Disclaimer: this is a report generated with my tool: https://github.com/DTeam-Top/tsw-cli. See it as an experiment not a formal research, 😄。
Mindmap
Summary
This document outlines the OWASP Top 10 vulnerabilities for Large Language Model (LLM) applications in 2025. It serves as a guide for developers, security professionals, and users to understand and mitigate the most critical risks associated with LLMs, including prompt injection, sensitive information disclosure, supply chain vulnerabilities, and misinformation. The document provides descriptions of each vulnerability, common examples, prevention strategies, attack scenarios, and references to related frameworks and taxonomies.
Terminology
- LLM (Large Language Model): A deep learning model designed to understand and generate human-like text based on patterns learned from vast amounts of data.
- Prompt Injection: Manipulating an LLM's input to alter its behavior or output in unintended ways.
- RAG (Retrieval-Augmented Generation): A technique that enhances LLM responses by retrieving information from external knowledge sources.
- SBOM (Software Bill of Materials): A comprehensive inventory of components used in software, aiding in vulnerability management.
- LoRA (Low-Rank Adaptation): A fine-tuning technique that efficiently adapts pre-trained LLMs to specific tasks.
- PEFT (Parameter-Efficient Fine-Tuning): A set of techniques for fine-tuning LLMs with minimal computational resources.
- PII (Personally Identifiable Information): Any data that could potentially identify a specific individual.
- XSS (Cross-Site Scripting): A type of web security vulnerability that allows attackers to inject malicious scripts into websites viewed by other users.
- CSRF (Cross-Site Request Forgery): A type of web security vulnerability that allows attackers to induce users to perform actions they do not intend to perform.
- SSRF (Server-Side Request Forgery): A type of web security vulnerability that allows an attacker to cause the server-side application to make HTTP requests to an arbitrary domain of the attacker's choosing.
- API (Application Programming Interface): A set of rules and specifications that software programs can follow to communicate with each other.
Main Points
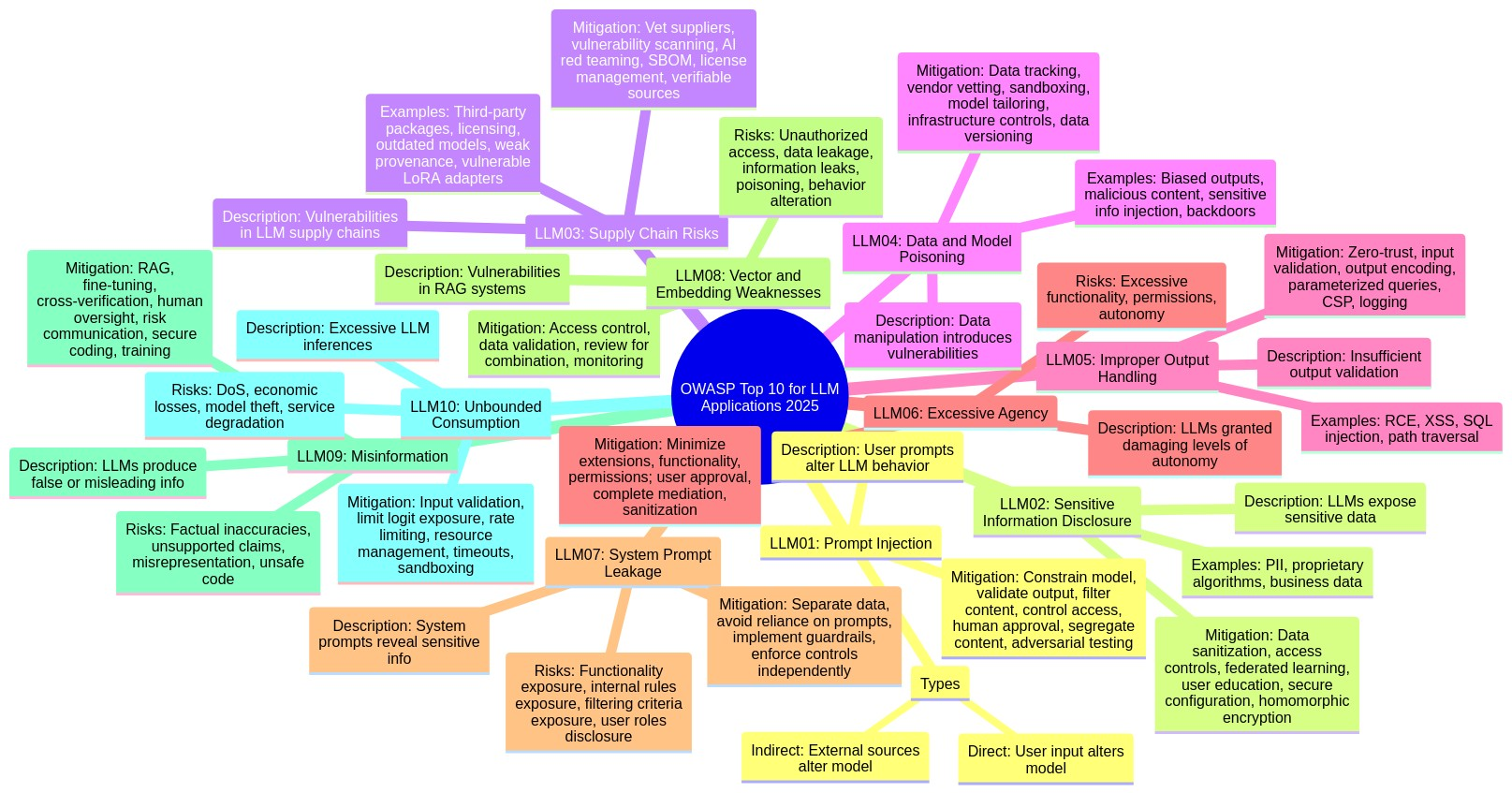
Point 1: LLM01:2025 Prompt Injection
Prompt injection vulnerabilities arise when user inputs unintentionally or maliciously alter the LLM's behavior. This can lead to harmful content generation, unauthorized access, or manipulation of critical decisions.
Implementation:
- Direct Prompt Injections: User input directly alters the model's behavior.
- Indirect Prompt Injections: External sources contain data that, when interpreted by the model, alters its behavior.
Mitigation:
- Constrain model behavior with specific instructions.
- Validate expected output formats.
