1.Introduction
This project demonstrates how to create a fully serverless chatbot using Amazon Bedrock, Amazon Kendra, and your own documents (PDF, TXT, CSV, etc.). This chatbot uses Retrieval Augmented Generation (RAG) to generate accurate and context-aware responses based on enterprise knowledge bases.
The solution is ideal for use cases such as:
• Technical support automation
• HR knowledge queries
• Compliance document search
• Enterprise data exploration
2.Objective
•Identify the key features of Amazon Bedrock, Amazon Kendra, and AWS serverless services.
•Explain the concept of Retrieval-Augmented Generation (RAG) and how it applies to building an AI-powered chatbot.
•Determine how to use Amazon Bedrock and Amazon Kendra to index and retrieve data from a knowledge base for chatbot interactions.
•Demonstrate how to construct a fully functional generative AI-powered chatbot for a specific use case, integrating Amazon serverless services to efficiently handle application code execution.
3.Architecture
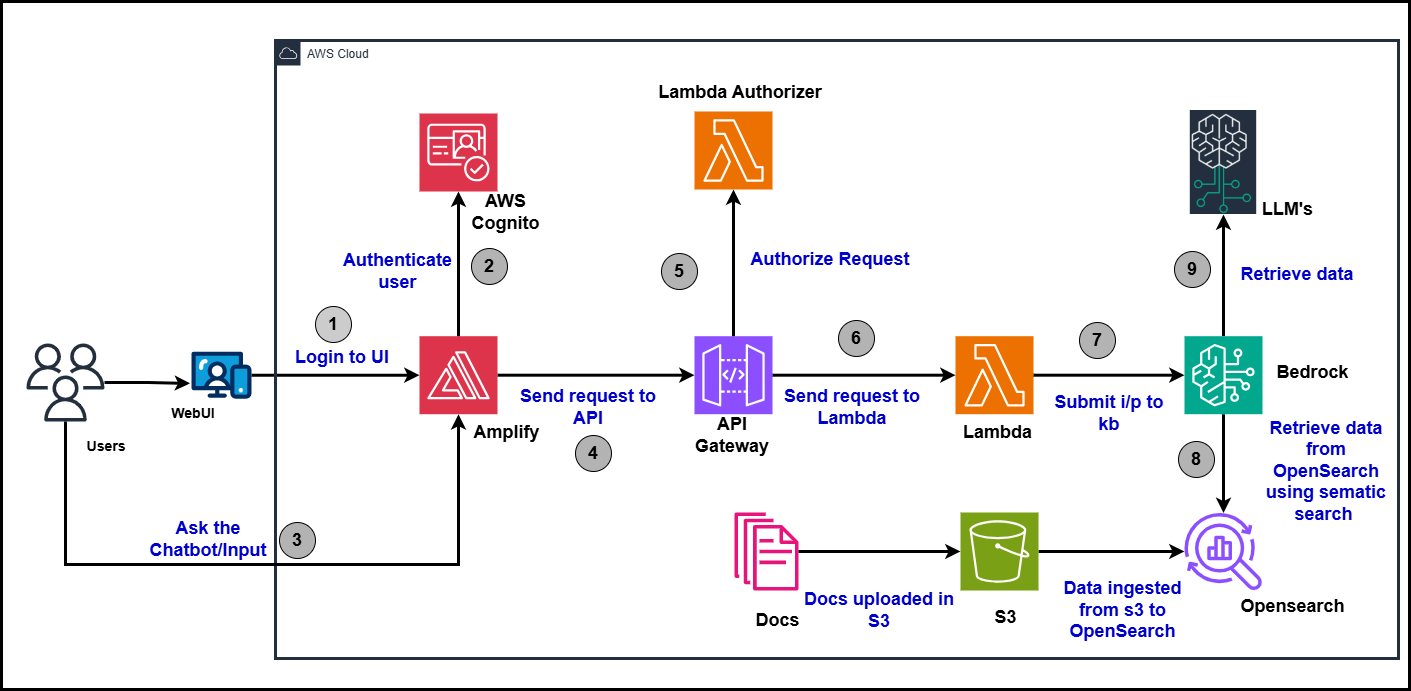
4.Technology Stack
1.Users: End-users of the chatbot
2.Web UI: User interface for chatbot interaction
3.AWS Amplify (React, Vue js): Manages front-end and authentication, specifically using React or Vue.js
4.Amazon API Gateway: Handles API requests
5.AWS Lambda (RAG/KB/LLM Functions): Executes serverless functions for Retrieval-Augmented Generation, Knowledge Base operations, and LLM interactions
6.Amazon Bedrock: Provides access to AI models and services
7.Large Language Models (Claude 3, Mistral, Llama etc.): AI models powering responses
8.Knowledge Bases: Stores structured information
9.Amazon S3: Object storage for documents and data
10.Documents (pdf, csv, txt etc.): Various file types for ingestion
11.Amazon OpenSearch: Vector database and search engine for efficient similarity search
12.Amazon Cognito: User authentication and authorization.
