
โดยปกติแล้วเมื่อเราต้องการที่จะข้อความจากภาพมานั้น เพื่อน ๆ คงนึกถึง Google Translate ที่จะสามารถอัพโหลดรูปภาพลงไปได้หรือหยิบกล้องมือถือ ขึ้นมาถ่ายจากนั้นก็จะได้คำแปลออกมาหรืออยากได้ข้อความนั้น ๆ แต่ว่าวันนี้เราจะพามาดูกันว่า เบื้องหลังเหล่ามีการทำงานแบบใด แต่ในบทความนี้ยังถือว่าเป็นจุดเล็ก ๆ และยังห่างไกลกับการทำงานของ Google Translate ทำ
OK งั้นเรามาเริ่มกันเลยดีกว่า ในบทความนี้เราจะพูดถึงเทคนิคในการประมวลผลภาพ (Image Processing) และ OpenCV ซึ่งน่าจะคุ้นหูกันมาบ้างแล้ว เพื่อใช้ในการแยกตัวอักษรที่อยู่ในภาพออกมาเป็นภาพย่อยที่ละตัว จากนั้นก็จะทำการบันทึกภาพเป็นไฟล์รูปภาพแยกที่ละตัวอักษรซึ่งเป็นพื้นฐานสำคัญของการทำงานด้าน OCR (Optical Character Recognition)
งั้นขอเพิ่มส่วนอธิบาย OCR หรือ การรู้จำอักขระด้วยแสง (Optical Character Recognition) : การรู้จำอักขระด้วยแสง หรือมักเรียกอย่างย่อว่า OCR คือกระบวนการทางกลไกหรือทางอิเล็กทรอนิกส์เพื่อแปลภาพของข้อความจากการเขียนหรือจากการพิมพ์ ไปเป็นข้อความที่สามารถแก้ไขได้โดยเครื่องคอมพิวเตอร์ การจับภาพอาจทำโดยเครื่องสแกนเนอร์ กล้องดิจิทัล โอซีอาร์เป็นสาขาวิจัยในการรู้จำแบบ, ปัญญาประดิษฐ์, และคอมพิวเตอร์วิทัศน์
อันดับแรกเลยนั้นก็คือการติดตั้ง library
pip install imutilsเป็น library Python เสริมสำหรับ OpenCV ที่มีฟังก์ชันอำนวยความสะดวก เช่น
การเรียงลำดับ contours, การย่อ/ขยายภาพ (resize), การหมุนภาพอัตโนมัติ, การแปลงองศา/พิกัด ซึ่งจะเป็น library หลักของเราในการทำงานในครั้งนี้
ขั้นตอนที่ 1 โหลดภาพ และแปลงเป็น Grayscale
import cv2
from imutils import contours
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
เราจะเริ่มจากการโหลดภาพที่มีตัวอักษรเข้ามาเข้ามาและแปลงจากภาพสีให้กลายเป็นภาพขาวดำ เพื่อให้สามารถนำไปประมวลผลต่อได้ง่ายขึ้น
ขั้นตอนที่ 2 ใช้ Otsu’s Threshold เพื่อแยกพื้นหลังกับตัวอักษร
thresh = cv2.threshold(
gray, 0, 255,
cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV
)[1]
ต่อมานั้นเราจะใช้ Otsu’s Threshold ที่ขะช่วยกำหนดค่ากลางอัตโนมัติเพื่อแยกพื้นหลังกับตัวอักษร โดยเราสั่งให้ทำ Invert (THRESH_BINARY_INV) เพื่อให้ตัวอักษรเป็นสีขาวและพื้นหลังเป็นสีดำ
ขั้นตอนที่ 3 หาขอบเขตของตัวอักษรและเรียงจากซ้ายไปขวา
cnts = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
cnts, _ = contours.sort_contours(cnts, method="left-to-right")เราจะใช้ cv2.findContours() เพื่อหาขอบเขตของตัวอักษรแต่ละตัว จากนั้นก็ขะใช้ sort_contours() จาก library imutils เพื่อเรียงจากซ้ายไปขวา ซึ่งเหมาะกับภาษาอังกฤษที่อ่านจากซ้ายไปขวา
ขั้นตอนที่ 4 ตัดตัวอักษรทีละตัวด้วย ROI และบันทึกภาพ
ROI_number = 0
for c in cnts:
area = cv2.contourArea(c)
if area > 10:
x,y,w,h = cv2.boundingRect(c)
ROI = image[y:y+h, x:x+w]
cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2)
ROI_number += 1

วนลูปในแต่ละ Contour ตรวจสอบว่า area มากกว่า 10 เพื่อกรอง noise ออก
ตัดสี่เหลี่ยมล้อมรอบตัวอักษร Bounding Box
บันทึกภาพแต่ละตัวเป็นไฟล์ ROI_0.png, ROI_1.png, ...
