In my previous work as a Platform Engineer for a remittance company, we faced a significant issue related to costs. Our Fivetran syncs were consuming an excessive amount of Databricks cluster resources, and as a result, we had to make a crucial decision to reduce operational costs in Databricks. As data volumes continued to grow, finding a solution that would maintain efficiency while lowering costs became a top priority.
Fivetran offers an elegant solution to sync data from various data sources to cloud platforms like Databricks, especially when S3 is used as the destination. In our case, however, the majority of our databases were PostgreSQL, which made the solution even more important as we needed to ensure cost efficiency for our sync process.
This article explores two approaches we considered to mitigate these issues and improve cost-efficiency while maintaining the integrity and accessibility of our data.
The Two Approaches for Syncing Data from PostgreSQL to Databricks
There are two primary strategies to sync data from PostgreSQL to Databricks using Fivetran: direct sync to Databricks and syncing via S3 to create external tables in Databricks. Let’s examine both approaches and how they impact cost, performance, and data management.
1. Direct Sync from PostgreSQL to Databricks
In this first approach, Fivetran establishes a direct connection from PostgreSQL to Databricks, facilitating real-time data movement from the source into Databricks. This method is simple to set up and requires minimal ongoing management.
Advantages:
- Simplicity: With straightforward configuration, this method minimizes the need for extra processing steps.
Challenges:
- High Compute Costs: Direct syncing incurs significant computational charges in Databricks, as every sync triggers cluster activity, which can quickly add up, especially with high-frequency or large data sets.
- Limited Flexibility: Sync frequency can be more rigid, which may lead to performance issues or inefficient cost management.
2. Sync via S3 to Create External Tables in Databricks
In this approach, Fivetran first syncs data into an S3 bucket, and from there, the S3 destination functionality is used to create external tables in Databricks. External tables allow Databricks to query data directly from S3 without ingesting it into the Databricks warehouse, reducing computational load significantly.
Advantages:
- Reduced Compute Costs: By leveraging external tables, the data is stored in S3, and Databricks queries the data directly from there. This avoids the need to allocate compute resources for loading the data into Databricks, cutting down on cluster usage and costs.
- Flexible Data Access: This method allows for easy querying of data stored in S3 using external tables in Databricks, providing more flexibility in your data pipeline.
Challenges:
- Latency: While external tables are cost-effective, they may introduce some latency compared to directly syncing data into Databricks, as Databricks queries external storage.
- Setup Complexity: This approach requires additional setup steps, including configuring Fivetran to sync with S3 and setting up external tables in Databricks.
Additionally, in this configuration, we used Delta Lake as the data format for the S3 sync. Delta Lake enables ACID transactions and better data quality management, which ensures that the data remains reliable while being queried in Databricks. By using external tables, the data remains as external and not as managed tables, which means that data does not automatically sync metadata with the Unity Catalog.
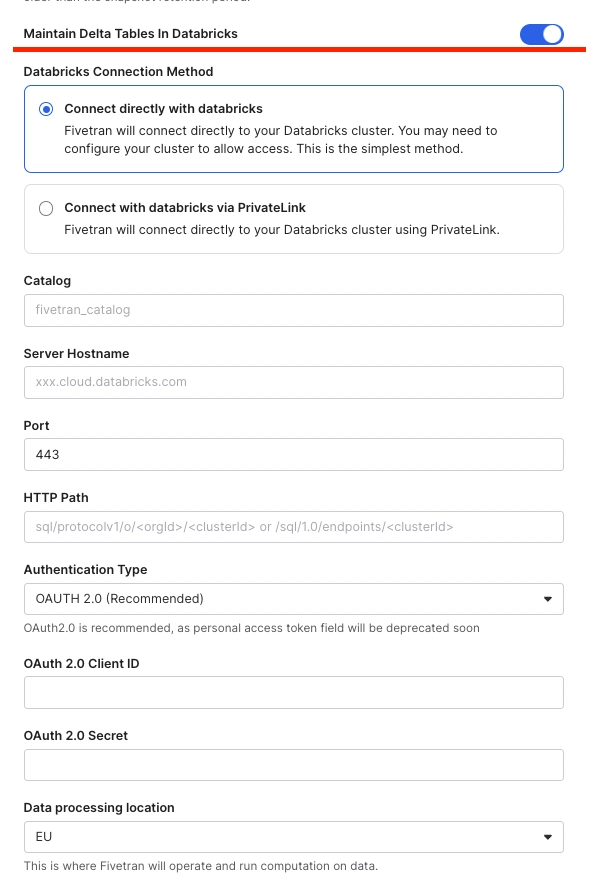
To configure Fivetran for syncing data into S3 and using it as an external table source in Databricks, follow these steps:
- In Fivetran Console, go to Destinations
- Choose S3 Data Lake as your destination.
- Table Format: Be sure to select DELTA as the table format to enable the benefits of Delta Lake’s transactional capabilities.
- Maintain Delta Tables in Databricks: Enable the toggle for this option to ensure that Delta tables are maintained in Databricks as external tables, allowing for seamless querying and management.
- Warehouse Configuration: Fill in the details for the Databricks warehouse you will be using for querying the external tables.
These configurations ensure that your S3 data is optimized for querying in Databricks while maintaining cost efficiency by using external tables.
Choosing the Right Approach: Cost, Performance, and Data Freshness
The decision between direct syncing and syncing through S3 depends largely on your organization's priorities:
- Minimizing Compute Costs: If reducing compute usage in Databricks is a primary goal, syncing via S3 and using external tables is the better choice. This method significantly cuts down on the need for Databricks clusters while still providing easy access to data.
- Data Volume: For large volumes of data, external tables offer a cost-effective solution, as they offload storage to S3, which is much more economical.
Conclusion: Optimizing Data Sync with Fivetran
Fivetran provides two efficient ways to sync data from PostgreSQL to Databricks, each with its advantages and trade-offs. Direct syncing offers simplicity and real-time access but comes with high computational costs. On the other hand, syncing data to S3 and using external tables in Databricks reduces compute costs significantly, making it a more cost-effective option for larger data volumes.
By considering the trade-offs between these two approaches, organizations can optimize their data pipelines, reduce costs, and maintain performance, ensuring they make the most out of their Databricks resources.

