This is a Plain English Papers summary of a research paper called Single Transformer Beats Modular Vision-Language Models in New Study. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Simplicity Revolution in Vision-Language Models
Multimodal Large Language Models (MLLMs) have seen remarkable progress, but most follow a modular design: a pre-trained vision encoder extracts image features, a language model processes text, and a lightweight projector aligns these modalities. While effective, this approach fragments multimodal processing and limits deployment flexibility.
A promising alternative has emerged - eliminating the visual encoder entirely and processing raw image patches and text tokens within a single Transformer. This approach, exemplified by SAIL (Single trAnsformer model for vIsion and Language), removes modality-specific modules, enabling parameter sharing and end-to-end learning of vision-language interactions.
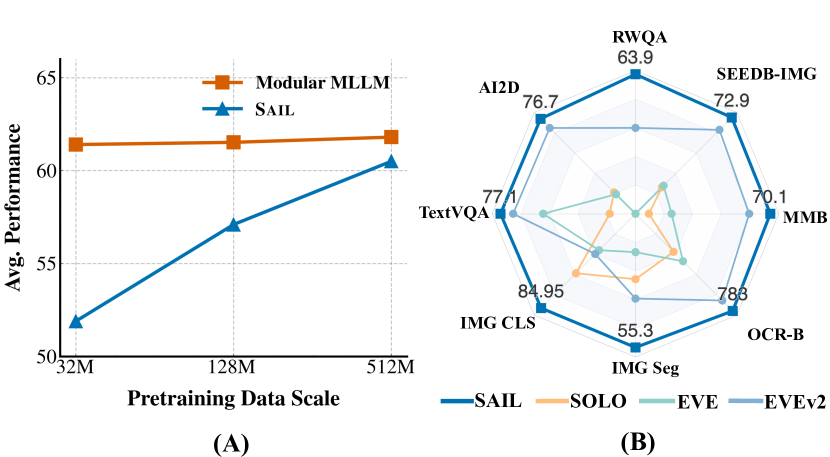
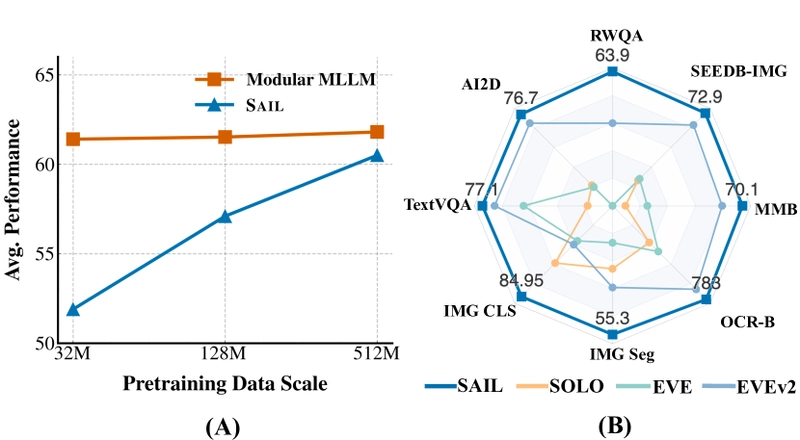
Data scaling curve showing SAIL's superior performance gains with increased training data (left) and comparison with other Single Transformer MLLMs showing SAIL's strong performance on both vision and vision-language tasks (right).
SAIL's analysis uncovers striking advantages of Single Transformer architectures:
Superior Data Scaling: SAIL exhibits steeper performance gains as pretraining data scales. While modular MLLMs initially perform better, the gap narrows substantially with more data.
Vision-Centric Information Flow: Analysis of attention distributions shows Single Transformers assign significantly higher attention scores to image tokens during prediction, indicating a more direct visual information pathway.
Strong Visual Representation: The pretrained Single Transformer inherently serves as a powerful vision encoder, performing impressively on vision-centric tasks like classification and segmentation.
