Honestly, it's less about choosing one tool over another and more about understanding how each tool links with the next and the existing tooling. As you embark on the Kubernetes scaling journey, remember that this ecosystem is as dynamic as it is complex.🧩
Why Kubernetes AutoScaling is Important?
Imagine yourself organizing a weekend street festival. You start small, a couple of food stalls, local stores, a trickle of visitors. Then word spreads on social media and, overnight, you're dealing with crowds the size of a small concert. Your challenge isn't just more chairs or another coffee shop, it's how you flex your setup on the fly without breaking customer experience 🎠. In Kubernetes, scaling features play the role of your festival crew. The trick is to combine different helpers, Horizontal Pod Autoscaler, Vertical Pod Autoscaler, KEDA, and Node Autoscaling, so they cover each other's blind spots and keep the music playing.
Horizontal Pod Autoscaler (HPA):
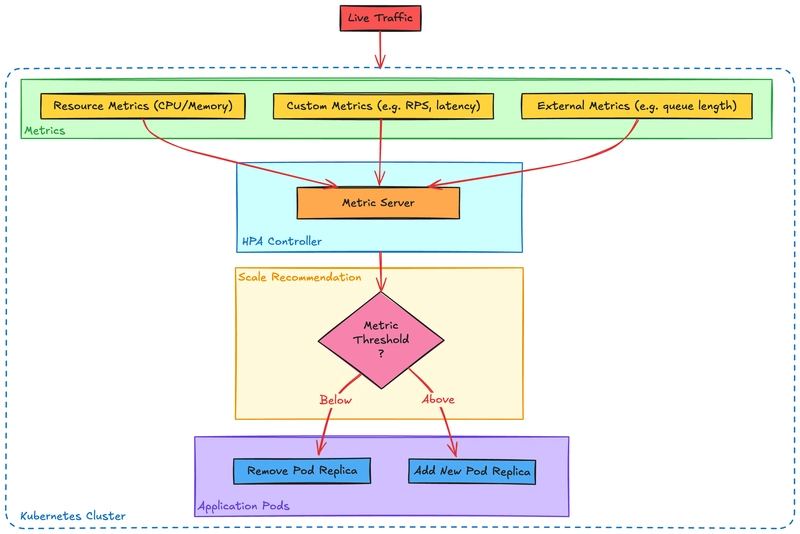
The Horizontal Pod Autoscaler monitors metrics such as CPU utilization or custom application metrics, and based on these indicators, it scales out or in by increasing or decreasing the number of pod replicas.
So, how does HPA work in practice?
Imagine you run a small coffee shop. During normal hours, you have 2 baristas handling all the orders. But during peak hours, like in the morning rush, there are too many customers, and the line gets long. What do you do? You bring in more baristas to handle the load and serve coffee faster. When the rush dies down, and it gets quiet again, you send the extra baristas home to save on costs.
Similarly, HPA continuously assesses the workload and, when it senses higher demand, spins up additional pod instances to ensure smooth operations. Conversely, when the load subsides, it scales down to conserve resources, much like traffic lights returning to normal patterns at night.
🧭 Note: This shows how HPA is more flexible than many realize. It isn’t just about CPU, it’s a plug-and-play scaling engine once you hook it to custom or external metrics. Also, lesson learned - always specify CPU & memory requests when configuring resources, if you want reliable reactions.
Vertical Pod Autoscaler (VPA):
While HPA focuses on the number of pods, Vertical Pod Autoscaler modifies the resource requests and limits of individual pods, ensuring that each application instance can handle the workload assigned to it without being over- or under-provisioned.
So what makes VPA essential?
You're still running that coffee shop. But instead of hiring more baristas during peak hours, you try a different approach - Instead of hiring more baristas, sometimes you give them better tools, like faster espresso machines or sharper milk frothers. Train them to be more efficient, so that they can serve more customers per minute. When it’s slow, you let them use simpler tools and take it easy(cost optimization).
While HPA expands your team, VPA tweaks each member's workload capacity. For Kubernetes, this means tuning the pod's CPU and memory allocations according to its needs, preventing wasteful allocation while avoiding resource starvation. While HPA expands your team, VPA tweaks each member's workload capacity. It's like having a personal trainer adjust each performer's stamina and strength so they deliver peak performance—no more, no less.
