I remember back in my days of being a Systems Administrator, I had lots of fun building a monitoring server from scratch with Nagios. Anyone old enough to remember it? Looks like Nagios is still alive and kicking these days too.
What that involved every time there was a cryptic Linux related error, I had to do the “man” command or —help to start off with. Then running verbose mode to try to debug without much success. Then searching the internet for any clues, usually on Stack overflow at that time and it was either “Duplicate question, closing” or “I solved the problem!” Without any details on how they solved it. It was frustrating and I remember either trying to do a temp workaround of some sort or give up configuring that particular feature.
More than 15 years later - things have gotten much much easier in some ways but also complex.
The move from VMs to containers and going from tightly coupled monoliths to micro services.
Was micro services meant to make your life as a Platform/DevOps Engineer simple?
Maybe - but there are still complexities on how to continue being operationally excellent and keeping up with the dreaded Kubernetes version upgrades.
This works if you’ve got a handful of non-critical applications running. What about in an enterprise scenario where you do have critical workloads running and more than a few of them?
I’ve lived through troubleshooting Kubernetes with a customer - rather, trying to upgrade their Kubernetes version and making it work with their applications on non-prod. We were frantically working to fix this as a new Kubernetes version was going to be force rolled out in their prod environment for security reasons, and the customer was so far behind in versions.
Basically it was a team of people trying all the different kubectl commands under the sun to try and troubleshoot what’s broken - without prior knowledge of the workload. Somehow, we were able to avoid the imminent disaster in time, but it wasn’t ideal.
After that incident, I was continually on the search around how do we make Kubernetes operations simple for customers.
This coincided with the launch of Amazon EKS Auto Mode.
What is EKS Auto Mode? I would say a better, improved version of AWS Fargate for EKS.
On Fargate for EKS, there were quite a few limitations, including the ability to not be able to run daemonsets and other networking and storage considerations.
EKS Auto Mode brings best practices of Amazon EKS into one place without most of these limitations.
For example, EKS Auto Mode keeps your Kubernetes cluster, nodes and other components up to date with the latest patches up to a 21 day window.
This still means that your organisation needs to make sure that your applications running on EKS need to be tested and ready for the next Kubernetes version.
I started playing around with Auto Mode per the AWS documentation and then a thought came to my mind.
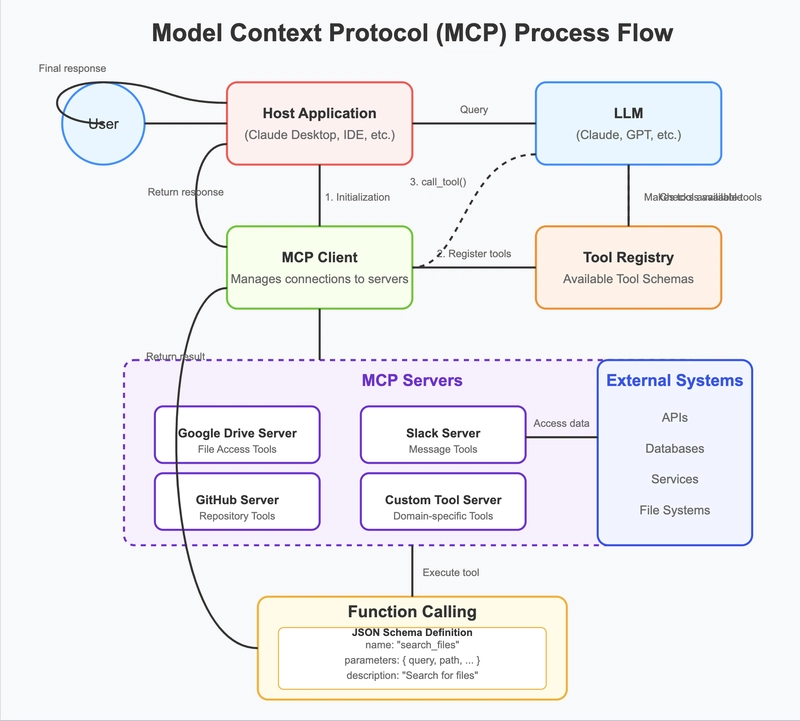
What if you could run connect an MCP server to Amazon EKS Auto Mode?
MCP is a protocol that helps standardise communication with LLMs.
According to Anthropic, it’s like a USB C port to connect data sources and tools.
Basically, the aim is to reduce operational overhead of development.
Why would anyone want to do that with Amazon EKS?
Well wouldn’t that help with troubleshooting endlessly with kubectl until the break of dawn? (I shouldn’t have given up on my rap career)

Then I stumbled into this GitHub repo. Shout out to Alexi-led for an awesome project.
So I decided to give it a try. It wasn’t difficult to get started at all.
I was impressed by how it could automatically run the kubectl commands via the Claude Desktop UI.
No more frantically looking up the kubectl commands and switches on the CNCF webpages.
Wait… does that mean CNCF certifications like CKA (Certified Kubernetes Administrator) and CKAD(Certified Kubernetes Application Developer) is going to be obsolete?
I wished at that time we had something like an MCP server that could interrogate your EKS workloads and ask it questions in natural language. It sure would have made the troubleshooting much easier!
So here’s a video of me asking questions about my current Amazon EKS setup.
It dives into great detail around the current configuration, including the number of pods, deployments and services etc.
I was then curious around whether it was running Auto-Mode or EC2s behind the scenes. I think in this case, it was undecided as it said it was Auto-Mode and some type of managed services but it had instances starting with i- . The correct answer is yes this is Auto-Mode, as Karpenter has been installed out of the box as with other automations.
I then asked it to scale the amount of nodes to test out Karpenter. It did this seamlessly and I was taken by surprise. I know Karpenter is meant to scale automatically without you having to trigger or input the scaling, I just wanted to see if Claude knew what it needed to do. And of-course testing the scaling back down gracefully was satisfying as well.
So imagine being able to ask Claude to troubleshoot especially if you’ve exhausted all options and it’s 2AM in the morning and your brain isn’t working.
Wouldn’t it ease some stress off your day to day life as an Engineer?