5.Implementation (Step-by-Step)
5.1 IAM Permissions and Roles
1.Kendra Role
- Open IAM Console Go to IAM Roles in AWS Console → Click Create role.
- Choose Trusted Entity •Trusted entity type: AWS Service •Use case: Choose Kendra •Click Next 3.Name and Create the Role •Role name: AmazonKendra-us-east-2-chatbot-2025 (or your naming convention) •Click Create role
- Add Permissions Policy •Click Create policy → Choose JSON tab •Paste the following policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowS3ReadAccess",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-s3-bucket-name",
"arn:aws:s3:::your-s3-bucket-name/*"
]
},
{
"Sid": "AllowCloudWatchLogging",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}•Click Next, then Create policy
- Name and Create the Role •Role name: AmazonKendra-us-east-2-chatbot-2025 (or your naming convention) •Click Create role
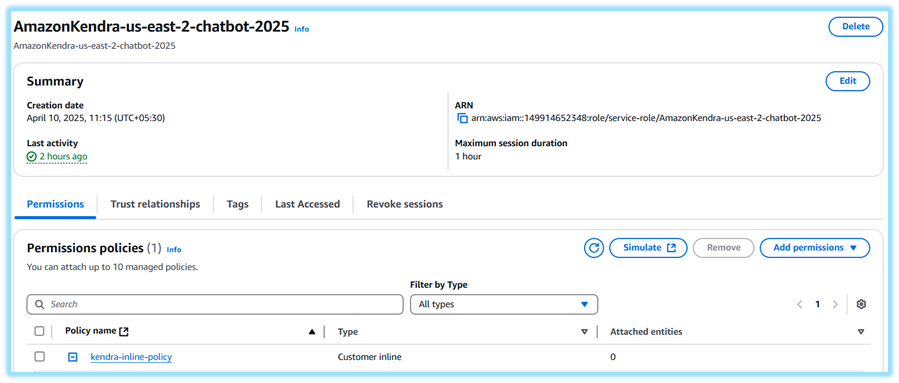
2. Lambda Execution Role
•Go to IAM > Roles > Create role
•Choose AWS Service > Lambda > Click Next
•Attach these 7 AWS managed policies:
AmazonBedrockFullAccess
AmazonCognitoPowerUser
AmazonKendraFullAccess
AmazonS3ReadOnlyAccess
AWSLambdaBasicExecutionRole
AmazonAPIGatewayInvokeFullAccess
AmazonSSMReadOnlyAccess
•Click Next → (Skip tags) → Name it Chatbot_Lambda_Role_2025 → Click Create role
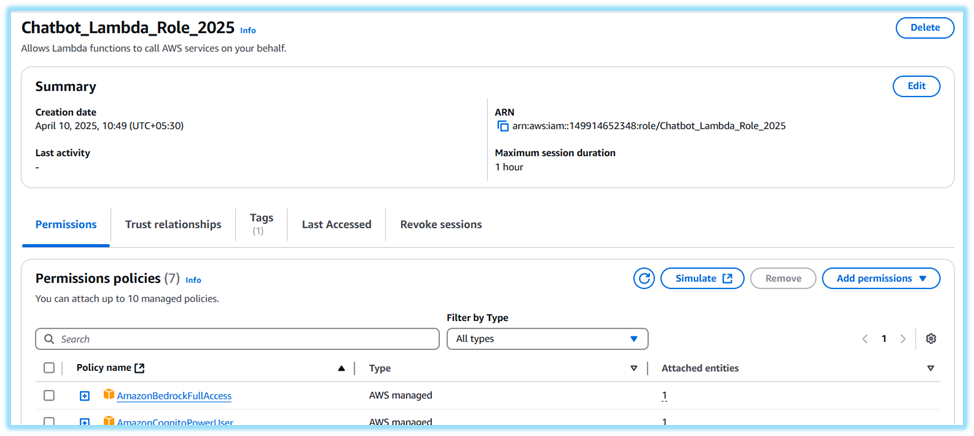
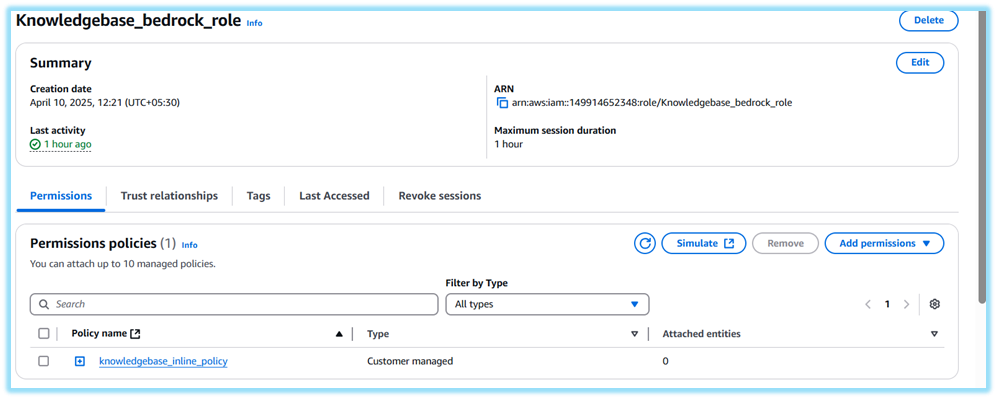
3. Knowledgebase_bedrock_role
- Go to IAM > Roles > Create role
- Choose AWS service > Bedrock (or use Custom Trust Policy if prompted for specific service access) → Click Next
- On Add permissions page, skip adding managed policies → Click Next
- Set Role name as Knowledgebase_bedrock_role → Click Create role
- Once created, go to the role → Click Add inline policy
- Go to JSON tab and paste the inline policy (see below)
- Click Review policy
- Name it knowledgebase_inline_policy → Click Create policy
5.2 Create an S3 Bucket for Knowledge Documents
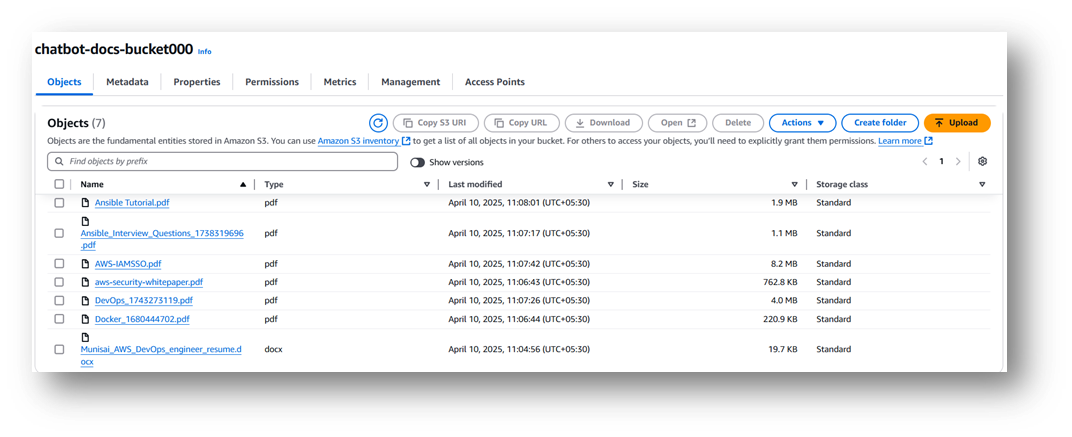
- Go to Amazon S3 in the AWS Console.
- Click on “Create bucket”.
- Enter a unique bucket name (Chatbot-docs-bucket000).
- Choose the Region where your services are hosted.
- Uncheck "Block all public access" (only if private access via roles is set properly).
- Leave other settings as default and click Create bucket.
- After the bucket is created:
- Upload 1-2 sample files (e.g., .pdf, .csv, .txt) under a folder (e.g., /knowledge/).
- Note the full S3 URI.
5.3 Amazon Kendra Setup for GenAI Chatbot
Step 1: Create an Amazon Kendra Index
1.Navigate to the Amazon Kendra Console:
- Open the Amazon Kendra Console.
Select Create index to begin the index creation process.
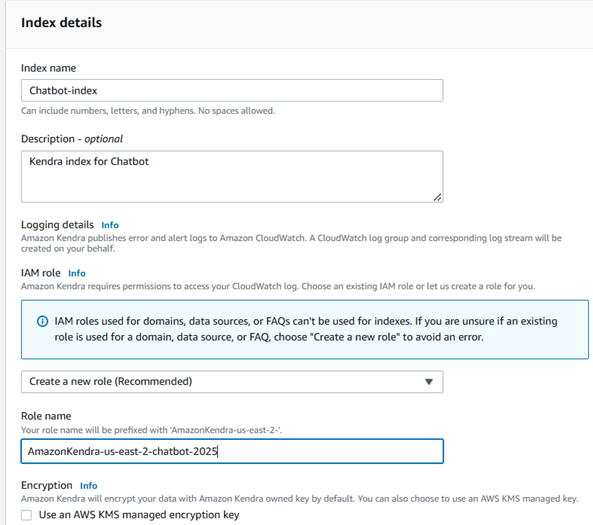
2.Configure the Index:Index Name: Provide a unique name for your index, such as GenAI-Chatbot-Index.
Description: Optionally add a description for the index (e.g., "Index for enterprise knowledge base for chatbot").
Language: Select the language for the content (e.g., English).
IAM Role: Choose an existing IAM role with necessary permissions.
3.Review & Create:Review the details and click Create to finalize the index setup.

Step 2: Configure Data Sources for Kendra Index
1.Choose a Data Source:
- After the index is created, select Data sources from the Kendra console.
- Click Add data source to start the configuration for content ingestion.
2.Select the Content Source:
- Choose S3 as the data source for your documents (PDFs, CSVs, TXT files).
- Enter a name for the data source (e.g., S3-Documents).
3.Configure S3 Data Source:
- S3 Bucket: Provide the S3 bucket where your documents are stored.
- Access Role: Specify an IAM role with permissions to read from the S3 bucket.
- Document Metadata: Configure metadata fields if necessary (e.g., author, document type).


3.Create Data Source:
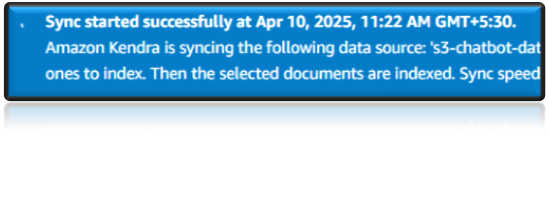
- Review the settings and click Create to complete the data source setup.
- Start Sync.