- Implement input and output filtering.
- Enforce privilege control.
- Require human approval for high-risk actions.
- Segregate external content.
- Conduct adversarial testing.
Point 2: LLM02:2025 Sensitive Information Disclosure
LLMs can inadvertently expose sensitive data, including PII, financial details, and confidential business data, leading to unauthorized access and privacy violations.
Mitigation:
- Integrate data sanitization techniques.
- Enforce strict access controls.
- Utilize federated learning and differential privacy.
- Educate users on safe LLM usage.
- Ensure transparency in data usage.
- Conceal system preambles.
Point 3: LLM03:2025 Supply Chain
LLM supply chains are vulnerable to compromised training data, models, and deployment platforms, resulting in biased outputs and security breaches.
Implementation:
- Managing third-party risks like outdated components and licensing issues.
- Mitigating vulnerabilities in pre-trained models and LoRA adapters.
- Addressing risks in collaborative development environments and on-device LLMs.
Mitigation:
- Vet data sources and suppliers.
- Apply vulnerability scanning and management.
- Conduct AI red teaming and evaluations.
- Maintain a Software Bill of Materials (SBOM).
- Use verifiable model sources and integrity checks.
- Implement monitoring and auditing for collaborative model development.
Point 4: LLM04: Data and Model Poisoning
Data poisoning involves manipulating training data to introduce vulnerabilities or biases, compromising model security and performance.
Mitigation:
- Track data origins and transformations.
- Vet data vendors rigorously.
- Implement strict sandboxing.
- Tailor models for specific use cases.
- Ensure sufficient infrastructure controls.
- Use data version control (DVC).
- Test model robustness with red team campaigns.
- Monitor training loss and analyze model behavior.
Point 5: LLM05:2025 Improper Output Handling
Insufficient validation and sanitization of LLM outputs can lead to XSS, CSRF, SSRF, privilege escalation, and remote code execution.
Mitigation:
- Treat the model as any other user with proper input validation.
- Follow OWASP ASVS guidelines.
- Encode model output back to users.
- Implement context-aware output encoding.
- Use parameterized queries for database operations.
- Employ strict Content Security Policies (CSP).
- Implement robust logging and monitoring systems.
Point 6: LLM06:2025 Excessive Agency
Granting LLMs excessive functionality, permissions, or autonomy can lead to damaging actions due to unexpected or manipulated outputs.
Mitigation:
- Minimize extensions and their functionality.
- Avoid open-ended extensions.
- Minimize extension permissions.
- Execute extensions in the user's context.
- Require user approval for high-impact actions.
- Implement authorization in downstream systems.
- Sanitize LLM inputs and outputs.
