Microservices Read Patterns focus on how to read data in a reliable and fast way, given constraints such as multi-service reads.
Microservices Reliability Playbook
- Introduction to Risk
- Introduction to Microservices Reliability
- Microservices Patterns
- Read Patterns
- Write Patterns
- Multi-Service Patterns
- Call Patterns
Download the full Playbook at a free PDF
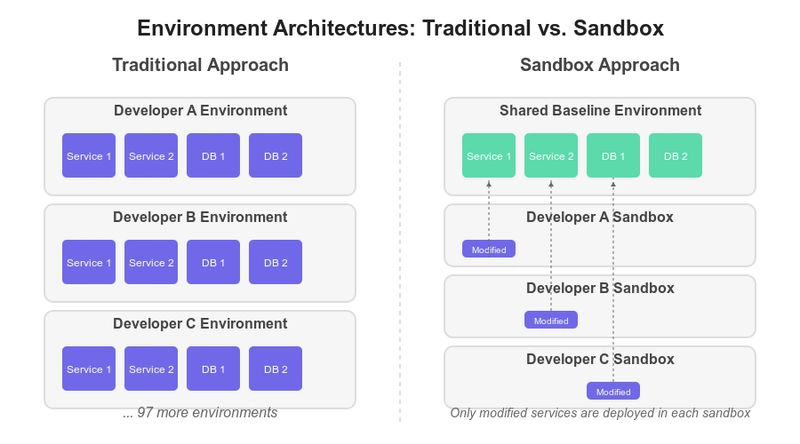
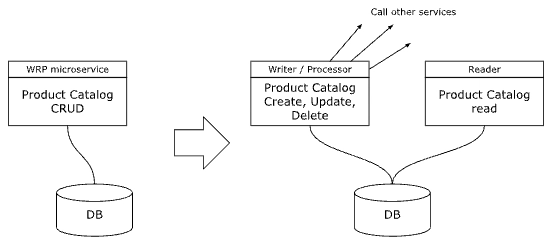
Reader Pattern
The Reader pattern mandates that we split a system into two microservices (reader and writer), favoring higher SLO for read operations. The Reader service is built to be very simple, with reading data from the database and returning it, working on the same database that the writer writes into. The reader may perform complex queries including joins to read the data.
For instance we can consider a product catalog CRUD service. We can consider the get product and search for product APIs as the more critical APIs that require 0.99999 % reliability, while the rest of the update APIs can have a lower SLO. The product catalog reader service may query the products, categories, variants, inventory and other tables to fulfill the get product and search for product APIs.
The Reader Pattern applied to the product catalog
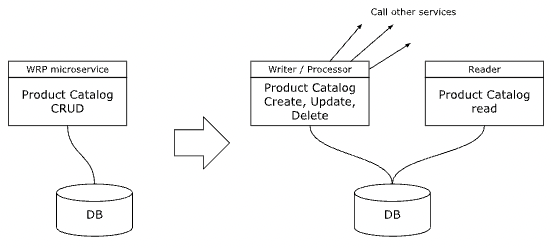
We also note that regarding risk of change, it is more likely that more changes are applied to the Create / Update / Delete operations of the product catalog, while the Read operation tends to be more stable. In any case, we isolate the read operation from risk of change of the Create / Update / Delete operations.
It is important to note that this pattern is great when the database schema is simple. However, when a read operation requires reading from multiple tables using complex queries, stored procedures or multiple queries, those also affect latency and reliability.
Advantages:
- Simple reader service as an ideal microservice, five-nines reliability.
- Decouple risk of change of write and processing operations from higher SLO read operations
- Isolate high SLO read operations from other lower SLO operations
Disadvantages:
- For complex DB schema with references, read operations still need complex queries or multiple queries, which impacts latency and reliability.
- Shared dependency on the database (Reader vs writer / processor)
- Coupling on the DB Schema - changes that require DB change still risk the higher SLO
Reader with Preprocessing and Enrichment Pattern
Preprocessing is reading data from multiple tables and creating a new derived table to support read operations. For instance, consider a product catalog preprocessing the products, categories and variants tables into a single product-read table, from which all product information can be read by key.
