
This is a Plain English Papers summary of a research paper called Simple Edit Beats Complex Nets for Realistic AI Dance Animation. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
From Dance Challenges to Controllable Character Animation in the Wild
Creating realistic animated characters that can perform complex movements while maintaining visual consistency presents significant challenges. Current methods struggle with rare poses, stylized characters, character-object interactions, complex lighting, and dynamic scenes. Most previous approaches focus on injecting pose and appearance guidance through elaborate bypass networks called Reference Nets but often fail in open-world scenarios.
RealisDance-DiT introduces a refreshing perspective: when using a powerful foundation model, straightforward modifications with strategic fine-tuning strategies can address these challenges more effectively than complex architectures. Built upon the Wan-2.1 video foundation model, RealisDance-DiT demonstrates that minimal modifications yield surprisingly strong results.

Results of RealisDance-DiT. Left: Frames generated by RealisDance-DiT. Right: Evaluation on the proposed RealisDance-Val dataset using VBench-I2V metrics.
The authors reveal that widely used Reference Net designs actually underperform with large-scale Diffusion Transformer (DiT) models. Instead, they propose two key fine-tuning strategies: a "low-noise warmup" that accelerates convergence by starting with simpler samples, and a "large batches and small iterations" approach that preserves the valuable priors in the foundation model.

Failure cases of existing methods. Existing methods sometimes generate a face in the silhouette frame, leave dumbbells suspended in the air when the woman squats down, generate artifacts when producing the yoga pose, and generate a realistic face for the comic character.
Previous Approaches in Character Animation
Character animation has evolved from GAN-based methods to modern diffusion approaches. Early diffusion methods like DisCo used ControlNet to incorporate background and pose guidance while adding a motion module for cross-frame consistency. However, it struggled with character consistency since it relied on CLIP features to inject character ID.
Animate Anyone improved character consistency by introducing a UNet-based Reference Net, yet still faltered with stylized characters, complex gestures, and large camera motions. Animate-X introduced a pose indicator approach for stylized characters, while RealisDance integrated 3D hand conditions to improve hand fidelity. HumanVid attempted to address camera motions in realistic settings.
Despite these advancements, existing methods perform poorly in open scenes. The authors identify the weak image-to-video main network as the primary limitation and argue that powerful native video foundation models are needed to handle open-world challenges.
Simple Model Modifications: Unlocking Potential of Foundation Models
RealisDance-DiT is built upon Wan-2.1, with several architectural modifications explored. Initially, the authors attempted to directly transfer Reference Net to Wan-2.1, but this resulted in an overly large network difficult to fine-tune with limited GPU resources. Even a down-scaled Reference Net converged slowly with mediocre performance.
Surprisingly, directly concatenating the reference latent to the noise latent and fine-tuning the entire network converged much quicker with excellent results. This indicates that large video foundation models inherently possess capabilities for downstream tasks—the key is not to modify the architecture extensively but to unlock existing abilities.