Point 7: LLM07:2025 System Prompt Leakage
System prompt leakage exposes sensitive information used to guide the LLM's behavior, potentially facilitating other attacks.
Mitigation:
- Separate sensitive data from system prompts.
- Avoid reliance on system prompts for strict behavior control.
- Implement guardrails outside of the LLM.
- Enforce security controls independently from the LLM.
Point 8: LLM08:2025 Vector and Embedding Weaknesses
Weaknesses in vector and embedding generation, storage, or retrieval can lead to harmful content injection, manipulated outputs, or sensitive information access.
Mitigation:
- Implement fine-grained access controls and permission-aware vector stores.
- Implement robust data validation pipelines.
- Review data combinations and classifications.
- Maintain detailed logs of retrieval activities.
Point 9: LLM09:2025 Misinformation
LLMs can produce false or misleading information that appears credible, leading to security breaches, reputational damage, and legal liability.
Mitigation:
- Use Retrieval-Augmented Generation (RAG).
- Enhance the model with fine-tuning or embeddings.
- Encourage cross-verification and human oversight.
- Implement automatic validation mechanisms.
- Communicate risks to users.
- Establish secure coding practices.
Point 10: LLM10:2025 Unbounded Consumption
Uncontrolled LLM inferences can lead to denial of service (DoS), economic losses, model theft, and service degradation.
Mitigation:
- Implement strict input validation.
- Limit exposure of logits and logprobs.
- Apply rate limiting and user quotas.
- Manage resource allocation dynamically.
- Set timeouts and throttling.
- Restrict the LLM's access using sandboxing.
- Monitor resource usage and detect anomalies.
Improvements And Creativity
- Focus on Real-World Risks: The 2025 update reflects a deeper understanding of existing risks and introduces critical updates based on real-world applications.
- New Vulnerabilities: The inclusion of "System Prompt Leakage" and "Vector and Embeddings Weaknesses" addresses previously overlooked areas with significant exploit potential.
- Expanded Scope: "Unbounded Consumption" expands beyond Denial of Service to include resource management and cost concerns.
- Emphasis on Agentic Architectures: The "Excessive Agency" entry is expanded to address the increasing use of LLMs in autonomous agent systems.
Insights
This document provides a timely and essential resource for securing LLM applications. As LLMs become more integrated into various systems, understanding and mitigating these vulnerabilities is crucial.
Predictions and Recommendations:
- Security measures should focus on a defense-in-depth strategy, combining multiple mitigation techniques.
- Continuous monitoring and adaptation are necessary due to the evolving nature of LLM vulnerabilities.
- Further research is needed to develop robust defenses against advanced attacks, such as multimodal prompt injection and model extraction.
References
- ChatGPT Plugin Vulnerabilities - Chat with Code Embrace the Red
- ChatGPT Cross Plugin Request Forgery and Prompt Injection Embrace the Red
- Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection Arxiv
- Defending ChatGPT against Jailbreak Attack via Self-Reminder Research Square
- Prompt Injection attack against LLM-integrated Applications Cornell University
- Inject My PDF: Prompt Injection for your Resume Kai Greshake
- Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection Cornell University
- Threat Modeling LLM Applications AI Village
- Reducing The Impact of Prompt Injection Attacks Through Design Kudelski Security
- Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations (nist.gov)
- 2407.07403 A Survey of Attacks on Large Vision-Language Models: Resources, Advances, and Future Trends (arxiv.org)
- Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks
- Universal and Transferable Adversarial Attacks on Aligned Language Models (arxiv.org)
- From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy (arxiv.org)
- Lessons learned from ChatGPT’s Samsung leak: Cybernews
- AI data leak crisis: New tool prevents company secrets from being fed to ChatGPT: Fox Business
- ChatGPT Spit Out Sensitive Data When Told to Repeat ‘Poem’ Forever: Wired
- Using Differential Privacy to Build Secure Models: Neptune Blog
- Proof Pudding (CVE-2019-20634) AVID (
moohax&monoxgas) - A06:2021 – Vulnerable and Outdated Components
- PoisonGPT: How we hid a lobotomized LLM on Hugging Face to spread fake news