Current Landscape of Vision-Language Models
Paradigms in Vision-Language Model Design
The two primary approaches to MLLMs have distinct advantages and limitations:
Modular MLLMs with Visual Encoders rely on pretrained vision encoders like CLIP-ViT or InternViT to process visual inputs. While this enables effective transfer of visual knowledge, it introduces several drawbacks:
- Separate vision encoders slow down training and inference
- Integration of visual features into LLMs remains challenging
- Balancing interactions between components becomes increasingly complex at scale
Single Transformer-based MLLMs Without Visual Encoders process raw image patches and text tokens through a unified architecture. These models fall into two categories:
- Continuous tokenization (Fuyu-8B, SOLO): Directly maps patches to LLM embeddings via linear projections
- Discrete tokenization (Chameleon, Emu3): Uses VQ-VAE tokenizers to compress images into discrete tokens
Despite innovations from models like EVE and Mono-InternVL, critical gaps remain in understanding the scaling laws and fundamental properties of purely end-to-end trained models.
Vision Representation Learning
Training effective visual representations with language data typically follows three paradigms:
Text as Classification Labels: Uses textual descriptions to extract categorical supervision (Tag2Text, RAM, CatLIP)
Image-Text Contrastive Learning: Aligns global image-text embeddings within a shared latent space (CLIP, ALIGN)
Text as Autoregressive Targets: Treats caption generation as a pretext task for visual representation learning (SimVLM, CapPa)
SAIL aligns with the third category but removes architectural fragmentation by jointly modeling image patches and text tokens in a single Transformer. The approach shows that the resulting model learns transferable vision representations that work well on both multimodal tasks and pure vision tasks.
SAIL: A Single Transformer for Vision and Language
Model Architecture
SAIL uses a unified Transformer architecture that processes both images and text without separate encoders. For text, raw input is tokenized and embedded via the language model's embedding module. For images, input is partitioned into patches and projected into embeddings via linear projection. Special tokens ( and ) mark the boundaries of image patch spans.
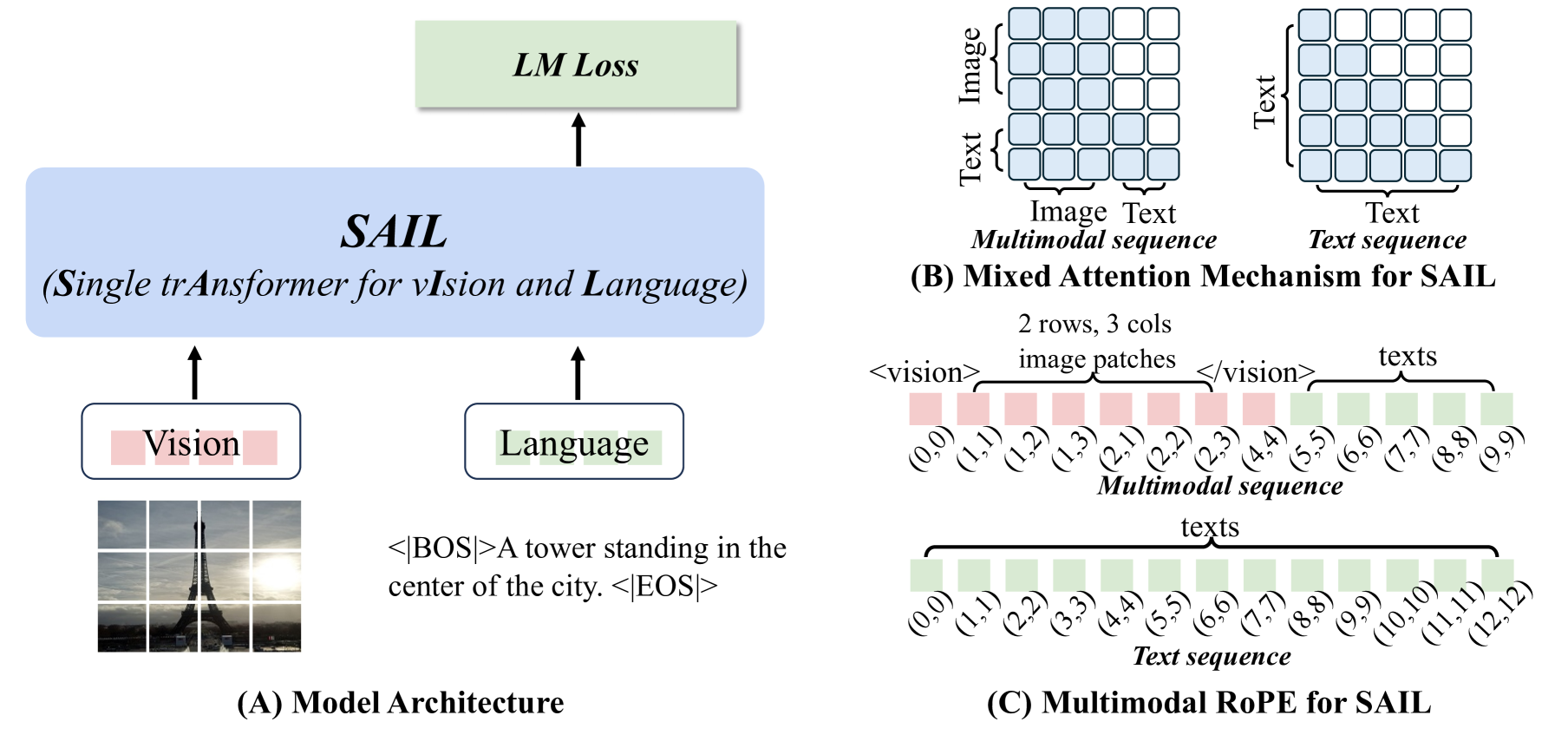
SAIL's unified architecture processes both images and text without extra modules (A), uses a mixed attention mechanism (B) allowing bidirectional attention for image patches, and implements multimodal rotary position embeddings (C) for improved spatial modeling.
Two key innovations distinguish SAIL:
-
Bidirectional attention within image patches: Unlike previous Single Transformer approaches that use only causal attention, SAIL implements a mixed attention scheme:
- Causal attention for text tokens (preserving autoregressive generation)
- Full bidirectional attention for image tokens (enabling holistic spatial relationships)
Multimodal Rotary Position Embeddings (M-RoPE): Decomposes positional encoding into height and width axes, with text tokens sharing uniform position IDs and image tokens adaptively mapping to coordinates.
Pretraining Strategy
SAIL applies a two-stage curriculum:
Accelerated Visual Knowledge Acquisition: Pretraining on large-scale image-text pairs with lower resolution (224×224) to maximize data throughput. Pure text corpora are interleaved to prevent losing language capabilities.
Enhancing Any-Resolution Image Understanding: Extended pretraining with an any-resolution strategy where images retain their native resolutions and positional embeddings adapt dynamically.
| Stage | Dataset | Img.Res | Num |
|---|---|---|---|
| Pretraining S1 | Recap-DataComp-1B [43] SlimPajama [66] |
224x224 | 512M |
| Pretraining S2 | Capfusion [84] OCR from LAION COCO [63] InifinityMM Stage 2 subset [29] SlimPajama [66] |
AnyRes | 60M 7M 19M |
| SFT | InifinityMM Stage3 [29] | AnyRes | 6M |
Details of training datasets used across all stages, showing data sources, image resolution settings, and sample counts.
The pretraining objective uses standard language modeling loss only on text tokens, excluding image patches and special visual tokens from loss computation.
Supervised Fine-tuning
During Supervised Fine-tuning (SFT), SAIL trains on publicly available instruction datasets to enhance understanding of complex linguistic instructions and diverse dialogue patterns. This phase fine-tunes the entire network, focusing on aligning the model's responses with human intent through exposure to varied instructional formats and multimodal interactions.
Experimental Results: Simplicity Meets Performance
Experimental Settings
SAIL evaluates across a broad range of benchmarks:
- Vision-language: MMBench-EN, SEEDBench-IMG, MMVet, MME, HallusionBench, MathVista, OCRBench
- Visual question answering: TextVQA, ScienceQA-IMG, AI2D, MMStar, RealWorldQA
- Vision representation: ImageNet-1K, ADE20K, ARO
For pretraining, SAIL initializes from Mistral-7B-v0.1 with patch size 14, using 128 NVIDIA A100 GPUs. The supervised fine-tuning process uses a global batch size of 512 for one epoch.