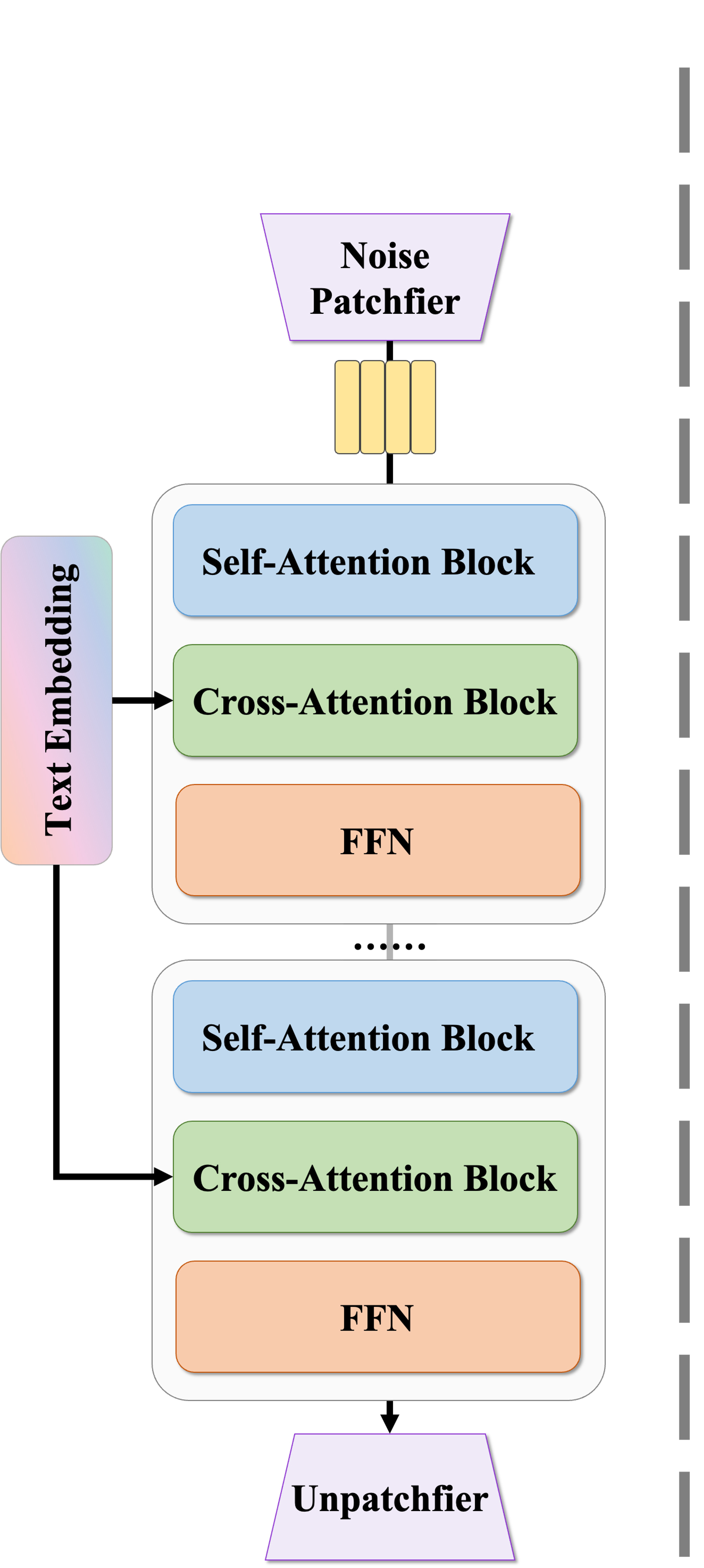
a) Original Wan-2.1
Key implementation details include:
- Using three pose conditions (HaMeR, DWPose, SMPL-CS) as in previous works
- Encoding all poses and reference images with the original Wan-2.1 VAE
- Adding reference latent to noise latent along the sequence length
- Replacing Rotary Position Embedding (RoPE) with shifted RoPE
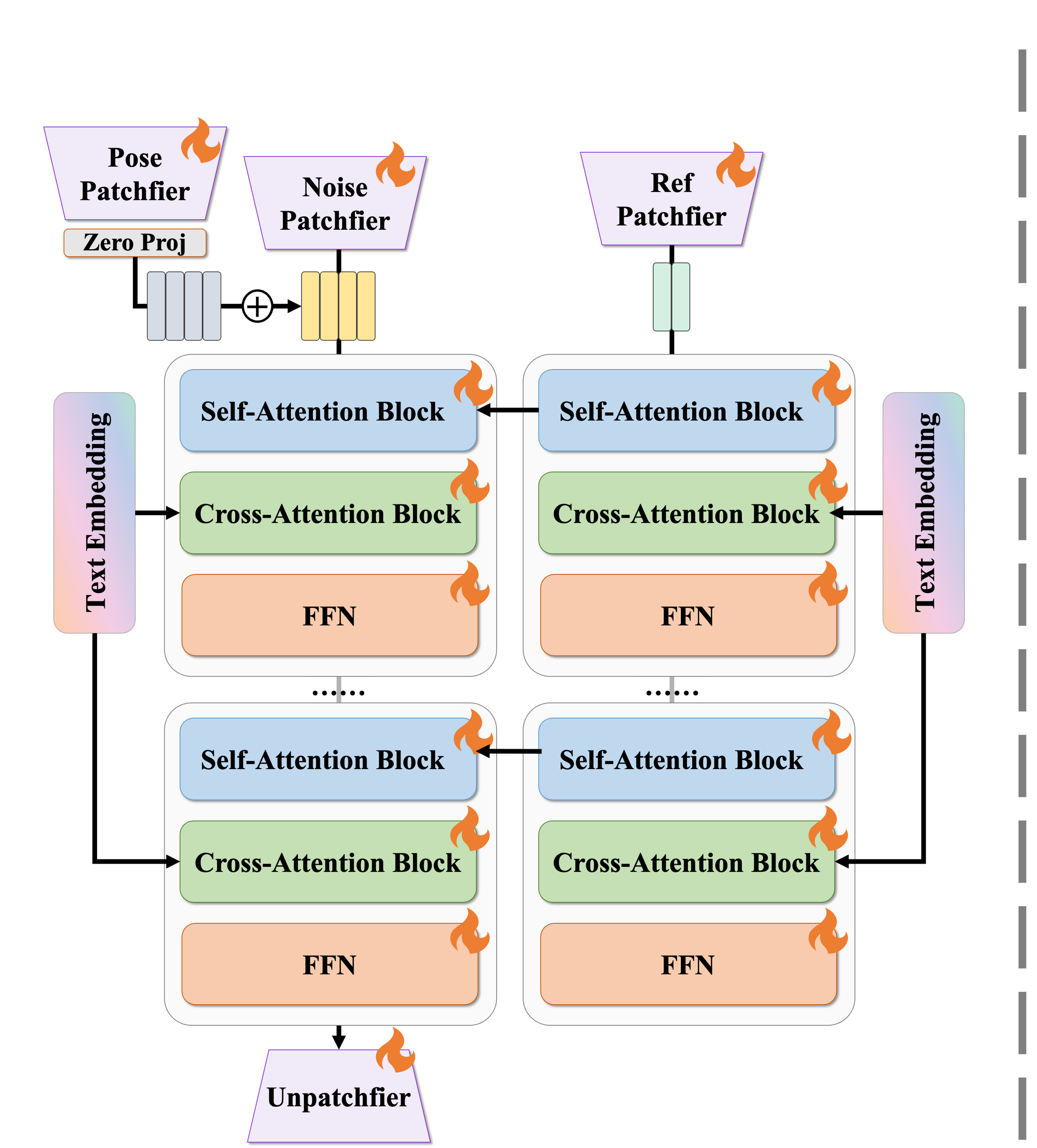
Illustration of spatially shifted RoPE for the reference latent.