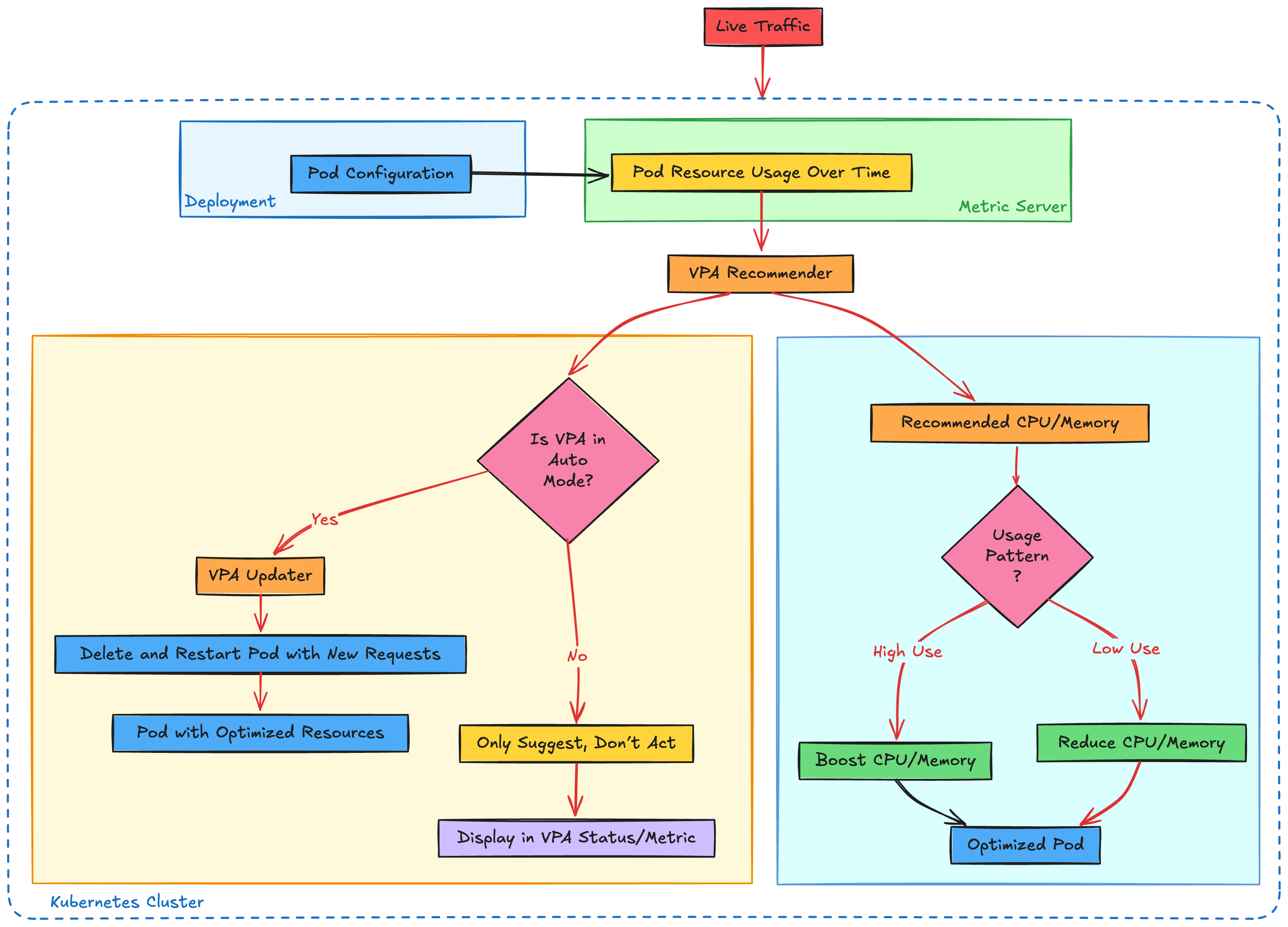
🧭 Note: The VPA doesn’t update running pods—it replaces them, which is critical to understand if you're running stateful or long-lived jobs.
KEDA: The Event‑Driven
Enter KEDA - the Kubernetes Event-driven Autoscaler, which adds an entirely new dimension to scaling. Imagine a city with pop-up events, a flash mob or a surprise concert that brings an unexpected gathering of people to the coffee shop. KEDA responds to external events or queued messages by scaling your Kubernetes workloads in real-time, independent of traditional resource metrics.