และในขณะเดียวกันก็ วาดกรอบสีเขียว แสดงผลลัพธ์ด้วย cv2.rectangle() เพื่อดูว่าโปรแกรมตรวจจับได้ถูกต้องหรือไม่
ขั้นตอนที่ 5 แสดงผลลัพธ์
cv2.imshow('thresh', thresh)
cv2.imshow('image', image)
cv2.waitKey()แสดงภาพ Threshold และแสดงภาพจริงที่มีกรอบครอบตัวอักษร
จากนั้นรอให้ผู้ใช้กดปุ่มเพื่อปิดหน้าต่าง
ตัวอย่างเพิ่มเติม
เราจะลองใช้ภาพอื่น ในการในการทดสอบว่า บทความการแยกและบันทึกตัวอักษรจากภาพด้วย Python และ OpenCV นี้ สามารถนำมาใช้งานจริงได้หรือไม่
ขั้นตอนที่ 1 โหลดภาพ และแปลงเป็น Grayscale
import cv2
from imutils import contours
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
เราจะเริ่มจากการโหลดภาพที่มีตัวอักษรเข้ามาเข้ามาและแปลงจากภาพสีให้กลายเป็นภาพขาวดำ เพื่อให้สามารถนำไปประมวลผลต่อได้ง่ายขึ้น
ขั้นตอนที่ 2 ใช้ Otsu’s Threshold เพื่อแยกพื้นหลังกับตัวอักษร
thresh = cv2.threshold(
gray, 0, 255,
cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV
)[1]
ต่อมานั้นเราจะใช้ Otsu’s Threshold ที่ขะช่วยกำหนดค่ากลางอัตโนมัติเพื่อแยกพื้นหลังกับตัวอักษร โดยเราสั่งให้ทำ Invert (THRESH_BINARY_INV) เพื่อให้ตัวอักษรเป็นสีขาวและพื้นหลังเป็นสีดำ
ขั้นตอนที่ 3 หาขอบเขตของตัวอักษรและเรียงจากซ้ายไปขวา
cnts = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
cnts, _ = contours.sort_contours(cnts, method="left-to-right")เราจะใช้ cv2.findContours() เพื่อหาขอบเขตของตัวอักษรแต่ละตัว จากนั้นก็ขะใช้ sort_contours() จาก library imutils เพื่อเรียงจากซ้ายไปขวา ซึ่งเหมาะกับภาษาอังกฤษที่อ่านจากซ้ายไปขวา
ขั้นตอนที่ 4 ตัดตัวอักษรทีละตัวด้วย ROI และบันทึกภาพ
ROI_number = 0
for c in cnts:
area = cv2.contourArea(c)
if area > 10:
x,y,w,h = cv2.boundingRect(c)
ROI = image[y:y+h, x:x+w]
cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2)
ROI_number += 1
วนลูปในแต่ละ Contour ตรวจสอบว่า area มากกว่า 10 เพื่อกรอง noise ออก
