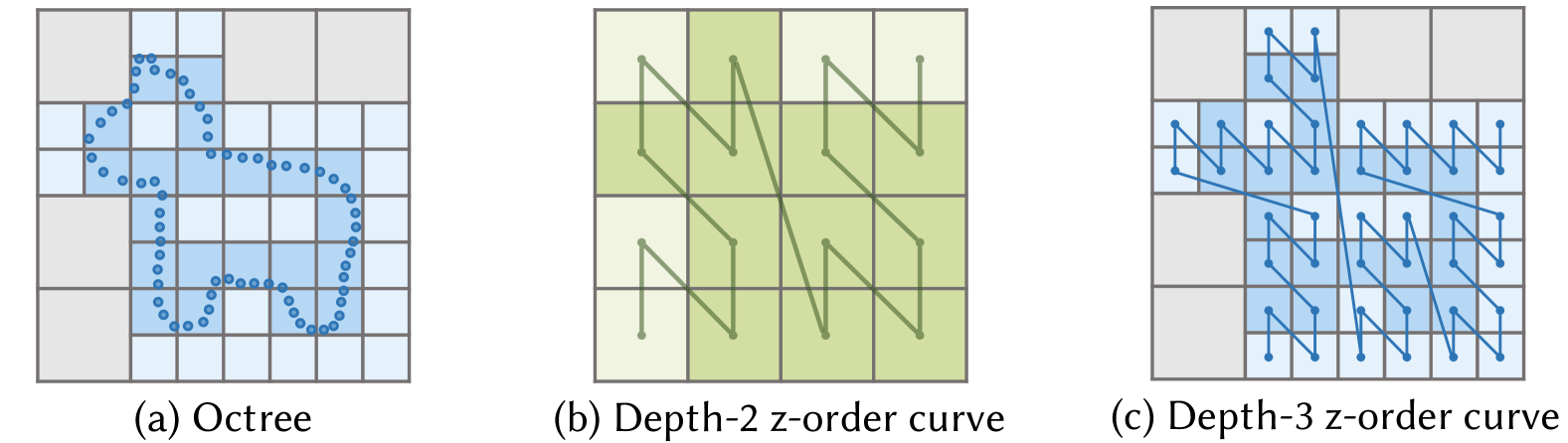
Octree and z-order curves. 2D images are used for clearer illustration. (a): The input point cloud with its corresponding octree. Node statuses are color-coded: darker colors represent nodes containing points, lighter colors indicate empty nodes, and gray denotes non-existing nodes at the given depth. (b) & (c): z-order curves at octree depths 2 and 3, respectively.
Efficient Transformer Architecture
To handle the long sequences resulting from the octree representation, OctGPT incorporates several key enhancements:
Octree-based Attention: Divides tokens into fixed-size windows for efficient self-attention computation, alternating between dilated octree attention and shifted window attention to enable cross-window interactions.
3D Positional Encoding: Extends rotary positional encoding (RoPE) to 3D space (RoPE3D) and introduces learnable scale embeddings to differentiate tokens at different octree depths.
Multiple Token Generation: Adopts a multi-token generation strategy with a depth-wise teacher-forcing mask, allowing parallel prediction of multiple tokens while preserving hierarchical dependencies.
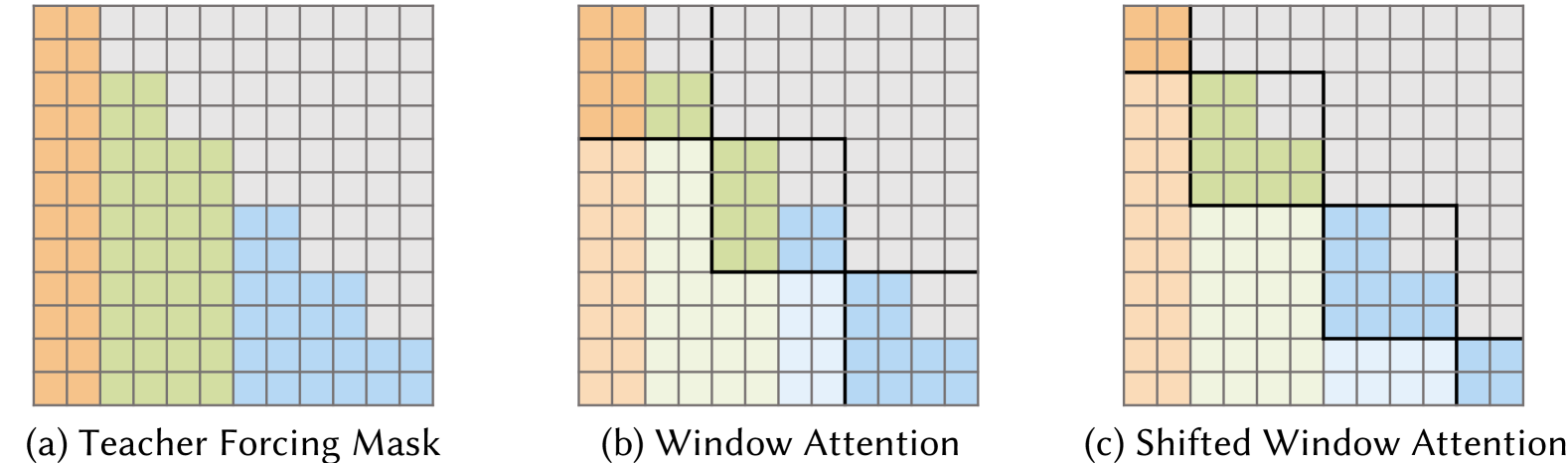
Multiscale Autoregressive Models. (a) Our model predicts multiple tokens autoregressively according to the depth-wise teacher-forcing mask. Tokens at different scales are represented in distinct colors, while masks are depicted in gray. (b) Octree-based Window attention is adopted for cross-scale communication and improved computational efficiency. (c) Shifted window attention allows for interactions across different windows.
These innovations reduce training time by 13 folds and generation time by 69 folds compared to standard approaches, enabling efficient training of high-resolution 3D shapes (1024³) on just four NVIDIA 4090 GPUs within days.
Performance and Versatility