So, how does KEDA work?
KEDA monitors external event sources like message queues, databases, or custom event providers, and triggers scaling based on defined metrics. It integrates seamlessly with HPA, often acting as a complementary mechanism that anticipates sudden surges in demand. It triggers scaling actions even when the HPA detects stable conditions.
KEDA's strength lies in its ability to decouple scaling decisions from the traditional CPU& memory metrics, which makes it perfect for applications that react to irregular but critical events, like an online flash sale or a sudden spike in API calls. Just define a ScaledObject, point it at your queue, and let KEDA do its magic.
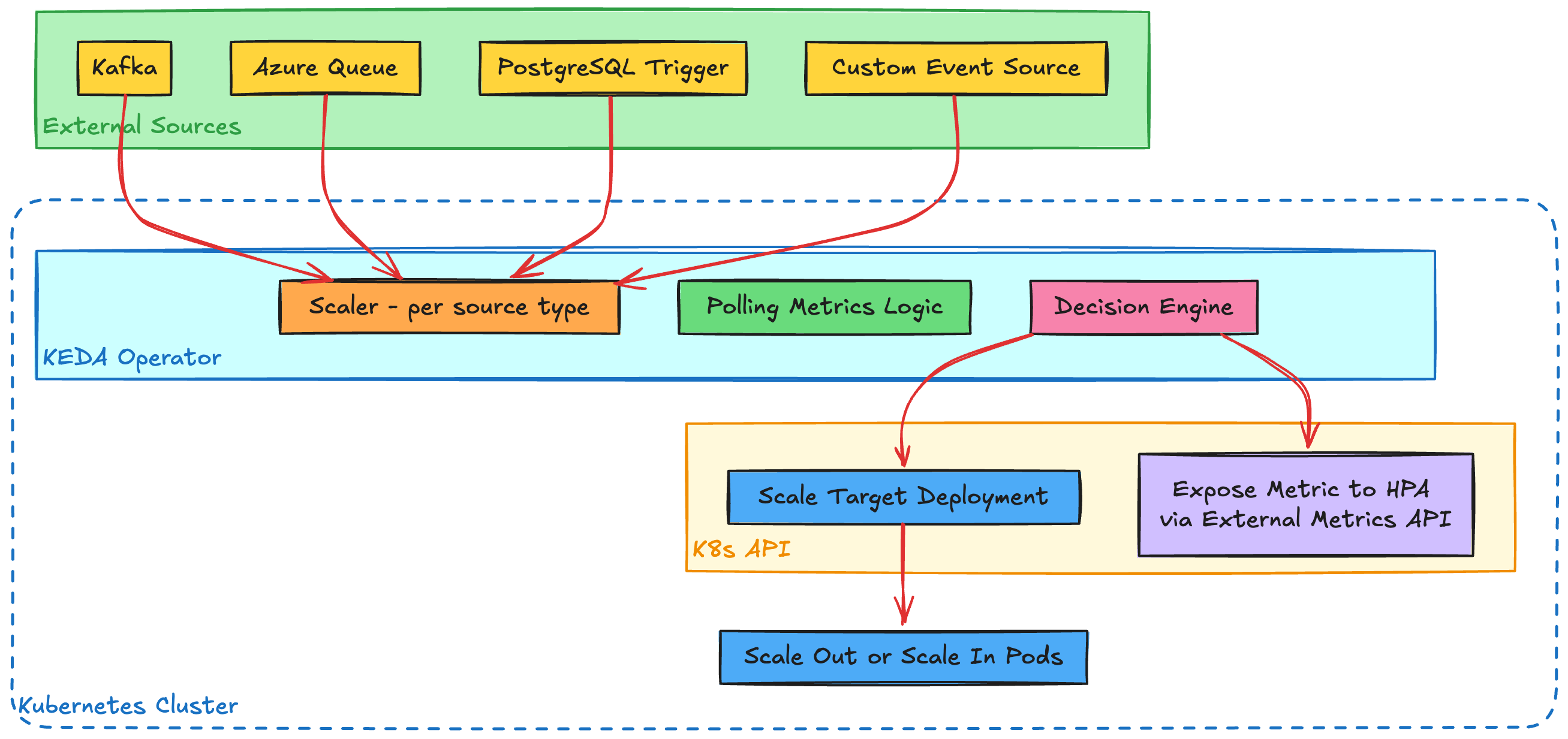
🧭 Note: KEDA doesn’t just scale deployments directly; it also feeds metrics to HPA, acting as a bridge between external event systems and Kubernetes-native autoscaling.