- Large Language Models On-Device with MediaPipe and TensorFlow Lite
- Hijacking Safetensors Conversion on Hugging Face
- ML Supply Chain Compromise
- Using LoRA Adapters with vLLM
- Removing RLHF Protections in GPT-4 via Fine-Tuning
- Model Merging with PEFT
- HuggingFace SF_Convertbot Scanner
- Thousands of servers hacked due to insecurely deployed Ray AI framework
- LeftoverLocals: Listening to LLM responses through leaked GPU local memory
- How data poisoning attacks corrupt machine learning models: CSO Online
- MITRE ATLAS (framework) Tay Poisoning: MITRE ATLAS
- PoisonGPT: How we hid a lobotomized LLM on Hugging Face to spread fake news: Mithril Security
- Poisoning Language Models During Instruction: Arxiv White Paper 2305.00944
- Poisoning Web-Scale Training Datasets - Nicholas Carlini | Stanford MLSys #75: Stanford MLSys Seminars YouTube Video
- ML Model Repositories: The Next Big Supply Chain Attack Target OffSecML
- Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor JFrog
- Backdoor Attacks on Language Models: Towards Data Science
- Never a dill moment: Exploiting machine learning pickle files TrailofBits
- arXiv:2401.05566 Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training Anthropic (arXiv)
- Backdoor Attacks on AI Models Cobalt
- Proof Pudding (CVE-2019-20634) AVID (
moohax&monoxgas) - Arbitrary Code Execution: Snyk Security Blog
- ChatGPT Plugin Exploit Explained: From Prompt Injection to Accessing Private Data: Embrace The Red
- New prompt injection attack on ChatGPT web version. Markdown images can steal your chat data.: System Weakness
- Don’t blindly trust LLM responses. Threats to chatbots: Embrace The Red
- Threat Modeling LLM Applications: AI Village
- OWASP ASVS - 5 Validation, Sanitization and Encoding: OWASP AASVS
- AI hallucinates software packages and devs download them – even if potentially poisoned with malware Theregiste
- Slack AI data exfil from private channels: PromptArmor
- Rogue Agents: Stop AI From Misusing Your APIs: Twilio
- Embrace the Red: Confused Deputy Problem: Embrace The Red
- NeMo-Guardrails: Interface guidelines: NVIDIA Github
- Simon Willison: Dual LLM Pattern: Simon Willison
- SYSTEM PROMPT LEAK: Pliny the prompter
- Prompt Leak: Prompt Security
- chatgpt_system_prompt: LouisShark
- leaked-system-prompts: Jujumilk3
- OpenAI Advanced Voice Mode System Prompt: Green_Terminals
- Augmenting a Large Language Model with Retrieval-Augmented Generation and Fine-tuning
- Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
- Information Leakage in Embedding Models
- Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence
- New ConfusedPilot Attack Targets AI Systems with Data Poisoning
- Confused Deputy Risks in RAG-based LLMs
- How RAG Poisoning Made Llama3 Racist!
- What is the RAG Triad?
- AI Chatbots as Health Information Sources: Misrepresentation of Expertise: KFF
- Air Canada Chatbot Misinformation: What Travellers Should Know: BBC
- ChatGPT Fake Legal Cases: Generative AI Hallucinations: LegalDive
- Understanding LLM Hallucinations: Towards Data Science
- How Should Companies Communicate the Risks of Large Language Models to Users?: Techpolicy
- A news site used AI to write articles. It was a journalistic disaster: Washington Post
- Diving Deeper into AI Package Hallucinations: Lasso Security
- How Secure is Code Generated by ChatGPT?: Arvix
- How to Reduce the Hallucinations from Large Language Models: The New Stack
- Practical Steps to Reduce Hallucination: Victor Debia
- A Framework for Exploring the Consequences of AI-Mediated Enterprise Knowledge: Microsoft
- Proof Pudding (CVE-2019-20634) AVID (
moohax&monoxgas) - arXiv:2403.06634 Stealing Part of a Production Language Model arXiv
- Runaway LLaMA | How Meta's LLaMA NLP model leaked: Deep Learning Blog
- I Know What You See:: Arxiv White Paper
- A Comprehensive Defense Framework Against Model Extraction Attacks: IEEE
- Alpaca: A Strong, Replicable Instruction-Following Model: Stanford Center on Research for Foundation Models (CRFM)
- How Watermarking Can Help Mitigate The Potential Risks Of LLMs?: KD Nuggets
- Securing AI Model Weights Preventing Theft and Misuse of Frontier Models
- Sponge Examples: Energy-Latency Attacks on Neural Networks: Arxiv White Paper arXiv
- Sourcegraph Security Incident on API Limits Manipulation and DoS Attack Sourcegraph
Original Paper: OWASP Top 10 for Large Language Models (LLM) Applications - 2025
Report generated by TSW-X
Advanced Research Systems Division
Date: 2025-03-17 09:37:18.887920