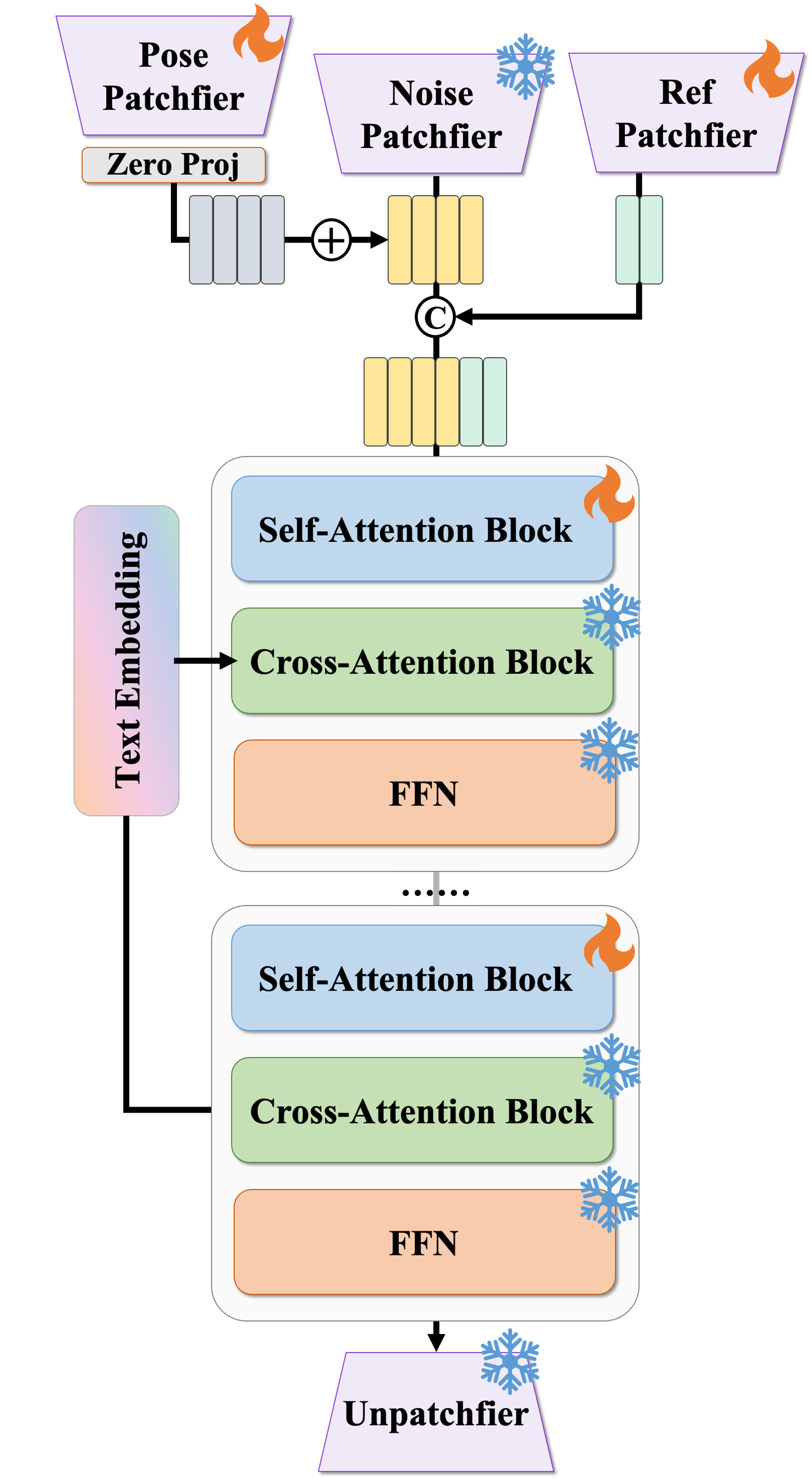
The authors found that fine-tuning just the newly introduced condition patchifiers, zero projection layer, and self-attention blocks performed just as well as full fine-tuning, confirming their hypothesis that minimal modification is sufficient.
Fine-tuning Strategies: Low-noise Warmup and Large Batch Training
The researchers propose two fine-tuning strategies to accelerate convergence while preserving the rich priors in Wan-2.1:
Low-noise warmup strategy: Unlike traditional diffusion models that use fixed sampling distributions throughout training, this strategy employs a dynamic sampling approach. During early fine-tuning, it samples more small timesteps (less noise), making it easier for the model to process samples and stabilize. As fine-tuning progresses, the probability of sampling larger timesteps gradually increases.