Vision-Language Task Performance
SAIL consistently outperforms other Single Transformer-based models across diverse vision-language tasks:
| Method | #Param | #Data | #Vtoken | General VQA | Hallucination | Math&knowledge | OCR VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MMS* | MMB ${ }^{\text {en }}$ | SEED $^{1}$ | MMV | MME | RWQA | POPE | Hallu | $\mathrm{SQA}^{1}$ | MathV | TQA | AI2D OCRB | ||||
| Modular MLLMs: | |||||||||||||||
| InternVL-1.5 [13] | 2.2B | $-/-$ | 3328 | 46.7 | 70.9 | 69.8 | 39.3 | 1902 | 57.9 | 88.3 | 37.3 | 84.9 | 41.3 | 70.5 | 69.8 |
| QwenVL-Chat [3] | 7B | 7.2B / 50M | 256 | 34.5 | 60.6 | 58.2 | - | 1848 | 49.3 | - | 36.8 | 68.2 | 35.3 | 61.5 | 45.9 |
| LLaVA-1.5 [47] | 7B | 0.4B+ / 665K | 576 | 33.1 | 64.3 | 64.3 | 30.5 | 1859 | 54.8 | 85.9 | 27.6 | 66.8 | 25.5 | 46.1 | 54.8 |
| LLaVA-1.6 [48] | 7B | 0.4B+ / 760K | 2880 | 37.6 | 67.4 | 64.7 | 43.9 | 1842 | 57.8 | 86.4 | 27.6 | 70.2 | 32.5 | 64.9 | 66.6 |
| Cambrian-1 [69] | 8B | 10B+ / 7M | 576 | 50.7 | 75.9 | 74.7 | - | - | 64.2 | - | 30.6 | 80.4 | 48.1 | 71.7 | 73.0 |
| LLaVA-OneVision [41] | 7B | 10B+ / 3.2M | 7290 | 60.9 | 81.7 | 74.8 | 58.8 | 1998 | 65.5 | - | - | 96.6 | 56.1 | - | 81.6 |
| Single Transformer-based MLLMs: | |||||||||||||||
| Fuya [5] | 8B | $-/-$ | - | 34.4 | 10.7 | 59.3 | 21.4 | - | 43.7 | 84 | 29.8 | 56.8 | 30.2 | - | 46.8 |
| Chameleon [67] | 7B | 1.4B+ / 1.8M | 1024 | 31.1 | 31.1 | 30.6 | 8.3 | 170 | 39 | 19.4 | 17.1 | 47.2 | 22.5 | 4.8 | 46.0 |
| EVE [21] | 7B | 33M / 1.8M | 2304 | - | 52.3 | 64.6 | 25.7 | 1628 | - | 85.0 | - | 64.9 | - | 56.8 | 61.0 |
| SOLO [11] | 8B | 43.7M / 2M | 1024 | 35.8 | 67.7 | 64.4 | 30.4 | 1260 | 44.7 | 78.6 | 40.4 | 73.3 | 32.9 | 25.0 | 61.4 |
| Mono-InternVL [54] | 3B | 1.3B / 7M | 6400 | - | 65.5 | 67.4 | 40.1 | 1875 | - | - | 45.7 | 93.6 | 45.7 | 72.6 | 68.6 |
| Emu3 [79] | 8B | $/-$ | 16K | 46.6 | 58.5 | 68.2 | 37.2 | - | 57.4 | 85.2 | 31.7 | 89.2 | 31.3 | 64.7 | 70.0 |
| EVE2 [22] | 7B | 92M / 7.3M | 2500 | - | 66.3 | 71.4 | 45.0 | 1709 | 62.4 | 87.6 | - | 96.2 | - | 71.1 | 74.8 |
| SAIL | 7B | 600M / 6M | 3600 | 53.1 | 70.1 | 72.9 | 46.3 | 1719 | 63.9 | 85.8 | 54.2 | 93.3 | 57.0 | 77.1 | 76.7 |
Comparison with existing vision-language models on various vision-language benchmarks, including MMStar, MMBench-EN, SEEDBench-Img, MMVet, MME, POPE, HallusionBench, ScienceQA-Img, TextVQA, MathVistaMINI, AI2D, RealWorldQA, and OCRBench. Note that #A-Param denotes the number of activated parameters; #Data represents the pre-training / fine-tuning data volume; #Vtoken indicates the maximum image patch tokens.