ตัดสี่เหลี่ยมล้อมรอบตัวอักษร Bounding Box
บันทึกภาพแต่ละตัวเป็นไฟล์ ROI_0.png, ROI_1.png, ...
และในขณะเดียวกันก็ วาดกรอบสีเขียว แสดงผลลัพธ์ด้วย cv2.rectangle() เพื่อดูว่าโปรแกรมตรวจจับได้ถูกต้องหรือไม่
ขั้นตอนที่ 5 แสดงผลลัพธ์
cv2.imshow('thresh', thresh)
cv2.imshow('image', image)
cv2.waitKey()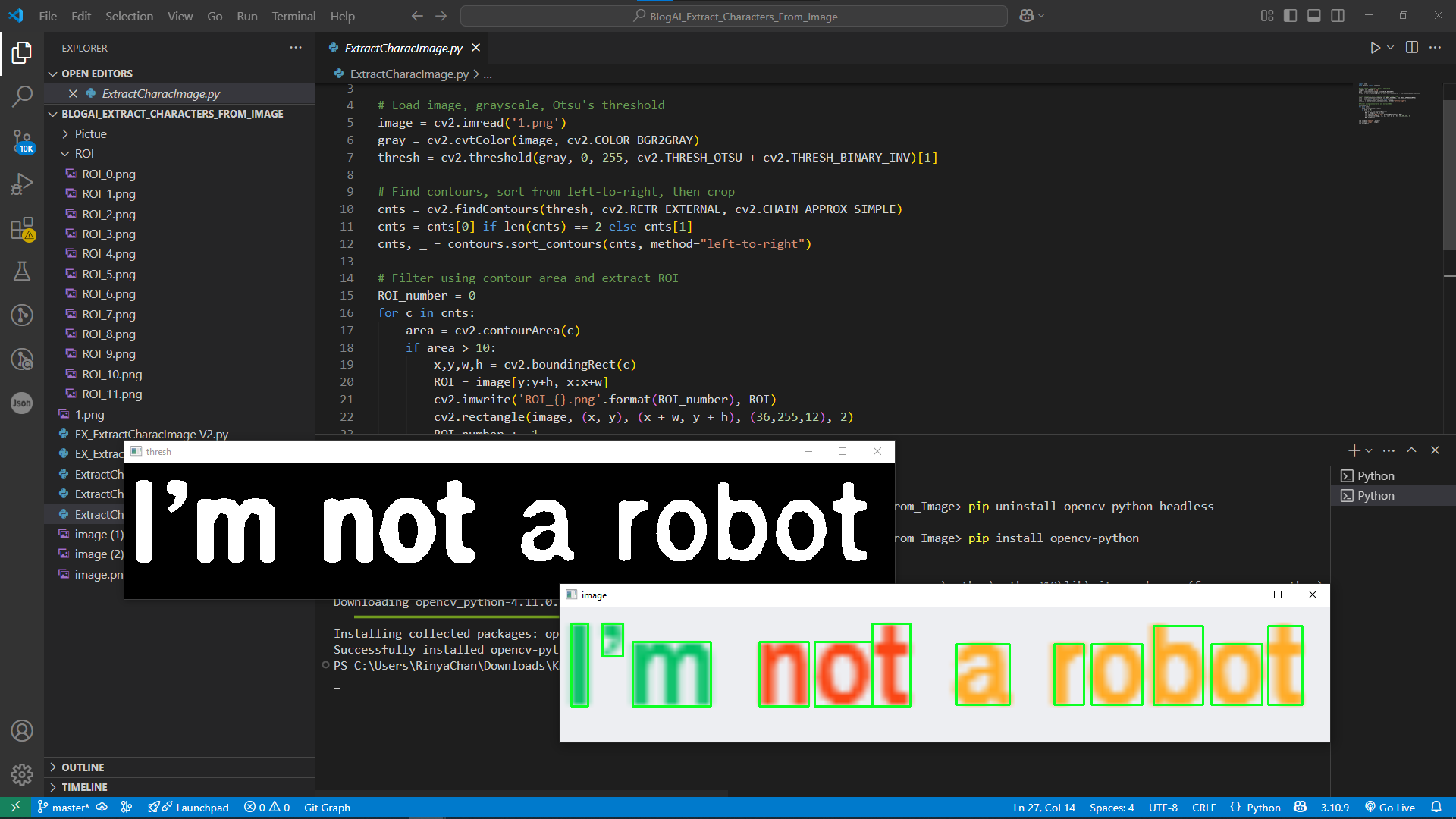
แสดงภาพ Threshold และแสดงภาพจริงที่มีกรอบครอบตัวอักษร
จากนั้นรอให้ผู้ใช้กดปุ่มเพื่อปิดหน้าต่าง
Code ทั้งหมด
import cv2
from imutils import contours
# Load image, grayscale, Otsu's threshold
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY_INV)[1]
# Find contours, sort from left-to-right, then crop
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
cnts, _ = contours.sort_contours(cnts, method="left-to-right")
# Filter using contour area and extract ROI
ROI_number = 0
for c in cnts:
area = cv2.contourArea(c)
if area > 10:
x,y,w,h = cv2.boundingRect(c)
ROI = image[y:y+h, x:x+w]
cv2.imwrite('ROI_{}.png'.format(ROI_number), ROI)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2)
ROI_number += 1
cv2.imshow('thresh', thresh)
cv2.imshow('image', image)
cv2.waitKey()สรุปผล
สรุปแล้วในบทความนี้ เราได้แสดงให้เห็นแล้วว่าสามารถที่จะใช้การประมวลผลภาพ (Image Processing) และ OpenCV ในการแยกและบันทึกตัวอักษรจากภาพได้จากตัวอย่างเพิ่มเติมที่มีซึ่งในบทความนี้ เราจะได้เรียนรู้การใช้ OpenCV เพื่อแปลงภาพให้พร้อมใช้งาน
แยกตัวอักษรจากภาพโดยใช้ threshold และ contours ตัดและบันทึกภาพตัวอักษรออกมาเป็นไฟล์ย่อย โดยเทคนิคนี้สามารถใช้เป็น ขั้นตอนเริ่มต้นในการเตรียมข้อมูลสำหรับระบบ OCR ได้ หรือจะใช้แบบ standalone เพื่อแยกข้อความจากภาพก็ได้เช่นกัน หรือนำไปต่อยอดในงานต่อ ๆ ไป
References
https://stackoverflow.com/questions/60515216/extracting-and-saving-characters-from-an-image