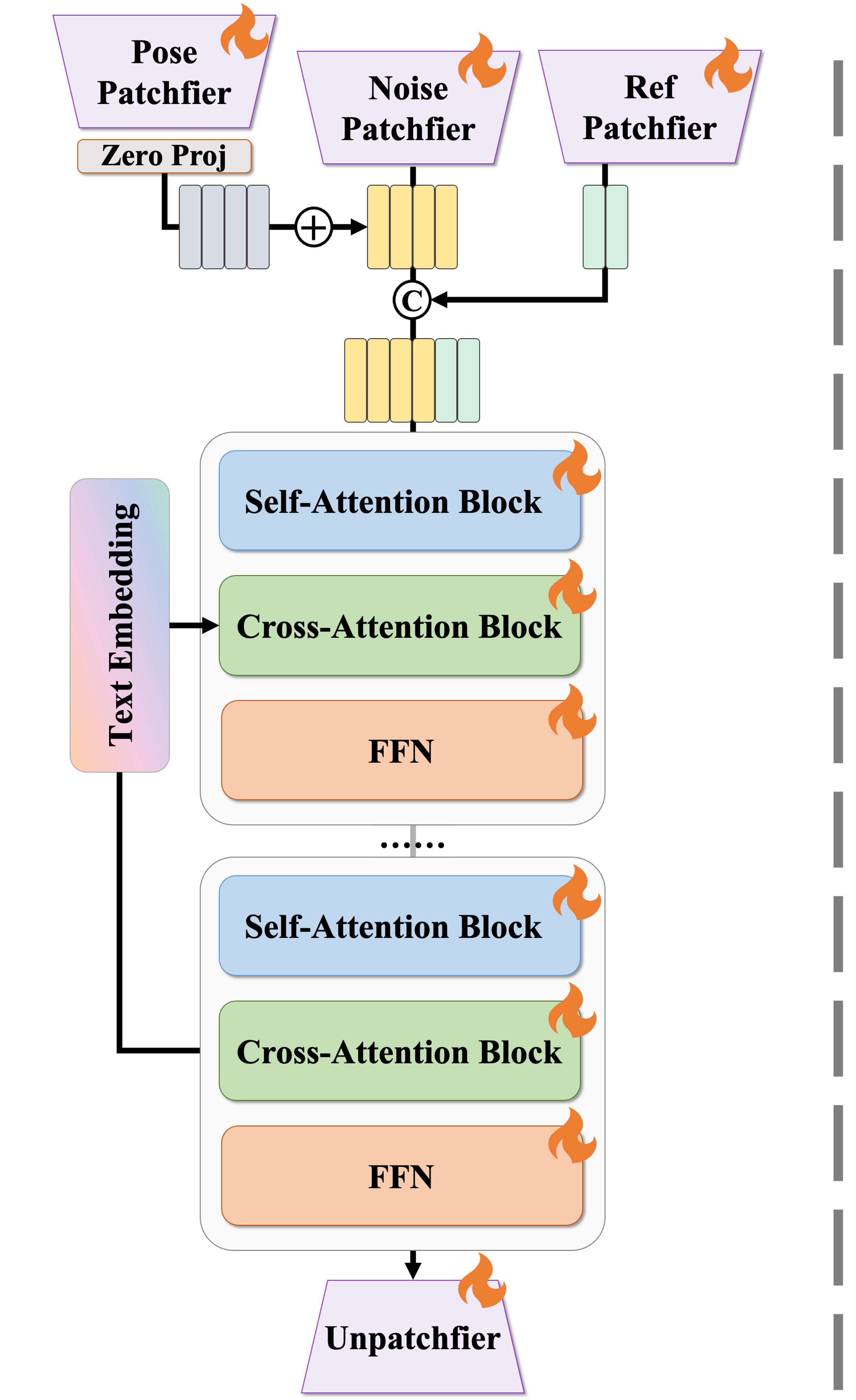
Illustration of low-noise warmup strategy.
The strategy is implemented with a probability density function that incorporates an iteration-relevant component, allowing the sampling distribution to adapt throughout fine-tuning. Early on, there's a higher probability of sampling small timesteps, which gradually shifts toward uniform sampling as iterations increase.
Large batches and small iterations: The researchers recommend using larger batch sizes and fewer training iterations. Larger batches provide more informative yet smoother gradients per update, allowing the model to focus on important factors rather than being distracted by noise. Fewer iterations help preserve the foundation model's valuable pre-trained priors and reduce overfitting.
Together, these strategies facilitate faster convergence while maintaining the rich knowledge already present in the foundation model.
Inference Strategies: Handling Character Body Shape Diversity
During fine-tuning, RealisDance-DiT randomly drops reference images and text prompts at a 5% rate, enabling classifier-free guidance (CFG) with a scale of 2 during inference.
To handle diverse body shapes, the researchers employ an optimization-based approach to refine and replace shape parameters of the SMPL-X model. Starting with initial estimates from GVHMR, they use SMPLify-X to optimize shape parameters guided by 2D keypoints and human silhouettes. This minimizes discrepancies between projected 3D silhouettes and reference silhouettes while maintaining accurate keypoint alignment. The refined shape parameters replace default ones in the driving pose, enabling better shape alignment between reference characters and pose sequences.
