This article was originally published on IBM Developer by Cedric Clyburn
Incorporating artificial intelligence (AI) into an organization isn't a matter of flipping a switch; it requires careful customization to suit specific business needs. When adapting large language models (LLMs) for the enterprise, there are typically two primary strategies to choose from: fine tuning and retrieval augmented generation (RAG). While fine tuning focuses on shaping the model's responses and behavior, RAG relies on integrating external data into the model's workflow. Both approaches customize LLM behavior and output, but each is uniquely suited to different use cases and types of data. So, let’s explore each method to help you determine the best fit for your needs.
Adapting large language models for enterprise use
LLMs are robust systems trained on vast data sets, but while general-purpose LLMs excel at diverse language tasks, they often lack the specific knowledge or behavioral capacities required for enterprise applications.
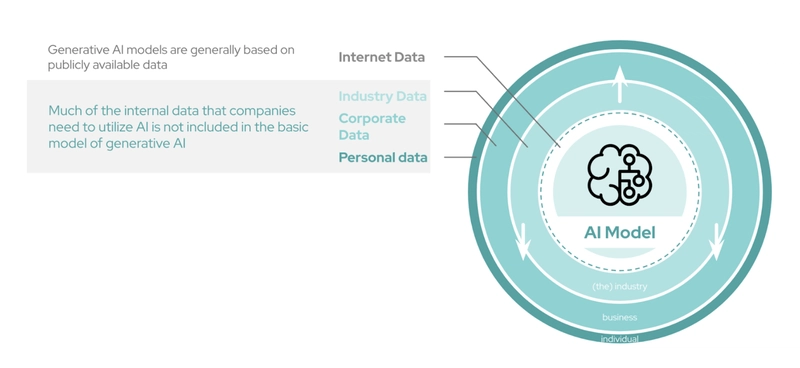
For truly useful applications of generative AI, applying industry, corporate, and personal data is where value is maximized.
For truly useful applications of generative AI, applying industry, corporate, and personal data is where value is maximized.
In specialized fields such as finance, healthcare, or customer support, developing an AI strategy means needing a model or system that is tailored to a specific purpose. However, this is highly dependent on the nature of the data an organization is working with—It all comes down to your data.
AI's effectiveness is fundamentally tied to data, and enterprises need to assess if their data is static (unchanging over time) or dynamic (frequently updated). To help simplify this, let’s imagine for a moment that I’m giving you a new task to learn about a new subject or skill. You have two options here: you could either learn and teach yourself the content or outsource it to others. When we talk about fine tuning versus RAG, it’s a similar concept.
There may be foundational, domain specific knowledge and processes that would be helpful for a model to understand, but what if information is dynamic and evolves quickly? In that case, simply providing it to an LLM on demand can be more effective. However, let’s take a closer look at real-world examples of these approaches being used and understand when to take each approach.
Introducing new model capabilities: The role of fine tuning
Fine tuning can adapt a general-purpose LLM into a domain-specific expert by training it on curated datasets. This process adjusts the model’s internal parameters, embedding static, foundational knowledge and aligning its behavior with specific tasks or industries. For example, a fine-tuned model in healthcare can generate accurate, context-aware responses while understanding compliance standards.
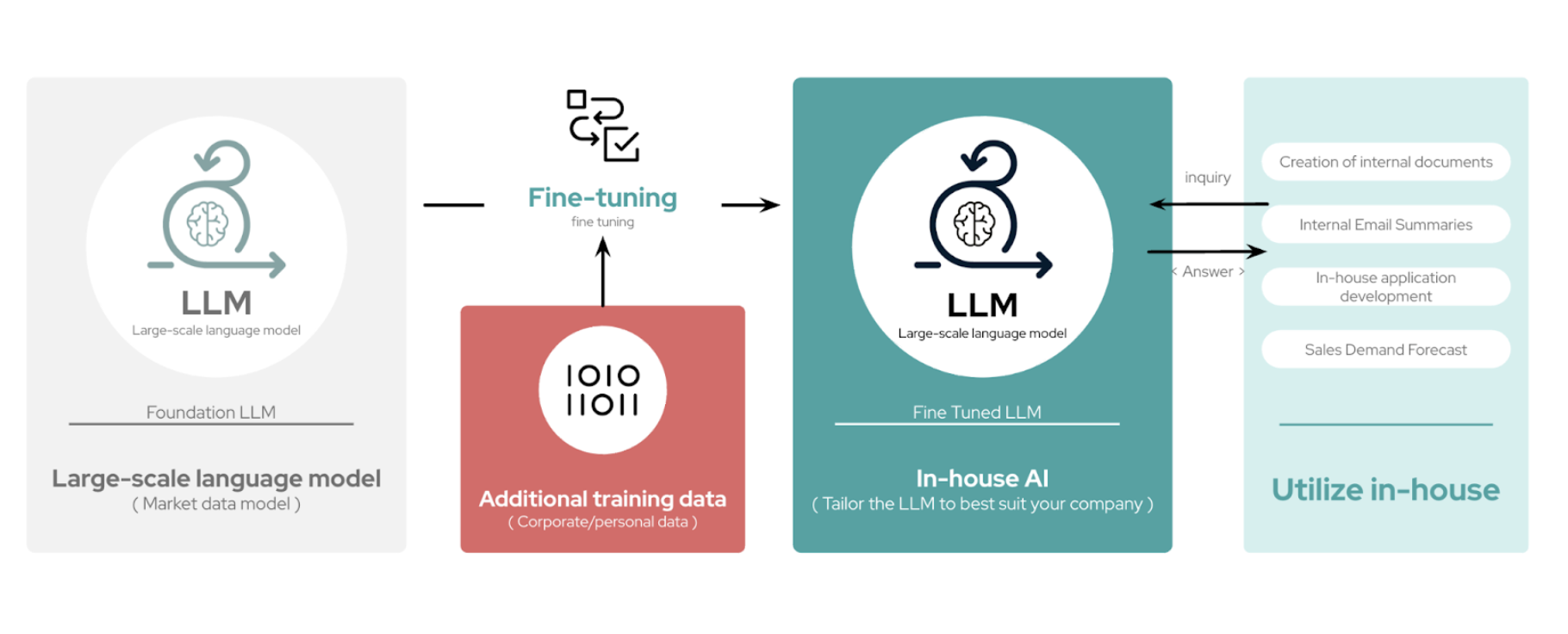
Fine-tuning allows an LLM to internalize domain-specific knowledge, enabling precise and consistent outputs tailored to enterprise needs.
This approach is best suited for scenarios involving stable, unchanging data or tasks requiring consistent outputs, such as regulatory documentation or specialized terminology. While resource-intensive, fine-tuning ensures precise alignment with enterprise goals, making it ideal for long-term, static use cases.
Integrating with your data: The case for RAG
Due to the historical nature of training and fine-tuning being a complicated process, RAG has been adopted by both developers and enterprises to complement general-purpose LLMs with up-to-date and external data. This means having the ability to take a model off the shelf, regardless of whether it’s proprietary or open source, and enable access to data repositories and databases without re-training. You’ll typically encounter these steps in the approach:
Data transformation:
Converting enterprise data into a format accessible by the AI, such as embedding knowledge into a searchable format.Storage in a knowledge base:
Organizing data within a knowledge library, which the model can access in real time.Response generation:
Using the knowledge base, the AI system retrieves relevant information to generate accurate, evidence-backed answers.