Compared to the state-of-the-art modular MLLM LLaVA-OneVision, SAIL achieves comparable performance on several benchmarks including MMStar, SEEDBench-IMG, and RealWorldQA. This demonstrates that scaling up single-transformer pretraining effectively enhances cross-modal alignment between images and text.
Vision Representation Learning Performance
SAIL demonstrates exceptional performance on vision tasks compared to other single transformer models:
| Method | Classification | Segmentation | |||
|---|---|---|---|---|---|
| Top-1 | Top-5 | mIoU | mAcc | aAcc | |
| EVE [21] | 42.03 | 65.77 | 27.12 | 35.89 | 72.91 |
| EVE2 [22] | 44.86 | 69.41 | 40.85 | 53.53 | 79.31 |
| SOLO [11] | 59.10 | 80.89 | 35.11 | 44.81 | 76.02 |
| SAIL | 84.95 | 97.59 | 55.30 | 67.24 | 84.87 |
Comparison on image classification and semantic segmentation with other encoder-free approaches. Our SAIL outperforms other alternatives by a large margin.
Even when compared with specialized vision backbones, SAIL achieves competitive performance with significantly less training data:
| Method | #Data | #Param | ImageNet-1K | ADE20K |
|---|---|---|---|---|
| OpenCLIP-H [15] | 2B | 0.6B | 84.4 | - |
| OpenCLIP-G [15] | 2B | 1.8B | 86.2 | $39.3^{1}$ |
| ViT-22B [19] | 3B | 22B | $\mathbf{89.5}$ | 55.3 |
| InternViT [14] | 6B | 6B | 88.2 | $\mathbf{58.7}$ |
| SAIL | $\mathbf{0.5B}$ | 7B | 85.0 | 55.3 |
Comparison on image classification and semantic segmentation with other vision backbones. Despite using significantly less training data, SAIL achieves competitive performance.
For additional vision-related tasks, Pixel-SAIL explores SAIL's downstream capabilities in pixel-grounded understanding.
Properties of Single Transformer Models
Model Scaling: As model size increases from 0.5B to 7B parameters, performance improves consistently across vision-language tasks:
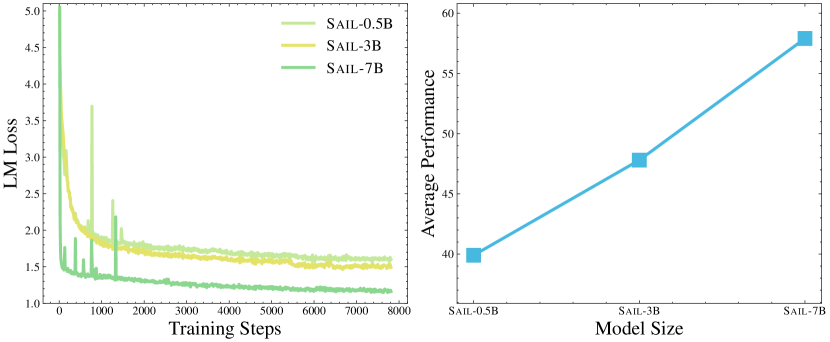
As SAIL's model size increases from 0.5B to 7B parameters, training loss decreases (left) and performance on downstream vision-language tasks improves (right).
Data Scaling: Single Transformer models show superior data scaling properties compared to modular MLLMs. While modular MLLMs perform better with limited data, SAIL exhibits a steeper performance curve as data scales, eventually achieving comparable performance with 512M image-text pairs.