OctGPT was evaluated on the ShapeNet and Objaverse datasets, comparing against state-of-the-art methods including GAN-based approaches (IM-GAN, SDF-StyleGAN), diffusion-based methods (Wavelet-Diffusion, MeshDiffusion, SPAGHETTI, LAS-Diffusion, XCube, OctFusion), and autoregressive methods (MeshGPT, 3DILG, 3DShape2VecSet).
| Method | Chair | Airplane | Car | Table | Rifle |
|---|---|---|---|---|---|
| IM-GAN | 63.42 | 74.57 | 141.2 | 51.70 | 103.3 |
| SDF-StyleGAN | 36.48 | 65.77 | 97.99 | 39.03 | 64.86 |
| Wavelet-Diffusion | 28.64 | 35.05 | N/A | 30.27 | N/A |
| MeshDiffusion | 49.01 | 97.81 | 156.21 | 49.71 | 87.96 |
| SPAGHETTI | 65.26 | 59.21 | N/A | N/A | N/A |
| LAS-Diffusion | 20.45 | 32.71 | 80.55 | 17.25 | 44.93 |
| XCube | 18.07 | 19.08 | 80.00 | N/A | N/A |
| OctFusion | 16.15 | 24.29 | 78.00 | 17.19 | 30.56 |
| MeshGPT | 37.05 | N/A | N/A | 25.25 | N/A |
| OctGPT | 31.05 | 27.47 | 64.43 | 19.64 | 21.91 |
| 3DShape2VecSet | 21.21 | 46.27 | 110.12 | 25.15 | 54.20 |
| LAS-Diffusion | 21.55 | 43.08 | 86.34 | 17.41 | 70.39 |
| OctFusion | 19.63 | 30.92 | 80.97 | 17.49 | 28.59 |
| 3DILG | 31.64 | 54.38 | 164.15 | 54.13 | 77.74 |
| OctGPT | 28.28 | 29.27 | 62.40 | 20.64 | 27.21 |
Table 1. The quantitative comparison of shading-image-based FID. The upper part shows results for training on each category separately, while the lower part shows results for training on all categories together. Shaded rows indicate autoregressive models, and green numbers highlight the improvement of our OctGPT in FID score over the previous best-performing autoregressive models. On average, OctGPT achieves the best performance.
OctGPT consistently outperforms other autoregressive methods and even surpasses state-of-the-art diffusion-based methods in some categories. Compared to previous autoregressive approaches, OctGPT achieves a significant improvement in FID performance while being substantially more efficient.

