From chatbots to automated content generation, AI applications are constantly changing the way we interact with technology and utilize them to transform operational workflows. Generative AI can write text, sketch images, and automate monotonous tasks, freeing professionals from completing less valuable and time-consuming tasks.
From chatbots to automated content generation, AI applications are constantly changing the way we interact with technology and utilize them to transform operational workflows. Generative AI can write text, sketch images, and automate monotonous tasks, freeing professionals from completing less valuable and time-consuming tasks.
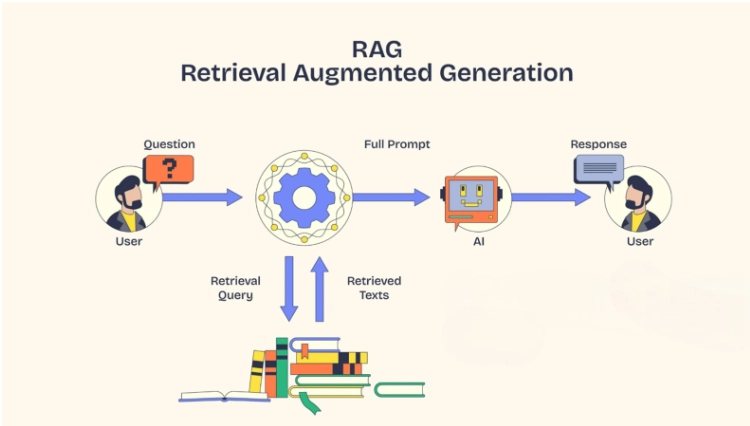
Retrieval-Augmented Generation, or RAG, is the solution. RAG is an AI framework that improves the LLM response accuracy by giving the LLM access to external data sources. The LLM is trained on enormous datasets, but they lack the specific context about a business, industry, or customer. So, instead of letting LLM rely solely on pre-trained knowledge, RAG retrieves the relevant data from external sources before LLM generates a response.
According to IBM, Advanced RAG AI Models improves AI accuracy by 85%, making everything much more factual and trustworthy. With companies relying more heavily on AI, RAG will be a boon, as it guarantees well-timed decision-making and trustworthy outputs. Let's discuss how RAG works, its advantages, and why it's a game-changer in today's age of modern AI and Gen AI applications.
What is RAG?
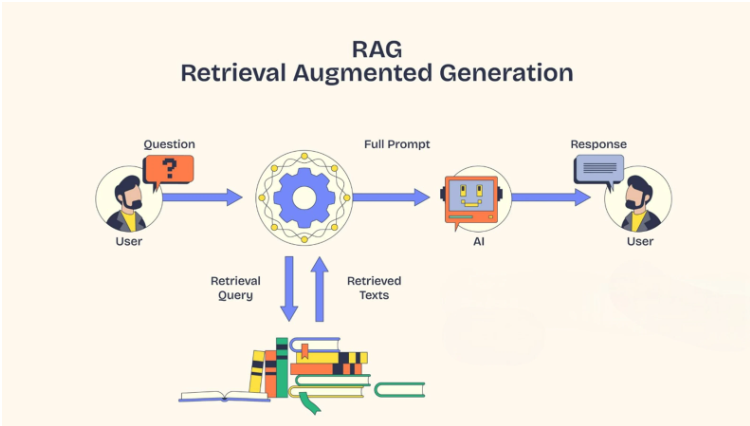
RAG is a technique that enhances the LLM’s capabilities to deliver accurate answers by incorporating real-time data retrieval. It allows the LLM to search external databases or documents during the output generation process to deliver accurate and up-to-date information.
Each RAG model has two major building blocks: the Retrieval Module and the Generation Module. The retrieval system searches through the extensive knowledge base and finds the most relevant information that matches the input sequence. This information is fed to the generative model, and it uses this to create a well-informed and accurate response.
According to a research paper, human evaluators found that RAG-based responses are 43% more accurate than LLM which solely relied on fine-tuning.
For instance, Meta’s RAG model is a differential end-to-end model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq-2-seq generator (Meta’s Bidirectional and Auto-Regressive Transformers [BART] model).
A neural retrieval system is an AI-based information retrieval method that uses deep learning models, especially neural networks, to retrieve relevant documents or passages based on a given query.
On the other hand, seq-2-seq is a deep learning architecture that converts one sequence into another of variable lengths. The seq-2-seq architecture is based on encoder and decoder components, where the encoder processes the input sequence into a fixed-length representation, and the decoder generates an output sequence based on this representation. The seq-2-seq architecture forms the foundation of LLMs designed for tasks such as machine translation, text summarization, chatbots, and question-answering.
The RAG model looks and acts like a seq-2-seq model; however, there is one intermediary step that makes all the difference. Instead of sending the input sequence to the generator, RAG uses the input to retrieve a set of relevant documents or information from a source, like Wikipedia.
So, the LLM based on RAG architecture supports two sources of knowledge: 1. Knowledge that the seq-2-seq model stores in its parameters (parametric memory) 2. Knowledge stored in the corpus through which RAG retrieves external information (non-parametric memory)
These two sources complement each other. The RAG architecture gives flexibility to LLMs that rely on a closed-book approach (pre-learned knowledge) to improve the accuracy of responses by integrating with models that follow the open-book approach (fetch real-time information from external sources).
For example, if a prompt “when did the first mammal appear on Earth” is searched, then the RAG looks for documents with “Mammal”, “History of Earth”, or “Evolution of Mammals”. These supporting documents are concatenated as the context with the original input, and it is fed to the seq-2-seq model to produce the output.
**
How Does RAG Work?
**
Retrieval Augmented Generation uses entirely different forms of outside knowledge to enhance an AI-generated response. In contrast to former models, which were heavily reliant on pre-trained data, RAG dynamically retrieves relevant information before generating an answer. Accuracy, therefore, improves while the rate of misinformation is effectively reduced. According to Meta AI, RAG has improved response precision by over 60% as opposed to normal generative models. This is how it works:
Step 1: Understanding Query
- Firstly, the model takes the input query from the user.
- It understands the key intent, keywords, and context by applying Natural Language Processing (NLP) methods.
Step 2: Information Retrieval
- Searching for relevant information from outside knowledge bases like Wikipedia, databases, or private documents.
- It does not just rely on dense retrieval using vector embedding techniques to extract contextually relevant documents.
- Advanced techniques such as FAISS (Facebook AI Similarity Search) and BM25 improve the search efficiency.
Step 3: Context Integration
- The documents retrieved have been processed and ranked for relevance.
- Content retrieved through this process is grouped with the self-originated user query to form an enriched input.
- Important data are refined and weighted by the self-attention mechanisms of transformer models.
Step 4: Response Generation
- The generative model, usually a transformer-based architecture such as GPT-4, uses this enriched context to generate an answer.
- Reduces hallucination and provides real-time, fact-based answers.
Step 5: Output Delivery
- The post-processing algorithm is a means for adjusting the ultimate result to the human ends of its expression.
- As a result, the system responds with a very well-sourced, accurate, and context-based answer.
Retrieval-augmented generation keeps and updates the AI models such that, with context accuracy critical for application-based ones in financial, healthcare, and legal research, it becomes a combination of retrieval and generation.
Read The Full Blog:-https://www.bitontree.com/blog/understanding-rag-in-generative-ai