5.4 Create a Bedrock Knowledge Base
1.Go to Bedrock Console:https://console.aws.amazon.com/bedrock/home
2.Navigate:In the left panel, click "Knowledge bases" → "Create knowledge base"
3.Basic Info:
- Name: Hello-chatbot
Description: (Optional) GenAI chatbot with RAG using Bedrock
4.IAM Permissions:Choose "Create and use a new IAM role"
(Or use existing role like Knowledgebase_bedrock_role)
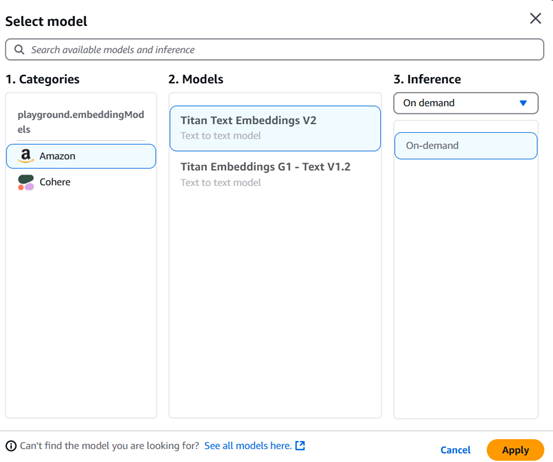
5.Embeddings Model:
- Provider: Amazon
- Model: Titan Text Embeddings V2
6.Vector Store:
- Choose Amazon OpenSearch Serverless (recommended)

7.Set Up Data Source:
- Select your bucket name or Amazon Kendra as a data source for knowledge base.
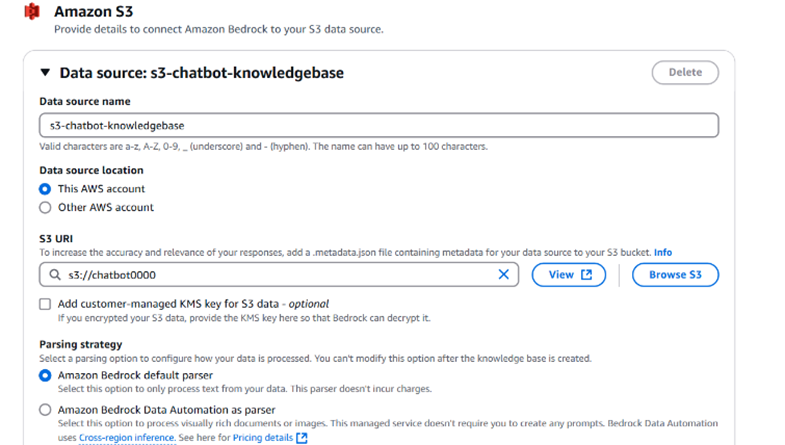
8.Review & Create:
- Review all settings
- Click "Create knowledge base"

After Successfully creation you need to sync the knowledge base to the data source for chatbot to give the answers for your questions as per you documents.
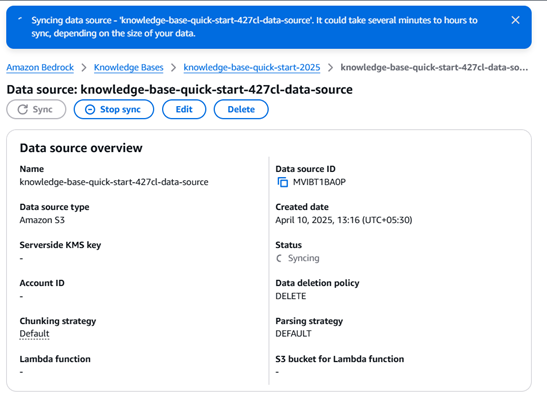
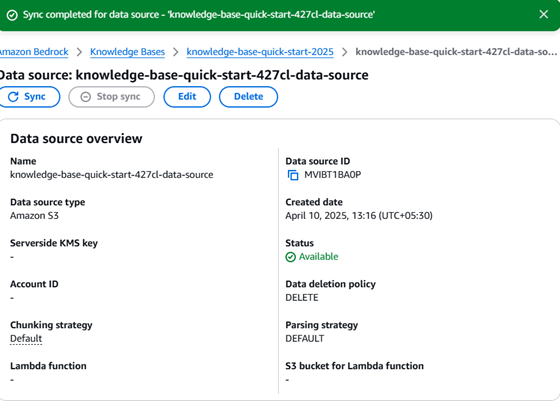
Let’s check the Results BOOM……..!