Cluster Autoscaler: Scaling the Foundation
All the pod-level magic in the world won’t matter if your cluster nodes themselves are out of breath. Enter the Cluster Autoscaler, Kubernetes' answer to auto-expanding your actual compute fleet.
Node Pools and Labels: Define pools for different workloads (e.g., gpu-node-pool, spot-instance-pool) and let the autoscaler respect node affinities and taints.
Scale Out: When pending pods can’t fit on existing nodes, the autoscaler requests new nodes from your cloud provider or on-prem scheduler.
Scale In: Idle nodes (with no scheduled or low-priority pods) are cordoned and drained, then removed to save costs.
🧭 Note: Tune the scale down delay to avoid premature node deletions during fleeting load dips. A too-aggressive scale-down often leads to rapid spin-up/down cycles, which can hurt performance and billable minutes.
Beyond the Basics: A Holistic Ecosystem Perspective, When to Mix, Match, or Mistrust
Now, while HPA, VPA, and KEDA are powerful individually, the real magic happens when they're orchestrated together. Kubernetes administrators are the conductors who must balance these elements to ensure that applications perform reliably under any condition.
👉 HPA + VPA = Powerful Pair
Combining horizontal breadth with vertical depth usually covers 80% of use cases. I start here for most web‑tier and API services.
👉 KEDA for the Complex Cases
When the traffic patterns are driven by events, like external triggers, KEDA bridges the gap. Just don't expect it to replace HPA, think of it as a safety net.
👉 Cluster Autoscaler
Pods are only as useful as the nodes beneath them. Without node scaling, you risk choking on unfillable pending pods or wasting dollars on oversized clusters.
👉 Interactions in Real-World Scenarios
Imagine an e-commerce platform during Black Friday. HPA can scale the number of pods in response to rising traffic, VPA adjusts each pod's resource allocations based on the varying load from backend processes, and KEDA kicks in to manage sporadic events such as flash sales notifications or rapid order processing bursts. Together, they ensure that the entire system remains robust, responsive, and cost-effective.💸
👉 Observability Is Non‑Negotiable
No matter how many autoscalers you deploy, without clear dashboards and alerts, you're sprinting blind. Tools like Prometheus and Grafana provide the eyes and ears for this orchestration. They allow operators to visualize metrics in real-time, set alerts, and even predict when scaling might become necessary. My favorite trick: a combined alert that fires only when HPA, VPA, and KEDA decisions all point toward trouble.
Glancing Ahead: Smarter, Predictive, Multi‑Cloud
🔮 I won't pretend to have a crystal ball, but I'm excited about:
Predictive Autoscaling:
ML‑driven insights that forecast busy hours and pre‑warm capacity—think of it as deploying extra food stalls based on last year's festival data.Multi-Cloud Environments Scaling:
As organizations diversify their infrastructure, autoscaling solutions will need to not only manage load within a single cluster but also across geographically dispersed environments.
3 . Intent-Driven Policies:
Imagine declaring, “Optimize for cost under 10% error rate,” and the autoscaler picks the right mix of HPA, VPA, node scaling, and spot instances to meet that goal, now read the first word of this sentence.🌀
Final Thoughts
Scaling Kubernetes isn't about flipping a single switch, it's a well choreographed dance between multiple controllers, each with its quirks and temperament. In my experience, the most resilient systems are those where HPA, VPA, KEDA, and Cluster Autoscaler aren't just enabled, but thoughtfully tuned, and where the team never stops questioning whether the defaults still make sense.
As you refine your own autoscaling symphony, embrace the messiness: the odd spike that breaks patterns, the silent nights when resources sit idle, and those triumphant moments when capacity snaps to attention just in time. After all, true mastery isn't measured by perfect performance, it's proven by how gracefully you recover when everything goes sideways.🕺
⚠️ Implementation walkthrough in the upcoming blogs!🔜
Thanks for reading, I hope you found it interesting and enjoyed it!🎊🥂
📚 Recommended Resources:
