
AI is changing how we build software.
But as builders, we’re quietly ignoring a major flaw:
- We don’t test our prompts.
- We just deploy them… and hope.
The Moment It Broke
I was working on an AI feature that relied on a simple prompt to generate short summaries.
Same model. Same prompt. Temperature 0.1.
Ran it ten times and got five different outputs. Some subtle. Some wildly off.

It hit me: If your API response is unpredictable, your product is unreliable.
Why This Is Getting Worse
AI models are non-deterministic, which means slight differences are expected. But that doesn't mean they're acceptable in production.
To make matters worse:
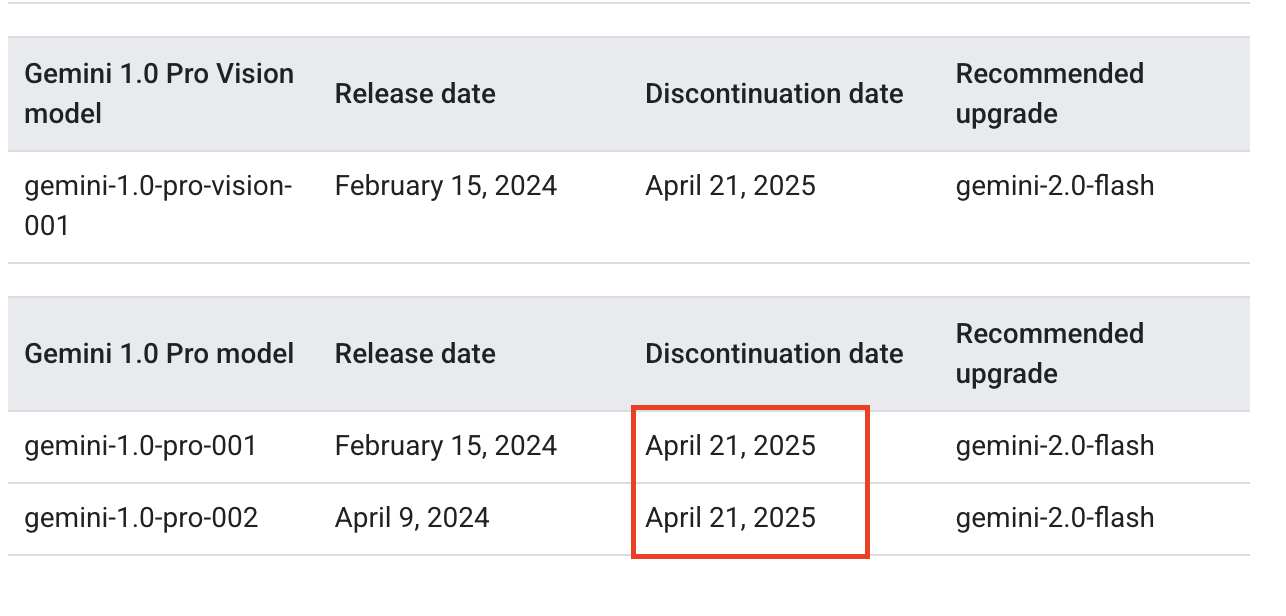
- Gemini 1.0 is already deprecated
- GPT-4.0 could be next
- Each update subtly changes model behavior
- Prompts that worked yesterday might break tomorrow
If you're building AI-first apps, you're in a loop of:
Test → Fix prompt → Re-test → Cross fingers → Repeat
That’s hours of work.
Every. Time. A. Model. Changes.
So I Built PromptPerf.dev
I needed a tool to help me trust my AI outputs before shipping.
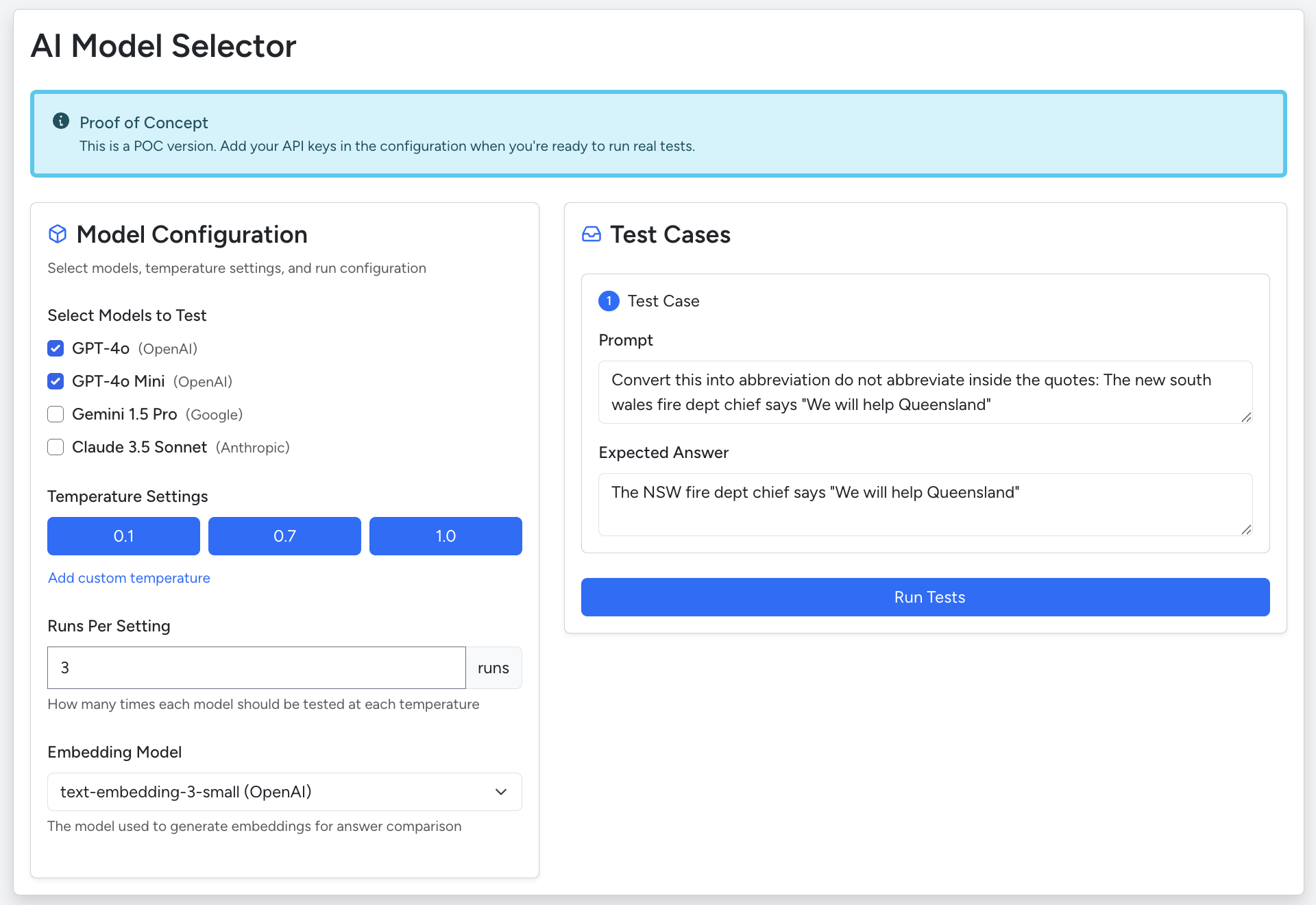
PromptPerf.dev is a playground for prompt testing:
✅ Test your prompt across multiple AI models
✅ Run it at different temperatures
✅ Compare outputs across multiple runs
✅ Track consistency + score against expected answers
Here’s a sneak peek:
Where We're Headed
Right now, I’m building this in public. It’s early — but focused.
Why This Matters
If you're building with LLMs, you know the feeling:
- The "it worked locally" moment — but with GPT
- A broken chain in Langchain or RAG that fails silently
- Users noticing weird output before you do
PromptPerf doesn’t replace model tuning.
It makes prompt reliability visible.
💬 I’d Love to Hear From You
- Have you run into inconsistency issues?
- What’s your current prompt testing workflow (if any)?
- Should prompt testing be part of CI/CD?
If this resonated, join the waitlist or just drop your thoughts below — I'd genuinely love feedback as we build.
🧪 PromptPerf.dev — build AI products you can trust.