Enrichments are a type of processing that adds data from other services to the current service data on reads. For example, consider enriching a product with inventory quantity or the association of product with categories and taxonomies (assuming categories and inventory are managed on separate services).
The default RWP service will call the other services on reads to enrich the product information, which means reducing reliability and increasing latency..
The Reader with Preprocessing and Enrichment Pattern mandates that on reads,
- The service does a simple SQL query to get the data, most commonly by primary key. The writer, on getting an insert or update operation, after updating the normalized table, also updates the derived preprocessed table for the reader.
- The service does not call any other service. Instead, the enrichments are happening as part of the proceeding on the Writer / Processor service. The Writer, on getting an insert or update operation, calls other services, creates the enriched data and saves it in the database.
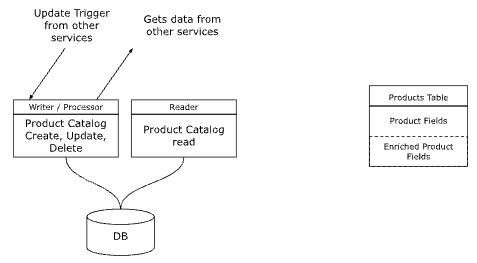
One has to ask what happens when the enrichment data changes? For instance, when inventory data changes (due to a purchase or new stock), or due to a change in categories?
First, we note that both inventory and categories for a product are “slowly changing data”, that is, data that changes a few times a day, at most a few times an hour, but is not interactive data. This allows us to reverse the update flow, and have the inventory and categories systems notify the product catalog Writer / Processor service to re-enrich the products, so that the reader will have them ready when needed.
The generic rule is that
- Preprocessing (without enrichment) applies to eventually consistent data (for which we can regain consistency, see below).
- Enrichment preprocessing only applies for slowly changing data, such that it is possible to process it beforehand on update triggers (data change events).
Second, did the system lose consistency due to not actively checking on reading the inventory? We claim it did not, as it was not consistent in the first place. Consider the full system includes the client (using a browser or mobile app) who sees the product from the catalog and the availability to purchase. Between the time of seeing the product and adding it to the cart the inventory can change again and again. As a result, the only consistent inventory check has to be done on checkout, on order creation (or reservation logic, if available).
Isolated Reader
The Isolated Reader pattern is a variation of the Read pattern and the Reader with Enrichment pattern to decouple the dependency on the database, decoupling both risk of change and risk of load and latency sourced at the shared database. In addition, the pattern simplifies the database queries on reads to become trivial queries, again improving both reliability and latency.
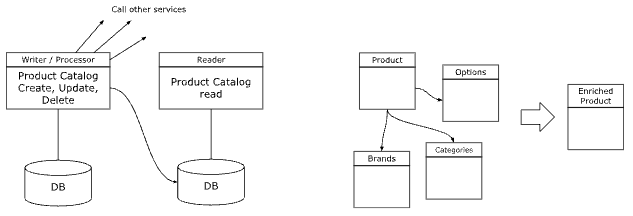
With the Isolated Reader pattern, the Writer / Processor service and database hold the canonical data structure, while the Reader database holds the enriched, simplified and indexed data prepared for reads.
The Writer / Processor service, on a write / update / delete operation, first writes to the canonical database. Then, it triggers a process to compute the reader database data and update the reader database.
For instance, in the product catalog example, the writer / processor may have tables of products with relations to product options, brands, categories, etc. It can be built as a normalized table with relationships, constraints and whatever makes sense.
The product catalog Reader products table will be a single table, with all the references materialized, including enrichment from other services such as the inventory data.
The Isolated Reader Pattern extends the Reader with Preprocessing and Enrichment Pattern by isolating the database hardware in addition to the microservices and data schema, decoupling risk of change and load of the database itself. It is the most efficient, reliable and fast read pattern, excluding additional layers such as cache.