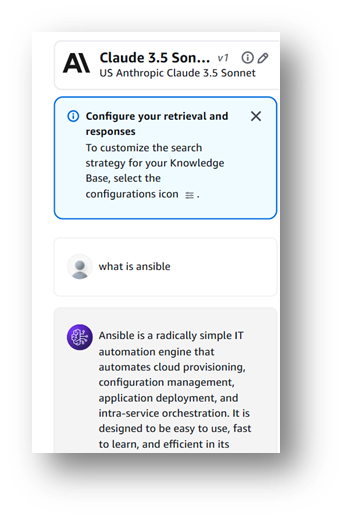
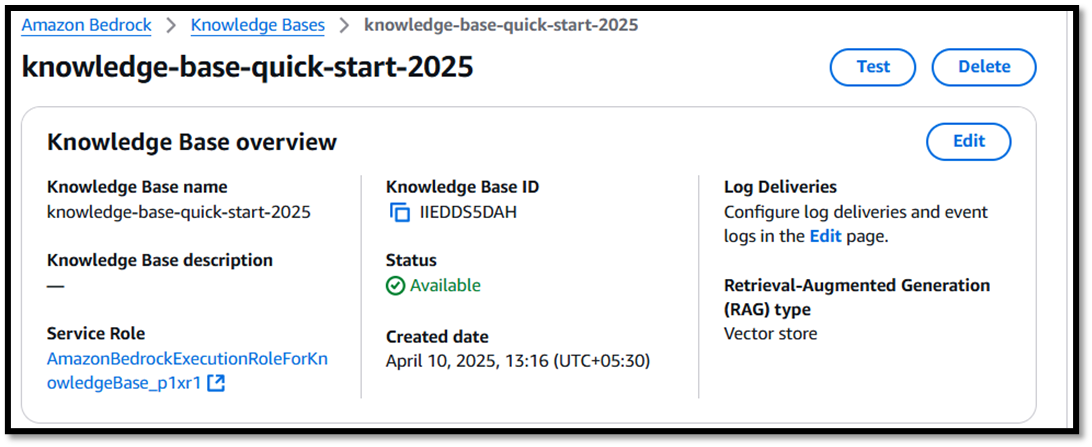
Serverless OpenSearch vector Database for Knowledge Base
- It is Created Automatically During the creation on Bedrock Knowledge Base.

It's Very Simple To create AI Chatbot Using Amazon Bedrock with Your Natural data.
4.5 AWS Lambda Function for Chatbot Logic
- Go to Lambda Console.
- Click Create function.
- Choose Author from scratch:
- Name the lambda function.
- Runtime: Python 3.12 or Node.js (your choice)
- Assign a role with Kendra & Bedrock access.

5.6 Create API with Amazon API Gateway
- Go to API Gateway Console.
- Click Create API → Choose HTTP API.
- Add a route:
- Method: POST
- Path: /ask
- Integration:
- Choose Lambda function (select your chatbot Lambda).
- Enable CORS.
- Click Next → Review → Click Create.
- Copy the Invoke URL (you’ll use it in frontend).


5.7 Cognito User Pools
- Create a User Pool: Go to the Amazon Cognito Console, select Create a User Pool, name it (e.g., webapp-userpool), and configure email as a required attribute with email verification enabled.
- Add a User: Under the Users and groups tab, click Create user, enter the user’s email, and set Email verified to Yes.