Superior Performance in Open-world Scenarios
RealisDance-DiT was compared against open-source methods including MooreAA, Animate-X, ControlNeXt, MimicMotion, and MusePose on three datasets: TikTok, UBC fashion video, and the authors' curated RealisDance-Val (featuring 100 videos with diverse challenges).
Visualization of frames generated by RealisDance-DiT. The images with orange borders are reference images.
The qualitative results show RealisDance-DiT's impressive capabilities:
- Character-object interactions: Natural movement of objects like paddles while rowing a boat or brooms while sweeping floors
- Complex lighting: Accurate rendering of light and shadow according to physical principles
- Rare poses: Smooth, physically consistent videos with accurate pose estimation
- Stylized characters: Effective generalization to various body shapes and styles
- Multiple characters: Potential for scenes with multiple animated characters

Qualitative comparisons between RealisDance-DiT and other methods.
Direct comparisons show RealisDance-DiT's advantages over existing methods:
- While ControlNeXt effectively generates a basketball player's movements, the basketball disappears. RealisDance-DiT maintains the basketball with realistic bouncing physics.
- Animate-X fails to generate legs for complex yoga poses, while RealisDance-DiT handles them effectively.
- MooreAA produces numerous artifacts when animating cartoon characters, while RealisDance-DiT generalizes well to anime styles.
- MimicMotion struggles with camera motion, while RealisDance-DiT maintains scene consistency during camera movements.
- MusePose produces shadows that don't align with character movements, while RealisDance-DiT generates physically accurate shadows.
Quantitative evaluations confirm RealisDance-DiT's superiority:
| Method | I2V Subject |
I2V BG |
Subject Consist |
BG Consist |
Temporal Flicker |
Motion Smooth |
Dynamic Degree |
Aesthetic Quality |
FVD ↓ | FID ↓ |
|---|---|---|---|---|---|---|---|---|---|---|
| Animate-X | 96.06 | 96.59 | 93.83 | 94.83 | 97.40 | 98.52 | 53 | 55.22 | 855.87 | 34.32 |
| ControlNeXt | 92.91 | 93.92 | 91.41 | 93.57 | 96.91 | 98.05 | 63 | 55.57 | 810.82 | 37.24 |
| MimicMotion | 92.79 | 93.80 | 91.10 | 93.20 | 96.78 | 98.20 | 59 | 53.31 | 783.55 | 40.19 |
| MooreAA | 92.33 | 93.35 | 93.12 | 93.77 | 95.20 | 96.74 | 68 | 56.08 | 867.48 | 35.50 |
| MusePose | 92.24 | 93.01 | 93.88 | 94.88 | 97.88 | 98.57 | 57 | 56.28 | 1049.06 | 42.02 |
| RealisDance-DiT | 95.97 | 96.57 | 93.91 | 95.83 | 97.76 | 98.71 | 66 | 57.93 | 563.28 | 24.79 |
Quantitative Results on the RealisDance-Val. RealisDance-DiT ranks either first or second across all evaluation metrics. Especially for FVD and FID, RealisDance-DiT outperforms all compared methods by a large margin.
| Method | SSIM | PSNR | LPIPS ↓ | FVD ↓ | FID ↓ |
|---|---|---|---|---|---|
| Animate-X | 0.7427 | 16.71 | 0.2854 | 508.63 | 32.77 |
| ControlNeXt | 0.7282 | 16.31 | 0.2958 | 548.01 | 33.48 |
| MimicMotion | 0.7507 | 19.30 | 0.2203 | 472.51 | 34.88 |
| MooreAA | 0.7636 | 18.62 | 0.2296 | 501.22 | 37.28 |
| MusePose | 0.7566 | 18.20 | 0.2484 | 532.75 | 41.99 |
| RealisDance-DiT | 0.7170 | 17.55 | 0.2613 | 458.81 | 30.39 |
Quantitative Results on the TikTok dataset.
| Method | SSIM | PSNR | LPIPS ↓ | FVD ↓ | FID ↓ |
|---|---|---|---|---|---|
| Animate-X | 0.8931 | 22.15 | 0.0691 | 70.47 | 10.11 |
| ControlNeXt | 0.8530 | 18.48 | 0.1320 | 143.02 | 13.82 |
| MimicMotion | 0.9126 | 23.80 | 0.0605 | 80.89 | 15.40 |
| MooreAA | 0.8795 | 20.83 | 0.0929 | 149.66 | 21.74 |
| MusePose | 0.8955 | 22.20 | 0.0665 | 96.17 | 14.95 |
Quantitative Results on the UBC fashion video dataset.