Information Flow Pattern: Single Transformer models allocate significantly more attention to image tokens during prediction:
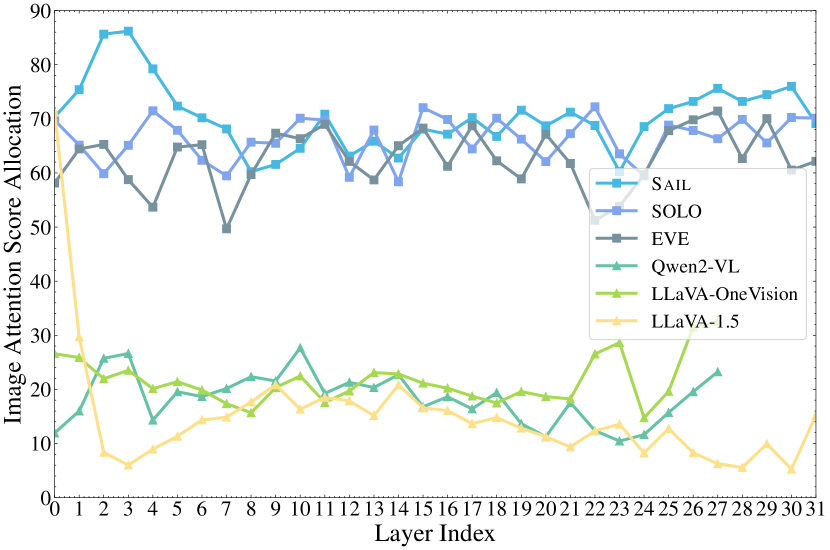
Single transformer models like SAIL allocate significantly higher attention to image tokens during prediction compared to modular MLLMs, indicating more direct visual information flow.
Single Transformer-based MLLMs allocate between 60% and 80% of attention scores to image tokens across all layers when predicting tokens, compared to just 10% to 30% in modular MLLMs. This indicates a more vision-centric approach to multimodal reasoning.
Empirical Observations on Basic Factors
Ablation studies identify key design choices for effective single-transformer MLLMs:
| Exp. Setting | VQAv2 | GQA | SQA | TQA | SEED-I |
|---|---|---|---|---|---|
| Default | 59.1 | 46.9 | 59.6 | 20.1 | 35.1 |
| #1 No Img full attn | 57.8 | 45.2 | 58.7 | 16.2 | 33.8 |
| #2 No pure text in PT | 56.3 | 42.1 | 48.6 | 18.3 | 32.4 |
Ablation Study on Basic Factors for Sail: This table presents the impact of different ablation settings on the performance of Sail across various benchmarks. The default setting includes image full attention and the inclusion of pure text data in pretraining.
Bidirectional Attention for Image Patches with Multimodal Position Encoding: Enabling full bidirectional attention for image patches paired with multimodal rotary position embeddings significantly improves performance, with a notable gain of 3.1% on TextVQA.
Interleaving Pure Text Data During Pretraining: Incorporating text data consistently improves performance across benchmarks, underscoring the importance of preserving language capabilities when training Single Transformer models.
The Future of Single Transformer MLLMs
The extensive analysis of SAIL demonstrates that Single Transformer-based MLLMs offer promising advantages over modular designs. By scaling both training data and model size, this unified architecture achieves performance comparable to modular MLLMs while functioning effectively as a vision backbone.
Key advantages include superior data scalability, vision-centric information flow, and strong visual representation capabilities. Even with less pretraining data than modular approaches, the single-transformer design shows competitive performance on both vision-language and pure vision tasks.
These findings suggest a promising future for simpler, more integrated multimodal architectures. As research continues to refine and enhance Single Transformer designs, we may see these streamlined models become the standard approach for multimodal intelligence, offering better scaling properties and more direct cross-modal interactions than their modular counterparts.
The research on SAIL opens new avenues for exploring how unified architectures can effectively learn from multimodal data without relying on pretrained components, potentially leading to more flexible and powerful vision-language systems.