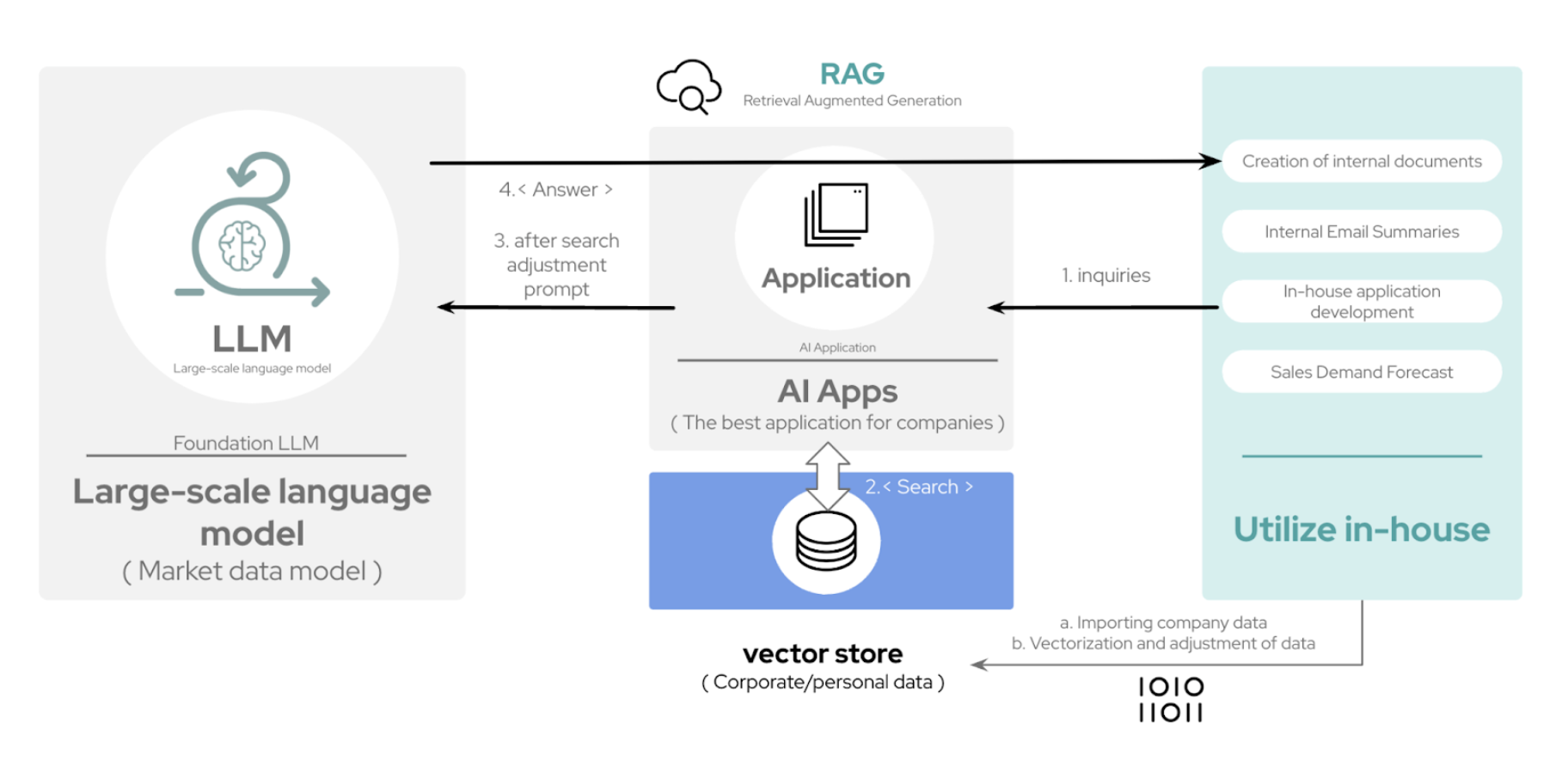
For customer support applications, RAG allows the LLM to draw from source data, delivering accurate responses that foster more trust and transparency. This evidence-backed answer component is important, as the idea of overconfidence, or hallucinations, is an issue when adopting AI into business use cases. However, it’s important to note that tuning and maintaining a RAG system is complex, requiring robust data pipelines to pull and feed timely information to the model during usage.
The best of both worlds: Combining fine tuning and RAG
Much like how businesses can benefit from a hybrid cloud and on-premise approach for their workloads, an AI strategy can combine fine tuning and RAG to best meet their needs. This results in an LLM being a subject matter expert in a specific field, deeply understanding specific content and terminology while staying current. For example, you could combine both resulting in a fine-tuned model on your domain-specific data to understand your industry’s context, while leveraging RAG for up-to-date information from databases and content stores. Scenarios such as financial analysis or regulatory compliance are just a few situations where the combined strategy would be immensely helpful.
While we’ve covered how these approaches can be helpful for business use cases, it’s important to understand that these techniques, specifically with fine tuning, allow us to set core behavioral parameters in these AI models themselves. This is incredibly important as we use AI to reflect our values and goals, not just our expectations. Enterprises should begin by figuring out what sticks and what doesn’t, and use those lessons to continue building great things.
If you'd like to learn how to start fine tuning models for experimentation and development, try out InstructLab, an open source project supported by IBM and Red Hat, by completing this tutorial, "Contributing knowledge to the open source Granite model using InstructLab."