On the RealisDance-Val dataset, RealisDance-DiT ranks first or second across all metrics, with particularly strong performance in FVD and FID scores. On the TikTok dataset, it achieves the best FVD and FID scores, while on the UBC fashion dataset, it performs competitively with other methods.
These results validate the approach of using a powerful foundation model with minimal modifications rather than complex architectures for controllable character animation.
What Really Matters in the Model Design
The researchers conducted several ablation studies to determine which aspects of their approach contributed most to performance.
First, they compared four model designs: a Reference Net variant, a lightweight Reference Net variant, simple modifications with full fine-tuning, and simple modifications with part fine-tuning:
| Ref. Net | Light Ref. | Net | Full Ft. | Part Ft. | |
|---|---|---|---|---|---|
| FID | OOM | 31.01 | 25.58 | 24.79 | |
| FVD | OOM | 678.98 | 519.22 | 563.28 |
Model design ablation results comparing Reference Net approaches with simpler modifications.
The Reference Net variant was too large to train (Out Of Memory), while the lightweight version achieved mediocre performance. Simple modifications with either full or partial fine-tuning yielded stronger results, confirming that foundation models already possess necessary capabilities that just need to be unlocked rather than extensively modified.
The researchers also validated their low-noise warmup strategy against fixed uniform sampling and a high-noise warmup approach:
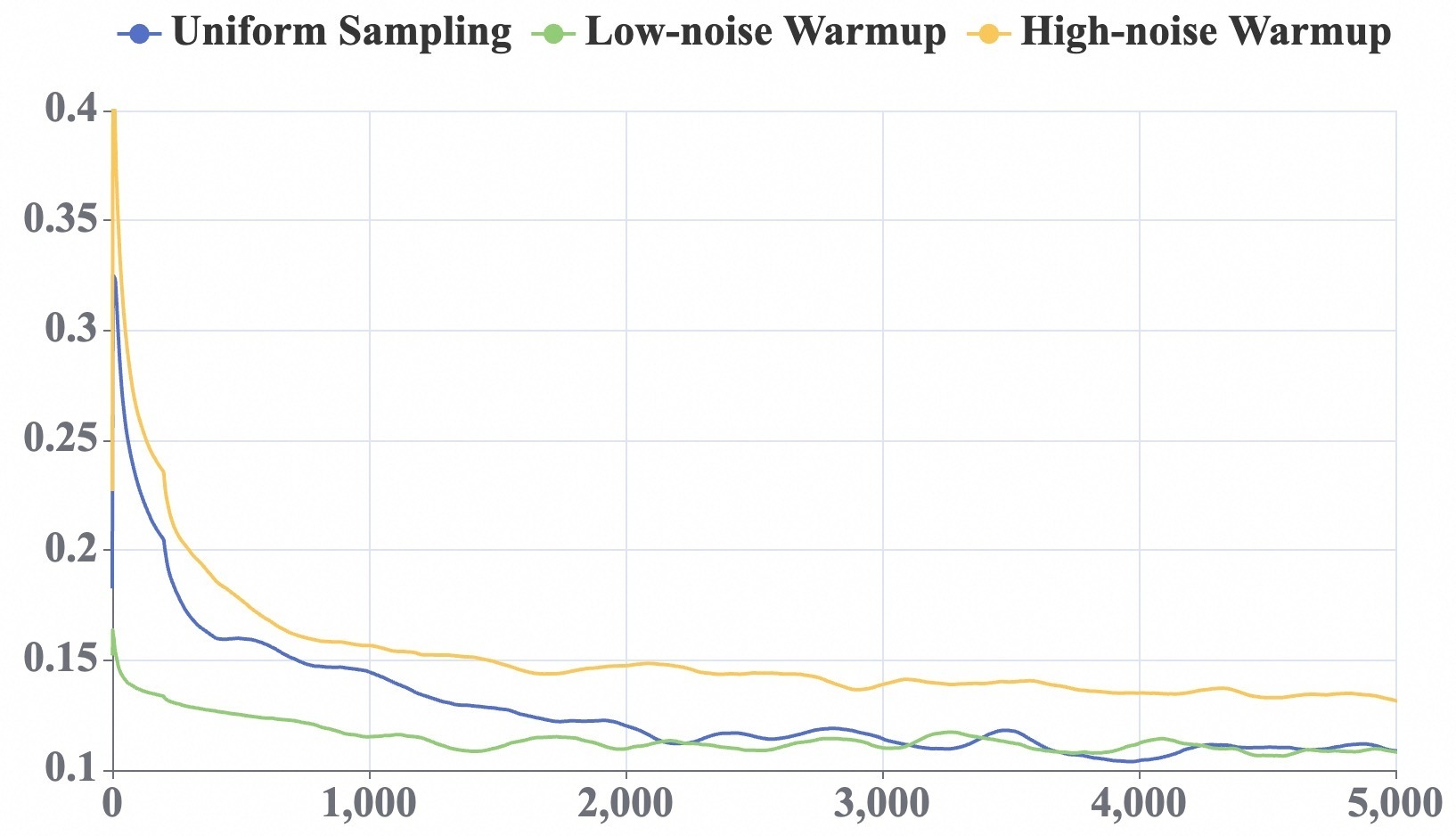
Visualization of smoothed training loss curves.
The low-noise warmup strategy clearly accelerated convergence compared to uniform sampling, while high-noise warmup actually slowed convergence—confirming that starting with simpler (less noisy) samples stabilizes early fine-tuning.
Finally, they explored batch size and iteration count effects:
Visualization of different batch configurations on the RealisDance-Val dataset. '#' denotes the batch size.
Larger batch sizes achieved faster convergence even with the same learning rate. However, as iterations increased, while conditional controllability slightly improved, the diversity of generated results significantly decreased with artifacts appearing. For example, with a batch size of 8 at iteration 36k, the model lost its ability to preserve backgrounds.