Comparison with state-of-the-art 3D autoregressive models. Experiments are conducted on the chair category. Top: the generated shapes. Bottom: the corresponding token.

Qualitative comparison results. We show the generated shapes from our OctGPT and other SOTA methods on airplane and chair category.
The efficiency gains from the OctGPT approach are substantial, as demonstrated in ablation studies:
| Method | FID | Niter | FID | Time |
|---|---|---|---|---|
| w/o RoPE3D | 38.03 | 64 | 35.95 | 6.43 s |
| w/o Scale Embeddings | 34.41 | 128 | 33.60 | 9.65 s |
| w/o z-order | 43.71 | 256 | 31.90 | 17.05 s |
| Ours | 27.47 | 512 | 27.47 | 34.51 s |
Table 2. Ablation studies on positional encodings and z-order (left) and number of generation iterations (right). The FID values are reported for the airplane category. Time indicates the time consumption to generate a mesh.
When comparing efficiency with other autoregressive models, OctGPT demonstrates remarkable improvements:
| Method | 5K | 10K | 20K | 40K | 80K | 160K |
|---|---|---|---|---|---|---|
| AutoSDF | 0.4 | OOM | ||||
| 3DILG | 0.7 | 2.0 | 6.4 | 22.7 | 84.8 | OOM |
| MeshGPT | 0.3 | 1.3 | 4.5 | OOM | ||
| OctGPT | 0.3 | 0.4 | 0.7 | 1.3 | 2.5 | 5.2 |
Table 4. Comparisons of efficiency with state-of-the-art 3D autoregressive models. We compare the training iteration time (in seconds) for longer sequences.
| Method | Params | Epochs | GPUs |
|---|---|---|---|
| AutoSDF | 32M | 400 | N/A |
| 3DILG | 316M | 400 | 4 × A100 |
| MeshGPT | 213M | 2000 | 4 × A100 |
| OctGPT | 170M | 200 | 4 × 4090 |
Table 5. Comparisons of convergence speed with state-of-the-art 3D autoregressive models. We present the number of parameters, epochs and GPUs
Versatile Applications
OctGPT demonstrates exceptional versatility across various applications:
Text-Conditioned Generation
OctGPT leverages CLIP's text encoder to extract text features and integrate them into the generation process through cross-attention modules. Compared to methods like AutoSDF, SDFusion, Shap-E, and Gaussian Cube, OctGPT generates shapes with superior quality and greater diversity.

Text conditional generation results on Objaverse dataset.

Comparison of text conditional generation results with other SOTA methods on Objaverse dataset.
| Method | FID (Inception) | FID (CLIP-ViT) |
|---|---|---|
| OctFusion | 81.25 | 9.09 |
| OctGPT | 59.91 | 6.45 |
Table 3. The quantitative comparison of shading-image-based FID with OctFusion for text-condition experiment on the Objaverse dataset.
Sketch and Image-Conditioned Generation
OctGPT can generate 3D shapes from sketches and images, demonstrating its generalization abilities. Even without relying on view information, the model generates high-quality shapes consistent with the input sketches or images.
Scene-Level Generation
A particularly impressive demonstration of OctGPT's capabilities is scene-level generation with multiple objects. Trained on the synthetic room dataset containing 5K scenes, OctGPT generates diverse, visually appealing scenes with multiple objects at 1024³ resolution.

Scene-level generation results. Experiments are conducted on Synthetic Rooms dataset.
Conclusion and Future Directions
OctGPT represents a significant advancement in 3D shape generation using autoregressive models. By encoding 3D shapes as multiscale binary sequences induced by octrees and employing an efficient transformer architecture, it achieves state-of-the-art performance and scalability.
While highly effective, the two-stage pipeline (VQVAE followed by autoregressive transformer) isn't end-to-end trainable, potentially constraining overall performance. Future work could focus on developing end-to-end training strategies, leveraging additional computational resources, and exploring multi-modality training to expand OctGPT's applicability.
The innovations in OctGPT open exciting possibilities for integrating 3D shape generation with other modalities, potentially leading to more comprehensive multimodal systems that can simultaneously generate 3D shapes, images, and text.