- Confirm: Check the Users tab, ensuring the user appears with Email verified set to Yes.

5.8 Deploy Web UI Using AWS Amplify
- Go to AWS Amplify Console.
- Click Get Started under Host a Web App.
- Connect your frontend GitHub repo,s3 or Zipfolder.
- For Zip Folder select Deploy Without git Option.
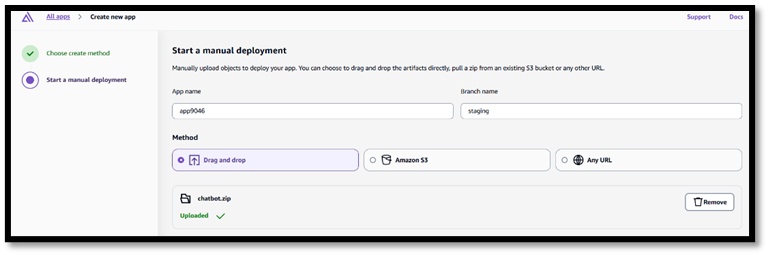

- Choose branch → Amplify auto-detects framework.
- Configure build settings (default works for React).
- Deploy.
- App is now live → Connect it to API Gateway & Cognito.
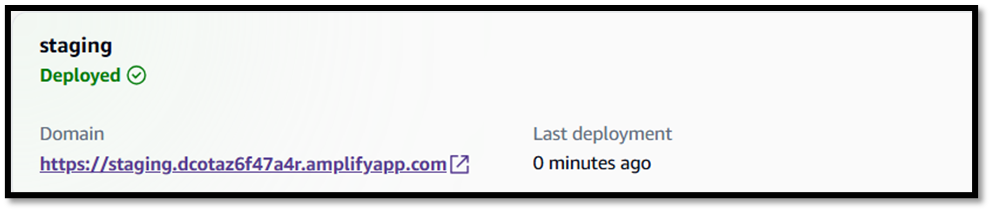
Rock On Yeahh…….!
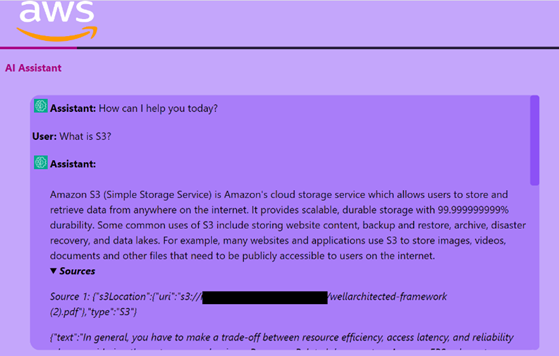
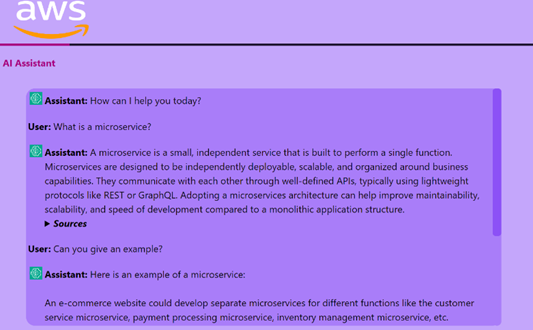
Conclusion
This serverless chatbot architecture offers a powerful and flexible approach to enterprise-level conversational search using Retrieval-Augmented Generation (RAG). With scalable cloud-native services, you can build intelligent assistants that understand and retrieve contextually accurate responses, powered by your own documents.
*Use this project to: *
- Enhance customer and employee support
- Provide intelligent knowledge base interfaces
- Automate internal data discovery workflows
GitHub Repo Link:
https://github.com/Narravula070/Serverless-AI-Chatbot-using-Bedrock.git
Follow Me on LinkedIn:
https://www.linkedin.com/in/munisaiteja-narravula/
Happy Learning and Deep Dive into AI Technologies for Future ....!