This confirms that large batch sizes with fewer iterations facilitate rapid convergence while preserving the foundation model's valuable priors and preventing overfitting on downstream data.
When RealisDance-DiT Struggles
Despite its strong performance, RealisDance-DiT has two main limitations:
Incorrect pose estimation: For extremely complex poses where all three pose estimation methods fail, RealisDance-DiT tends to generate random poses with artifacts. This highlights the model's dependence on accurate pose estimation.
Stationary camera and character: When both character and camera remain relatively stationary—such as skiing with a GoPro or riding a motorcycle toward the camera—RealisDance-DiT generates static backgrounds instead of backgrounds that properly recede. This limitation requires future work to address.

Illustration of limitation cases. RealisDance-DiT tends to generate a static background when the character and the camera are relatively stationary.
A Simple Yet Powerful Animation Baseline
RealisDance-DiT demonstrates that when working with powerful foundation models, simplicity often trumps complexity. Rather than elaborate architectural modifications, the key to successful controllable character animation lies in making minimal changes while employing strategic fine-tuning approaches that preserve the model's built-in knowledge.
The proposed fine-tuning strategies—low-noise warmup and large batches with small iterations—successfully accelerate convergence while maintaining the rich priors of the foundation model. This approach enables RealisDance-DiT to handle challenges that previous methods struggled with, including character-object interactions, complex lighting, stylized characters, and rare poses.
Experimental results across multiple datasets confirm that RealisDance-DiT outperforms existing methods by significant margins, particularly in measures of visual quality and temporal consistency. This establishes RealisDance-DiT as a solid baseline for future research in controllable character animation.
The simplicity of RealisDance-DiT, combined with its strong performance, suggests that the field may benefit from focusing more on unlocking the potential of existing foundation models rather than designing increasingly complex architectures. As the authors demonstrate, sometimes less truly is more.
For applications in video fashion try-on and other character animation tasks, this approach of minimal modification with strategic fine-tuning could prove valuable for developing robust, generalizable systems.
